Introducción
El formato PDF o archivo de documento portátil es uno de los formatos de archivo más comunes actualmente. Se utiliza ampliamente en todas las industrias, como en oficinas gubernamentales, atención médica e inclusive en el trabajo personal. Como consecuencia, existe una gran cantidad de datos no estructurados que existen en formato PDF y extraer estos datos para generar información significativa es un trabajo común entre los científicos de datos.
Hay varias bibliotecas de Python dedicadas a trabajar con documentos PDF como PYPDF2, etc. En este tutorial, usaré Camelot.

¿Por qué Camelot?
- Usted tiene el control: a diferencia de otras bibliotecas y herramientas que brindan un buen resultado o fallan miserablemente (sin intermediarios), Camelot le brinda el poder de modificar la extracción de tablas. (Esto es esencial puesto que todo en el mundo real, incluida la extracción de tablas PDF, es confuso).
- Malo las tablas se pueden descartar en función de métricas como la precisión y los espacios en blanco, sin tener que mirar manualmente cada tabla.
- Cada tabla es un DataFrame de pandas, que se integra a la perfección en Flujos de trabajo de análisis de datos y ETL.
- Exporte a múltiples formatos, incluidos JSONJSON, o JavaScript Object Notation, es un formato ligero de intercambio de datos que es fácil de leer y escribir para los humanos, y fácil de analizar y generar para las máquinas. Se utiliza comúnmente en aplicaciones web para enviar y recibir información entre un servidor y un cliente. Su estructura se basa en pares de clave-valor, lo que lo hace versátil y ampliamente adoptado en el desarrollo de software..., Excel, HTML y Sqlite.
Vamos a comenzar
Antes de instalar las bibliotecas de Camelot tenemos que instalar guión fantasma , una vez que instalemos el script fantasma, instalemos camelot-py.
Ejecutar debajo de los comandos :
pip install "camelot-py[cv]"
Una vez que haya instalado la biblioteca camelot-py, estaremos listos para comenzar. Estamos tratando de extraer una tabla de ingresos de GST a nivel estatal de este documento pdf.
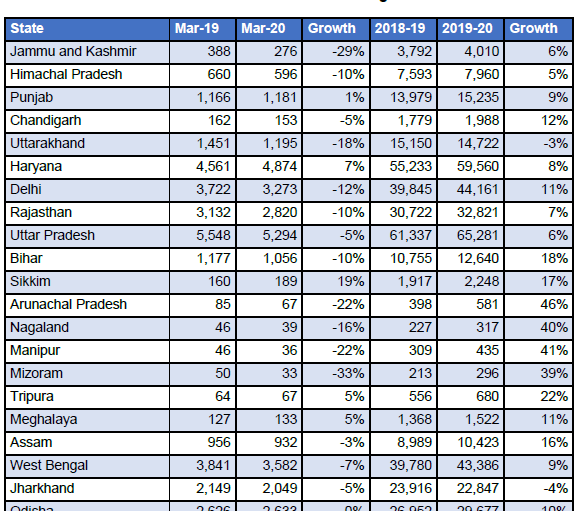
Tabla pdf
import camelot
Si tiene camelot, Python no imprimirá un mensaje de error, y si no, verá un ImportError.
# Syntax of the camelot.read_pdf function
camelot.read_pdf(
filepath,
pages='1',
password=None,
flavor='lattice',
suppress_stdout=False,
layout_kwargs={},
**kwargs,
)
Si tiene que extraer una tabla de diferentes páginas, debe dar el número de página.
tables2=camelot.read_pdf('gst-revenue-collection-march2020.pdf', flavor="stream", pages="0-3")
tables2
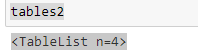
Esto le dará una lista total de la Tabla que está allí en un documento pdf. podemos elegir una tabla pasando el índiceEl "Índice" es una herramienta fundamental en libros y documentos, que permite ubicar rápidamente la información deseada. Generalmente, se presenta al inicio de una obra y organiza los contenidos de manera jerárquica, incluyendo capítulos y secciones. Su correcta elaboración facilita la navegación y mejora la comprensión del material, convirtiéndolo en un recurso esencial tanto para estudiantes como para profesionales en diversas áreas.....
tables2[2] # 2 is the index
tables2[2].parsing_report

El código anterior le proporcionará detalles como la precisión y el número de página. Tenga en cuenta que hay 2 páginas.
El siguiente código extraerá la tabla del documento pdf.
df2=tables2[2].df
df2
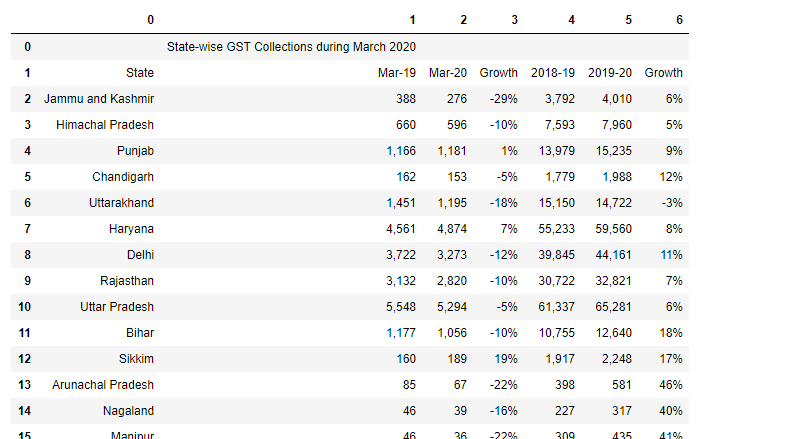
En esta circunstancia, debido a que la tabla está dividida en dos páginas diferentes. Entonces podemos hacer una solución.
tables2[3]
tables2[3].parsing_report

Aquí se puede notar, extraemos la tabla de la página no 3.
df3=tables2[3].df
df3
El siguiente es el código para agregar df2 y df3.
df4=df2.append(df3)
df4
df5=df4[1:] df5.head() new_header = df5.iloc[0]df5 = df5[1:]df5.columns = new_header
Aquí tienes, hemos extraído una tabla de pdf, ahora podemos exportar estos datos en cualquier formato al sistema local.
Conclusión
Extraer datos tabulares de pdf con la ayuda de la biblioteca camelot es verdaderamente fácil. Al mismo tiempo, sabemos que hay una gran cantidad de datos no estructurados en formato pdf y, después de extraer las tablas, podemos hacer muchos análisis y visualización en función de sus necesidades comerciales.
Espero que este post te ayude y te ahorre una buena cantidad de tiempo. Déjame saber si dispones de alguna sugerencia.
FELIZ CODIFICACIÓN.
Sobre el Autor

Prabhat Kumar – Analista asociado
Soy un ingeniero que hoy en día trabaja en las principales compañías multinacionales como analista asociado y entusiasta de la innovación, me encanta aprender cosas nuevas, creo que cada información dispone de una historia y me encanta leer las historias.
Prabhat Pathak (Perfil de Linkedin) es Analista Asociado.





