Este artículo fue publicado como parte del Blogatón de ciencia de datos
Este artículo se centra en Apache PigEl cerdo, un mamífero domesticado de la familia Suidae, es conocido por su versatilidad en la agricultura y la producción de alimentos. Originario de Asia, su cría se ha extendido por todo el mundo. Los cerdos son omnívoros y poseen una alta capacidad de adaptación a diversos hábitats. Además, juegan un papel importante en la economía, proporcionando carne, cuero y otros productos derivados. Su inteligencia y comportamiento social también son.... Es una plataforma de alto nivel para procesar y analizar una gran cantidad de datos.
VISIÓN DE CONJUNTO
Si vemos la descripción general de nivel superior de Pig, Pig es una abstracción de MapReduceMapReduce es un modelo de programación diseñado para procesar y generar grandes conjuntos de datos de manera eficiente. Desarrollado por Google, este enfoque Divide el trabajo en tareas más pequeñas, las cuales se distribuyen entre múltiples nodos en un clúster. Cada nodo procesa su parte y luego se combinan los resultados. Este método permite escalar aplicaciones y manejar volúmenes masivos de información, siendo fundamental en el mundo del Big Data..... Pig se ejecuta en Hadoop. Por lo tanto, utiliza tanto el sistema de archivos distribuidoUn sistema de archivos distribuido (DFS) permite el almacenamiento y acceso a datos en múltiples servidores, facilitando la gestión de grandes volúmenes de información. Este tipo de sistema mejora la disponibilidad y la redundancia, ya que los archivos se replican en diferentes ubicaciones, lo que reduce el riesgo de pérdida de datos. Además, permite a los usuarios acceder a los archivos desde distintas plataformas y dispositivos, promoviendo la colaboración y... de Hadoop (HDFSHDFS, o Sistema de Archivos Distribuido de Hadoop, es una infraestructura clave para el almacenamiento de grandes volúmenes de datos. Diseñado para ejecutarse en hardware común, HDFS permite la distribución de datos en múltiples nodos, garantizando alta disponibilidad y tolerancia a fallos. Su arquitectura se basa en un modelo maestro-esclavo, donde un nodo maestro gestiona el sistema y los nodos esclavos almacenan los datos, facilitando el procesamiento eficiente de información...) como el sistema de procesamiento de Hadoop, MapReduce. Se ejecutan los flujos de datos
por un motor. Se utiliza para analizar conjuntos de datos como flujos de datos. Incluye un lenguaje de alto nivel llamado Pig Latin para expresar estos flujos de datos.
La entrada para Pig es Pig Latin, que se convertirá en trabajos de MapReduce. Pig usa trucos de MapReduce para hacer todo el procesamiento de datos. Combina los scripts de Pig Latin en una serie de uno o más trabajos de MapReduce que a su vez se ejecutan.
Apache Pig fue diseñado por Yahoo porque es fácil de aprender y trabajar con él. Entonces, Pig hace que Hadoop sea bastante fácil. Apache Pig se desarrolló porque la programación de MapReduce se estaba volviendo bastante difícil y muchos usuarios de MapReduce no se sienten cómodos con los lenguajes declarativos. Ahora, Pig es un proyecto de código abierto bajo Apache.
TABLA DE CONTENIDO
- Características del cerdo
- Cerdo vs MapReduce
- Arquitectura de cerdo
- Opciones de ejecución de cerdo
- Comandos de ejecución básicos de Pig
- Tipos de datos de cerdo
- Operadores de cerdos
- Ejemplo de escritura latina de cerdo
1. CARACTERÍSTICAS DEL CERDO
Veamos algunas de las características de Pig.
- Tiene un rico conjunto de operadores como unir, ordenar, etc.
- Es fácil de programar ya que es similar a SQL.
- Las tareas en Apache Pig se han convertido en trabajos de MapReduce automáticamente. Los programadores deben centrarse solo en la semántica del lenguaje y no en MapReduce.
- Se pueden crear funciones propias usando Pig.
- Las funciones en otros lenguajes de programación como Java se pueden incrustar en los scripts Pig Latin.
- Apache Pig puede manejar
todo tipo de datos, como datos estructurados, no estructurados y semiestructurados y
almacena el resultado en HDFS.
2. CERDO VS MAPREDUCE
Veamos la diferencia entre Pig y MapReduce.
Pig tiene varias ventajas sobre MapReduce.
Apache Pig es un lenguaje de flujo de datos. Significa que permite a los usuarios describir cómo se deben leer, procesar y luego almacenar los datos de una o más entradas en una o más salidas en paralelo. Mientras que MapReduce, por otro lado, es un estilo de programación.
Apache Pig es un lenguaje de alto nivel, mientras que MapReduce es un código java compilado.
La sintaxis de Pig para realizar uniones y varios archivos es muy intuitiva y bastante simple como SQL. Código MapReduce
se vuelve complejo si desea escribir operaciones de unión.
La curva de aprendizaje de Apache Pig es muy pequeña. La experiencia en bibliotecas Java y MapReduce es imprescindible
para ejecutar el código MapReduce.
Los scripts de Apache Pig pueden hacer el equivalente a varias líneas de código MapReduce y el código MapReduce necesita más líneas de códigos para realizar las mismas operaciones.
Apache Pig es fácil de depurar y probar, mientras que los programas MapReduce requieren mucho tiempo para codificar, probar, etc. Pig Latin es menos costoso que MapReduce.
3. ARQUITECTURA PORCINA
Ahora veamos la arquitectura de Pig.
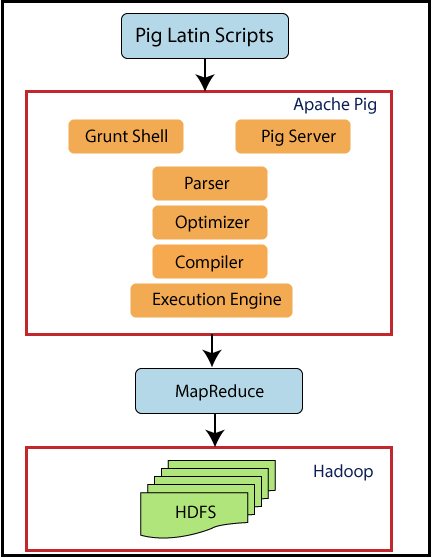
Pig se sienta encima de Hadoop. Los scripts de Pig se pueden ejecutar en el shell Grunt o en el servidor Pig. El motor de ejecución de Pig the Pass optimiza y compila el script y finalmente lo convierte en trabajos MapReduce. Utiliza HDFS para almacenar datos intermedios entre trabajos de MapReduce y luego escribe su salida en HDFS.
4. OPCIONES DE EJECUCIÓN DE CERDOS
Apache Pig puede ejecutar dos modos de ejecución. Ambos producen los mismos resultados.
4.1. Modo local
Comando en pasarelas
pig -x local
4.2. Modo Hadoop
Comando en pasarelas
pig -exectype mapreduce
Apache Pig se puede ejecutar de tres formas en los dos modos anteriores.
- Modo por lotes / archivo de secuencia de comandos: coloque los comandos de Pig en un archivo de secuencia de comandos y ejecute la secuencia de comandos
- Programa incrustado / UDF: incrustar comandos de Pig en java y ejecutar los scripts
5. COMANDOS DE CONCHA DE GRUNT DE CERDO
Las conchas grunt se pueden usar para escribir escrituras de Pig Latin. Los comandos del shell se pueden invocar mediante los comandos fs y sh. Veamos algunos básicos
Comandos de cerdo.
5.1. comando fs
El comando fs le permite ejecutar comandos HDFS desde Pig
5.1.1 Para enumerar todos los directorios en HDFS
grunt> fs -ls;
Ahora, se mostrarán todos los archivos en HDFS.
5.1.2. Para crear un nuevo directorio mydir en HDFS
grunt> fs -mkdir mydir/;
El comando anterior creará un nuevo directorio llamado mydir en HDFS.
5.1.3. Para eliminar un directorio
grunt> fs -rmdir mydir;
El comando anterior eliminará el directorio creado mydir.
5.1.4. Para copiar un archivo a HDFS
grant> fs -put sales.txt sales/;
Aquí, el archivo llamado sales.txt es el archivo de origen que se copiará al directorio de destino en HDFS, es decir, ventas.
5.1.5. Para salir de Grunt Shell
grunt> quit;
El comando anterior saldrá del grunt shell.
5.2. comando sh
El comando sh le permite ejecutar una declaración de Unix desde Pig
5.2.1. Para mostrar la fecha actual
grunt> sh date;
Este comando mostrará la fecha actual.
5.2.2. Para enumerar archivos locales
grunt> sh ls;
Este comando mostrará todos los archivos en el sistema local.
5.2.3. Para ejecutar Pig Latin desde grunt shell
grunt> run salesreport.pig;
El comando anterior ejecutará un archivo de script de Pig Latin «salesreport.pig» desde el shell de grunt.
5.2.4. Para ejecutar Pig Latin desde el indicador de Unix
$pig salesreport.pig;
El comando anterior ejecutará un archivo de script de Pig Latin “salesreport.pig” desde el indicador de Unix.
6. P
Pig Latin consta de los siguientes tipos de datos.
6.1. Átomo de datos
Es un valor único. Puede ser una cadena o un número. Son de tipos escalares como int, float, double, etc.
Por ejemplo, «john», 9.0
6.2. Tupla
Una tupla es similar a un registro con una secuencia de campos. Puede ser de cualquier tipo de datos.
Por ejemplo, (‘john’, ‘james’) es una tupla.
6.3. Bolsa de datos
Consiste en una colección de tuplas que es equivalente a una «tabla» en SQL. Las tuplas no son únicas y pueden tener un número arbitrario de campos, cada uno puede ser de cualquier tipo.
Por ejemplo, {(‘john’, ‘James), (‘ king ‘,’ mark ‘)} es una bolsa de datos que es equivalente a la siguiente tabla en SQL.
6.4. Mapa de datos
Este tipo de datos
contiene una colección de pares clave-valor. Aquí, la clave debe ser un carácter único. Los valores pueden ser de cualquier tipo.
Por ejemplo, [name#(‘john’, ‘james’), age#22] es un mapa de datos donde nombre, edad son claves y (‘john,’ james ‘), 22 son valores.
7. OPERADORES DE CERDOS
A continuación se muestra el contenido del archivo student.txt.
John,23,Hyderabad James,45,Hyderabad Sam,33,Chennai ,56,Delhi ,43,Mumbai
7.1. CARGA
Carga datos del sistema de archivos dado.
A = LOAD 'student.txt' AS (name: chararray, age: int, city: chararray);
Los datos del archivo del estudiante con nombres de columna como ‘nombre’, ‘edad’, ‘ciudad’ se cargarán en una variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.... A.
7.2. VERTEDERO
El operador DUMP se utiliza para mostrar el contenido de una relación. Aquí, se mostrará el contenido de A.
DUMP A //results (John,23,Hyderabad) (James,45,Hyderabad) (Sam,33,Chennai) (,56,Delhi) (,43,Mumbai)
7.3. TIENDA
La función de almacenamiento guarda los resultados en el sistema de archivos.
STORE A into ‘myoutput’ using PigStorage(‘*’);
Aquí, los datos presentes en A se almacenarán en myoutput separados por ‘*’.
DUMP myoutput; //results John*23*Hyderabad James*45*Hyderabad Sam*33*Chennai *56*Delhi *43*Mumbai
7.4. FILTRAR
B = FILTER A by name is not null;
El operador de FILTRO filtrará una tabla con algunas condiciones. Aquí, el nombre es la columna en A. Los valores no vacíos en el nombre se almacenarán en la variable B.
DUMP B; //results (John,23,Hyderabad) (James,45,Hyderabad) (Sam,33,Chennai)
7.5. PARA CADA UNO GENERAR
C = FOREACH A GENERATE name, city;
FOREACH operador está acostumbrado a acceder a registros individuales. Aquí, las filas presentes en el nombre y la ciudad se obtendrán de A y se almacenarán en C.
DUMP C //results (John,Hyderabad) (James,Hyderabad) (Sam,Chennai) (,Delhi) (,Mumbai)
8. EJEMPLO DE GUIÓN LATINA DE PIG
Tenemos un archivo de personas que tiene como campos la identificación del empleado, el nombre y las horas.
001,Rajiv,21 002,siddarth,12 003,Rajesh,22
Primero, cargue estos datos en un empleado variable. Filtrarlo por horas menos de 20 y almacenar a tiempo parcial. Ordene part time por orden descendente y guárdelo en otro archivo llamado part_time. Visualice el contenido.
El guión será
employee = Load ‘people’ as (empid, name, hours); parttime = FILTER employee BY Hours < 20; sorted = ORDER parttime by hours DESC; STORE sorted INTO ‘part_time’; DUMP sorted; DESCRIBE sorted; //results (003,Rajesh,22) (001,Rajiv,21)
NOTAS FINALES
Estos son algunos de los conceptos básicos de Apache Pig. Espero que hayas disfrutado leyendo este artículo. Empezar a practicar
con el entorno Cloudera.
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.






{kind=link}