Einführung
GitHub-Repositorys und Reddit-Diskussionen: beide Plattformen haben eine Schlüsselrolle in meinem maschinelles Lernen Reise. Sie haben mir geholfen, mein Wissen und Verständnis von Techniken des maschinellen Lernens und meinen Geschäftssinn zu entwickeln.
Sowohl GitHub als auch Reddit halten mich auch über die neuesten Entwicklungen im Bereich Machine Learning auf dem Laufenden, Ein Muss für jeden, der in diesem Bereich arbeitet!!
Und wenn Sie Programmierer sind, gut, GitHub ist wie ein Tempel für dich. Sie können den Code einfach herunterladen und auf Ihrem Computer replizieren. Dies macht es noch einfacher, neue Ideen zu lernen und vielfältige Fähigkeiten aufzubauen..

Ich freue mich, die besten GitHub-Repositorys und die Reddit-Diskussionen dieses Monats auszuwählen. In den Reddit-Threads, die ich vorgestellt habe, geht es sowohl um die technische Seite von maschinelles Lernen sowie die, die mit dem Rennen zu tun haben. Diese Fähigkeit, beides zu kombinieren, unterscheidet Experten für maschinelles Lernen von Hobbyisten..
Nachfolgend finden Sie die monatlichen Artikel, die wir bisher in dieser Serie behandelt haben:
So, Machen wir uns an die Arbeit für März!
GitHub-Repositorys

Wenn ich einen der Gründe für meine Faszination für wählen müsste Computer Vision, wären GANs (Generative gegnerische Netzwerke). Sie wurden vor wenigen Jahren von Ian Goodfellow erfunden und haben sich zu einer ganzen Forschungsgruppe entwickelt.. Aktuelle KI-Kunst, die Sie in den Nachrichten gesehen haben? Alles funktioniert mit GAN.

DeepMind hat letztes Jahr das BigGAN-Konzept entwickelt, aber wir haben eine Weile auf eine PyTorch-Implementierung gewartet. Dieses Repository enthält auch zuvor trainierte Modelle (128 × 128, 256 × 256 Ja 512 × 512). Sie können dies in nur einer Codezeile installieren:
pip install pytorch-pretrained-biggan
Und wenn Sie den vollständigen BigGAN-Forschungsartikel lesen möchten, Besuch hier.
Die Fähigkeit, mit Bilddaten zu arbeiten, wird zu einem bestimmenden Merkmal für jeden, der sich dafür interessiert tiefes Lernen. Das Aufkommen und schnelle Aufblühen von Computer-Vision-Algorithmen hat bei dieser Transformation eine wichtige Rolle gespielt.. Sie werden nicht überrascht sein zu erfahren, dass NVIDIA einer der führenden Anbieter in diesem Bereich ist..
Schauen Sie sich einfach ihre Entwicklungen an 2018:
Und nun, die Leute von NVIDIA haben eine weitere erstaunliche Version erstellt: die Fähigkeit, fotorealistische Bilder mit einem semantischen Eingabedesign zu synthetisieren. Wie gut ist es? Der folgende Vergleich bietet eine gute Illustration:

SPADE hat bestehende Methoden im beliebten COCO-Datensatz übertroffen. Das oben verlinkte Repository enthält die PyTorch-Implementierung und die zuvor für diese Technik trainierten Modelle (Achten Sie darauf, es mit einem Lesezeichen zu versehen).
Dieses Video zeigt, wie gut SPADE funktioniert in 40.000 Bilder von Flickr:
Dieses Repository basiert auf dem ‘Schnelle Online-Objektverfolgung und Segmentierung: ein vereinheitlichender Ansatz‘ Papier. Hier ist ein Beispielergebnis mit dieser Technik:

Beeindruckend! Die Technik, namens SiamMask, es ist ganz einfach, vielseitig und extrem schnell. Oh, Habe ich schon erwähnt, dass die Objektverfolgung in Echtzeit erfolgt?? Das ist mir auf jeden Fall aufgefallen. Dieses Repository enthält auch vortrainierte Modelle, damit Sie loslegen können.
Die Arbeit wird auf der renommierten CVPR-Konferenz präsentiert 2019 (Computer Vision und Mustererkennung) im Juni. Die Autoren haben ihren Ansatz im folgenden Video demonstriert:
Haben Sie schon einmal an einem Posenerkennungsprojekt gearbeitet?? Ich habe es getan und lass mich dir sagen, es ist ausgezeichnet. Es ist ein Beweis für die Fortschritte, die wir als Gemeinschaft beim Deep Learning gemacht haben.. Wer hätte das gedacht 10 Jahre, in denen wir die nächste Körperbewegung eines Menschen vorhersagen könnten?
Dieses GitHub-Repository ist ein PyTorch Implementierung von ‘Selbstüberwachtes Erlernen der menschlichen 3D-Pose mit Multi-View-Geometrie‘ Papier. Die Autoren haben eine neue Technik namens . entwickelt EpipolarPose, eine selbstüberwachte Lernmethode, um die Pose eines Menschen in 3D einzuschätzen.

Die EpipolarPose-Technik schätzt 2D-Posen aus Multi-View-Bildern während der Trainingsphase. Verwenden Sie dann die epipolare Geometrie, um eine 3D-Pose zu generieren. Dies, zur selben Zeit, Wird verwendet, um den 3D-Pose-Estimator zu trainieren. Dieser Vorgang ist im Bild oben dargestellt.
Dieser Artikel wurde auch auf der CVPR-Konferenz akzeptiert 2019. Gestalten Sie sich zu einem exzellenten Line-Up!!
Dies ist in vielerlei Hinsicht ein einzigartiges Repository. Es ist ein Open-Source-Deep-Learning-Modell zum Schutz Ihrer Privatsphäre. Das gesamte Konzept von DeepCamera basiert auf automatisiertem maschinellem Lernen (AutoML). Deswegen, Sie brauchen nicht einmal Programmiererfahrung, um ein neues Modell zu trainieren.

DeepCamera funktioniert auf Android-Geräten. Sie können den Code auch in Überwachungskameras integrieren. Es gibt VIEL, was Sie mit DeepCamera-Code tun können, was beinhaltet:
- Gesichtserkennung
- Gesichtserkennung
- Steuerung über die mobile Anwendung
- Objekterkennung
- Bewegungserkennung
Und viele andere Dinge. Es war noch nie so einfach, Ihr eigenes KI-gestütztes Modell zu erstellen!!
Reddit-Diskussionen

Ich habe die Reddit-Diskussionen dieses Monats in zwei Kategorien unterteilt:
- Die technische Seite des maschinellen Lernens
- Karrierebezogene Diskussionen über maschinelles Lernen (Rollen und Jobs)
Fangen wir mit dem technischen Aspekt an.
Data Scientists sind von Forschungsarbeit fasziniert. Wir wollen sie lesen, kodiere sie und schreibe vielleicht sogar eine von Grund auf neu. Wie cool wäre es, Ihr eigenes Forschungspapier auf einer hochkarätigen ML-Konferenz zu präsentieren??

Ich gehöre auf jeden Fall zur Kategorie der “Ich möchte einen Forschungsartikel schreiben”. Diese Diskussion, Gestartet von einem erfahrenen Forscher, befasst sich mit den Best Practices, die wir beim Schreiben eines Forschungsartikels befolgen sollten. Hier gibt es viele Infos und Erfahrungen, Ein Muss für uns alle!
Hier ist das GitHub-Repository mit den besten Tipps, Tipps und Ideen an einem Ort. Behandeln Sie diese Tipps als Richtlinien und nicht als in Stein gemeißelte Regeln.
Wie bringen Sie Ihre trainierten Machine-Learning-Modelle in die Produktion?? Wie setzt du sie um? Dies sind SEHR häufige Fragen, denen Sie in Ihrem Data Science-Interview begegnen werden (und Arbeit, Natürlich). Wenn Sie sich nicht sicher sind, was das ist, Ich schlage vor, Sie lesen es JETZT.
In diesem Diskussionsthread geht es um eine Open-Source-Bibliothek, die Ihre Machine-Learning-Modelle in nativen Code umwandelt (C, Python, Java) keine Abhängigkeiten. Muss durch den Thread scrollen, da es einige häufige Fragen gibt, die der Autor ausführlich behandelt hat.
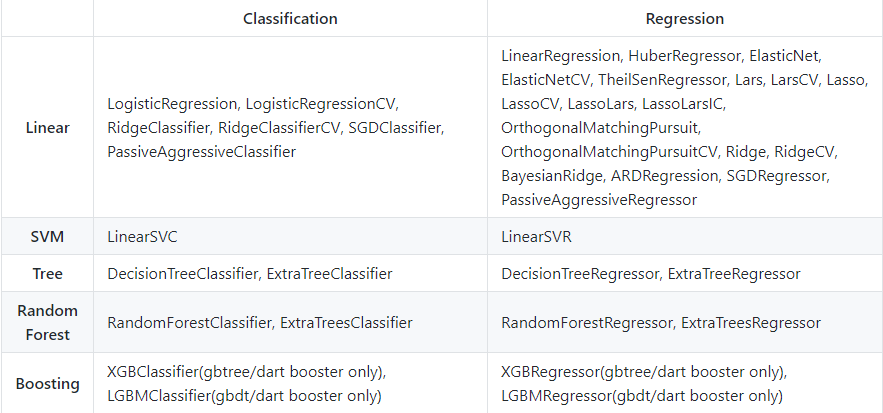
Den vollständigen Code finden Sie in dieses GitHub-Repository. Unten ist die Liste der Modelle, die diese Bibliothek derzeit unterstützt:
Verlagern wir jetzt den Fokus und sehen wir uns einige Diskussionen über die Karriere des maschinellen Lernens an. Diese gelten für ALLE Experten für maschinelles Lernen, aufstrebend und etabliert.
Wird das Aufkommen des automatisierten maschinellen Lernens ein Nachteil für die Branche selbst sein?? Das ist eine Frage, die sich die meisten von uns schon gestellt haben.. Die meisten Artikel, auf die ich stoße, sagen allen Pessimismus voraus. Einige behaupten sogar, dass Data Scientists nicht benötigt werden in 5 Jahre!

Quelle: Demokratie
Der Autor dieses Threads argumentiert wunderbar gegen den allgemeinen Konsens. Es ist sehr unwahrscheinlich, dass Data Science aufgrund von Automatisierung verschwindet.
In der Diskussion wird zu Recht argumentiert, dass es bei Data Science nicht nur um Datenmodellierung geht. Das ist nur der 10% des gesamten Prozesses. Ein wichtiger Teil des Data Science-Lebenszyklus ist die menschliche Intuition hinter den Modellen. Datenbereinigung, Datenvisualisierung und ein Hauch von Logik sind es, die diesen ganzen Prozess antreiben.
Hier ist ein Juwel und ein solides Argument, das mir aufgefallen ist:
Wir entwickeln alle Arten von Statistiksoftware im letzten Jahrhundert und, aber trotzdem, hat Statistiker nicht ersetzt.
Möchten Sie Ihre erste Stelle im Bereich Data Science ergattern?? Findest du es ein überwältigender Prozess?? Ich war dort. Es ist eine der größten Hürden, die es auf unseren jeweiligen Data Science-Reisen zu überwinden gilt..
Deshalb wollte ich diesen speziellen Thread hervorheben. Es ist eine wirklich aufschlussreiche Diskussion, wo Data-Science-Profis und -Anfänger diskutieren, wie man in dieses Feld einsteigt. Der Autor des Beitrags bietet einige eingehende Gedanken zum Prozess der Jobsuche im Bereich Data Science sowie Tipps zum Abschließen jeder Interviewrunde..

Ein Satz, der aus dieser Diskussion wirklich herausstach:
Erinnern, der Anstieg der Interviewanfragen und der Wissenszuwachs sind nicht nur ein Zusammenhang, es ist eine kausalität. Bei der Bewerbung, jeden Tag etwas Neues lernen.
Ein DataPeaker, Unser Ziel ist es, Ihnen zu helfen, Ihre erste Position in der Datenwissenschaft zu erreichen. Sehen Sie sich die erstaunlichen Ressourcen unten an, um Ihnen den Einstieg zu erleichtern:
Fachwissen: diese Schlüsselzutat im gesamten Data Scientist-Rezept. Häufig, angehende Datenwissenschaftler übersehen oder interpretieren es falsch. Und das führt oft zu Ablehnungen in Vorstellungsgesprächen.. Dann, Wie können Sie Ihren Geschäftssinn weiterentwickeln, um Ihre bestehenden Fähigkeiten im Bereich Technical Data Science zu ergänzen??
Diese Reddit-Diskussion bietet einige hilfreiche Einblicke. Die Fähigkeit, Ihre Ideen und Ihre Ergebnisse in kommerzielle Begriffe zu übersetzen, ist VITAL. Die meisten Interessengruppen, denen Sie in Ihrer Karriere begegnen werden, werden den Fachjargon nicht verstehen..
Hier ist meine Lieblingsauswahl aus der Diskussion:
Sie müssen Ihre Geschäftspartner besser kennen. Finden Sie heraus, was sie täglich tun, wie sind deine prozesse, wie sie die Daten generieren, die Sie verwenden werden. Wenn Sie verstehen, wie X und Y sehen, Sie können ihnen besser helfen, wenn sie mit Problemen zu Ihnen kommen.
Bei DataPeaker glauben wir fest daran, eine strukturierte Denkweise aufzubauen. Unsere Erfahrungen und unser Wissen zu diesem Thema haben wir im folgenden umfassenden Kurs gesammelt:
Dieser Kurs enthält mehrere Fallstudien, die Ihnen auch dabei helfen, sich ein Bild von der Arbeitsweise und Denkweise von Unternehmen zu machen..
Abschließende Anmerkungen
Die Reddit-Diskussionen im letzten Monat haben mir besonders gut gefallen. Ich fordere Sie auf, mehr darüber zu erfahren, wie die Produktionsumgebung in einem Machine-Learning-Projekt funktioniert. Für einen Data Scientist mittlerweile fast schon obligatorisch, damit du ihm nicht entkommen kannst.
Du solltest auch an diesen Reddit-Diskussionen teilnehmen. Passives Scrollen ist gut für den Wissenserwerb, Aber auch anderen Bewerbern hilft das Einbringen der eigenen Perspektive. Das ist ein nicht greifbares Gefühl, Aber du wirst es zu schätzen wissen und zu schätzen wissen, je mehr Erfahrung du bekommst.
Welche Diskussion fandest du am aufschlussreichsten? Und welches GitHub-Repository für Sie herausragte? Lass es mich im Kommentarbereich unten wissen!!





