Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Introducción
La visualización de datos en Python es quizás una de las características más utilizadas para la ciencia de datos con Python en la actualidad. Las bibliotecas en Python vienen con muchas características diferentes que permiten a los usuarios crear gráficos altamente personalizados, elegantes e interactivos.
En este artículo, cubriremos el uso de Matplotlib, Seaborn, así como una introducción a otros paquetes alternativos que se pueden usar en la visualización de Python.
Dentro de Matplotlib y Seaborn, cubriremos algunas de las parcelas más utilizadas en el mundo de la ciencia de datos para facilitar la visualización.
Más adelante en el artículo, repasaremos otra característica poderosa en las visualizaciones de Python, la subtrama, y cubrimos un tutorial básico para crear subtramas.
Paquetes útiles para visualizaciones en python
Matplotlib
Matplotlib es una biblioteca de visualización en Python para diagramas 2D de matrices. Matplotlib está escrito en Python y hace uso de la biblioteca NumPy. Se puede utilizar en shells Python e IPython, portátiles Jupyter y servidores de aplicaciones web. Matplotlib viene con una amplia variedad de gráficos como línea, barra, dispersión, histograma, etc. que pueden ayudarnos a profundizar en la comprensión de tendencias, patrones y correlaciones. Fue introducido por John Hunter en 2002.
Seaborn
Seaborn es una biblioteca orientada a conjuntos de datos para realizar representaciones estadísticas en Python. Está desarrollado sobre matplotlib y para crear diferentes visualizaciones. Está integrado con estructuras de datos de pandas. La biblioteca realiza internamente el mapeo y la agregación necesarios para crear elementos visuales informativos. Se recomienda utilizar una interfaz Jupyter / IPython en modo matplotlib.
Bokeh
Bokeh es una biblioteca de visualización interactiva para navegadores web modernos. Es adecuado para activos de datos grandes o de flujo continuo y se puede utilizar para desarrollar gráficos y cuadros de mando interactivos. Hay una amplia gama de gráficos intuitivos en la biblioteca que se pueden aprovechar para desarrollar soluciones. Trabaja en estrecha colaboración con las herramientas de PyData. La biblioteca es adecuada para crear imágenes personalizadas de acuerdo con los casos de uso requeridos. Las imágenes también se pueden hacer interactivas para servir un modelo de escenario hipotético. Todos los códigos son de código abierto y están disponibles en GitHub.
Altair
Altair es una biblioteca de visualización estadística declarativa para Python. La API de Altair es fácil de usar y coherente, y está construida sobre la especificación Vega-Lite JSONJSON, o JavaScript Object Notation, es un formato ligero de intercambio de datos que es fácil de leer y escribir para los humanos, y fácil de analizar y generar para las máquinas. Se utiliza comúnmente en aplicaciones web para enviar y recibir información entre un servidor y un cliente. Su estructura se basa en pares de clave-valor, lo que lo hace versátil y ampliamente adoptado en el desarrollo de software.... La biblioteca declarativa indica que al crear cualquier objeto visual, necesitamos definir los vínculos entre las columnas de datos y los canales (eje x, eje y, tamaño, color). Con la ayuda de Altair, es posible crear imágenes informativas con un código mínimo. Altair tiene una gramática declarativa tanto de visualización como de interacción.
tramadamente
plotly.py es una biblioteca de visualización interactiva, de código abierto, de alto nivel, declarativa y basada en navegador para Python. Contiene una variedad de visualización útil que incluye gráficos científicos, gráficos 3D, gráficos estadísticos, gráficos financieros, entre otros. Los gráficos de trazado se pueden ver en cuadernos de Jupyter, archivos HTML independientes o alojados en línea. La biblioteca Plotly ofrece opciones para la interacción y la edición. La robusta API funciona perfectamente en modo de navegador web y local.
ggplot
ggplot es una implementación de Python de la gramática de gráficos. La gramática de los gráficos se refiere a la asignación de datos a atributos estéticos (color, forma, tamaño) y objetos geométricos (puntos, líneas, barras). Los bloques de construcción básicos de acuerdo con la gramática de los gráficos son datos, geom (objetos geométricos), estadísticas (transformaciones estadísticas), escala, sistema de coordenadas y faceta.
El uso de ggplot en Python le permite desarrollar visualizaciones informativas de forma incremental, entendiendo primero los matices de los datos y luego ajustando los componentes para mejorar las representaciones visuales.
¿Cómo utilizar la visualización correcta?
Para extraer la información requerida de los diferentes elementos visuales que creamos, es esencial que usemos la representación correcta en función del tipo de datos y las preguntas que estamos tratando de entender. A continuación, analizaremos un conjunto de representaciones más utilizadas y cómo podemos utilizarlas de la manera más eficaz.
Gráfico de barras
Un gráfico de barrasEl gráfico de barras es una representación visual de datos que utiliza barras rectangulares para mostrar comparaciones entre diferentes categorías. Cada barra representa un valor y su longitud es proporcional a este. Este tipo de gráfico es útil para visualizar y analizar tendencias, facilitando la interpretación de información cuantitativa. Es ampliamente utilizado en diversas disciplinas, como la estadística, el marketing y la investigación, debido a su simplicidad y efectividad.... se utiliza cuando queremos comparar valores métricos en diferentes subgrupos de datos. Si tenemos un mayor número de grupos, se prefiere un gráfico de barras a un gráfico de columnas.
Gráfico de barras usando Matplotlib
#Creating the dataset
df = sns.load_dataset('titanic')
df=df.groupby('who')['fare'].sum().to_frame().reset_index()
#Creating the bar chart
plt.barh(df['who'],df['fare'],color = ['#F0F8FF','#E6E6FA','#B0E0E6'])
#Adding the aesthetics
plt.title('Chart title')
plt.xlabel('X axis title')
plt.ylabel('Y axis title')
#Show the plot
plt.show()
Gráfico de barras con Seaborn
#Creating bar plot
sns.barplot(x = 'fare',y = 'who',data = titanic_dataset,palette = "Blues")
#Adding the aesthetics
plt.title('Chart title')
plt.xlabel('X axis title')
plt.ylabel('Y axis title')
# Show the plot
plt.show()
Gráfico de columnas
Los gráficos de columnas se utilizan principalmente cuando necesitamos comparar una sola categoría de datos entre subelementos individuales, por ejemplo, al comparar ingresos entre regiones.
Gráfico de columnas usando Matplotlib
#Creating the dataset
df = sns.load_dataset('titanic')
df=df.groupby('who')['fare'].sum().to_frame().reset_index()
#Creating the column plot
plt.bar(df['who'],df['fare'],color = ['#F0F8FF','#E6E6FA','#B0E0E6'])
#Adding the aesthetics
plt.title('Chart title')
plt.xlabel('X axis title')
plt.ylabel('Y axis title')
#Show the plot
plt.show()
Gráfico de columnas con Seaborn
#Reading the dataset
titanic_dataset = sns.load_dataset('titanic')
#Creating column chart
sns.barplot(x = 'who',y = 'fare',data = titanic_dataset,palette = "Blues")
#Adding the aesthetics
plt.title('Chart title')
plt.xlabel('X axis title')
plt.ylabel('Y axis title')
# Show the plot
plt.show()
Gráfico de barras agrupadas
Se utiliza un gráfico de barras agrupadas cuando queremos comparar los valores en ciertos grupos y subgrupos.
Gráfico de barras agrupadas usando Matplotlib
#Creating the dataset
df = sns.load_dataset('titanic')
df_pivot = pd.pivot_table(df, values="fare",index="who",columns="class", aggfunc=np.mean)
#Creating a grouped bar chart
ax = df_pivot.plot(kind="bar",alpha=0.5)
#Adding the aesthetics
plt.title('Chart title')
plt.xlabel('X axis title')
plt.ylabel('Y axis title')
# Show the plot
plt.show()
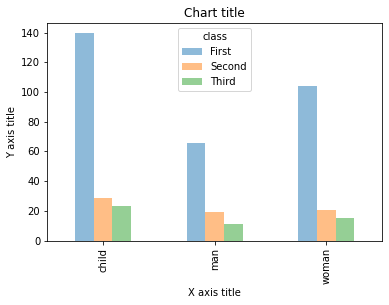
Gráfico de barras agrupadas con Seaborn
#Reading the dataset
titanic_dataset = sns.load_dataset('titanic')
#Creating the bar plot grouped across classes
sns.barplot(x = 'who',y = 'fare',hue="class",data = titanic_dataset, palette = "Blues")
#Adding the aesthetics
plt.title('Chart title')
plt.xlabel('X axis title')
plt.ylabel('Y axis title')
# Show the plot
plt.show()
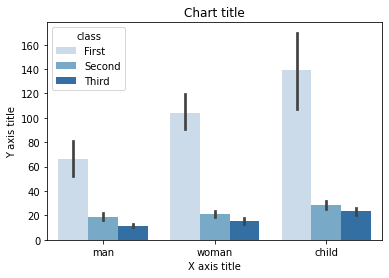
Gráfico de barras apiladas
Se utiliza un gráfico de barras apiladas cuando queremos comparar los tamaños totales de los grupos disponibles y la composición de los diferentes subgrupos.
Gráfico de barras apiladas usando Matplotlib
# Stacked bar chart
#Creating the dataset
df = pd.DataFrame(columns=["A","B", "C","D"],
data=[["E",0,1,1],
["F",1,1,0],
["G",0,1,0]])
df.plot.bar(x='A', y=["B", "C","D"], stacked=True, width = 0.4,alpha=0.5)
#Adding the aesthetics
plt.title('Chart title')
plt.xlabel('X axis title')
plt.ylabel('Y axis title')
#Show the plot
plt.show()
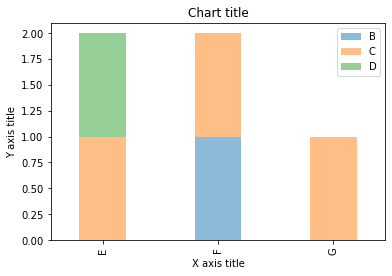
Gráfico de barras apiladas con Seaborn
dataframe = pd.DataFrame(columns=["A","B", "C","D"],
data=[["E",0,1,1],
["F",1,1,0],
["G",0,1,0]])
dataframe.set_index('A').T.plot(kind='bar', stacked=True)
#Adding the aesthetics
plt.title('Chart title')
plt.xlabel('X axis title')
plt.ylabel('Y axis title')
# Show the plot
plt.show()
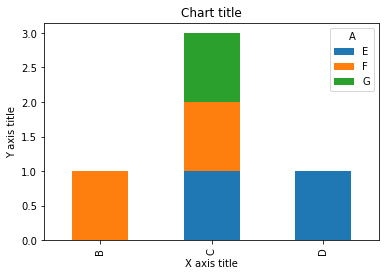
Gráfico de linea
Se utiliza un gráfico de líneasEl gráfico de líneas es una herramienta visual utilizada para representar datos a lo largo del tiempo. Consiste en una serie de puntos conectados por líneas, lo que permite observar tendencias, fluctuaciones y patrones en los datos. Este tipo de gráfico es especialmente útil en áreas como la economía, la meteorología y la investigación científica, facilitando la comparación de diferentes conjuntos de datos y la identificación de comportamientos a lo... para la representación de puntos de datos continuos. Este elemento visual se puede utilizar de forma eficaz cuando queremos comprender la tendencia a lo largo del tiempo.
Gráfico de líneas usando Matplotlib
#Creating the dataset
df = sns.load_dataset("iris")
df=df.groupby('sepal_length')['sepal_width'].sum().to_frame().reset_index()
#Creating the line chart
plt.plot(df['sepal_length'], df['sepal_width'])
#Adding the aesthetics
plt.title('Chart title')
plt.xlabel('X axis title')
plt.ylabel('Y axis title')
#Show the plot
plt.show()
Gráfico de líneas con Seaborn
#Creating the dataset
cars = ['AUDI', 'BMW', 'NISSAN',
'TESLA', 'HYUNDAI', 'HONDA']
data = [20, 15, 15, 14, 16, 20]
#Creating the pie chart
plt.pie(data, labels = cars,colors = ['#F0F8FF','#E6E6FA','#B0E0E6','#7B68EE','#483D8B'])
#Adding the aesthetics
plt.title('Chart title')
#Show the plot
plt.show()
Gráfico circular
Los gráficos circulares se pueden utilizar para identificar proporciones de los diferentes componentes en un todo dado.
Gráfico circular con Matplotlib
#Creating the dataset
cars = ['AUDI', 'BMW', 'NISSAN',
'TESLA', 'HYUNDAI', 'HONDA']
data = [20, 15, 15, 14, 16, 20]
#Creating the pie chart
plt.pie(data, labels = cars,colors = ['#F0F8FF','#E6E6FA','#B0E0E6','#7B68EE','#483D8B'])
#Adding the aesthetics
plt.title('Chart title')
#Show the plot
plt.show()
Gráfico de área
Los gráficos de área se utilizan para realizar un seguimiento de los cambios a lo largo del tiempo para uno o más grupos. Se prefieren los gráficos de área sobre los gráficos de líneas cuando queremos capturar los cambios a lo largo del tiempo para más de un grupo.
Gráfico de área usando Matplotlib
#Reading the dataset
x=range(1,6)
y=[ [1,4,6,8,9], [2,2,7,10,12], [2,8,5,10,6] ]
#Creating the area chart
ax = plt.gca()
ax.stackplot(x, y, labels=['A','B','C'],alpha=0.5)
#Adding the aesthetics
plt.legend(loc="upper left")
plt.title('Chart title')
plt.xlabel('X axis title')
plt.ylabel('Y axis title')
#Show the plot
plt.show()
Gráfico de área usando Seaborn
# Data
years_of_experience =[1,2,3]
salary=[ [6,8,10], [4,5,9], [3,5,7] ]
# Plot
plt.stackplot(years_of_experience,salary, labels=['Company A','Company B','Company C'])
plt.legend(loc="upper left")
#Adding the aesthetics
plt.title('Chart title')
plt.xlabel('X axis title')
plt.ylabel('Y axis title')
# Show the plot
plt.show()
Histograma de columna
Los histogramasLos histogramas son representaciones gráficas que muestran la distribución de un conjunto de datos. Se construyen dividiendo el rango de valores en intervalos, o "bins", y contando cuántos datos caen en cada intervalo. Esta visualización permite identificar patrones, tendencias y la variabilidad de los datos de manera efectiva, facilitando el análisis estadístico y la toma de decisiones informadas en diversas disciplinas.... de columna se utilizan para observar la distribución de una sola variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.... con pocos puntos de datos.
Gráfico de columnas usando Matplotlib
#Creating the dataset
penguins = sns.load_dataset("penguins")
#Creating the column histogram
ax = plt.gca()
ax.hist(penguins['flipper_length_mm'], color="blue",alpha=0.5, bins=10)
#Adding the aesthetics
plt.title('Chart title')
plt.xlabel('X axis title')
plt.ylabel('Y axis title')
#Show the plot
plt.show()
Gráfico de columnas con Seaborn
#Reading the dataset
penguins_dataframe = sns.load_dataset("penguins")
#Plotting bar histogram
sns.distplot(penguins_dataframe['flipper_length_mm'], kde=False, color="blue", bins=10)
#Adding the aesthetics
plt.title('Chart title')
plt.xlabel('X axis title')
plt.ylabel('Y axis title')
# Show the plot
plt.show()
Histograma de línea
Los histogramas de línea se utilizan para observar la distribución de una sola variable con muchos puntos de datos.
Gráfico de histograma de líneas usando Matplotlib
#Creating the dataset
df_1 = np.random.normal(0, 1, (1000, ))
density = stats.gaussian_kde(df_1)
#Creating the line histogram
n, x, _ = plt.hist(df_1, bins=np.linspace(-3, 3, 50), histtype=u'step', density=True)
plt.plot(x, density(x))
#Adding the aesthetics
plt.title('Chart title')
plt.xlabel('X axis title')
plt.ylabel('Y axis title')
#Show the plot
plt.show()
Gráfico de histograma de líneas con Seaborn
#Reading the dataset
penguins_dataframe = sns.load_dataset("penguins")
#Plotting line histogram
sns.distplot(penguins_dataframe['flipper_length_mm'], hist = False, kde = True, label="Africa")
#Adding the aesthetics
plt.title('Chart title')
plt.xlabel('X axis title')
plt.ylabel('Y axis title')
# Show the plot
plt.show()
Gráfico de dispersión
Los gráficos de dispersión se pueden aprovechar para identificar las relaciones entre dos variables. Se puede utilizar de forma eficaz en circunstancias en las que la variable dependiente puede tener varios valores para la variable independiente.
Gráfico de dispersión usando Matplotlib
#Creating the dataset
df = sns.load_dataset("tips")
#Creating the scatter plot
plt.scatter(df['total_bill'],df['tip'],alpha=0.5 )
#Adding the aesthetics
plt.title('Chart title')
plt.xlabel('X axis title')
plt.ylabel('Y axis title')
#Show the plot
plt.show()
Diagrama de dispersión usando Seaborn
#Reading the dataset
bill_dataframe = sns.load_dataset("tips")
#Creating scatter plot
sns.scatterplot(data=bill_dataframe, x="total_bill", y="tip")
#Adding the aesthetics
plt.title('Chart title')
plt.xlabel('X axis title')
plt.ylabel('Y axis title')
# Show the plot
plt.show()
Gráfico de burbujas
Los gráficos de dispersión se pueden aprovechar para representar y mostrar relaciones entre tres variables.
Gráfico de burbujas con Matplotlib
#Creating the dataset
np.random.seed(42)
N = 100
x = np.random.normal(170, 20, N)
y = x + np.random.normal(5, 25, N)
colors = np.random.rand(N)
area = (25 * np.random.rand(N))**2
df = pd.DataFrame({
'X': x,
'Y': y,
'Colors': colors,
"bubble_size":area})
#Creating the bubble chart
plt.scatter('X', 'Y', s="bubble_size",alpha=0.5, data=df)
#Adding the aesthetics
plt.title('Chart title')
plt.xlabel('X axis title')
plt.ylabel('Y axis title')
#Show the plot
plt.show()
Gráfico de burbujas con Seaborn
#Reading the dataset
bill_dataframe = sns.load_dataset("tips")
#Creating bubble plot
sns.scatterplot(data=bill_dataframe, x="total_bill", y="tip", hue="size", size="size")
#Adding the aesthetics
plt.title('Chart title')
plt.xlabel('X axis title')
plt.ylabel('Y axis title')
# Show the plot
plt.show()
Diagrama de caja
Se utiliza un diagrama de caja para mostrar la forma de la distribución, su valor central y su variabilidad.
Diagrama de caja usando Matplotlib
from past.builtins import xrange
#Creating the dataset
df_1 = [[1,2,5], [5,7,2,2,5], [7,2,5]]
df_2 = [[6,4,2], [1,2,5,3,2], [2,3,5,1]]
#Creating the box plot
ticks = ['A', 'B', 'C']
plt.figure()
bpl = plt.boxplot(df_1, positions=np.array(xrange(len(df_1)))*2.0-0.4, sym='', widths=0.6)
bpr = plt.boxplot(df_2, positions=np.array(xrange(len(df_2)))*2.0+0.4, sym='', widths=0.6)
plt.plot([], c="#D7191C", label="Label 1")
plt.plot([], c="#2C7BB6", label="Label 2")
#Adding the aesthetics
plt.title('Chart title')
plt.xlabel('X axis title')
plt.ylabel('Y axis title')
plt.legend()
plt.xticks(xrange(0, len(ticks) * 2, 2), ticks)
plt.xlim(-2, len(ticks)*2)
plt.ylim(0, 8)
plt.tight_layout()
#Show the plot
plt.show()
Diagrama de caja utilizando Seaborn
#Reading the dataset
bill_dataframe = sns.load_dataset("tips")
#Creating boxplots
ax = sns.boxplot(x="day", y="total_bill", hue="smoker", data=bill_dataframe, palette="Set3")
#Adding the aesthetics
plt.title('Chart title')
plt.xlabel('X axis title')
plt.ylabel('Y axis title')
# Show the plot
plt.show()
Gráfico de cascada
Se puede utilizar un gráfico de cascada para explicar la transición gradual en el valor de una variable que está sujeta a incrementos o decrementos.
#Reading the dataset
test = pd.Series(-1 + 2 * np.random.rand(10), index=list('abcdefghij'))
#Function for makig a waterfall chart
def waterfall(series):
df = pd.DataFrame({'pos':np.maximum(series,0),'neg':np.minimum(series,0)})
blank = series.cumsum().shift(1).fillna(0)
df.plot(kind='bar', stacked=True, bottom=blank, color=['r','b'], alpha=0.5)
step = blank.reset_index(drop=True).repeat(3).shift(-1)
step[1::3] = np.nan
plt.plot(step.index, step.values,'k')
#Creating the waterfall chart
waterfall(test)
#Adding the aesthetics
plt.title('Chart title')
plt.xlabel('X axis title')
plt.ylabel('Y axis title')
#Show the plot
plt.show()
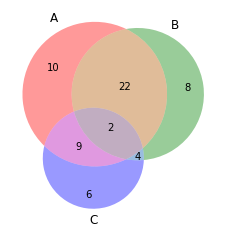
diagrama de Venn
Los diagramas de Venn se utilizan para ver las relaciones entre dos o tres conjuntos de elementos. Destaca las similitudes y diferencias
from matplotlib_venn import venn3 #Making venn diagram venn3(subsets = (10, 8, 22, 6,9,4,2)) plt.show()
Mapa de árbol
Los mapas de árbol se utilizan principalmente para mostrar datos agrupados y anidados en una estructura jerárquica y observar la contribución de cada componente.
import squarify
sizes = [40, 30, 5, 25, 10]
squarify.plot(sizes)
#Adding the aesthetics
plt.title('Chart title')
plt.xlabel('X axis title')
plt.ylabel('Y axis title')
# Show the plot
plt.show()
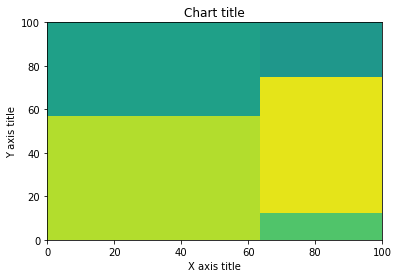
Gráfico de barras 100% apiladas
Se puede aprovechar un gráfico de barras apiladas al 100% cuando queremos mostrar las diferencias relativas dentro de cada grupo para los diferentes subgrupos disponibles.
#Reading the dataset
r = [0,1,2,3,4]
raw_data = {'greenBars': [20, 1.5, 7, 10, 5], 'orangeBars': [5, 15, 5, 10, 15],'blueBars': [2, 15, 18, 5, 10]}
df = pd.DataFrame(raw_data)
# From raw value to percentage
totals = [i+j+k for i,j,k in zip(df['greenBars'], df['orangeBars'], df['blueBars'])]
greenBars = [i / j * 100 for i,j in zip(df['greenBars'], totals)]
orangeBars = [i / j * 100 for i,j in zip(df['orangeBars'], totals)]
blueBars = [i / j * 100 for i,j in zip(df['blueBars'], totals)]
# plot
barWidth = 0.85
names = ('A','B','C','D','E')
# Create green Bars
plt.bar(r, greenBars, color="#b5ffb9", edgecolor="white", width=barWidth)
# Create orange Bars
plt.bar(r, orangeBars, bottom=greenBars, color="#f9bc86", edgecolor="white", width=barWidth)
# Create blue Bars
plt.bar(r, blueBars, bottom=[i+j for i,j in zip(greenBars, orangeBars)], color="#a3acff", edgecolor="white", width=barWidth)
# Custom x axis
plt.xticks(r, names)
plt.xlabel("group")
#Adding the aesthetics
plt.title('Chart title')
plt.xlabel('X axis title')
plt.ylabel('Y axis title')
plt.show()
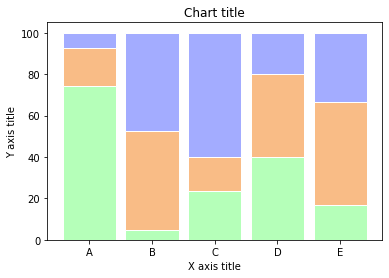
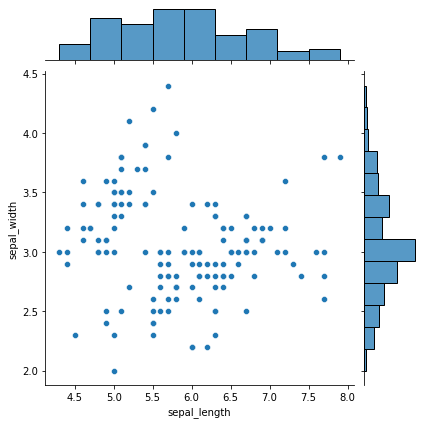
Parcelas marginales
Los gráficos marginales se utilizan para evaluar la relación entre dos variables y examinar sus distribuciones. Tales diagramas de dispersión que tienen histogramas, diagramas de cajaLos diagramas de caja, también conocidos como diagramas de caja y bigotes, son herramientas estadísticas que representan la distribución de un conjunto de datos. Estos diagramas muestran la mediana, los cuartiles y los valores atípicos, lo que permite visualizar la variabilidad y la simetría de los datos. Son útiles en la comparación entre diferentes grupos y en el análisis exploratorio, facilitando la identificación de tendencias y patrones en los datos.... o diagramas de puntos en los márgenes de los ejes xey respectivos
#Reading the dataset
iris_dataframe = sns.load_dataset('iris')
#Creating marginal graphs
sns.jointplot(x=iris_dataframe["sepal_length"], y=iris_dataframe["sepal_width"], kind='scatter')
# Show the plot
plt.show()
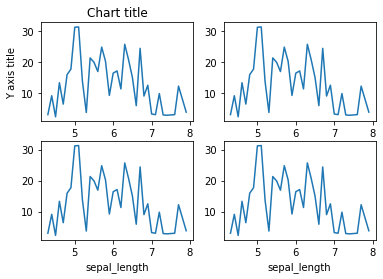
Subparcelas
Las subtramas son visualizaciones poderosas que facilitan las comparaciones entre tramas
#Creating the dataset
df = sns.load_dataset("iris")
df=df.groupby('sepal_length')['sepal_width'].sum().to_frame().reset_index()
#Creating the subplot
fig, axes = plt.subplots(nrows=2, ncols=2)
ax=df.plot('sepal_length', 'sepal_width',ax=axes[0,0])
ax.get_legend().remove()
#Adding the aesthetics
ax.set_title('Chart title')
ax.set_xlabel('X axis title')
ax.set_ylabel('Y axis title')
ax=df.plot('sepal_length', 'sepal_width',ax=axes[0,1])
ax.get_legend().remove()
ax=df.plot('sepal_length', 'sepal_width',ax=axes[1,0])
ax.get_legend().remove()
ax=df.plot('sepal_length', 'sepal_width',ax=axes[1,1])
ax.get_legend().remove()
#Show the plot
plt.show()
En conclusión, existe una variedad de bibliotecas diferentes que se pueden aprovechar en todo su potencial al comprender el caso de uso y el requisito. La sintaxis y la semántica varían de un paquete a otro y es esencial comprender los desafíos y las ventajas de las diferentes bibliotecas. ¡Feliz visualizando!
Científico de datos y entusiasta de la analíticaLa analítica se refiere al proceso de recopilar, medir y analizar datos para obtener información valiosa que facilite la toma de decisiones. En diversos campos, como los negocios, la salud y el deporte, la analítica permite identificar patrones y tendencias, optimizar procesos y mejorar resultados. El uso de herramientas avanzadas y técnicas estadísticas es fundamental para transformar datos en conocimiento aplicable y estratégico....
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.





