Einführung
Beim Erstellen eines Modells für maschinelles Lernen im wirklichen Leben, Es ist fast selten, dass alle Variablen im Datensatz für die Erstellung eines Modells nützlich sind. Das Hinzufügen redundanter Variablen verringert die Generalisierbarkeit des Modells und kann auch die Gesamtpräzision eines Klassifikators verringern. Was ist mehr, Das Hinzufügen von immer mehr Variablen zu einem Modell erhöht die Gesamtkomplexität des Modells.
Laut ihm Gesetz der Sparsamkeit von ‘Ockhams Rasiermesser’, Die beste Erklärung für ein Problem ist diejenige, die möglichst wenige Annahmen beinhaltet. Deswegen, Die Featureauswahl wird zu einem unverzichtbaren Bestandteil beim Erstellen von Modellen für maschinelles Lernen.
Ziel
Das Ziel der Merkmalsauswahl beim maschinellen Lernen besteht darin, den besten Merkmalssatz zu finden, mit dem Sie nützliche Modelle der untersuchten Phänomene erstellen können..
Techniken zur Auswahl von Funktionen beim maschinellen Lernen lassen sich grob in die folgenden Kategorien einteilen:
Beaufsichtigte Techniken: Diese Techniken können für gekennzeichnete Daten verwendet werden und werden verwendet, um relevante Merkmale zu identifizieren, um die Effizienz überwachter Modelle wie Klassifikation und Regression zu erhöhen..
Unbeaufsichtigte Techniken: Diese Techniken können für nicht gekennzeichnete Daten verwendet werden.
Aus taxonomischer Sicht, Diese Techniken werden unterteilt in:
EIN. Filtermethoden
B. Verpackungsmethoden
C. Integrierte Methoden
D. Hybride Methoden
In diesem Artikel, Wir werden einige beliebte Techniken zur Merkmalsauswahl im maschinellen Lernen besprechen.
EIN. Filtermethoden
Filtermethoden sammeln intrinsische Eigenschaften gemessener Merkmale durch univariate Statistiken statt durch Kreuzvalidierungsleistung. Diese Methoden sind schneller und weniger rechenintensiv als Wrapper-Methoden. Wenn es um hochdimensionale Daten geht, es ist rechnerisch günstiger, Filtermethoden zu verwenden.
Lassen Sie uns einige dieser Techniken analysieren:
Informationsgewinn
Der Informationsgewinn berechnet die Entropiereduktion aus der Transformation eines Datensatzes. Es kann für die Auswahl von Merkmalen verwendet werden, indem der Informationsgewinn jeder Variablen im Kontext der Zielvariablen bewertet wird.
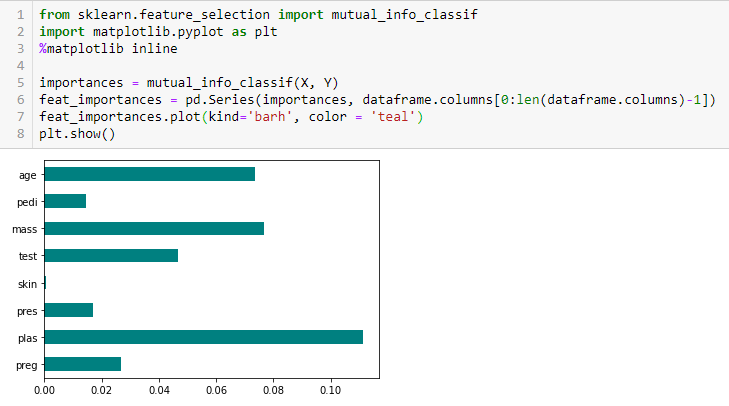
Chi-Quadrat-Test
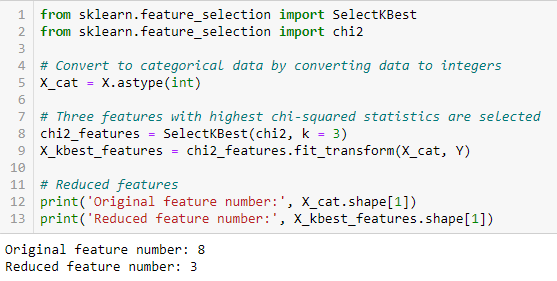
Der Chi-Quadrat-Test wird für kategoriale Merkmale in einem Datensatz verwendet. Wir berechnen das Chi-Quadrat zwischen jedem Merkmal und dem Ziel und wählen die gewünschte Anzahl von Merkmalen mit den besten Chi-Quadrat-Werten aus.. So wenden Sie das Chi-Quadrat richtig an, um die Beziehung zwischen verschiedenen Merkmalen im Datensatz und der Zielvariablen zu testen, folgende Bedingungen müssen erfüllt sein: Variablen müssen sein kategorisch, abgetastet ungeachtet und die Werte müssen a . haben erwartete Häufigkeit größer als 5.
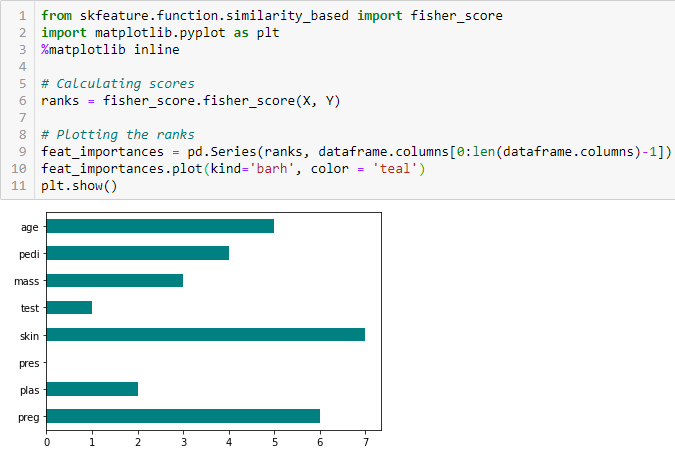
Fisher-Score
Der Fisher-Score ist eine der am häufigsten verwendeten Methoden zur überwachten Merkmalsauswahl. Der Algorithmus, den wir verwenden werden, gibt die Bereiche der Variablen basierend auf der Punktzahl des Fischers in absteigender Reihenfolge zurück. Dann können wir die Variablen entsprechend dem Fall auswählen.
Korrelationskoeffizient
Korrelation ist ein Maß für die lineare Beziehung von 2 oder mehr Variablen. Durch Korrelation, wir können eine Variable aus der anderen vorhersagen. Die Logik hinter der Verwendung der Korrelation für die Merkmalsauswahl besteht darin, dass gute Variablen stark mit dem Ziel korrelieren. Was ist mehr, die Variablen müssen mit dem Ziel korreliert sein, aber sie dürfen nicht miteinander korreliert sein.
Wenn zwei Variablen korreliert sind, wir können das eine vom anderen vorhersagen. Deswegen, wenn zwei Merkmale korreliert sind, das Modell braucht wirklich nur einen davon, da die zweite keine zusätzlichen Informationen hinzufügt. Wir werden hier die Korrelation von Pearson verwenden.
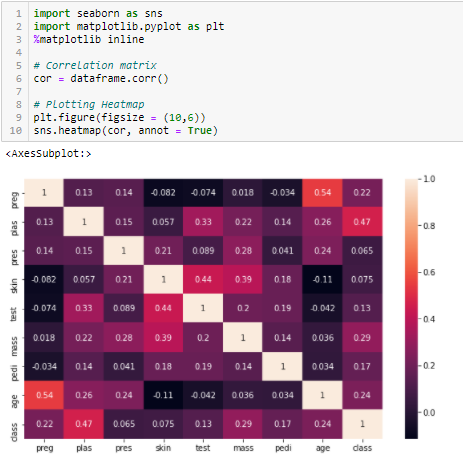
Wir müssen einen absoluten Wert festlegen, Sagen wir 0.5 als Schwellenwert für die Auswahl von Variablen. Wenn wir feststellen, dass die Prädiktorvariablen miteinander korreliert sind, wir können die Variable verwerfen, die einen niedrigeren Korrelationskoeffizientenwert mit der Zielvariablen hat. Wir können auch mehrere Korrelationskoeffizienten berechnen, um zu überprüfen, ob mehr als zwei Variablen miteinander korreliert sind. Dieses Phänomen wird als Multikollinearität bezeichnet..
Abweichungsschwelle
Der Varianzschwellenwert ist ein einfacher Basisansatz für die Merkmalsauswahl. Eliminieren Sie alle Merkmale, deren Variation keinen Schwellenwert erreicht. Standardmäßig, entfernt alle Null-Varianz-Eigenschaften, nämlich, Merkmale, die in allen Stichproben den gleichen Wert haben. Wir gehen davon aus, dass die Merkmale mit einer höheren Varianz nützlichere Informationen enthalten können., Beachten Sie jedoch, dass wir die Beziehung zwischen den charakteristischen Variablen oder den charakteristischen und Zielvariablen nicht berücksichtigen, was einer der Nachteile von Filtermethoden ist.

Get_support gibt einen booleschen Vektor zurück, wobei True bedeutet, dass die Variable keine Varianz von Null hat.
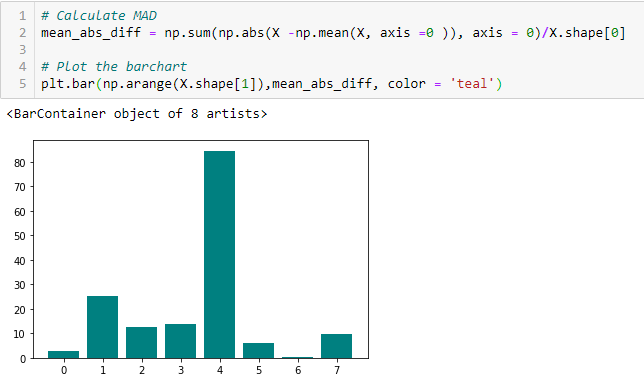
Mittlere absolute Differenz (VERRÜCKT)
„Die mittlere absolute Differenz (VERRÜCKT) berechnet die absolute Differenz vom Mittelwert. Der Hauptunterschied zwischen den Varianzmaßen und MAD ist das Fehlen des Quadrats im letzteren.. Das MAD, wie die Varianz, es ist auch eine variante der skala ». [1] Das bedeutet, je höher der DMA, größere Unterscheidungskraft.
Dispersionsverhältnis
„Ein weiteres Streuungsmaß ist das arithmetische Mittel“ (BIN) und das geometrische Mittel (GM). Für eine gegebene Eigenschaft (positiv) xich in n Mustern, AM und GM werden gegeben von
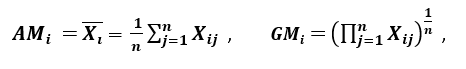
beziehungsweise; wie SOJAich GMich, mit Gleichheit genau dann, wenn xi1 = Xi2 =…. = XIn, dann der Anteil
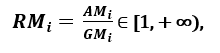
kann als Maß für die Streuung verwendet werden. Eine größere Streuung impliziert einen größeren Wert von Ri, also eine relevantere Funktion. Umgekehrt, wenn alle Feature-Samples haben (Über) der gleiche Wert, Ri ist in der Nähe 1, was auf ein Merkmal von geringer Relevanz hinweist '. [1]

 ‘
‘
B. Verpackungsmethoden:
Wrapper erfordern eine Methode, um den Speicherplatz nach allen möglichen Teilmengen von Features zu durchsuchen, Bewertung seiner Qualität durch Erlernen und Bewerten eines Klassifikators mit dieser Teilmenge von Merkmalen. Der Feature-Auswahlprozess basiert auf einem spezifischen maschinellen Lernalgorithmus, den wir versuchen in einen gegebenen Datensatz einzupassen. Folgt einem gierigen Suchansatz, indem alle möglichen Merkmalskombinationen anhand der Bewertungskriterien bewertet werden. Wrapper-Methoden führen im Allgemeinen zu einer besseren Vorhersagegenauigkeit als Filtermethoden.
Lassen Sie uns einige dieser Techniken analysieren:
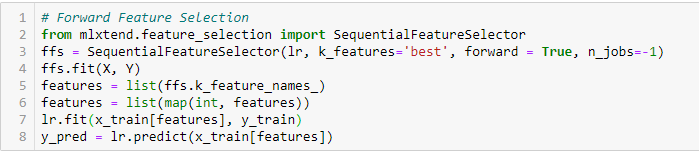
Auswahl erweiterter Funktionen
Dies ist eine iterative Methode, bei der wir mit der Variablen mit der besten Leistung im Vergleich zum Ziel beginnen. Dann, wir wählen eine andere Variable, die in Kombination mit der ersten ausgewählten Variable die beste Leistung bietet. Dieser Vorgang wird fortgesetzt, bis die voreingestellten Kriterien erreicht sind..
Entfernen von Rückwärtsfunktionen
Diese Methode funktioniert genau umgekehrt wie die Vorwärts-Feature-Auswahlmethode.. Hier, wir starten mit allen verfügbaren Funktionen und bauen ein Modell. Dann, wir nehmen die Variable des Modells, die den besten Bewertungsmaßwert liefert. Dieser Vorgang wird fortgesetzt, bis die voreingestellten Kriterien erreicht sind..
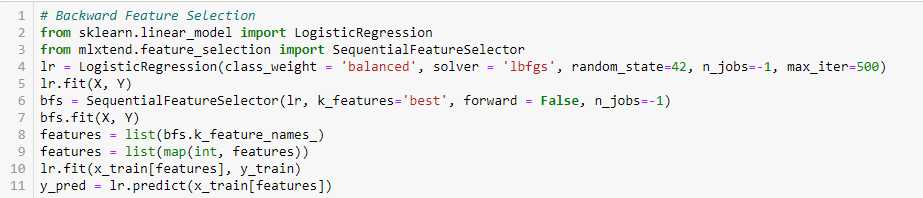
Diese Methode, zusammen mit dem oben besprochenen, auch bekannt als sequentielle Merkmalsauswahlmethode.
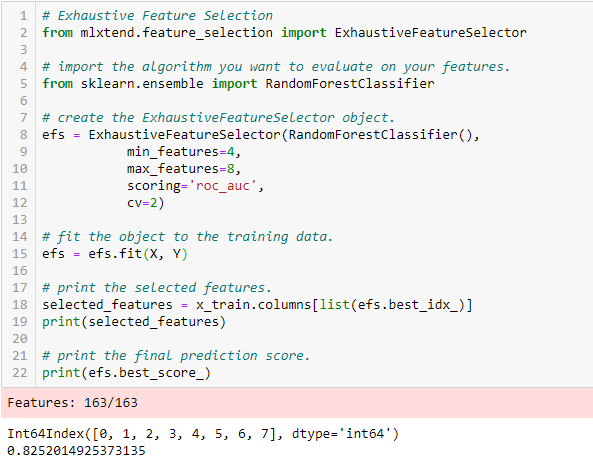
Umfangreiche Funktionsauswahl
Dies ist die bisher robusteste Methode zur Merkmalsauswahl. Dies ist eine Brute-Force-Bewertung jeder Feature-Untergruppe. Dies bedeutet, dass alle möglichen Kombinationen der Variablen ausprobiert werden und die Teilmenge mit der besten Leistung zurückgegeben wird.
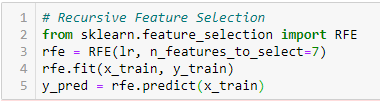
Eliminierung rekursiver Merkmale
‘Gegeben sei ein externer Schätzer, der den Merkmalen Gewichte zuweist (zum Beispiel, die Koeffizienten eines linearen Modells), das Ziel, rekursive Merkmale zu eliminieren (RFE) ist die rekursive Auswahl von Features unter Berücksichtigung immer kleinerer Feature-Sets. Zuerst, Der Schätzer wird mit dem anfänglichen Satz von Merkmalen trainiert und die Bedeutung jedes Merkmals wird durch ein coef_-Attribut oder durch ein feature_importances_-Attribut ermittelt.
Später, weniger wichtige Features werden aus dem aktuellen Feature-Set entfernt. Dieser Vorgang wird rekursiv an dem beschnittenen Satz wiederholt, bis schließlich die gewünschte Anzahl von auszuwählenden Merkmalen erreicht ist.. ‘[2]
C. Integrierte Methoden:
Diese Methoden umfassen die Vorteile sowohl der Wrap- als auch der Filtermethoden., durch Einbeziehen von Merkmalsinteraktionen, aber auch durch Beibehaltung eines angemessenen Rechenaufwands. Integrierte Methoden sind in dem Sinne iterativ, dass sie sich um jede Iteration des Modelltrainingsprozesses kümmern und sorgfältig die Features extrahieren, die am meisten zum Training für eine bestimmte Iteration beitragen..
Lassen Sie uns einige dieser Techniken analysieren, Klicke hier:
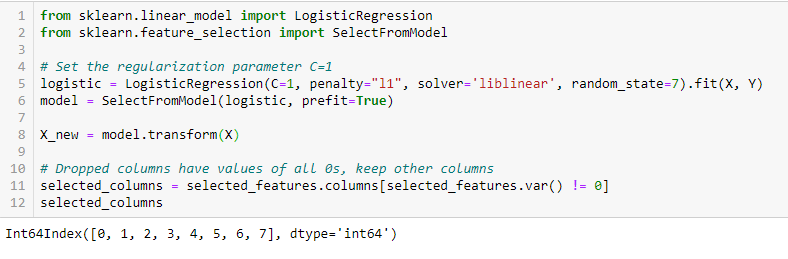
LASSO-Regularisierung (L1)
Die Regularisierung besteht darin, den verschiedenen Parametern des Modells für maschinelles Lernen eine Strafe hinzuzufügen, um die Freiheit des Modells zu reduzieren, nämlich, um eine Überanpassung zu vermeiden. Bei der Regularisierung linearer Modelle, die Strafe wird auf die Koeffizienten angewendet, die jeden der Prädiktoren multiplizieren. Von den verschiedenen Regularisierungsarten, Lasso oder L1 hat die Eigenschaft, einige der Koeffizienten auf Null zu reduzieren. Deswegen, diese Funktion kann aus dem Modell entfernt werden.
Bedeutung des Random Forest
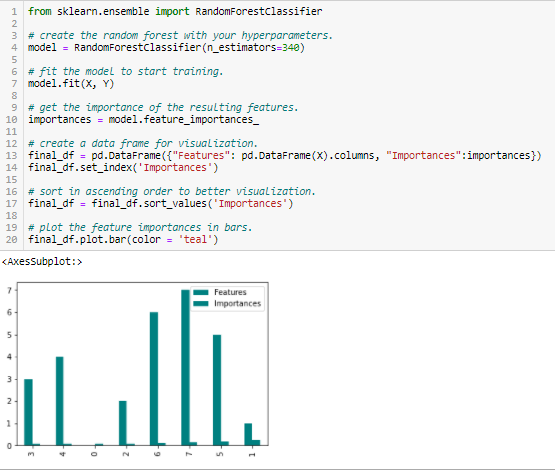
Random Forests ist eine Art Bagging-Algorithmus, der eine bestimmte Anzahl von Entscheidungsbäumen hinzufügt. Baumbasierte Strategien, die von Random Forests verwendet werden, werden natürlich danach eingestuft, wie gut sie die Knotenreinheit verbessern, oder mit anderen Worten, eine Verringerung der Verunreinigung (Gini-Verunreinigung) über alle Bäume. Die Knoten mit dem größten Rückgang an Verunreinigungen treten am Anfang der Bäume auf, während die Noten mit der geringsten Abnahme an Verunreinigungen am Ende der Bäume auftreten. Deswegen, beim Beschneiden von Bäumen unter einem bestimmten Knoten, wir können eine Teilmenge der wichtigsten Merkmale erstellen.
Fazit
Wir haben einige Techniken zur Funktionsauswahl besprochen. Wir haben absichtlich Feature-Extraktionstechniken wie die Hauptkomponentenanalyse belassen, Einzelwertzerlegung, Lineare Diskriminanzanalyse, etc. Diese Methoden tragen dazu bei, die Dimensionalität der Daten oder die Anzahl der Variablen zu reduzieren, während die Varianz der Daten erhalten bleibt..
Abgesehen von den oben besprochenen Methoden, es gibt viele andere Methoden zur Funktionsauswahl. Es gibt auch hybride Methoden, die Filter- und Umhüllungstechniken verwenden.. Wenn Sie mehr über Feature-Auswahltechniken erfahren möchten, meiner Meinung nach, ein hervorragender umfassender Lesestoff wäre ‘Auswahl an Funktionen zur Muster- und Datenerkennung«Siehe Urszula Stańczyk und Lakhmi C.. Jaina.
Verweise
Dokument mit dem Titel 'Effiziente Merkmalsauswahlfilter für hochdimensionale Daten’ von Artur J. Ferreira, Mario AT Figueiredo [1]
https://scikit-learn.org/stable/modules/generated/sklearn.feature_selection.RFE.html%20%5b2%5d [2]





