Dieser Artikel wurde im Rahmen der Data Science Blogathon
Einführung
Data Science ist ein aufstrebendes Feld mit zahlreichen Beschäftigungsmöglichkeiten. Wir alle müssen von den besten Fähigkeiten in der Datenwissenschaft gehört haben. um anzufangen, Die einfachste und wichtigste Fähigkeit, die sich jeder angehende Data Scientist aneignen sollte, ist SQL.
Heute, Die meisten Unternehmen sind datengetrieben. Diese Daten werden in einer Datenbank gespeichert und über ein Datenbankmanagementsystem verwaltet und verarbeitet. DBMS macht unsere Arbeit so einfach und organisiert. Deswegen, Es ist wichtig, die beliebteste Programmiersprache in das erstaunliche DBMS-Tool zu integrieren.
SQL ist die am weitesten verbreitete Programmiersprache bei der Arbeit mit Datenbanken und ist mit verschiedenen relationalen Datenbanksystemen kompatibel, wie MySQL, SQL Server und Oracle. Aber trotzdem, Der SQL-Standard verfügt über einige Funktionen, die in verschiedenen Datenbanksystemen unterschiedlich implementiert sind. Deswegen, SQL wird zu einem der wichtigsten Konzepte, die es in diesem Bereich der Datenwissenschaft zu lernen gilt.
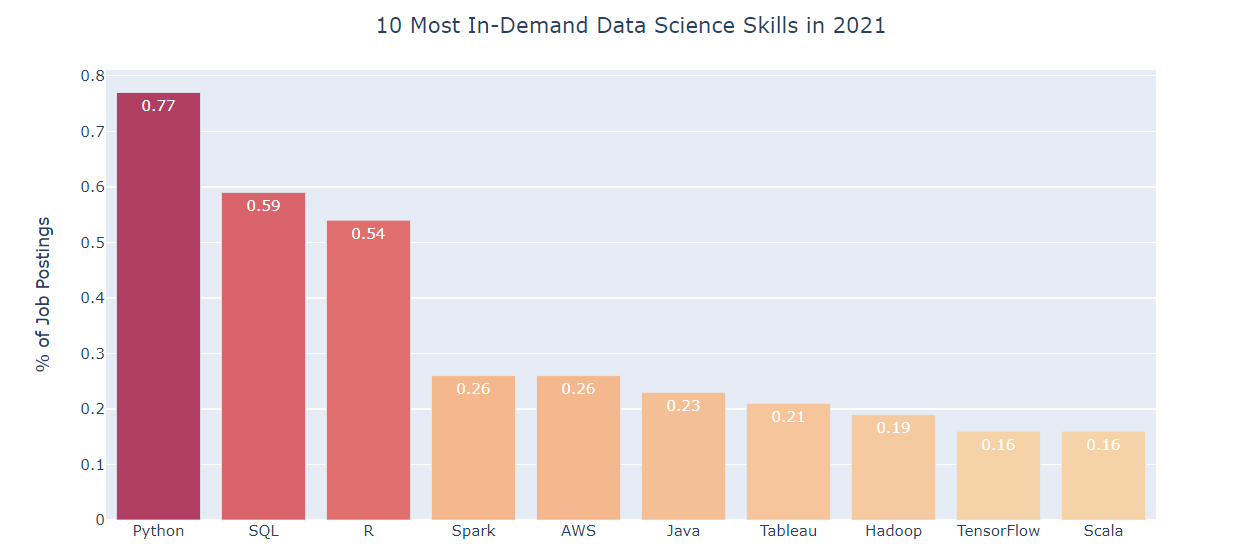
Bildquelle: KDnuggets
Bedarf an SQL in Data Science
SQL (Strukturierte Abfragesprache) Es wird verwendet, um verschiedene Vorgänge für die in den Datenbanken gespeicherten Daten auszuführen, Aktualisieren von Datensätzen, Datensätze löschen, Erstellen und Ändern von Tabellen, Ansichten, etc. SQL ist auch der Standard für die heutigen Big-Data-Plattformen, die SQL als Schlüssel-API für ihre relationalen Datenbanken verwenden.
Data Science ist die umfassende Untersuchung von Daten. So arbeiten Sie mit Daten, Wir müssen sie aus der Datenbank extrahieren. Hier kommt SQL ins Spiel. Relationales Datenbankmanagement ist ein entscheidender Bestandteil der Datenwissenschaft. Ein Data Scientist kann steuern, definieren, manipulieren, Erstellen und Abfragen der Datenbank mithilfe von SQL-Befehlen.
Viele moderne Branchen haben das Datenmanagement ihrer Produkte mit NoSQL-Technologie ausgestattet, aber SQL ist immer noch die ideale Wahl für viele Business-Intelligence- und Office-Operations-Tools.
Viele der Datenbankplattformen basieren auf SQL. Aus diesem Grund ist es zu einem Standard für viele Datenbanksysteme geworden. Moderne Big-Data-Systeme wie Hadoop, Spark verwendet SQL auch nur, um relationale Datenbanksysteme zu verwalten und strukturierte Daten zu verarbeiten.
Das können wir sagen:
1. Ein Data Scientist benötigt SQL, um strukturierte Daten zu verarbeiten. Wie strukturierte Daten in relationalen Datenbanken gespeichert werden. Deswegen, So konsultieren Sie diese Datenbanken, Ein Data Scientist sollte ein gutes Verständnis von SQL-Befehlen haben.
Big-Data-Plattformen wie Hadoop und Spark bieten eine Erweiterung für Abfragen mit SQL-Befehlen zur Bearbeitung.
3.SQL ist das Standardwerkzeug zum Experimentieren mit Daten durch Erstellen von Testumgebungen.
4. So führen Sie Analysevorgänge für Daten durch, die in relationalen Datenbanken wie Oracle gespeichert sind, Microsoft SQL, MySQL, wir brauchen SQL.
5. SQL ist auch ein wesentliches Werkzeug für die Datenaufbereitung und -verarbeitung. Deswegen, im Umgang mit verschiedenen Big-Data-Tools, Wir verwenden SQL.
Schlüsselelemente von SQL für Data Science
Im Folgenden sind die wichtigsten Aspekte von SQL aufgeführt, die für Data Science am nützlichsten sind. Alle angehenden Data Scientists sollten sich dieser notwendigen SQL-Kenntnisse und -Funktionen bewusst sein.
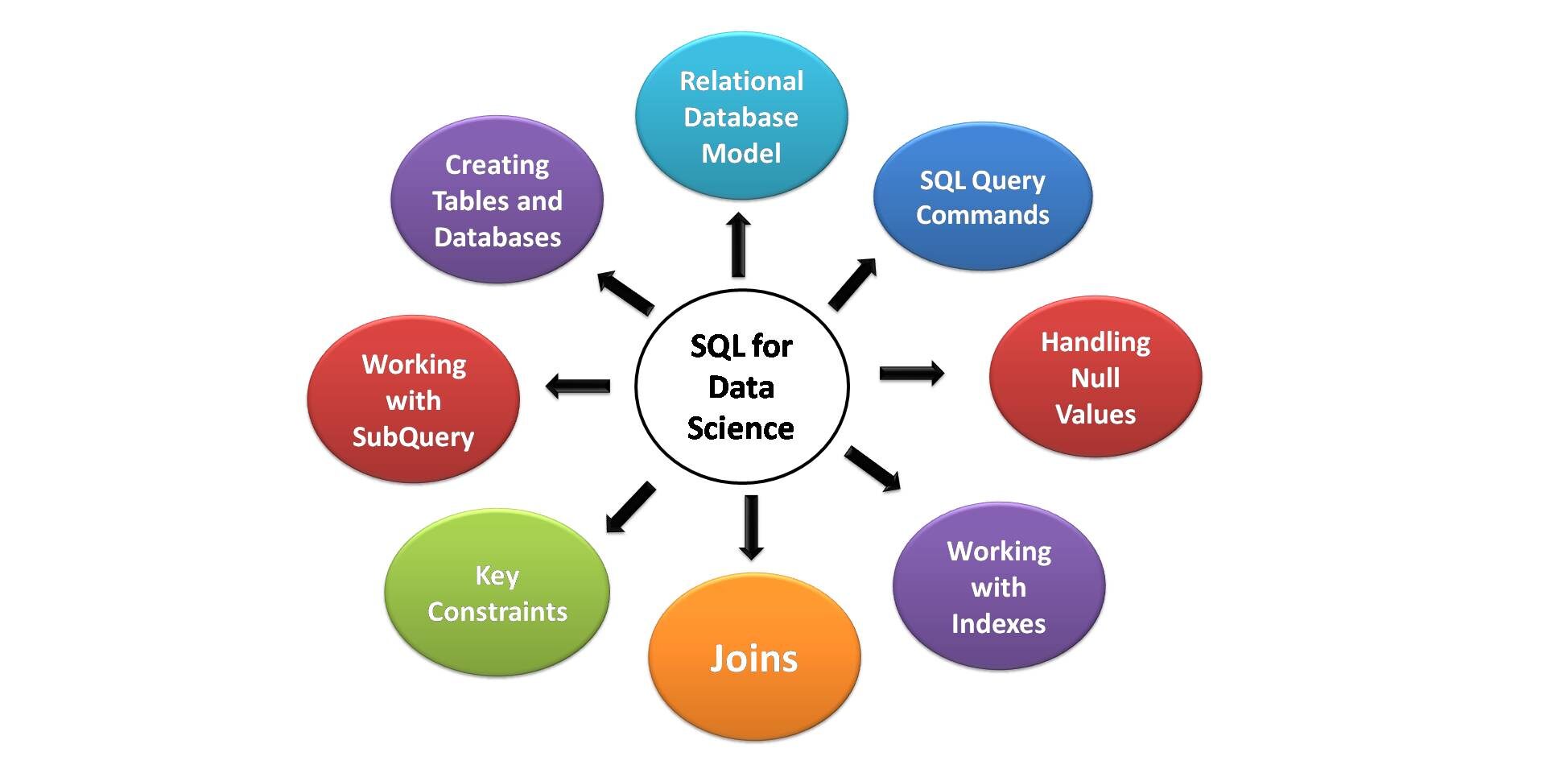
Bildquelle: Für mich
Einführung in SQL mit Python
Wie wir alle wissen, SQL ist das am weitesten verbreitete Datenbankverwaltungstool und Python ist aufgrund seiner Flexibilität und der großen Auswahl an Bibliotheken die beliebteste Data-Science-Sprache. Es gibt mehrere Möglichkeiten, SQL mit Python zu verwenden. Python stellt mehrere Bibliotheken zur Verfügung, die für diesen Zweck entwickelt werden und verwendet werden können. SQLite, PostgreSQL, und MySQL sind Beispiele für diese Bibliotheken.
Gründe für die Verwendung von SQL mit Python
Es gibt viele Anwendungsfälle, in denen Data Scientists Python mit SQL verbinden möchten. Data Scientists müssen eine Verbindung zu einer SQL-Datenbank herstellen, um die Daten aus der Webanwendung zu speichern. Es hilft auch bei der Kommunikation zwischen verschiedenen Datenquellen.
Kein Wechsel zwischen verschiedenen Programmiersprachen für die Datenverwaltung erforderlich. Macht die Arbeit von Data Scientists komfortabler. Sie werden in der Lage sein, ihre Python-Kenntnisse zu nutzen, um Daten zu manipulieren, die in einer SQL-Datenbank gespeichert sind. Sie benötigen keine CSV-Datei.
MySQL mit Python
MySQL ist ein serverbasiertes Datenbankmanagementsystem. Ein MySQL-Server kann mehrere Datenbanken haben. Eine MySQL-Datenbank besteht aus einem zweistufigen Prozess zum Erstellen einer Datenbank:
1. Stellen Sie eine Verbindung zu einem MySQL-Server her.
2. Führen Sie separate Abfragen aus, um die Datenbank zu erstellen und die Daten zu verarbeiten.
Beginnen wir mit MySQL mit Python
Zuerst, Wir erstellen eine Verbindung zwischen dem MySQL-Server und der MySQL-Datenbank. Dafür, Wir definieren eine Funktion, die eine Verbindung zum MySQL-Datenbankserver herstellt und das Verbindungsobjekt zurückgibt:
!pip install mysql-connector-python
import mysql.connector
from mysql.connector import Error
def create_connection(host_name, user_name, user_password):
connection = None
try:
Verbindung = mysql.connector.connect(
host=host_name,
user=user_name,
passwd=user_password
)
drucken("Verbindung zur MySQL-Datenbank erfolgreich hergestellt")
außer Fehler als e:
drucken(F"Der Fehler"{e}' aufgetreten ist")
return connection
connection = create_connection("localhost", "Wurzel", "")
Im obigen Code, Wir haben eine Funktion create_connection definiert () , der die folgenden drei Parameter akzeptiert:
1. nombre_host
2. Nutzername
3. Benutzer-Passwort
Mysql.connector ist ein Python-SQL-Modul, das eine .connect-Methode enthält () , die verwendet wird, um eine Verbindung zu einem MySQL-Datenbankserver herzustellen. Wenn die Verbindung hergestellt ist, Das erstellte Verbindungsobjekt wird an die aufrufende Funktion zurückgegeben.
Bis jetzt, Die Verbindung wurde erfolgreich hergestellt, Lassen Sie uns nun eine Datenbank erstellen.
#we have created a function to create database that contions two parameters #connection and query defcreate_database(Verbindung,Anfrage): #Jetzt erstellen wir einen Objektcursor zum Ausführen von SQL-Abfragen Cursor=connection.cursor() Versuchen: #Die auszuführende Abfrage wird in cursor.execute übergeben() in String-Form cursor.execute(Anfrage) drucken("Datenbank erfolgreich erstellt") außerFehlerwiee: drucken(F"Der Fehler"{e}' aufgetreten ist")
#now we are creating a database named example_app create_database_query="DATENBANK ERSTELLEN example_app" create_database(Verbindung,create_database_query)
#now will create database example_app on database server #and also cretae connection between database and server defcreate_connection(host_name,user_name,user_password,db_name): Verbindung=Keiner versucht es: Verbindung=mysql.connector.connect( host=host_name, user=user_name, passwd=user_password, database=db_name ) drucken("Verbindung zur MySQL-Datenbank erfolgreich hergestellt") außerFehlerwiee: drucken(F"Der Fehler"{e}' aufgetreten ist") RückkehrVerbindung
#Aufruf dercreate_connection()und verbindet sich mit demexample_appDatenbank. Verbindung=create_connection("localhost","Wurzel","","example_app")
SQLite
SQLite ist wahrscheinlich die einfachste Datenbank, die wir mit einer Python-Anwendung verbinden können, da es sich um ein integriertes Modul handelt, Wir müssen keine externen Python-SQL-Module installieren. Standardmäßig, Die Python-Installation enthält eine Python-SQL-Bibliothek namens sqlite3, die für die Interaktion mit einer SQLite-Datenbank verwendet werden kann.
SQLite ist eine serverlose Datenbank. Lesen und Schreiben von Daten in eine Datei. Das bedeutet, dass wir nicht einmal einen SQLite-Server installieren und ausführen müssen, um Datenbankoperationen wie MySQL und PostgreSQL durchzuführen!
Lassen Sie uns sqlite3 verwenden So stellen Sie eine Verbindung zu einer SQLite-Datenbank in Python her:
importierensqlite3 vonsqlite3importierenFehler
defcreate_connection(Weg): Verbindung=Keiner versucht es: Verbindung=sqlite3.connect(Weg) drucken("Verbindung zur SQLite-Datenbank erfolgreich")
außerFehlerwiee: drucken(F"Der Fehler"{e}' aufgetreten ist") RückkehrVerbindung
Im obigen Code, Wir haben sqlite3 und die Modulfehlerklasse importiert. Definieren Sie dann eine Funktion mit dem Namen .create_connection () , die den Pfad zur SQLite-Datenbank akzeptiert. Dann .connect () des sqlite3-Moduls nimmt den SQLitite-Datenbankpfad als Parameter. Gibt an, ob die Datenbank in dem in .connect angegebenen Pfad vorhanden ist, Es wird eine Verbindung zur Datenbank hergestellt. Andererseits, Eine neue Datenbank wird auf dem angegebenen Pfad erstellt, und dann wird eine Verbindung hergestellt.
sqlite3.connect (Route) gibt ein Verbindungsobjekt zurück, die auch von create_connection (). Dieses Verbindungsobjekt wird verwendet, um SQL-Abfragen für eine SQLite-Datenbank auszuführen. In der nächsten Codezeile wird eine Verbindung zur SQLite-Datenbank hergestellt:
Verbindung=create_connection("E:example_app.sqlite")
Sobald die Verbindung hergestellt ist, können wir sehen, dass die Datenbankdatei im Stammverzeichnis erstellt wird, und wenn wir, Wir können auch den Speicherort der Datei ändern.
In diesem Artikel, Wir diskutieren, wie wichtig SQL für Data Science ist und auch, wie wir mit Python mit SQL arbeiten können. Danke fürs Lesen. Teilen Sie mir Ihre Kommentare und Vorschläge im Kommentarbereich mit.
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von DataPeaker und werden nach Ermessen des Autors verwendet.





