Este post fue hecho público como parte del Blogatón de ciencia de datos
Introducción
muestreo para obtener la probabilidad de un rango de una cantidad desconocida. ¡Suena dificil! no se preocupe, exploraremos esto en profundidad en este post
Una breve historia:
El Método Monte Carlo fue inventado por John Neumann y Ulam Stanislaw para impulsar la toma de decisiones en condiciones inciertas. Lleva el nombre de una conocida ciudad de casinos de Montecarlo llamada Mónaco, dado que el elemento de azar es fundamental para el enfoque de modelado, dado que es semejante a un juego de ruleta.
En palabras sencillas, la simulación de Monte Carlo es un método de estimando el valor de un cantidad desconocida con la ayuda de estadísticas inferenciales. No es necesario profundizar en las estadísticas inferenciales para tener una sólida comprensión del funcionamiento de la simulación de Monte Carlo. A pesar de esto, este post pasará únicamente por aquellos puntos de la estadística inferencial que serán relevantes para nosotros en la simulación de Monte Carlo.
La estadística inferencial se encarga de la población que es nuestro conjunto de ejemplos y muestra, que es un subconjunto adecuado de la población. El punto clave a prestar atención es que una muestra aleatoria tiende a exhibir lo mismo características / propiedad como la población de la que se extrae.
Veremos un ejemplo para comprender el funcionamiento de la simulación de Monte Carlo.
Nuestro objetivo es estimar qué probabilidades hay de salir adelante si lanzamos una moneda un número infinito de veces.
1. Digamos que le damos la vuelta una vez y nos adelantamos. ¿Estaremos seguros de decir que nuestra respuesta es 1?
2. Ahora volvimos a lanzar la moneda y volvió a aparecer la cara. ¿Estamos seguros de que el próximo lanzamiento además estará por delante?
3. Lo volteamos una y otra vez, digamos 100 veces, y extrañamente aparece la cabeza cada vez. Ahora, ¿tenemos que aceptar el hecho de que el próximo giro resultará en otra cabeza?
4. Cambiemos el escenario y supongamos que de 100 lanzamientos, 52 dieron como consecuencia que la cabeza descansara, 48 se convirtieron en cruces. ¿La probabilidad de que el próximo lanzamiento resulte en la cabeza es 52/100? Dada la observación, es nuestra mejor estimación, pero la confianza seguirá siendo baja.
¿Por qué hay una diferencia en el nivel de confianza?
Es esencial saber que nuestra estimación depende de dos cosas
1. Tamaño: el tamaño de la muestra (a modo de ejemplo, 100 vs 2 en los casos 2 y 4 respectivamente)
2. Diferencia: varianza de la muestra (todos los resultados como cabeza frente a 52 cabezas como en el caso 3 y 4 respectivamente)
3. A medida que aumenta la varianza de la observación (casos 3 y 4), surge la necesidad de una observación más extensa (como en los casos 2 y 4) para tener el mismo grado de confianza.
Ahora estaremos simulando un juego de ruleta (python):
Ruleta es un juego en el que un disco con bloques (mitad rojo y mitad negro) en el que se puede contener una bola, gira con una bola. Necesitamos adivinar un número y si la bola cae en este número, entonces es una victoria, y ganamos una cantidad de (monto pagado por una ranura
) X (no. De ranuras totales en la máquina).
class Roulette():
def __init__(self):
self.pockets = []
for i in range(1,37):
self.pockets.append(i)
self.ball = None
self.pocketOdds = len(self.pockets) - 1
def spin(self):
self.ball = random.choice(self.pockets)
def betPocket(self, pocket, amt):
if str(pocket) == str(self.ball):
return amt*self.pocketOdds
else: return -amt
def __str__(self):
return 'Fair Roulette'
def playRoulette(game, numSpins, pocket, bet):
totPocket = 0
for i in range(numSpins):
game.spin()
totPocket += game.betPocket(pocket, bet)
if toPrint:
print (numSpins, 'spins of', game)
print ('Expected return betting', pocket, '=',
str(100*totPocket/numSpins) + '%n')
return (totPocket/numSpins)
game = Roulette()
for numSpins in (100, 1000000):
for i in range(3):
playRoulette(game, numSpins, 5, 1, True)
100 giros de ruleta
Apuestas de retorno esperado 5 = -100.0%
100 giros de ruleta
Apuestas de retorno esperado 5 = 42.0%
100 giros de ruleta
Apuestas de retorno esperado 5 = -26.0%
1000000 giros de ruleta
Apuestas de retorno esperado 5 = -0,0546%
1000000 giros de ruleta
Apuestas de retorno esperado 5 = 0,502%
1000000 giros de ruleta
Apuestas de retorno esperado 5 = 0,7764%
Ley de los números grandes
En pruebas independientes repetidas con la probabilidad constante p de la población de un resultado particular en cada prueba, la probabilidad de que el resultado ocurra, dicho de otra forma, obtenida de las muestras. difiere de p converge a cero como el el número de ensayos va al infinito.
Simplemente significa que si se producen desviaciones (varianza) del comportamiento esperado (probabilidad p), es probable que en el futuro estas desviaciones se compensen con la desviación opuesta.
Ahora hablemos de un incidente interesante que tuvo lugar el 18 de agosto de 1913, en un casino de Montecarlo. En la ruleta, el negro subió un récord veintiséis veces seguidas, y surgió el pánico para apostar al rojo (para igualar la desviación del comportamiento esperado)
Analicemos esta situación matemáticamente
1. Probabilidad de 26 rojos consecutivos = 1 / 67,108,865
2. Probabilidad de 26 rojos consecutivos cuando los 25 rollos anteriores fueron rojos = 1/2
Regresión a la media
1. Después de un evento aleatorio extremo, es probable que el siguiente evento aleatorio sea menos extremo, de modo que se mantenga la media.
2. A modo de ejemplo, si la rueda de la ruleta se gira 10 veces y los rojos vienen cada vez, entonces es un evento extremo = 1/1024 y es probable que en los próximos 10 giros obtengamos menos de 10 rojos, pero el número promedio es 5 solamente.
Entonces, cuando miramos la media de 20 giros, estará más cerca de la media esperada del 50% de rojos que del 100% en los primeros 10 giros.
Ahora es el momento de afrontar algo de realidad.
Espacio de muestreo de posibles resultados
1. No es factible garantizar una precisión perfecta a través de el muestreo y tampoco puede decirse que una estimación no sea exactamente correcta.
Nos enfrentamos a una pregunta aquí: ¿cuántas muestras se requieren para mirar antes de que podamos tener una confianza significativa en nuestra respuesta?
Depende de la variabilidad en la distribución subyacente.
Niveles de confianza e intervalos de confianza
Del mismo modo que en una situación de la vida real, no podemos estar seguros de ningún parámetro desconocido obtenido de una muestra para toda la población, por lo que utilizamos niveles de confianza e intervalos de confianza.
El intervalo de confianza proporciona un rango en el que es probable que el valor desconocido esté contenido con la confianza de que el valor desconocido se encuentra estrictamente dentro de ese rango.
A modo de ejemplo, el rendimiento de apostar en una tragamonedas 1000 veces en la ruleta es -3% con un margenEl margen es un término utilizado en diversos contextos, como la contabilidad, la economía y la impresión. En contabilidad, se refiere a la diferencia entre los ingresos y los costos, lo que permite evaluar la rentabilidad de un negocio. En el ámbito editorial, el margen es el espacio en blanco alrededor del texto en una página, que facilita la lectura y proporciona una presentación estética. Su correcta gestión es esencial... de error de +/- 4% con un nivel de confianza del 95%.
Se puede decodificar aún más a medida que realizamos una prueba infinita de 1000,
El rendimiento medio / medio esperado sería de -3%
El rendimiento variaría aproximadamente entre + 1% y -7% que además el 95% de las veces.
Función de densidad de probabilidad (PDF).
La distribución de forma general se establece a través de la función de densidad de probabilidad (PDF). Se establece como la probabilidad de que la variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.... aleatoria se encuentre entre un intervalo.
El área bajo la curva entre los dos puntos de PDF es la probabilidad de que la variable aleatoria se encuentre dentro de ese rango.
Concluyamos nuestro aprendizaje con un ejemplo:
Digamos que hay una baraja de cartas barajadas y necesitamos hallar la probabilidad de obtener 2 reyes consecutivos si colocan las cartas en el orden en que están colocadas.
Método analítico:
P (al menos 2 reyes consecutivos) = 1-P (sin reyes consecutivos)
= 1- (49! X 48!) / ((49-4)! X52!) = 0.217376
Por simulación de Monte Carlo:
Pasos
1. Seleccione repetidamente los puntos de datos aleatorios: aquí asumimos que el barajado de las cartas es aleatorio
2. Realización de cálculos deterministas. Varios de estos barajar y hallar los resultados.
3. Combinar los resultados: Explorando el resultado y terminando con nuestra conclusión.
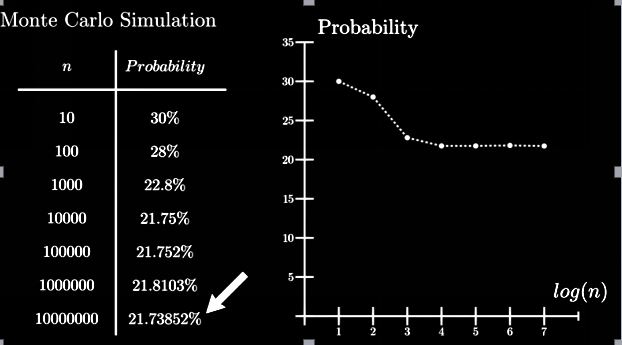
A través de el método de Monte Carlo logramos una solución casi exacta a partir del método analítico.
Ventajas de la simulación Monte Carlo
- Fácil de poner en práctica y proporciona muestreo estadístico para experimentos numéricos usando la computadora.
- Nos proporciona soluciones aproximadas satisfactorias a problemas matemáticos computacionalmente costosos.
- Puede utilizarse tanto para problemas deterministas como estocásticos.
Desventajas de la simulación Monte Carlo
- A veces lleva mucho tiempo, dado que tenemos que generar una gran cantidad de muestreos para obtener el resultado satisfactorio deseado.
- Los resultados obtenidos con este método son solo la aproximación de la respuesta verdadera y no la respuesta exacta.
Sobre el Autor
Soy Dinesh Junjariya, un estudiante de Btech del IIT Jodhpur.
Para cualquier sugerencia, comente a continuación.
Los medios que se muestran en este post no son propiedad de DataPeaker y se usan a discreción del autor.





