Introducción:
En este artículo, aprenderemos todos los conceptos estadísticos importantes que se requieren para los roles de ciencia de datos.
Tabla de contenido:
- Diferencia entre parámetro y estadística
- Estadísticas y sus tipos
- Tipos de datos y niveles de medición
- Momentos de decisión empresarial
- Teorema del límite central (CLT)
- Distribuciones de probabilidad
- Representaciones gráficas
- Prueba de hipótesis
1. Diferencia entre parámetro y estadística
En nuestro día a día seguimos hablando de Población y muestra. Entonces, es muy importante conocer la terminología para representar la población y la muestra.
Un parámetro es un número que describe los datos de la población. Y una estadística es un número que describe los datos de una muestra.
2. Estadísticas y sus tipos
La definición de Wikipedia de Estadística establece que «es una disciplina que se ocupa de la recopilación, organización, análisis, interpretación y presentación de datos».
Significa que, como parte del análisis estadístico, recopilamos, organizamos y extraemos información significativa de los datos, ya sea a través de visualizaciones o explicaciones matemáticas.
Las estadísticas se clasifican ampliamente en dos tipos:
- Estadísticas descriptivas
- Estadística inferencial
Estadísticas descriptivas:
Como sugiere el nombre en Estadística descriptiva, describimos los datos utilizando las distribuciones Media, Desviación estándar, Gráficos o Probabilidad.
Básicamente, como parte de la Estadística descriptiva, medimos lo siguiente:
- Frecuencia: no. de veces que ocurre un punto de datos
- Tendencia central: la centralidad de los datos: media, medianaLa mediana es una medida estadística que representa el valor central de un conjunto de datos ordenados. Para calcularla, se organizan los datos de menor a mayor y se identifica el número que se encuentra en el medio. Si hay un número par de observaciones, se promedia los dos valores centrales. Este indicador es especialmente útil en distribuciones asimétricas, ya que no se ve afectado por valores extremos.... y moda.
- Dispersión: la extensión de los datos: rango, varianza y desviación estándar
- La medida de la posición: percentiles y rangos de cuantiles
Estadística inferencial:
En Estadística inferencial, estimamos los parámetrosLos "parámetros" son variables o criterios que se utilizan para definir, medir o evaluar un fenómeno o sistema. En diversos campos como la estadística, la informática y la investigación científica, los parámetros son fundamentales para establecer normas y estándares que guían el análisis y la interpretación de datos. Su adecuada selección y manejo son cruciales para obtener resultados precisos y relevantes en cualquier estudio o proyecto.... de población. O realizamos pruebas de hipótesis para evaluar las suposiciones hechas sobre los parámetros de la población.
En términos simples, interpretamos el significado de las estadísticas descriptivas infiriéndolas a la población.
Por ejemplo, estamos realizando una encuesta sobre el número de vehículos de dos ruedas en una ciudad. Suponga que la ciudad tiene una población total de 5L personas. Por lo tanto, tomamos una muestra de 1000 personas, ya que es imposible realizar un análisis de los datos de la población completa.
De la encuesta realizada, se encuentra que 800 personas de 1000 (800 de 1000 es 80%) son vehículos de dos ruedas. Entonces, podemos inferir estos resultados a la población y concluir que las personas de 4L de la población de 5L son vehículos de dos ruedas.
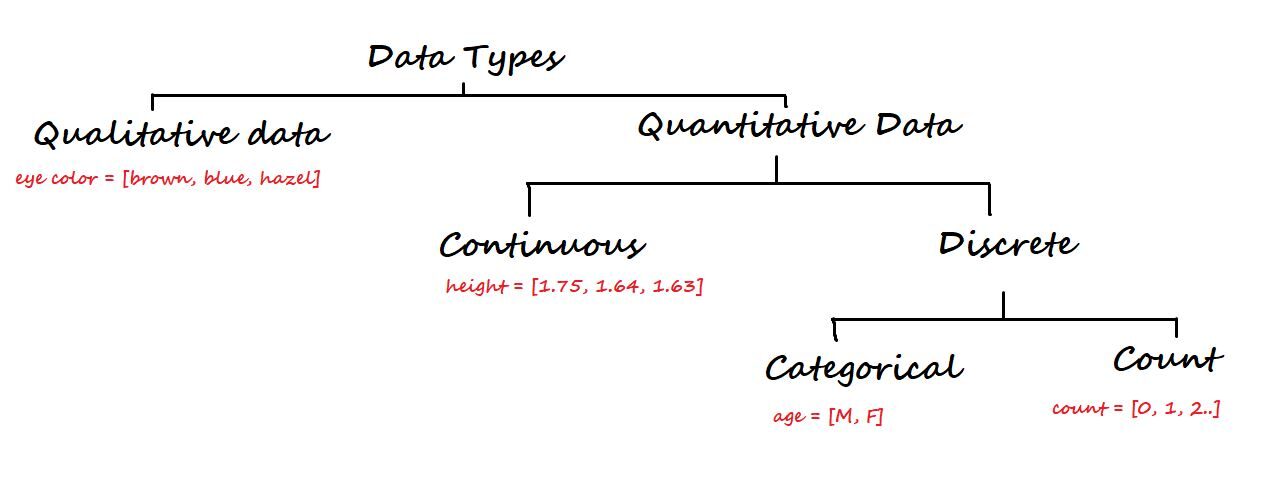
3. Tipos de datos y nivel de medición
En un nivel superior, los datos se clasifican en dos tipos: Cualitativo y Cuantitativo.
Los datos cualitativos no son numéricos. Algunos de los ejemplos son el color de ojos, la marca del automóvil, la ciudad, etc.
Por otro lado, los datos cuantitativos son numéricos y nuevamente se dividen en datos continuos y discretos.
Datos continuos: Se puede representar en formato decimal. Algunos ejemplos son altura, peso, tiempo, distancia, etc.
Datos discretos: No se puede representar en formato decimal. Algunos ejemplos son la cantidad de computadoras portátiles, la cantidad de estudiantes en una clase.
Los datos discretos se vuelven a dividir en categóricos y datos de recuento.
Datos categóricos: representan el tipo de datos que se pueden dividir en grupos. Algunos ejemplos son edad, sexo, etc.
Contar datos: Estos datos contienen números enteros no negativos. Ejemplo: número de hijos que tiene una pareja.
Nivel de medida
En estadística, el nivel de medición es una clasificación que describe la relación entre los valores de una variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.....
Tenemos cuatro niveles fundamentales de medición. Son:
- Escala nominal
- Escala ordinal
- Escala de intervalo
- Escala de proporción
1. Escala nominal: Esta escala contiene la menor cantidad de información ya que los datos solo tienen nombres / etiquetas. Puede usarse para clasificación. No podemos realizar operaciones matemáticas en datos nominales porque no hay un valor numérico para las opciones (los números asociados con los nombres solo se pueden usar como etiquetas).
Ejemplo: ¿A qué país perteneces? India, Japón, Corea.
2. Escala ordinal: En comparación con la escala nominal, la escala ordinal tiene más información porque junto con las etiquetas, tiene orden / dirección.
Ejemplo: Nivel de ingresos: ingresos altos, ingresos medios, ingresos bajos.
3. Escala de intervalo: Es una escala numérica. La escala de intervalo tiene más información que las escalas ordinales nominales. Junto con el orden, conocemos la diferencia entre las dos variables (el intervalo indica la distancia entre dos entidades).
Se pueden utilizar la media, la mediana y la moda para describir los datos.
Ejemplo: temperatura, ingresos, etc.
4. Escala de relación: La escala de razón tiene la mayor cantidad de información sobre los datos. A diferencia de las otras tres escalas, la escala de razón puede acomodar un verdadero punto cero. Se dice simplemente que la escala de razón es la combinación de escalas Nominal, Ordinal e Intercal.
Ejemplo: peso actual, altura, etc.
4. Momentos de decisión empresarial
Tenemos cuatro momentos de decisión empresarial que nos ayudan a comprender los datos.
4.1. Medidas de tendencia central
(También se conoce como decisión comercial en el primer momento)
Habla de la centralidad de los datos. Para simplificarlo, es parte del análisis estadístico descriptivo en el que un solo valor en el centro representa todo el conjunto de datos.
La tendencia central de un conjunto de datos se puede medir mediante:
Significar: Es la suma de todos los puntos de datos dividida por el número total de valores en el conjunto de datos. No siempre se puede confiar en la media porque está influenciada por valores atípicos.
Mediana: Es el valor intermedio de un conjunto de datos ordenado / ordenado. Si el tamaño del conjunto de datos es par, la mediana se calcula tomando el promedio de los dos valores medios.
Modo: Es el valor más repetido del conjunto de datos. Los datos con un solo modo se denominan unimodales, los datos con dos modos se denominan bimodales y los datos con más de dos modos se denominan multimodales.
4.2. Medidas de dispersión
(También se conoce como decisión empresarial de segundo momento)
Habla de la difusión de datos desde su centro.
La dispersión se puede medir usando:
Diferencia: Es la distancia al cuadrado promedio de todos los puntos de datos de su media. El problema con la varianza es que las unidades también se cuadrarán.
Desviación Estándar: Es la raíz cuadrada de la varianza. Ayuda a recuperar las unidades originales.
Distancia: Es la diferencia entre los valores máximo y mínimo de un conjunto de datos.
La medida |
Población |
Muestra |
| Significar | µ = (Σ XI)/NORTE | x̄ = (Σ xI)/norte |
| Mediana | El valor medio de los datos | El valor medio de los datos |
| Modo | Valor más ocurrido | Valor más ocurrido |
| Diferencia | σ2 = (Σ XI – µ)2/NORTE | s2 = (Σ xI – X )2/ (n-1) |
| Desviación Estándar | σ = raíz cuadrada ((Σ XI – µ)2/NORTE) | s = raíz cuadrada ((Σ xI – X )2/ (n-1)) |
| Distancia | Máximo minimo | Máximo minimo |
4.3. Oblicuidad
(También se conoce como decisión comercial en el tercer momento)
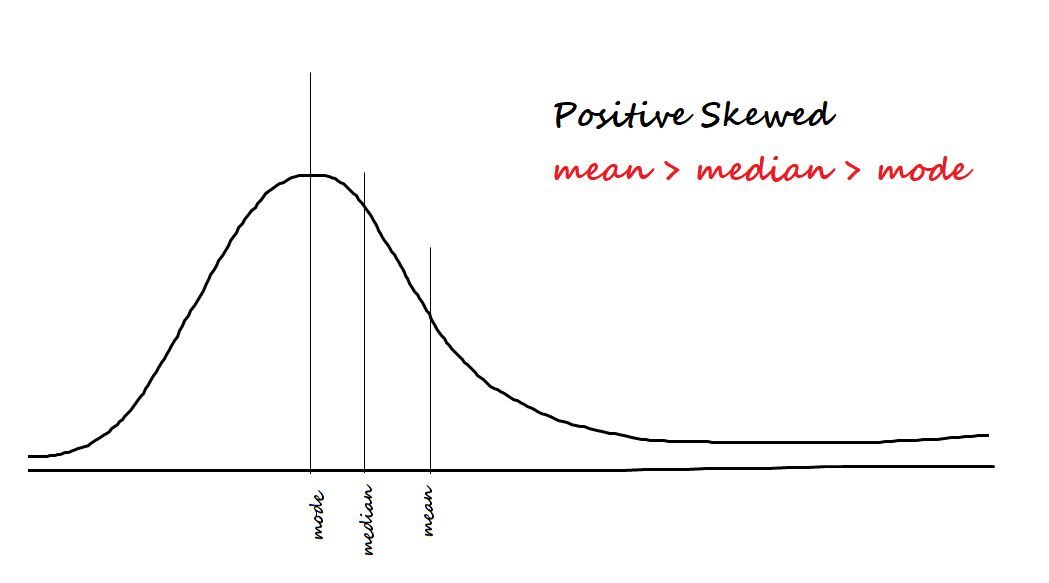
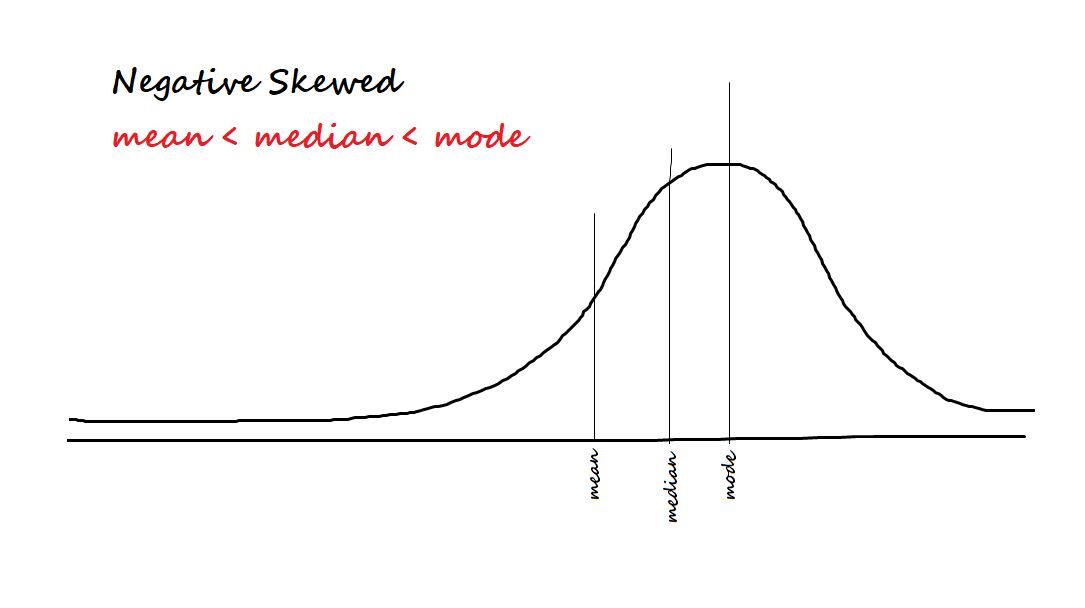
Mide la asimetría en los datos. Los dos tipos de asimetría son:
Positivo / sesgado a la derecha: Se dice que los datos están sesgados positivamente si la mayoría de los datos se concentran en el lado izquierdo y tienen una cola hacia la derecha.
Negativo / sesgado a la izquierda: Se dice que los datos están sesgados negativamente si la mayoría de los datos se concentran en el lado derecho y tienen una cola hacia la izquierda.
La fórmula de la asimetría es mi [(X – µ)/ σ ]) 3 = Z3
4.4. Curtosis
(También se conoce como decisión comercial del cuarto momento)
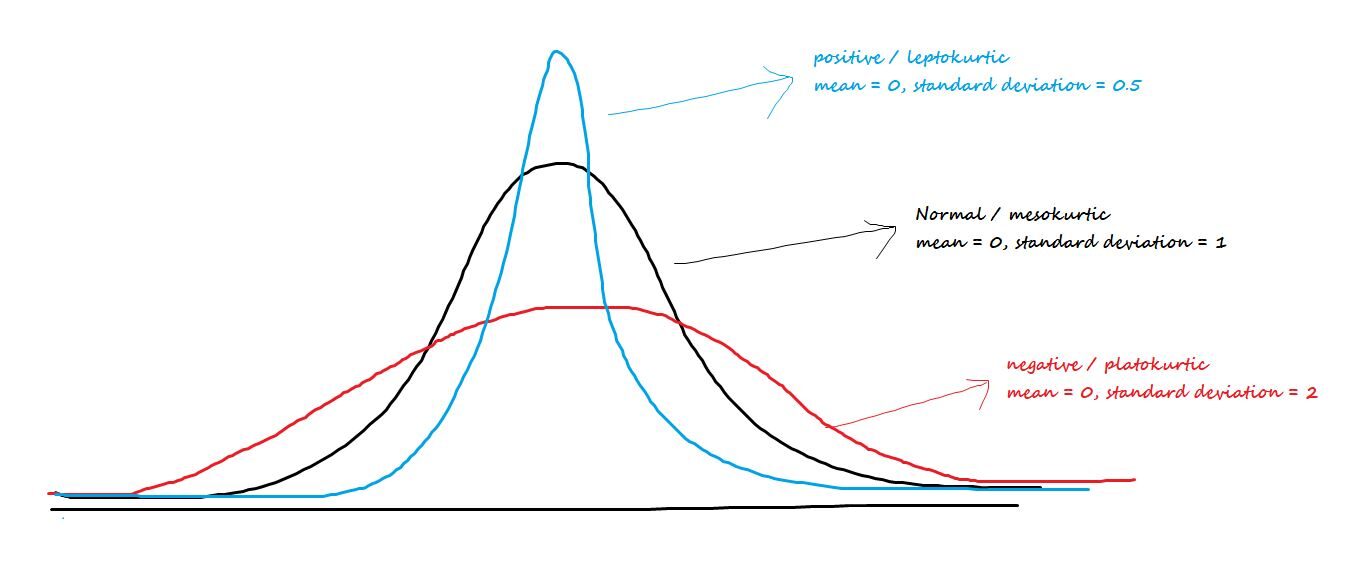
Habla sobre el pico central o la gordura de las colas. Los tres tipos de curtosis son:
Positivo / leptocúrtico: Tiene picos afilados y colas más claras.
Negativo / Platokúrtico: Tiene picos anchos y colas más gruesas.
Mesocúrtico: Distribución normal
La fórmula de la curtosis es mi [(X – µ)/ σ ]) 4-3 = Z4– 3
Juntos, la asimetría y la curtosis se denominan estadísticas de forma.
5. Teorema del límite central (CLT)
En lugar de analizar los datos de toda la población, siempre sacamos una muestra para su análisis. El problema con el muestreo es que “la media de la muestra es una variable aleatoria, varía para diferentes muestras”. Y la muestra aleatoria que extraemos nunca puede ser una representación exacta de la población. Este fenómeno se denomina variación muestral.
Para anular la variación muestral, usamos el teorema del límite central. Y de acuerdo con el teorema del límite central:
1. La distribución de las medias muestrales sigue una distribución normal si la población es normal.
2. la distribución de las medias muestrales sigue una distribución normal aunque la población no sea normal. Pero el tamaño de la muestra debería ser lo suficientemente grande.
3. El gran promedio de todos los valores medios muestrales nos da la media poblacional.
4. Teóricamente, el tamaño de la muestra debería ser 30. Y prácticamente, la condición sobre el tamaño de la muestra (n) es:
n> 10 (k3)2, donde k3 es la asimetría de la muestra.
n> 10 (k4), donde K4 es la muestra de curtosis.
6. Distribuciones de probabilidad
En términos estadísticos, una función de distribución es una expresión matemática que describe la probabilidad de diferentes resultados posibles para un experimento.
Por favor, lea este artículo mío sobre los diferentes tipos de distribuciones de probabilidad.
7. Representaciones gráficas
La representación gráfica se refiere al uso de tablas o gráficos para visualizar, analizar e interpretar datos numéricos.
Para una sola variable (análisis univariante), tenemos un diagrama de barras, un diagrama de líneas, un diagrama de frecuencia, un diagrama de puntos, un diagrama de caja y el diagrama de QQ normal.
Discutiremos el diagrama de caja y el diagrama de QQ normal.
7.1. Diagrama de caja
Un diagrama de caja es una forma de visualizar la distribución de datos basada en un resumen de cinco números. Se utiliza para identificar los valores atípicos en los datos.
Los cinco números son mínimo, primer cuartil (Q1), mediana (Q2), tercer cuartil (Q3) y máximo.
La región de la caja contendrá el 50% de los datos. El 25% inferior de la región de datos se denomina Bigote inferior y el 25% superior de la región de datos se denomina Bigote superior.
La región intercuartil (IQR) es la diferencia entre el tercer y el primer cuartil. IQR = Q3 – Q1.
Los valores atípicos son los puntos de datos que se encuentran debajo del bigote inferior y más allá del bigote superior.
La fórmula para encontrar los valores atípicos es Valor atípico = Q ± 1,5 * (IQR)
Los valores atípicos que se encuentran debajo del bigote inferior se dan como Q1 – 1,5 * (IQR)
Los valores atípicos que se encuentran más allá del bigote superior se dan como Q3 + 1.5 * (IQR)
Consulte mi artículo sobre la detección de valores atípicos mediante un diagrama de caja.
7.2. Gráfico QQ normal
Un diagrama de QQ normal es una especie de diagrama de dispersiónEl diagrama de dispersión es una herramienta gráfica utilizada en estadística para visualizar la relación entre dos variables. Consiste en un conjunto de puntos en un plano cartesiano, donde cada punto representa un par de valores correspondientes a las variables analizadas. Este tipo de gráfico permite identificar patrones, tendencias y posibles correlaciones, facilitando la interpretación de datos y la toma de decisiones basadas en la información visual presentada.... que se traza creando dos conjuntos de cuantiles. Se utiliza para comprobar si los datos siguen la normalidad o no.
En el eje x tenemos las puntuaciones Z y en el eje y tenemos los cuantiles de muestra reales. Si el diagrama de dispersión forma una línea recta, se dice que los datos son normales.
8. Prueba de hipótesis
La prueba de hipótesis en estadística es una forma de probar las suposiciones hechas sobre los parámetros de la población.
Consulta mi artículo sobre pruebas de hipótesis para leerlo en detalle.
Notas finales:
Gracias por leer hasta la conclusión. Al final de este artículo, estamos familiarizados con los conceptos estadísticos importantes.
Espero que este artículo sea informativo. No dudes en compartirlo con tus compañeros de estudio.
Otras publicaciones de blog mías
No dude en consultar mis otras publicaciones de blog de mi perfil de DataPeaker.
Puedes encontrarme en LinkedIn, Gorjeo en caso de que desee conectarse. Me encantaría conectarme contigo.
Para un intercambio inmediato de pensamientos, escríbame a [email protected].
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





