Este artículo fue publicado como parte del Blogatón de ciencia de datos.

¿Qué es el análisis de sentimiento?
El inicio y el rápido desarrollo del campo coinciden con los de los medios basados en la web en la web, por ejemplo, encuestas, recopilación de conversaciones, revistas web, microblogs, Twitter y organizaciones interpersonales, porque, sin precedentes en la historia de la humanidad, tenemos un colosal volumen de información obstinada registrada en estructuras avanzadas. Desde mediados de 2000, la investigación de suposiciones se ha convertido en uno de los territorios de examen más dinámicos en la preparación del lenguaje común.
Asimismo, se considera ampliamente en la minería de información, la minería web y la minería de texto. A decir verdad, se ha extendido desde la ingeniería de software hasta las ciencias y sociologías del ejecutivo debido a su importancia para las empresas y la sociedad en general. En los últimos tiempos, también han florecido los ejercicios modernos que abarcan el examen de los sentimientos. Han surgido varias empresas nuevas. Numerosas empresas enormes han construido sus propias capacidades internas.
Los marcos de examen de supuestos han descubierto sus aplicaciones en prácticamente todos los espacios comerciales y sociales. El análisis de sentimientos, también llamado minería de opinión, es el campo de estudio que analiza las opiniones, sentimientos, evaluaciones, valoraciones, actitudes y emociones de las personas hacia entidades como productos, servicios, organizaciones, individuos, problemas, eventos, temas y sus atributos. Representa un gran espacio problemático.
También hay muchos nombres y tareas ligeramente diferentes, por ejemplo, análisis de sentimientos, minería de opiniones, extracción de opiniones, minería de sentimientos, análisis de subjetividad, análisis de efectos, análisis de emociones, minería de opiniones, etc.
Análisis de sentimiento en Python
Hay muchos paquetes disponibles en Python que utilizan diferentes métodos para realizar análisis de sentimientos. En el próximo artículo, repasaremos algunos de los métodos y paquetes más populares:
1. Textblob
2. VADER
→ Bloque de texto:
Textblob El analizador de sentimientos devuelve dos propiedades para una oración de entrada determinada:
- La polaridad es un flotador que se encuentra entre [-1,1], -1 indica sentimiento negativo y +1 indica sentimientos positivos.
- La subjetividad es también un flotador que se encuentra en el rango de [0,1]. Las oraciones subjetivas generalmente se refieren a opiniones, emociones o juicios.
Veamos cómo usar Textblob:
from textblob import TextBlob
test = TextBlob("The movie was awesome!")
print(test.sentiment)

Textblob ignorará las palabras con las que no esté familiarizado, considerará las palabras y expresiones a las que puede distribuir los extremos y los puntos medios para obtener la última puntuación.
→ VADER:
Utiliza una lista de características léxicas (por ejemplo, una palabra) que se etiquetan como positivas o negativas según su orientación semántica para calcular el sentimiento del texto. El sentimiento de Vader devuelve la probabilidad de que una oración de entrada dada sea positiva, negativa y neutral.
Por ejemplo:
«¡La película fue increíble!»
Positivo: 99%
Negativo: 1%
Neutro: 0%
Estas tres probabilidades sumarán el 100%. Veamos cómo usar VADER:
from vaderSentiment.vaderSentiment import SentimentIntensityAnalyzer
analyzer = SentimentIntensityAnalyzer()
sentence = "The movie was awesome!"
vs = analyzer.polarity_scores(sentence)
print"{:-<65} {}".format(sentence, str(vs))

Análisis de sentimiento VADER
Vader está optimizado para datos de redes sociales y puede producir buenos resultados cuando se usa con datos de Twitter, Facebook, etc. Como el resultado anterior muestra la polaridad de la palabra y sus probabilidades de ser pos, neg neu y compuesto.
Ahora, aclararé lo anterior con la ayuda del conjunto de datos de la posada, es decir, el conjunto de datos de Hotel-Review, donde hay opiniones de los clientes que se quedaron en el hotel.
Para resumir el proceso de manera muy simple:
1) Procesamiento previo de la entrada en sus oraciones o palabras componentes.
2) Identifique y etiquete cada fichaLa "Ficha" es un término utilizado en diversos contextos, generalmente para referirse a un documento o tarjeta que contiene información específica sobre un tema, persona o producto. En ámbitos académicos, se utiliza para registrar datos relevantes sobre investigaciones o fuentes bibliográficas. En el ámbito empresarial, las fichas pueden ser herramientas útiles para organizar datos de clientes o productos, facilitando la gestión y el acceso a la información.... con un componente de la parte del discurso (es decir, sustantivo, verbo, determinantes, sujeto de la oración, etc.).
3) Asigne una puntuación de sentimiento de -1 a 1, donde -1 es para sentimiento negativo, 0 como neutral y +1 es un sentimiento positivo
4) Devolver puntajes y puntajes opcionales como puntaje compuesto, subjetividad, etc. mediante el uso de dos poderosas herramientas de Python: Textblob y VADER.
Textblob:
from nltk.sentiment.vader import SentimentIntensityAnalyzer
from nltk.sentiment.util import *
from textblob import TextBlob
from nltk import tokenize
df = pd.read_csv('hotel-reviews.csv')
df.head()
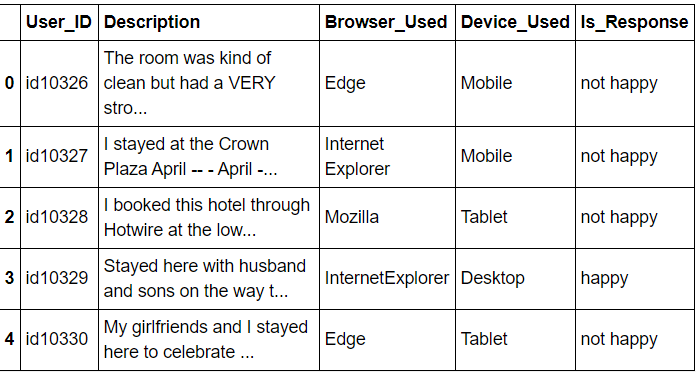
Vista previa del conjunto de datos
Lo anterior es la vista previa del conjunto de datos del conjunto de datos del hotel.
df.drop_duplicates(subset =”Description”, keep = “first”, inplace = True)
df['Description'] = df['Description'].astype('str')
def get_polarity(text):
return TextBlob(text).sentiment.polarity
df['Polarity'] = df['Description'].apply(get_polarity)
En lo anterior, usando el TextBlob (texto) .sentiment.polarity, para generar polaridad de sentimiento.
df['Sentiment_Type']='' df.loc[df.Polarity>0,'Sentiment_Type']='POSITIVE' df.loc[df.Polarity==0,'Sentiment_Type']='NEUTRAL' df.loc[df.Polarity<0,'Sentiment_Type']='NEGATIVE'
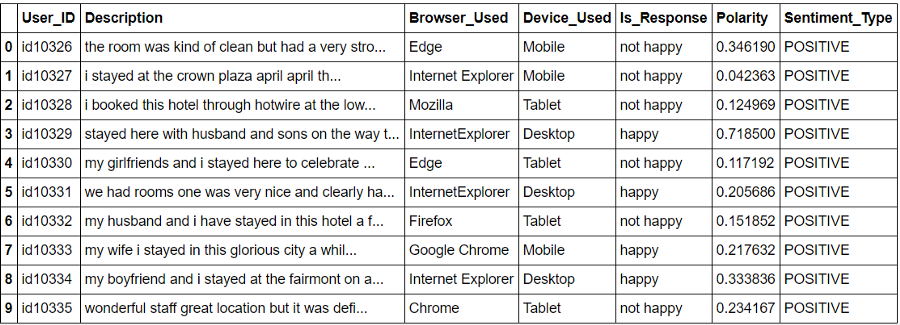
Con Textblob
Después de la TextBlob la polaridad y el tipo de sentimiento para cada comentario / descripción recibido.
df.Sentiment_Type.value_counts().plot(kind='bar',title="Sentiment Analysis")
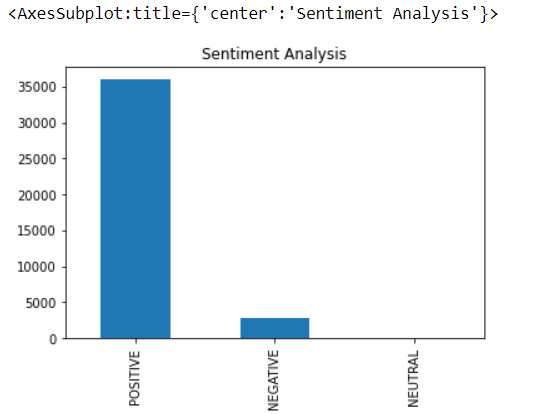
Gráfico de análisis de sentimiento con Textblob
Al trazar el gráfico de barrasEl gráfico de barras es una representación visual de datos que utiliza barras rectangulares para mostrar comparaciones entre diferentes categorías. Cada barra representa un valor y su longitud es proporcional a este. Este tipo de gráfico es útil para visualizar y analizar tendencias, facilitando la interpretación de información cuantitativa. Es ampliamente utilizado en diversas disciplinas, como la estadística, el marketing y la investigación, debido a su simplicidad y efectividad.... para lo mismo, los sentimientos positivos son más que negativos, lo que puede generar comprensión ya que las personas están contentas con el servicio.
VADER:
VADER (Diccionario Valence Aware y Razonador de sentimientos) es una biblioteca preconstruida de analizador de sentimientos de código abierto basada en reglas / léxicos, protegida bajo la licencia MIT.
import nltk
nltk.download('vader_lexicon')
from nltk.sentiment.vader import SentimentIntensityAnalyzer
sid = SentimentIntensityAnalyzer()
Con VADER, usando el sid.polarity_scores (Descripción)), para generar polaridad de sentimiento.
df['scores'] = df['Description'].apply(lambda Description: sid.polarity_scores(Description)) df.head()

Valor de puntuación generado sobre la base de VADER
Después de la VADER las puntuaciones que tienen pos, neg, neu y compuesto.
df['compound'] = df['scores'].apply(lambda score_dict: score_dict['compound']) df['sentiment_type']='' df.loc[df.compound>0,'sentiment_type']='POSITIVE' df.loc[df.compound==0,'sentiment_type']='NEUTRAL' df.loc[df.compound<0,'sentiment_type']='NEGATIVE'
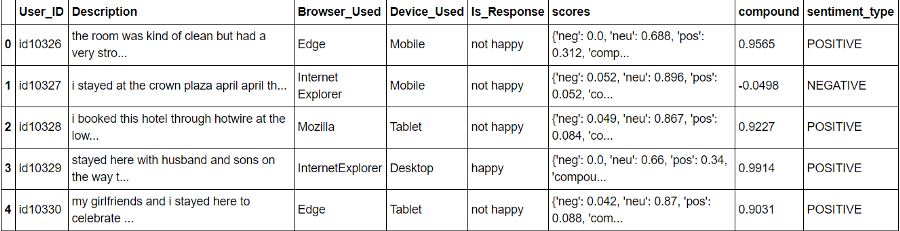
Análisis de sentimiento con VADER
Después de la VADER el compuesto y el tipo de sentimiento para cada comentario / descripción recibido.
df.sentiment_type.value_counts().plot(kind='bar',title="sentiment analysis")
Gráfico de análisis de sentimiento con VADER
Tanto Textblob como Vader ofrecen una serie de funciones; es mejor intentar ejecutar algunos datos de muestra sobre su tema para ver cuál funciona mejor para sus requisitos. Al trazar el gráfico de barras para lo mismo, los sentimientos positivos son más que negativos, lo que puede generar comprensión ya que las personas están contentas con el servicio.
Espero que esto ayude 🙂
Sígueme si te gustan mis publicaciones. Para obtener más ayuda, consulte mi Github para Textblob y VADER.
Conectarse a través de LinkedIn https://www.linkedin.com/in/afaf-athar-183621105/
Feliz aprendizaje 😃





