Introducción
«Los datos son el combustible de los algoritmos de aprendizaje automático».
Antes de buscar información a partir de los datos, primero tenemos que realizar tareas de preprocesamiento que luego solo nos permiten usar esos datos para una mayor observación y entrenar nuestro modelo de aprendizaje automático.
Se requiere la corrección del valor faltante para reducir el sesgo y producir modelos adecuados potentes. La mayoría de los algoritmos no pueden manejar los datos faltantes, por lo que debe actuar de alguna manera para simplemente no dejar que su código se bloquee. Entonces, comencemos con los métodos para resolver el problema.
Métodos para lidiar con valores perdidos
Ejemplo 1, Tengamos una conjunto de datos ficticios en el que hay tres características independientes (predictores) y una característica dependiente (respuesta).
| Característica-1 | Característica-2 | Característica-3 | Producción |
| Masculino | 23 | 24 | sí |
| – – – – | 24 | 25 | No |
| Mujer | 25 | 26 | sí |
| Masculino | 26 | 27 | sí |
Aquí, tenemos un valor faltante en la fila 2 para Feature-1.
Los métodos populares que utiliza la comunidad de aprendizaje automático para manejar el valor faltante de las variables categóricas en el conjunto de datos son los siguientes:
1. Elimine las observaciones: Si hay una gran cantidad de observaciones en el conjunto de datos, donde todas las clases que se van a predecir están suficientemente representadas en los datos de entrenamiento, intente eliminar las observaciones de valor que faltan, lo que no generaría cambios significativos en su feed de su modelo.
Por ejemplo, 1, Implementar este método en un conjunto de datos dado, podemos eliminar toda la fila que contiene los valores faltantes (eliminar la fila-2).
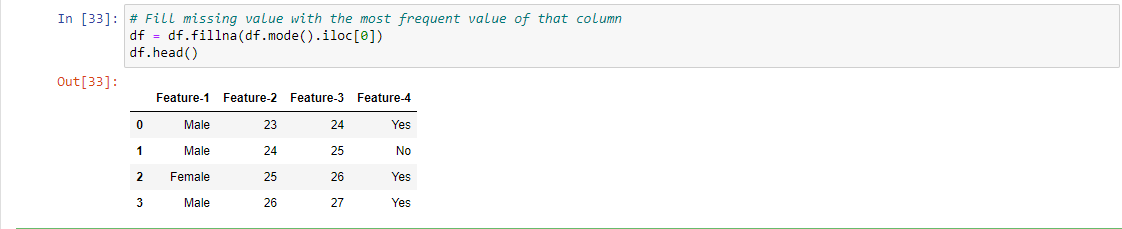
2. Reemplace los valores perdidos con el valor más frecuente: Siempre puede imputarlos basándose en Modo en el caso de variables categóricas, asegúrese de no tener distribuciones de clases muy sesgadas.
NOTA: Pero en algunos casos, esta estrategia puede hacer que los datos estén desequilibrados en las clases wrt si hay una gran cantidad de valores faltantes presentes en nuestro conjunto de datos.
– Generalmente, reemplazar los valores perdidos con la media / medianaLa mediana es una medida estadística que representa el valor central de un conjunto de datos ordenados. Para calcularla, se organizan los datos de menor a mayor y se identifica el número que se encuentra en el medio. Si hay un número par de observaciones, se promedia los dos valores centrales. Este indicador es especialmente útil en distribuciones asimétricas, ya que no se ve afectado por valores extremos.... / moda es una forma burda de tratar los valores perdidos. Dependiendo del contexto, como si la variación es baja o si la variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.... tiene un apalancamiento bajo sobre la respuesta, una aproximación tan aproximada es aceptable y podría dar resultados satisfactorios. En este caso, dado que está diciendo que es una variable categórica, es posible que este paso no sea aplicable.
Por ejemplo, 1, Para implementar este método, reemplazamos el valor faltante por el valor más frecuente para esa columna en particular, aquí reemplazamos el valor faltante por Masculino ya que el recuento de Masculino es mayor que Femenino (Masculino = 2 y Femenino = 1).
3. Desarrolle un modelo para predecir los valores perdidos: Una forma inteligente de hacer esto podría ser entrenar un clasificador sobre sus columnas con valores perdidos como una variable dependiente contra otras características de su conjunto de datos y tratar de imputar basándose en el clasificador recién entrenado.
Aquí está el algoritmo que puede seguir:
– Divida los datos en dos partes. Una parte tendrá los valores actuales de la columna, incluida la columna de salida original, la otra parte tendrá las filas con los valores faltantes.
– Dividir la 1ª parte (valores actuales) en un conjunto de validación cruzada para la selección del modelo.
– Entrene sus modelos y pruebe sus métricas con los datos validados cruzados. También puede realizar una búsqueda en cuadrícula o una búsqueda aleatoria para obtener los mejores resultados.
– Finalmente, con el modelo, predice los valores desconocidos que faltan en nuestro problema.
NOTA: Dado que está tratando de imputar valores perdidos, las cosas serán más agradables de esta manera, ya que no están sesgadas y obtiene las mejores predicciones del mejor modelo.
Por ejemplo, 1, Para implementar la estrategia dada, en primer lugar consideraremos la columna Característica-2, Característica-3 y Salida para nuestro nuevo clasificador, lo que significa que estas 3 columnas se utilizan como características independientes para nuestro nuevo clasificador y la Característica-1 se considera un resultado y una nota objetivo que aquí consideramos solo las filas que no faltan, ya que los datos de nuestro tren y las observaciones que tienen un valor faltante se convertirán en nuestros datos de prueba. Tenemos que hacer la predicción utilizando nuestro modelo en los datos de prueba y, después de las predicciones, tenemos el conjunto de datos al que no le falta ningún valor.
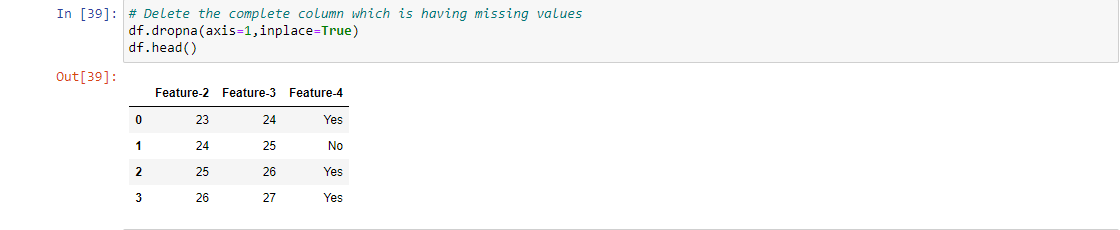
4. Eliminando la variable: Si hay un conjunto excepcionalmente mayor de valores perdidos, intente excluir la variable en sí para un modelo adicional, pero debe asegurarse de que no sea muy significativa para predecir la variable objetivo, es decir, la correlación entre la variable descartada y la variable objetivo es muy baja o redundante.
Por ejemplo, 1, Para implementar esta estrategia para manejar los valores faltantes, tenemos que eliminar la columna completa que contiene los valores faltantes, por lo que para un conjunto de datos dado eliminamos la Característica-1 por completo y usamos solo las características de la izquierda para predecir nuestra variable objetivo.
5. Aplicar técnicas de aprendizaje automático sin supervisión: En este enfoque, utilizamos técnicas no supervisadas como K-medias, Agrupación jerárquica, etc. La idea es que puede omitir aquellas columnas que tienen valores perdidos y considerar todas las demás columnas excepto la columna de destino e intentar crear tantos clústeres como no de características independientes (después de eliminar las columnas de valores perdidos), finalmente encontrar la categoría en el que cae la fila que falta.
Por ejemplo, 1, Para implementar esta estrategia, dejamos caer la columna Característica-1 y luego usamos Característica-2 y Característica-3 como nuestras características para el nuevo clasificador y luego, finalmente, después de la formación del clústerUn clúster es un conjunto de empresas y organizaciones interconectadas que operan en un mismo sector o área geográfica, y que colaboran para mejorar su competitividad. Estos agrupamientos permiten compartir recursos, conocimientos y tecnologías, fomentando la innovación y el crecimiento económico. Los clústeres pueden abarcar diversas industrias, desde tecnología hasta agricultura, y son fundamentales para el desarrollo regional y la creación de empleo...., tratamos de observar en qué clúster se encuentra el registro faltante y nosotros están listos con nuestro conjunto de datos final para un análisis más detallado.
Implementación en Python
Importe las dependencias necesarias.
Cargue y lea el conjunto de datos.

Encuentre el número de valores perdidos por columna.

Aplicar estrategia-1 (eliminar las observaciones que faltan).

Aplicar Estrategia-2 (Reemplazar los valores perdidos con el valor más frecuente).
Aplicar Estrategia-3 (Eliminar la variable que tiene valores perdidos).
Aplicar la estrategia 4 (Desarrollar un modelo para predecir los valores perdidos).
Para esta estrategia, primero codificamos nuestras columnas categóricas independientes usando “One Hot Encoder” y columnas categóricas dependientes usando “Label Encoder”.
– Leer y cargar el conjunto de datos codificado.
– Haga registros faltantes como nuestros datos de prueba.
– Haga registros que no falten como nuestros datos de entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina.....
– Variables independientes y dependientes separadas.
– Encajar nuestro modelo de Regresión Logística.

– Predecir la clase de registros faltantes.

¡Esto completa nuestra parte de implementación!
Notas finales
¡Gracias por leer!
Este artículo le presenta diferentes formas de abordar el problema de tener valores perdidos para variables categóricas.
Si le gustó esto y desea saber más, visite mis otros artículos sobre ciencia de datos y aprendizaje automático haciendo clic en el enlace
No dude en ponerse en contacto conmigo en Linkedin, Correo electrónico.
¿Algo no mencionado o quieres compartir tus pensamientos? No dude en comentar a continuación y me pondré en contacto con usted.
Hasta entonces, quédese en casa, manténgase seguro para evitar la propagación de COVID-19, ¡y sigue aprendiendo!
Sobre el Autor
Chirag Goyal
Actualmente, estoy cursando mi Licenciatura en Tecnología (B.Tech) en Ciencias de la Computación e Ingeniería de el Instituto Indio de Tecnología de Jodhpur (IITJ). Estoy muy entusiasmado con el aprendizaje automático, el aprendizaje profundoEl aprendizaje profundo, una subdisciplina de la inteligencia artificial, se basa en redes neuronales artificiales para analizar y procesar grandes volúmenes de datos. Esta técnica permite a las máquinas aprender patrones y realizar tareas complejas, como el reconocimiento de voz y la visión por computadora. Su capacidad para mejorar continuamente a medida que se le proporcionan más datos la convierte en una herramienta clave en diversas industrias, desde la salud... y la inteligencia artificial.
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





