Introducción
“Si le hablas a un hombre en un idioma que entiende, se le sube a la cabeza. Si le hablas en su propio idioma, llegará a su corazón «. – Nelson Mandela
La belleza del lenguaje trasciende fronteras y culturas. Aprender un idioma que no sea nuestro idioma materno es una gran ventaja. Pero el camino hacia el bilingüismo, o multilingüismo, a menudo puede ser largo e interminable.
Hay tantos pequeños matices que nos perdemos en el mar de palabras. Sin embargo, las cosas se han vuelto mucho más fáciles con los servicios de traducción en línea (¡te estoy mirando el Traductor de Google!).
Siempre he querido aprender un idioma que no sea el inglés. Intenté aprender alemán (o Deutsch) en 2014. Fue divertido y desafiante. Finalmente tuve que renunciar, pero albergaba el deseo de empezar de nuevo.

Avance rápido hasta 2019, tengo la suerte de poder construir un traductor de idiomas para cualquier posible par de idiomas. ¡Qué gran beneficio ha sido el procesamiento del lenguaje natural!
En este artículo, analizaremos los pasos para crear un modelo de traducción de idioma alemán al inglés utilizando Keras. También echaremos un vistazo rápido a la historia de los sistemas de traducción automática con el beneficio de la retrospectiva.
Este artículo asume familiaridad con RNN, LSTM y Keras. A continuación se muestran un par de artículos para leer más sobre ellos:
Tabla de contenido
- Traducción automática: una breve historia
- Comprensión de la declaración del problema
- Introducción a la predicción secuencia a secuencia
- Implementación en Python usando Keras
Traducción automática: una breve historia
La mayoría de nosotros conocimos la traducción automática cuando Google presentó el servicio. Pero el concepto ha existido desde mediados del siglo pasado.
El trabajo de investigación en traducción automática (MT) comenzó ya en la década de 1950, principalmente en los Estados Unidos. Estos primeros sistemas se basaban en enormes diccionarios bilingües, reglas codificadas a mano y principios universales subyacentes al lenguaje natural.
En 1954, IBM realizó una primera demostración pública de una traducción automática. El sistema tenía un vocabulario bastante pequeño de solo 250 palabras y podía traducir solo 49 oraciones rusas seleccionadas al inglés. El número parece minúsculo ahora, pero el sistema es ampliamente considerado como un hito importante en el progreso de la traducción automática.

Esta imagen ha sido tomada del trabajo de investigación describiendo el sistema de IBM
Pronto surgieron dos escuelas de pensamiento:
- Enfoques empíricos de prueba y error, utilizando métodos estadísticos, y
- Enfoques teóricos que involucran la investigación lingüística fundamental
En 1964, el gobierno de los Estados Unidos estableció el Comité Asesor de Procesamiento Automático de Idiomas (ALPAC) para evaluar el progreso de la traducción automática. ALPAC insistió un poco y publicó un informe en noviembre de 1966 sobre el estado de MT. A continuación se muestran los aspectos más destacados de ese informe:
- Planteó serias dudas sobre la viabilidad de la traducción automática y la calificó de desesperada.
- Se desalentó la financiación para la investigación de MT
- Fue un informe bastante deprimente para los investigadores que trabajan en este campo.
- La mayoría de ellos abandonaron el campo y comenzaron nuevas carreras.
¡No es exactamente una recomendación entusiasta!
Un largo período de sequía siguió a este lamentable informe. Finalmente, en 1981, un nuevo sistema llamado Sistema METEO se desplegó en Canadá para la traducción de los pronósticos meteorológicos publicados en francés al inglés. Fue un proyecto bastante exitoso que se mantuvo en funcionamiento hasta 2001.
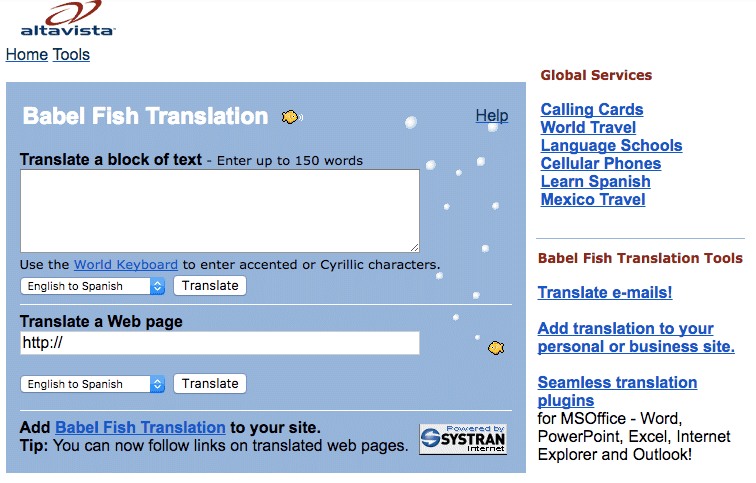
La primera herramienta de traducción web del mundo, Pez de Babel, fue lanzado por el motor de búsqueda de AltaVista en 1997.
Y luego vino el avance con el que todos estamos familiarizados ahora: Google Translate. Desde entonces, ha cambiado la forma en que trabajamos (e incluso aprendemos) con diferentes idiomas.
Fuente: translate.google.com
Comprensión de la declaración del problema
Volvamos a donde lo dejamos en la sección de introducción, es decir, aprender alemán. Sin embargo, esta vez voy a hacer que mi máquina haga esta tarea. El objetivo es convertir una oración en alemán en su contraparte en inglés utilizando un sistema de traducción automática neuronal (NMT).

Usaremos datos de pares de oraciones alemán-inglés de http://www.manythings.org/anki/. Puedes descargarlo desde aquí.
Introducción al modelado secuencia a secuencia (Seq2Seq)
Los modelos de secuencia a secuencia (seq2seq) se utilizan para una variedad de tareas de PNL, como resumen de texto, reconocimiento de voz, modelado de secuencias de ADN, entre otras. Nuestro objetivo es traducir frases dadas de un idioma a otro.
Aquí, tanto la entrada como la salida son frases. En otras palabras, estas oraciones son una secuencia de palabras que entran y salen de un modelo. Esta es la idea básica del modelado secuencia a secuencia. La siguiente figura"Figura" es un término que se utiliza en diversos contextos, desde el arte hasta la anatomía. En el ámbito artístico, se refiere a la representación de formas humanas o animales en esculturas y pinturas. En la anatomía, designa la forma y estructura del cuerpo. Además, en matemáticas, "figura" se relaciona con las formas geométricas. Su versatilidad hace que sea un concepto fundamental en múltiples disciplinas.... intenta explicar este método.
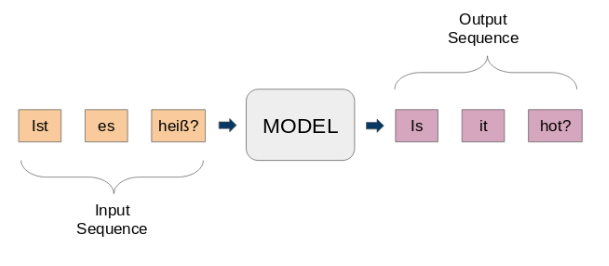
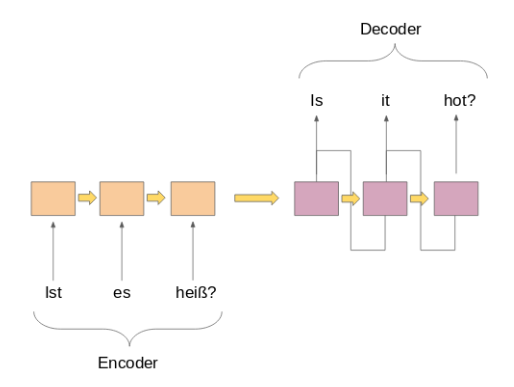
Un modelo típico de seq2seq tiene 2 componentes principales:
a) un codificador
b) un decodificador
Ambas partes son esencialmente dos modelos diferentes de redes neuronales recurrentes (RNN) combinados en una red gigante:
He enumerado algunos casos de uso importantes del modelado secuencia a secuencia a continuación (aparte de la traducción automática, por supuesto):
- Reconocimiento de voz
- Extracción de entidad / sujeto de nombre para identificar el tema principal de un cuerpo de texto
- Clasificación de relaciones para etiquetar relaciones entre varias entidades etiquetadas en el paso anterior
- Habilidades de chatbot para tener capacidad de conversación e interactuar con los clientes
- Resumen de texto para generar un resumen conciso de una gran cantidad de texto
- Sistemas de respuesta a preguntas
Implementación en Python usando Keras
¡Es hora de ensuciarnos las manos! No hay mejor sensación que aprender un tema viendo los resultados de primera mano. Arrancaremos nuestro entorno Python favorito (Jupyter Notebook para mí) y nos pondremos manos a la obra.
Importar las bibliotecas necesarias
import string
import re
from numpy import array, argmax, random, take
import pandas as pd
from keras.models import Sequential
from keras.layers import Dense, LSTM, Embedding, RepeatVector
from keras.preprocessing.text import Tokenizer
from keras.callbacks import ModelCheckpoint
from keras.preprocessing.sequence import pad_sequences
from keras.models import load_model
from keras import optimizers
import matplotlib.pyplot as plt
%matplotlib inline
pd.set_option('display.max_colwidth', 200)
Lea los datos en nuestro IDE
Nuestros datos son un archivo de texto (.txt) de pares de oraciones inglés-alemán. Primero, leeremos el archivo usando la función definida a continuación.
# function to read raw text file
def read_text(filename):
# open the file
file = open(filename, mode="rt", encoding='utf-8')
# read all text
text = file.read()
file.close()
return text
Definamos otra función para dividir el texto en pares inglés-alemán separados por ‘ n’. Luego, dividiremos estos pares en oraciones en inglés y oraciones en alemán, respectivamente.
# split a text into sentences
def to_lines(text):
sents = text.strip().split('n')
sents = [i.split('t') for i in sents]
return sents
Ahora podemos usar estas funciones para leer el texto en una matriz en nuestro formato deseado.
data = read_text("deu.txt")
deu_eng = to_lines(data)
deu_eng = array(deu_eng)
Los datos reales contienen más de 150.000 pares de oraciones. Sin embargo, usaremos solo los primeros 50,000 pares de oraciones para reducir el tiempo de entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina.... del modelo. Puede cambiar este número según la potencia de cálculo de su sistema (¡o si se siente afortunado!).
deu_eng = deu_eng[:50000,:]
Preprocesamiento de texto
Un paso muy importante en cualquier proyecto, especialmente en PNL. Los datos con los que trabajamos a menudo no están estructurados, por lo que hay ciertas cosas de las que debemos ocuparnos antes de pasar a la parte de construcción del modelo.
(a) Limpieza de texto
Primero echemos un vistazo a nuestros datos. Esto nos ayudará a decidir qué pasos de preprocesamiento adoptar.
deu_eng
array([['Hi.', 'Hallo!'],
['Hi.', 'Grüß Gott!'],
['Run!', 'Lauf!'],
...,
['Mary has very long hair.', 'Maria hat sehr langes Haar.'],
["Mary is Tom's secretary.", 'Maria ist Toms Sekretärin.'],
['Mary is a married woman.', 'Maria ist eine verheiratete Frau.']],
dtype="<U380")
Nos desharemos de los signos de puntuación y luego convertiremos todo el texto a minúsculas.
# Remove punctuation
deu_eng[:,0] = [s.translate(str.maketrans('', '', string.punctuation)) for s in deu_eng[:,0]]
deu_eng[:,1] = [s.translate(str.maketrans('', '', string.punctuation)) for s in deu_eng[:,1]]
deu_eng
array([['Hi', 'Hallo'],
['Hi', 'Grüß Gott'],
['Run', 'Lauf'],
...,
['Mary has very long hair', 'Maria hat sehr langes Haar'],
['Mary is Toms secretary', 'Maria ist Toms Sekretärin'],
['Mary is a married woman', 'Maria ist eine verheiratete Frau']],
dtype="<U380")
# convert text to lowercase
for i in range(len(deu_eng)):
deu_eng[i,0] = deu_eng[i,0].lower()
deu_eng[i,1] = deu_eng[i,1].lower()
deu_eng
array([['hi', 'hallo'],
['hi', 'grüß gott'],
['run', 'lauf'],
...,
['mary has very long hair', 'maria hat sehr langes haar'],
['mary is toms secretary', 'maria ist toms sekretärin'],
['mary is a married woman', 'maria ist eine verheiratete frau']],
dtype="<U380")
(b) Conversión de texto a secuencia
Un modelo Seq2Seq requiere que convertimos tanto las oraciones de entrada como las de salida en secuencias enteras de longitud fija.
Pero antes de hacer eso, visualicemos la longitud de las oraciones. Capturaremos la longitud de todas las oraciones en dos listas separadas para inglés y alemán, respectivamente.
# empty lists
eng_l = []
deu_l = []
# populate the lists with sentence lengths
for i in deu_eng[:,0]:
eng_l.append(len(i.split()))
for i in deu_eng[:,1]:
deu_l.append(len(i.split()))
length_df = pd.DataFrame({'eng':eng_l, 'deu':deu_l})
length_df.hist(bins = 30)
plt.show()
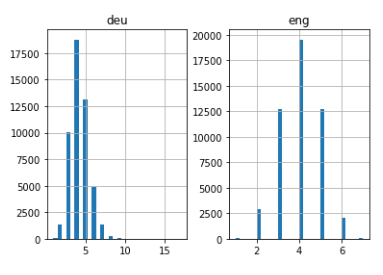
Bastante intuitivo: la longitud máxima de las oraciones en alemán es de 11 y la de las frases en inglés es de 8.
A continuación, vectorice nuestros datos de texto mediante el uso de Keras Tokenizador () clase. Convertirá nuestras oraciones en secuencias de números enteros. Luego podemos rellenar esas secuencias con ceros para hacer todas las secuencias de la misma longitud.
Tenga en cuenta que prepararemos tokenizadores para las oraciones en alemán e inglés:
# function to build a tokenizer
def tokenization(lines):
tokenizer = Tokenizer()
tokenizer.fit_on_texts(lines)
return tokenizer
# prepare english tokenizer
eng_tokenizer = tokenization(deu_eng[:, 0])
eng_vocab_size = len(eng_tokenizer.word_index) + 1
eng_length = 8
print('English Vocabulary Size: %d' % eng_vocab_size)
English Vocabulary Size: 6453
# prepare Deutch tokenizer
deu_tokenizer = tokenization(deu_eng[:, 1])
deu_vocab_size = len(deu_tokenizer.word_index) + 1
deu_length = 8
print('Deutch Vocabulary Size: %d' % deu_vocab_size)
Deutch Vocabulary Size: 10998
El siguiente bloque de código contiene una función para preparar las secuencias. También realizará el relleno de secuencia hasta una longitud máxima de oración como se mencionó anteriormente.
# encode and pad sequences def encode_sequences(tokenizer, length, lines): # integer encode sequences seq = tokenizer.texts_to_sequences(lines) # pad sequences with 0 values seq = pad_sequences(seq, maxlen=length, padding='post') return seq
Construcción del modelo
Ahora dividiremos los datos en tren y conjunto de prueba para el entrenamiento y la evaluación del modelo, respectivamente.
from sklearn.model_selection import train_test_split # split data into train and test set train, test = train_test_split(deu_eng, test_size=0.2, random_state = 12)
Es hora de codificar las oraciones. Nosotros codificaremos Oraciones en alemán como secuencias de entrada y Oraciones en inglés como secuencias de destino. Esto debe hacerse tanto para el tren como para los conjuntos de datos de prueba.
# prepare training data trainX = encode_sequences(deu_tokenizer, deu_length, train[:, 1]) trainY = encode_sequences(eng_tokenizer, eng_length, train[:, 0]) # prepare validation data testX = encode_sequences(deu_tokenizer, deu_length, test[:, 1]) testY = encode_sequences(eng_tokenizer, eng_length, test[:, 0])
¡Ahora viene la parte emocionante!
Comenzaremos definiendo nuestra arquitectura de modelo Seq2Seq:
- Para el codificador, usaremos una capa de incrustación y una capa LSTM
- Para el decodificador, usaremos otra capa LSTM seguida de una capa densaLa capa densa es una formación geológica que se caracteriza por su alta compacidad y resistencia. Comúnmente se encuentra en el subsuelo, donde actúa como una barrera al flujo de agua y otros fluidos. Su composición varía, pero suele incluir minerales pesados, lo que le confiere propiedades únicas. Esta capa es crucial en estudios de ingeniería geológica y recursos hídricos, ya que influye en la disponibilidad y calidad del agua...

Arquitectura del modelo
# build NMT model
def define_model(in_vocab,out_vocab, in_timesteps,out_timesteps,units):
model = Sequential()
model.add(Embedding(in_vocab, units, input_length=in_timesteps, mask_zero=True))
model.add(LSTM(units))
model.add(RepeatVector(out_timesteps))
model.add(LSTM(units, return_sequences=True))
model.add(Dense(out_vocab, activation='softmax'))
return model
Estamos utilizando el optimizador RMSprop en este modelo, ya que suele ser una buena opción cuando se trabaja con redes neuronales recurrentes.
# model compilation model = define_model(deu_vocab_size, eng_vocab_size, deu_length, eng_length, 512)
rms = optimizers.RMSprop(lr=0.001) model.compile(optimizer=rms, loss="sparse_categorical_crossentropy")
Tenga en cuenta que hemos utilizado ‘sparse_categorical_crossentropy‘como la función de pérdidaLa función de pérdida es una herramienta fundamental en el aprendizaje automático que cuantifica la discrepancia entre las predicciones del modelo y los valores reales. Su objetivo es guiar el proceso de entrenamiento al minimizar esta diferencia, permitiendo así que el modelo aprenda de manera más efectiva. Existen diferentes tipos de funciones de pérdida, como el error cuadrático medio y la entropía cruzada, cada una adecuada para distintas tareas y.... Esto se debe a que la función nos permite usar la secuencia de destino tal como está, en lugar del formato codificado en caliente. La codificación en caliente de las secuencias de destino utilizando un vocabulario tan extenso podría consumir toda la memoria de nuestro sistema.
¡Estamos listos para comenzar a entrenar nuestro modelo!
Lo entrenaremos durante 30 épocas y con un tamaño de lote de 512 con una división de validación del 20%. El 80% de los datos se utilizará para entrenar el modelo y el resto para evaluarlo. Puede cambiar y jugar con estos hiperparámetros.
También usaremos el ModelCheckpoint () función para guardar el modelo con la menor pérdida de validación. Personalmente prefiero este método a la parada anticipada.
filename="model.h1.24_jan_19"
checkpoint = ModelCheckpoint(filename, monitor="val_loss", verbose=1, save_best_only=True, mode="min")
# train model
history = model.fit(trainX, trainY.reshape(trainY.shape[0], trainY.shape[1], 1),
epochs=30, batch_size=512, validation_split = 0.2,callbacks=[checkpoint],
verbose=1)
Comparemos la pérdida de entrenamiento y la pérdida de validación.
plt.plot(history.history['loss']) plt.plot(history.history['val_loss']) plt.legend(['train','validation']) plt.show()
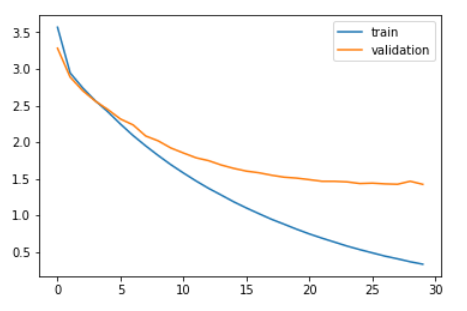
Como puede ver en el gráfico anterior, la pérdida de validación dejó de disminuir después de 20 épocas.
Finalmente, podemos cargar el modelo guardado y hacer predicciones sobre los datos invisibles: testX.
model = load_model('model.h1.24_jan_19')
preds = model.predict_classes(testX.reshape((testX.shape[0],testX.shape[1])))
Estas predicciones son secuencias de números enteros. Necesitamos convertir estos números enteros en sus palabras correspondientes. Definamos una función para hacer esto:
def get_word(n, tokenizer):
for word, index in tokenizer.word_index.items():
if index == n:
return word
return None
Convertir predicciones en texto (inglés):
preds_text = []
for i in preds:
temp = []
for j in range(len(i)):
t = get_word(i[j], eng_tokenizer)
if j > 0:
if (t == get_word(i[j-1], eng_tokenizer)) or (t == None):
temp.append('')
else:
temp.append
else:
if(t == None):
temp.append('')
else:
temp.append
preds_text.append(' '.join(temp))
Pongamos las oraciones originales en inglés en el conjunto de datos de prueba y las oraciones predichas en un marco de datos:
pred_df = pd.DataFrame({'actual' : test[:,0], 'predicted' : preds_text})
Podemos imprimir aleatoriamente algunas instancias reales frente a las previstas para ver cómo funciona nuestro modelo:
# print 15 rows randomly pred_df.sample(15)
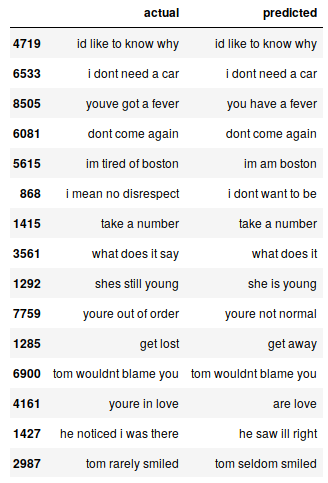
Nuestro modelo Seq2Seq hace un trabajo decente. Pero hay varios casos en los que pierde la comprensión de las palabras clave. Por ejemplo, se traduce «estoy cansado de Boston» por «soy de Boston».
Estos son los desafíos a los que se enfrentará de forma habitual en la PNL. Pero estos no son obstáculos inamovibles. Podemos mitigar estos desafíos utilizando más datos de entrenamiento y construyendo un modelo mejor (o más complejo).
Puedes acceder al código completo desde este Github repositorio.
Notas finales
Incluso con un modelo Seq2Seq muy simple, los resultados son bastante alentadores. Podemos mejorar este rendimiento fácilmente mediante el uso de un modelo de codificador-decodificador más sofisticado en un conjunto de datos más grande.
Otro experimento en el que puedo pensar es probar el enfoque seq2seq en un conjunto de datos que contiene oraciones más largas. Cuanto más experimente, más aprenderá sobre este vasto y complejo espacio.
Si tiene algún comentario sobre este artículo o tiene alguna duda / pregunta, por favor compártala en la sección de comentarios a continuación.





