Dieser Artikel wurde im Rahmen der Data Science Blogathon.
Einführung
El análisis de clústeres o la agrupación en clústeres es un algoritmo de aprendizaje automático no supervisado que agrupa conjuntos de datos sin etiquetar. Su objetivo es formar conglomerados o grupos utilizando los puntos de datos en un conjunto de datos de tal manera que exista una alta similitud entre los conglomerados y una baja similitud entre los conglomerados. In einfachen Worten, la agrupación en clústeres tiene como objetivo formar subconjuntos o grupos dentro de un conjunto de datos que consta de puntos de datos que son realmente similares entre sí y los grupos o subconjuntos o clústeres formados pueden diferenciarse significativamente entre sí.
¿Por qué agrupar?
Supongamos que tenemos un conjunto de datos y no sabemos nada al respecto. Dann, un algoritmo de GruppierungDas "Gruppierung" Es handelt sich um ein Konzept, das sich auf die Organisation von Elementen oder Individuen in Gruppen mit gemeinsamen Merkmalen oder Zielen bezieht. Dieses Verfahren wird in verschiedenen Disziplinen eingesetzt, einschließlich Psychologie, Pädagogik und Biologie, um die Analyse und das Verständnis von Verhaltensweisen oder Phänomenen zu erleichtern. Im Bildungsbereich, zum Beispiel, Gruppenbildung kann die Interaktion und das Lernen unter den Schülern verbessern, indem sie die Arbeit fördert.. puede descubrir grupos de objetos donde las distancias promedio entre los miembros / puntos de datos de cada grupo están más cerca que a los miembros / puntos de datos en otros grupos.
Algunas de las aplicaciones prácticas de Clustering en la vida real como:
1) SegmentierungDie Segmentierung ist eine wichtige Marketingtechnik, bei der ein breiter Markt in kleinere, homogenere Gruppen unterteilt wird. Diese Praxis ermöglicht es Unternehmen, ihre Strategien und Botschaften an die spezifischen Merkmale jedes Segments anzupassen, So verbessern Sie die Effektivität Ihrer Kampagnen. Das Targeting kann auf demografischen Kriterien basieren, psychografisch, geografisch oder verhaltensbezogen, Erleichterung einer relevanteren und persönlicheren Kommunikation mit der Zielgruppe.... de clientes: Encontrar un grupo de clientes con un comportamiento similar dada una gran DatenbankEine Datenbank ist ein organisierter Satz von Informationen, mit dem Sie, Effizientes Verwalten und Abrufen von Daten. Einsatz in verschiedenen Anwendungen, Von Unternehmenssystemen bis hin zu Online-Plattformen, Datenbanken können relational oder nicht-relational sein. Das richtige Design ist entscheidend für die Optimierung der Leistung und die Gewährleistung der Informationsintegrität, und erleichtert so eine fundierte Entscheidungsfindung in verschiedenen Kontexten.... de clientes (se da un ejemplo práctico usando la segmentación de clientes bancarios)
2) Clasificación del tráfico de la red: Agrupación de características de las fuentes de tráfico. Los tipos de tráfico se pueden clasificar fácilmente mediante clústeres.
3) Filtro de correo no deseado: Los datos se agrupan en diferentes secciones (Header, remitente y contenido) y luego pueden ayudar a clasificar cuáles de ellos son spam.
4)Planificación de la ciudad: Agrupación de casas según su ubicación geográfica, valor y tipo de casa.
Diferentes tipos de algoritmos de agrupación
1) Gruppierung von K-Strümpfen – Usando este algoritmo, clasificamos un conjunto de datos dado a través de un cierto número de clústeres predeterminados o „k“ clústeres.
2) Hierarchische Gruppierung – Sigue dos enfoques Divisivo y Aglomerativo.
Agglomerative considera cada observación como un solo grupo y luego agrupa puntos de datos similares hasta que se fusionan en un solo grupo y Divisive funciona justo enfrente de él.
3) Fuzzy C significa Clustering – El funcionamiento del algoritmo FCM es casi similar al algoritmo de agrupamiento de k-medias, la principal diferencia es que en FCM un punto de datos se puede colocar en más de un grupo.
4) Agrupación espacial basada en densidad – Útil en las áreas de aplicación donde requerimos estructuras de ClusterEin Cluster ist eine Gruppe miteinander verbundener Unternehmen und Organisationen, die im selben Sektor oder geografischen Gebiet tätig sind, und die zusammenarbeiten, um ihre Wettbewerbsfähigkeit zu verbessern. Diese Gruppierungen ermöglichen die gemeinsame Nutzung von Ressourcen, Wissen und Technologien, Förderung von Innovation und Wirtschaftswachstum. Cluster können sich über eine Vielzahl von Branchen erstrecken, Von der Technologie bis zur Landwirtschaft, und sind von grundlegender Bedeutung für die regionale Entwicklung und die Schaffung von Arbeitsplätzen.... no lineales, basadas puramente en la densidad.
Jetzt, aquí en este artículo, nos centraremos profundamente en el algoritmo de agrupamiento de k-medias, explicaciones teóricas del funcionamiento de k-medias, Vorteile und Nachteile, y un problema de agrupamiento práctico resuelto que mejorará la comprensión teórica y le dará una visión adecuada. de cómo funciona la agrupación en clústeres de k-medias.
Dass es ist k-halb Clustering?
La agrupación de K-Means es un algoritmo de Unüberwachtes LernenUnüberwachtes Lernen ist eine Technik des maschinellen Lernens, die es Modellen ermöglicht, Muster und Strukturen in Daten ohne vordefinierte Beschriftungen zu identifizieren. Durch Algorithmen wie k-means und Hauptkomponentenanalyse, Dieser Ansatz wird in einer Vielzahl von Anwendungen eingesetzt, wie z. B. Kundensegmentierung, Anomalieerkennung und Datenkomprimierung. Seine Fähigkeit, verborgene Informationen preiszugeben, macht es zu einem wertvollen Werkzeug in der..., que se utiliza para agrupar el conjunto de datos sin etiquetar en diferentes grupos / Teilmengen.
Ahora debe estar preguntándose qué significa ‚k‘ Ja ‚es bedeutet‘ en el k-means Clustering significa ??
Dejando de lado todas sus suposiciones aquí, ‚k‘ define el número de grupos predefinidos que deben crearse en el proceso de agrupación, digamos que si k = 2, habrá dos grupos, y para k = 3, habrá tres grupos y así sucesivamente. Como es un algoritmo basado en centroide, ‚Medien‘ en el agrupamiento de k-medias está relacionado con el centroide de los puntos de datos donde cada grupo está asociado con un centroide. El concepto de un algoritmo basado en centroide se explicará en la explicación de trabajo de k-medias.
Hauptsächlich, el algoritmo de agrupación en clústeres de k-means realiza dos tareas:
- Determina el valor más óptimo para K puntos centrales o centroides mediante un proceso repetitivo.
- Asigna cada punto de datos a su centro k más cercano. El clúster se crea con puntos de datos que están cerca del centro k particular.
¿Cómo funciona la agrupación en clústeres de k-means?
Supongamos que tenemos dos variables X1 y X2, AusbreitungsdiagrammDas Streudiagramm ist ein grafisches Werkzeug, das in der Statistik verwendet wird, um die Beziehung zwischen zwei Variablen zu visualisieren. Es besteht aus einer Menge von Punkten in einer kartesischen Ebene, wobei jeder Punkt ein Wertepaar darstellt, das den analysierten Variablen entspricht. Diese Art von Diagramm ermöglicht es Ihnen, Muster zu erkennen, Trends und mögliche Korrelationen, Erleichterung der Dateninterpretation und Entscheidungsfindung auf der Grundlage der präsentierten visuellen Informationen.... dann:
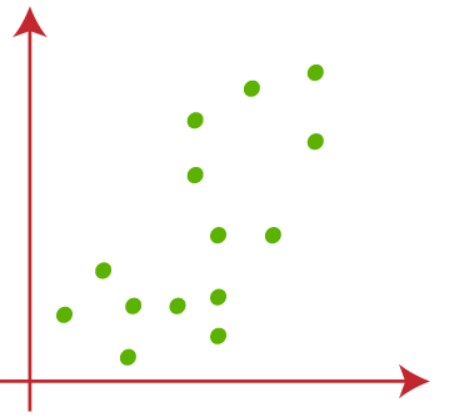
(1) Supongamos que el valor de k, que es el número de grupos predefinidos, es ist 2 (k = 2), por lo que aquí agruparemos nuestros datos en 2 Gruppen.
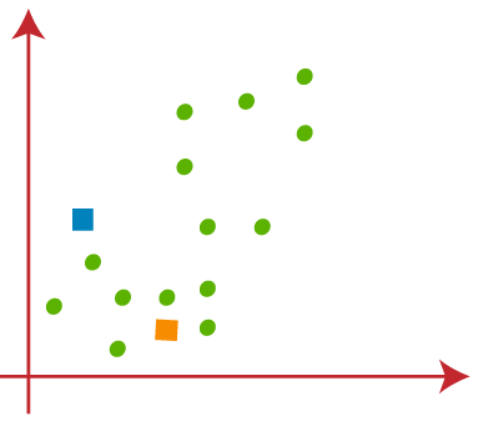
Es necesario elegir k puntos aleatorios para formar los grupos. No pueden existir restricciones en la selección de k puntos aleatorios desde el interior de los datos ni desde el exterior. Dann, aquí estamos considerando 2 puntos como k puntos (que no forman parte de nuestro conjunto de datos) que se muestran en la siguiente Abbildung"Abbildung" ist ein Begriff, der in verschiedenen Zusammenhängen verwendet wird, Von der Kunst zur Anatomie. Im künstlerischen Bereich, bezieht sich auf die Darstellung menschlicher oder tierischer Formen in Skulpturen und Gemälden. In der Anatomie, bezeichnet die Form und Struktur des Körpers. Was ist mehr, in der Mathematik, "Abbildung" Es hängt mit geometrischen Formen zusammen. Seine Vielseitigkeit macht es zu einem grundlegenden Konzept in mehreren Disziplinen....:
(2) El siguiente paso es asignar cada punto de datos del conjunto de datos en el diagrama de dispersión a su punto k más cercano, esto se hará calculando la distancia euclidiana entre cada punto con un punto k y dibujando una MedianDer Median ist ein statistisches Maß, das den zentralen Wert eines Satzes geordneter Daten darstellt. Um es zu berechnen, Die Daten werden von der niedrigsten zur höchsten sortiert und die Zahl in der Mitte wird identifiziert. Wenn es eine gerade Anzahl von Beobachtungen gibt, Die beiden Kernwerte werden gemittelt. Dieser Indikator ist besonders nützlich bei asymmetrischen Verteilungen, da es nicht von Extremwerten beeinflusst wird.... entre ambos centroides, que se muestra en la figura a continuación-
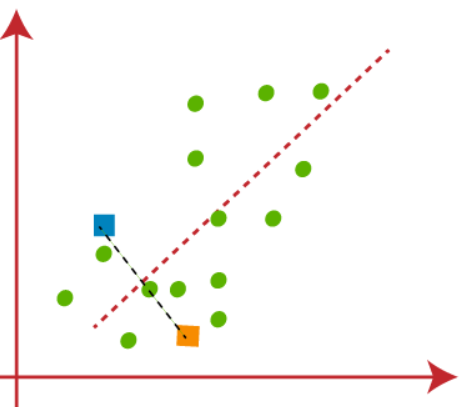
Podemos observar claramente que el punto a la izquierda de la línea roja está cerca de K1 o el centroide azul y los puntos a la derecha de la línea roja están cerca de K2 o el centroide naranja.
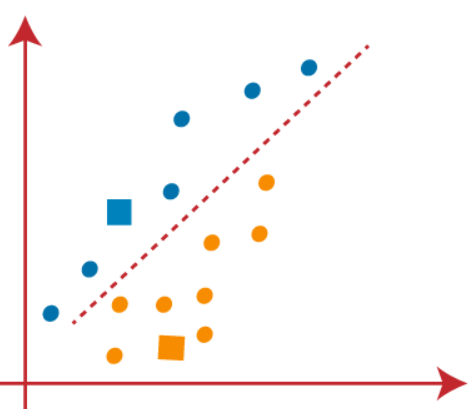
(3) Como necesitamos encontrar el punto más cercano, repetiremos el proceso eligiendo un nuevo centroide. So wählen Sie die neuen Schwerpunkte, calcularemos el centro de gravedad de estos centroides y encontraremos nuevos centroides como se muestra a continuación:
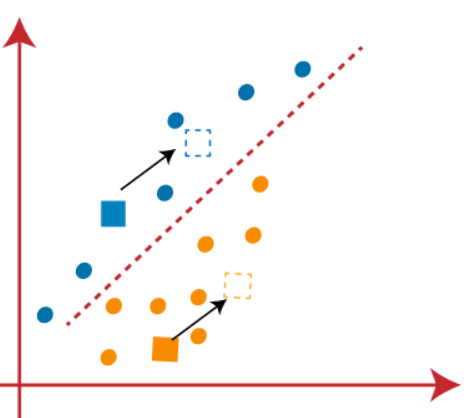
(4) Jetzt, necesitamos reasignar cada punto de datos a un nuevo centroide. Dafür, tenemos que repetir el mismo proceso de encontrar una línea mediana. La mediana será como a continuación:
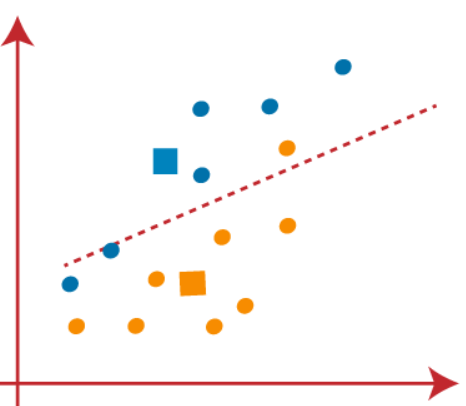
Im Bild oben, Wir sehen, un punto naranja está en el lado izquierdo de la línea y dos puntos azules están justo a la línea. Dann, estos tres puntos se asignarán a nuevos centroides

Seguiremos encontrando nuevos centroides hasta que no haya puntos diferentes en ambos lados de la línea.
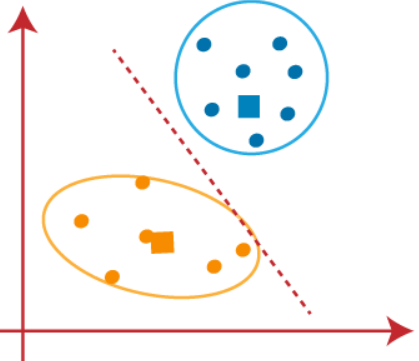
Ahora podemos eliminar los centroides asumidos, y los dos grupos finales serán como se muestra en la imagen de abajo
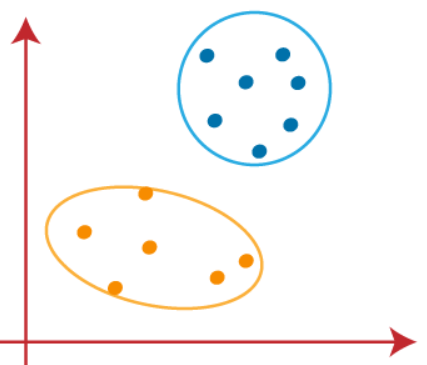
Hasta ahora hemos visto cómo funciona el algoritmo de k-medias y los distintos pasos involucrados para llegar al destino final de los clusters diferenciadores.
Ahora todos deben estar preguntándose cómo elegir el valor de k número de clusters.
El rendimiento del algoritmo de agrupación de K-means depende en gran messenDas "messen" Es ist ein grundlegendes Konzept in verschiedenen Disziplinen, , die sich auf den Prozess der Quantifizierung von Eigenschaften oder Größen von Objekten bezieht, Phänomene oder Situationen. In Mathematik, Wird verwendet, um Längen zu bestimmen, Flächen und Volumina, In den Sozialwissenschaften kann es sich auf die Bewertung qualitativer und quantitativer Variablen beziehen. Die Messgenauigkeit ist entscheidend, um zuverlässige und valide Ergebnisse in der Forschung oder praktischen Anwendung zu erhalten.... de las agrupaciones que forma. Elegir el número óptimo de clústeres es una tarea difícil. Hay varias formas de encontrar el número óptimo de conglomerados, pero aquí estamos discutiendo dos métodos para encontrar el número de conglomerados o el valor de K que es el Método del codo y puntuación de la silueta.
Método del codo para encontrar ‚k‘ número de grupos:[1]
El método Elbow es el más popular para encontrar un número óptimo de conglomerados, este método utiliza WCSS (Suma de cuadrados dentro de los conglomerados) que representa las variaciones totales dentro de un conglomerado.
WCSS = ∑Pi en Cluster1 Distanz (Pich C1)2 + ΣPi en Cluster2Distanz (Pich C2)2+ ΣPi en CLuster3 Distanz (Pich C3)2
En la fórmula anterior ∑Pi en Cluster1 Distanz (Pich C1)2 es la suma del cuadrado de las distancias entre cada punto de datos y su centroide dentro de un grupo1 de manera similar para los otros dos términos en la fórmula anterior.
Pasos involucrados en el método del codo:
- K- significa que el agrupamiento se realiza para diferentes valores de k (von 1 ein 10).
- WCSS se calcula para cada grupo.
- Se traza una curva entre los valores WCSS y el número de conglomerados k.
- El punto de curvatura agudo o un punto de la trama parece un brazo, entonces ese punto se considera como el mejor valor de K.
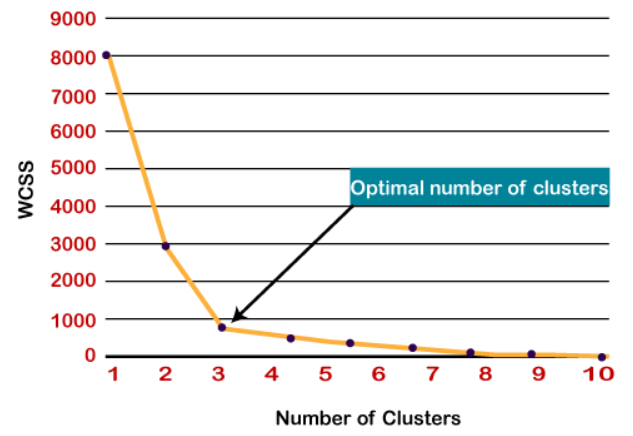
Also hier, wie wir sehen können, una curva pronunciada está en k = 3, por lo que el número óptimo de grupos es 3.
Puntuación de silueta Método para encontrar ‚k‘ número de conglomerados
El valor de silueta es una medida de cuán similar es un objeto a su propio grupo (cohesión) en comparación con otros grupos (separación). La silueta varía de -1 ein +1, donde un valor alto indica que el objeto se corresponde bien con su propio grupo y no con los grupos vecinos. Si la mayoría de los objetos tienen un valor alto, entonces la configuración de agrupamiento es apropiada. Si muchos puntos tienen un valor bajo o negativo, entonces la configuración de la agrupación en clústeres puede tener demasiados o muy pocos clústeres.
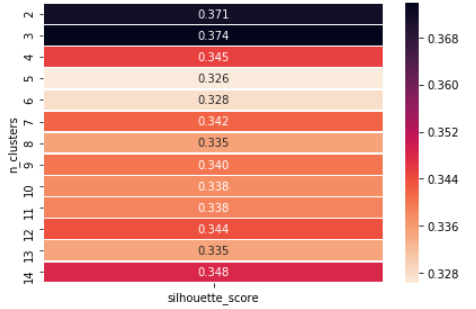
Ejemplo que muestra cómo podemos elegir el valor de ‚k‘, ya que podemos ver que en n = 3 tenemos la puntuación máxima de silueta, Daher, elegimos el valor de k = 3.
Ventajas de utilizar la agrupación en clústeres de k-means
- Einfach zu implementieren.
- Con una gran cantidad de variables, K-Means puede ser computacionalmente más rápido que el agrupamiento jerárquico (si K es pequeño).
- Las k-medias pueden producir agrupaciones más altas que las agrupaciones jerárquicas.
Desventajas de usar clustering de k-means
Es difícil predecir el número de agrupaciones (valor K).
Las semillas iniciales tienen un fuerte impacto en los resultados finales.
Implementación práctica del algoritmo de agrupación en clústeres K-means utilizando Python (segmentación de clientes bancarios)
Aquí estamos importando las bibliotecas necesarias para nuestro análisis.
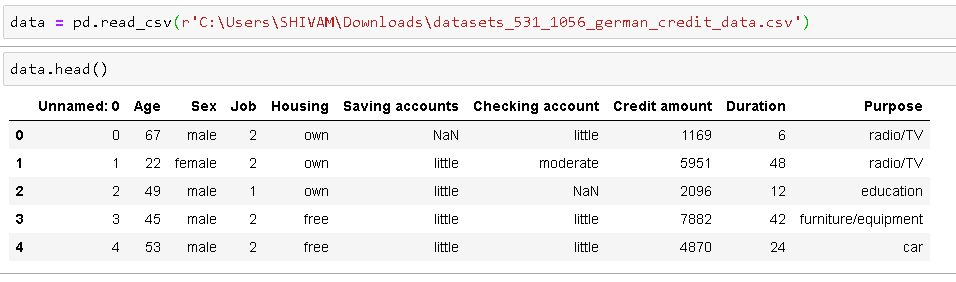
Leer los datos y obtener las 5 mejores observaciones para echar un vistazo al conjunto de datos
No se ha incluido el código para EDA (Explorative Datenanalyse), se realizó EDA con estos datos y se realizó un análisis de valores atípicos para limpiar los datos y hacerlos aptos para nuestro análisis.
Wie wir wissen, las K-medias se realizan solo en los datos numéricos, por lo que elegimos las columnas numéricas para nuestro análisis.

Jetzt, para realizar la agrupación de k-medias como se discutió anteriormente en este artículo, necesitamos encontrar el valor del número ‚k‘ de agrupaciones y podemos hacerlo usando el siguiente código, aquí usamos varios valores de k para la agrupación y luego seleccionando utilizando el Ellbogenmethode.

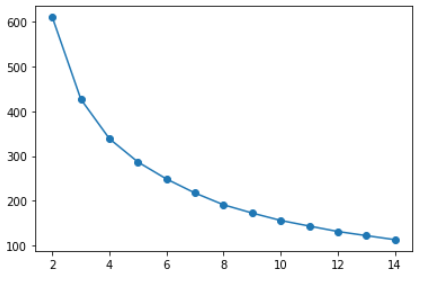
A medida que aumenta el número de conglomerados, die abweichung (suma de cuadrados dentro del conglomerado) nimmt ab. El codo en 3 Ö 4 grupos representa el equilibrio más parsimonioso entre minimizar el número de grupos y minimizar la varianza dentro de cada grupo, por lo que podemos elegir un valor de k para que sea 3 Ö 4
Ahora se muestra cómo podemos usar el método del valor de silueta para encontrar el valor de ‚k‘.

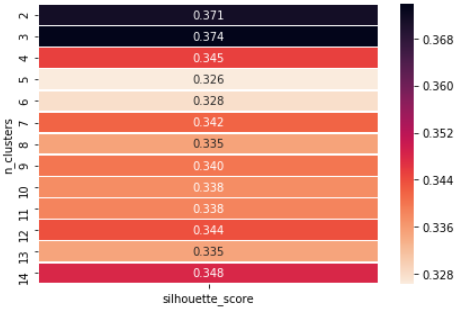
Si observamos, obtenemos el número óptimo de conglomerados en n = 3, por lo que finalmente podemos elegir el valor de k = 3.
Jetzt, ajustar el algoritmo de k significa usando el valor de k = 3 y trazar el Heatmapein "Heatmap" ist eine grafische Darstellung, die Farben verwendet, um die Dichte von Daten in einem bestimmten Bereich anzuzeigen. Häufig in der Datenanalyse verwendet, Marketing und Verhaltensstudien, Diese Art der Visualisierung ermöglicht es Ihnen, Muster und Trends schnell zu erkennen. Durch chromatische Variationen, Heatmaps erleichtern die Interpretation großer Informationsmengen, dabei helfen, fundierte Entscheidungen zu treffen.... para los clústeres.
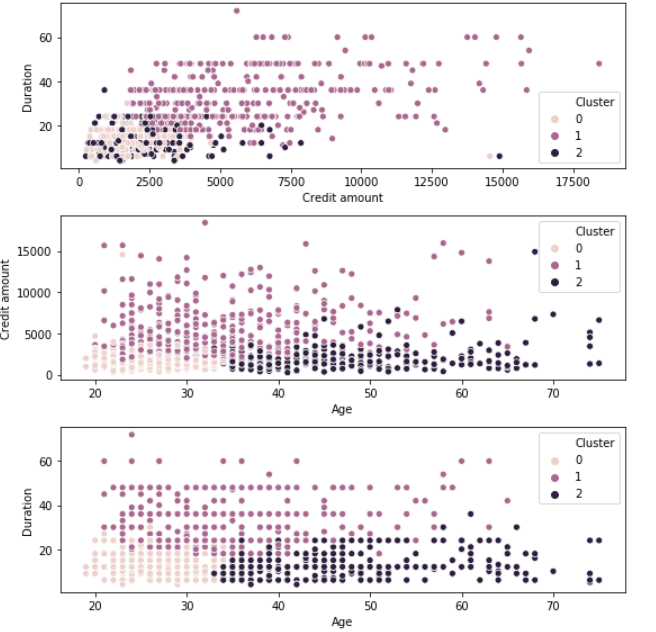

Análisis final
Cluster 0: clientes jóvenes que obtienen préstamos de bajo crédito durante un período breve
Gruppe 1: Clientes de mediana edad que obtienen préstamos de alto crédito durante un período prolongado
Gruppe 2: Clientes de edad avanzada que obtienen préstamos de crédito medio por un período corto
Fazit
Hemos discutido qué es la agrupación en clústeres, sus tipos y su aplicación en diferentes industrias. Discutimos qué es la agrupación de k-medias, el funcionamiento del algoritmo de agrupación de k-medias, dos métodos para seleccionar el número ‚k‘ de agrupaciones, y sus ventajas y desventajas. Später, pasamos por la implementación práctica del algoritmo de agrupación en clústeres de k-medias utilizando el problema de segmentación de clientes bancarios en Python.
Verweise:
(1) img (1) a img (8) Ja [1] , referencia tomada del „Algoritmo de agrupación en clústeres de K-medias“
https://www.javatpoint.com/k-means-clustering-algorithm-in-machine-learning





