Introducción
Muy a menudo, utilizamos la verificación de datos y la validación de datos de manera intercambiable cuando hablamos de calidad de datos. Sin embargo, estos dos términos son distintos. En este artículo, entenderemos la diferencia en 4 contextos diferentes:
- Diccionario de significado de verificación y validación
- Diferencia entre verificación de datos y validación de datos en general
- Diferencia entre verificación y validación desde una perspectiva de desarrollo de software
- Diferencia entre verificación de datos y validación de datos desde una perspectiva de aprendizaje automático
1) Diccionario de significado de verificación y validación
La Tabla 1 explica el significado del diccionario de las palabras verificación y validación con algunos ejemplos.
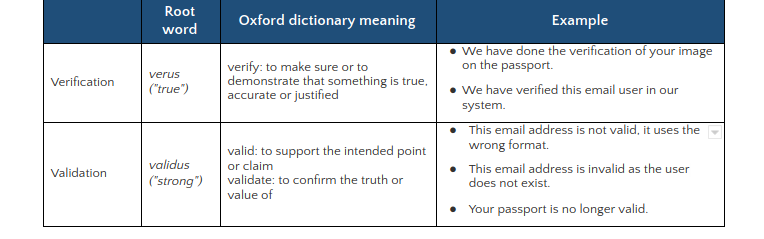
En resumen, la verificación se trata de veracidad y precisión, mientras que la validación se trata de respaldar la solidez de un punto de vista o la exactitud de una afirmación. La validación comprueba la exactitud de una metodología, mientras que la verificación comprueba la exactitud de los resultados.
2) Diferencia entre verificación de datos y validación de datos en general
Ahora que entendemos el significado literal de las dos palabras, exploremos la diferencia entre «verificación de datos» y «validación de datos».
Verificación de datos: para asegurarse de que los datos sean precisos.
Validación de datos: para asegurarse de que los datos sean correctos.
Desarrollemos con ejemplos en la Tabla 2.

Tabla 2: «Verificación de datos» y «validación de datos» ejemplos
3) Diferencia entre verificación y validación desde una perspectiva de desarrollo de software
Desde una perspectiva de desarrollo de software,
- La verificación se realiza para garantizar que el software sea de alta calidad, bien diseñado, robusto y sin errores sin entrar en su usabilidad.
- La validación se realiza para garantizar la usabilidad y la capacidad del software para satisfacer las necesidades del cliente.
Como se muestra en la Figura"Figura" es un término que se utiliza en diversos contextos, desde el arte hasta la anatomía. En el ámbito artístico, se refiere a la representación de formas humanas o animales en esculturas y pinturas. En la anatomía, designa la forma y estructura del cuerpo. Además, en matemáticas, "figura" se relaciona con las formas geométricas. Su versatilidad hace que sea un concepto fundamental en múltiples disciplinas.... 1, la prueba de corrección, análisis de robustez, pruebas unitarias, pruebas de integración y otros son todos verificación Pasos donde las tareas están orientadas a verificar detalles. La salida del software se verifica con la salida deseada. Por otro lado, la inspección del modelo, las pruebas de caja negra y las pruebas de usabilidad son todas validación Pasos donde las tareas están orientadas a entender si el software cumple con los requisitos y expectativas.
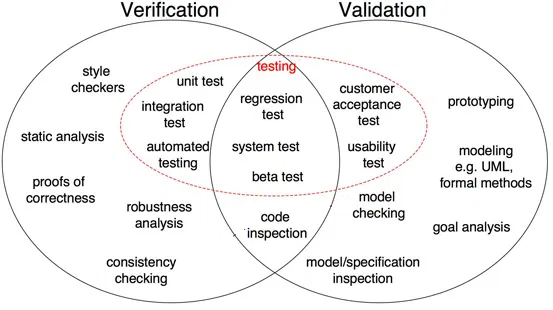
Fig 1: Diferencias entre verificación y validación en el desarrollo de software
4) Diferencia entre verificación de datos y validación de datos desde una perspectiva de aprendizaje automático
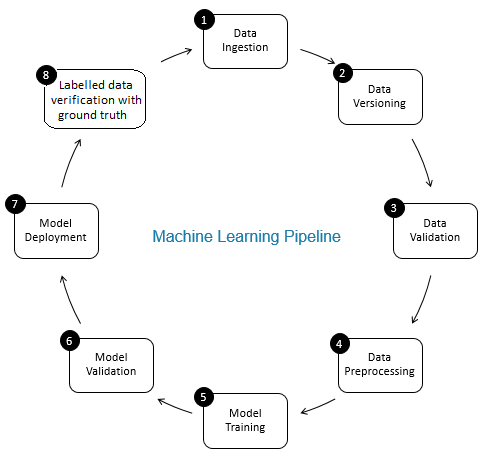
El papel de verificación de datos en el proceso de aprendizaje automático es el de un guardián. Eso asegura datos precisos y actualizados tiempo extraordinario. La verificación de datos se realiza principalmente en la nueva etapa de adquisición de datos, es decir, en el paso 8 de la canalización de ML, como se muestra en la Fig. 2. Ejemplos de este paso son identificar registros duplicados y realizar la deduplicación, y limpiar la discrepancia en la información del cliente en campos como dirección o número de teléfono.
Por otra parte, validación de datos (en el paso 3 de la canalización de ML) asegura que los datos incrementales del paso 8 que se agregan a los datos de aprendizaje sean de buena calidad y similares (desde una perspectiva de propiedades estadísticas) a los datos de entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina.... existentes. Por ejemplo, esto incluye encontrar anomalías en los datos o detectando diferencias entre los datos de entrenamiento existentes y los datos nuevos para agregar a los datos de entrenamiento. De lo contrario, cualquier problema de calidad de los datos / diferencias estadísticas en los datos incrementales puede perderse y el entrenamiento los errores pueden acumularse con el tiempo y deteriorar la precisión del modelo. Por tanto, la validación de datos detecta cambios significativos (si los hay) en los datos de entrenamiento incrementales en una etapa temprana que ayuda con el análisis de la causa raíz.
Autores:
1. Aditya Agarwal: Aditya Aggarwal se desempeña como Ciencia de datos – Líder de práctica en Abzooba Inc. Con más de 12 años de experiencia en impulsar objetivos comerciales a través de soluciones basadas en datos, Aditya se especializa en análisis predictivo, aprendizaje automático, inteligencia comercial y estrategia comercial. en una variedad de industrias. Como líder de práctica de análisis avanzado en Abzooba, Aditya lidera un equipo de más de 50 profesionales de la ciencia de datos enérgicos en Abzooba que están resolviendo problemas comerciales interesantes utilizando el aprendizaje automático, el aprendizaje profundoEl aprendizaje profundo, una subdisciplina de la inteligencia artificial, se basa en redes neuronales artificiales para analizar y procesar grandes volúmenes de datos. Esta técnica permite a las máquinas aprender patrones y realizar tareas complejas, como el reconocimiento de voz y la visión por computadora. Su capacidad para mejorar continuamente a medida que se le proporcionan más datos la convierte en una herramienta clave en diversas industrias, desde la salud..., el procesamiento del lenguaje natural y la visión por computadora. Proporciona liderazgo intelectual en IA a los clientes para traducir sus objetivos comerciales en problemas analíticos y soluciones basadas en datos. Bajo su liderazgo, varias organizaciones han automatizado las tareas rutinarias, han reducido los costos operativos, han aumentado la productividad del equipo y han mejorado los ingresos de primera y última línea. Ha creado soluciones como el motor de subrogación, el motor de recomendación de precios, el mantenimiento predictivo del sensor de IoT y más. Aditya tiene una licenciatura en tecnología y una licenciatura en administración de empresas del Instituto Indio de Tecnología (IIT), Delhi.
2. Dr. Arnab Bose: el Dr. Arnab Bose es director científico de Abzooba, una empresa de análisis de datos, y profesor adjunto de la Universidad de Chicago, donde enseña aprendizaje automático y análisis predictivo, operaciones de aprendizaje automático, análisis de series de tiempo y Forecasting y Health Analytics en el programa de Maestría en Ciencias en AnalíticaLa analítica se refiere al proceso de recopilar, medir y analizar datos para obtener información valiosa que facilite la toma de decisiones. En diversos campos, como los negocios, la salud y el deporte, la analítica permite identificar patrones y tendencias, optimizar procesos y mejorar resultados. El uso de herramientas avanzadas y técnicas estadísticas es fundamental para transformar datos en conocimiento aplicable y estratégico..... Es un veterano de la industria de análisis predictivo de 20 años que disfruta del uso de datos estructurados y no estructurados para pronosticar e influir en los resultados del comportamiento en la atención médica, el comercio minorista, las finanzas y el transporte. Sus áreas de enfoque actuales incluyen la estratificación de riesgos para la salud y el manejo de enfermedades crónicas mediante el aprendizaje automático, y la implementación de producción y el monitoreo de modelos de aprendizaje automático. Arnab ha publicado capítulos de libros y artículos arbitrados en numerosas conferencias y revistas del Instituto de Ingenieros Eléctricos y Electrónicos (IEEE). Ha recibido la Mejor Presentación en la American Control Conference y ha impartido charlas sobre análisis de datos en universidades y empresas de EE. UU., Australia e India. Arnab tiene una maestría y un doctorado. grados en ingeniería eléctrica de la Universidad del Sur de California, y un B.Tech. en ingeniería eléctrica del Instituto Indio de Tecnología en Kharagpur, India.
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





