
Mit steigender Rechenleistung, jetzt können wir Algorithmen auswählen, die sehr intensive Berechnungen durchführen. Einer dieser Algorithmen ist der “Zufälliger Wald”, über die wir in diesem Beitrag sprechen werden. Obwohl der Algorithmus bei verschiedenen Wettbewerben sehr beliebt ist (als Beispiel, die in Kaggle laufen), das Endergebnis des Modells ist wie eine Blackbox und, deshalb, sollte mit Bedacht verwendet werden.
vor dem Fortfahren, Hier ist ein Beispiel für die Relevanz der Auswahl des besten Algorithmus.
Relevanz der Auswahl des richtigen Algorithmus
Gestern sah ich einen Film namens ” Die Ära von El Mañana“. Ich liebte das Konzept und den Denkprozess, der hinter der Handlung dieses Films stand. Lassen Sie mich die Handlung zusammenfassen (ohne den Höhepunkt zu kommentieren, Sicher). Im Gegensatz zu anderen Science-Fiction-Filmen, Dieser Film dreht sich um eine einzige Macht, die auf beiden Seiten verliehen wird (Held und Bösewicht). Power ist die Fähigkeit, den Tag neu zu starten.
Die Menschheit befindet sich im Krieg mit einer exotischen Spezies namens “imitiert”. Mimic wird als eine viel weiter entwickelte Zivilisation beschrieben als eine exotische Spezies. Die gesamte Mimic-Zivilisation ist wie ein einzelner vollständiger Organismus. Es hat ein zentrales Gehirn namens “Omega” die alle anderen Zivilisationsorganismen kontrolliert. Bleiben Sie jede Sekunde mit allen anderen Zivilisationsarten in Kontakt. "Alpha" ist die Hauptkriegerart (wie das Nervensystem) dieser Zivilisation und übernimmt das Kommando von "Omega". “Omega” hat die Macht, den Tag jederzeit neu zu starten.
Jetzt, lasst uns den Hut eines vorausschauenden Analysten tragen, um diese Handlung zu analysieren. Wenn ein System die Möglichkeit hat, den Tag jederzeit neu zu starten, er wird diese Kraft immer dann einsetzen, wenn eine seiner Kriegerspezies stirbt. Ja, deshalb, Es wird keinen einzigen Krieg geben, wenn eine der Kriegerspezies (alfa) wird wirklich sterben, und das Gehirn “Omega” wird wiederholt das beste Szenario testen, um den Tod der Menschheit zu maximieren und die Anzahl der Alpha-Kills zu begrenzen (Kriegerspezies) jeden tag auf null. Das kannst du dir vorstellen als “DAS BESTE” prädiktiver Algorithmus, der jemals erstellt wurde. Es ist buchstäblich unmöglich, einen solchen Algorithmus zu besiegen.
Gehen wir jetzt zurück zu “Zufällige Wälder” anhand einer Fallstudie.
Fallstudie
Unten ist eine Verteilung des Jahreseinkommens Gini Koeffizienten in verschiedenen Ländern:
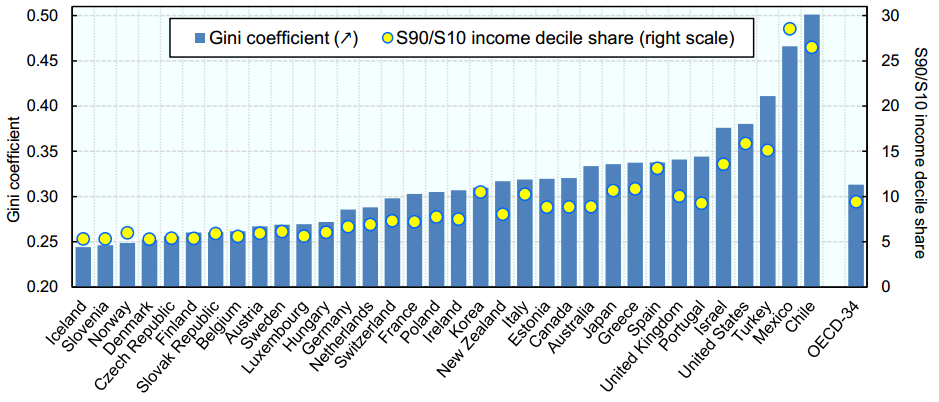
Mexiko hat den zweithöchsten Gini-Koeffizienten und, deshalb, hat eine sehr hohe Segregation im Jahreseinkommen von Arm und Reich. Unsere Aufgabe ist es, einen genauen Vorhersagealgorithmus zu erstellen, um das jährliche Einkommensniveau jedes Einzelnen in Mexiko zu schätzen. Die Einkommensklassen sind wie folgt:
1. Weniger als $ 40,000
2. $ 40 000 – 150 000
3. Mehr von $ 150 000
Nachfolgend finden Sie die Informationen, die für jeden Einzelnen verfügbar sind:
1. Alter, 2. Geschlecht, 3. Höchster Bildungsabschluss, 4. Arbeit in der Industrie, 5. Wohnsitz in Metro / Kein Zähler
Wir müssen einen Algorithmus entwickeln, um eine genaue Vorhersage für eine Person mit den folgenden Merkmalen zu treffen::
1. Alter: 35 Jahre, 2, Geschlecht: Männlich, 3. Höchster Bildungsabschluss: Diplomat, 4. Industrie: Herstellung, 5. Heim: Metro
Wir werden in diesem Beitrag nur über Random Forest sprechen, um diese Vorhersage zu treffen.
Der Random Forest-Algorithmus
Der Random Forest ist wie ein Bootstrap-Algorithmus mit dem Entscheidungsbaummodell (WAGEN). Sagen wir, wir haben 1000 Beobachtungen in der gesamten Bevölkerung mit 10 Variablen. Der Random Forest versucht, mehrere CART-Modelle mit unterschiedlichen Stichproben und unterschiedlichen Anfangsvariablen zu erstellen. Als Beispiel, eine zufällige Stichprobe von 100 Beobachtungen und 5 Zufällig ausgewählte Anfangsvariablen, um ein CART-Modell zu erstellen. Werde den Vorgang wiederholen (Sagen wir) 10 Mal und machen Sie dann eine endgültige Vorhersage für jede Beobachtung. Die endgültige Vorhersage ist eine Funktion jeder Vorhersage. Diese letzte Vorhersage kann einfach der Mittelwert jeder Vorhersage sein.
Zurück zur Fallstudie
Haftungsausschluss: Die Zahlen in diesem Beitrag sind illustrativ
Mexiko hat eine Bevölkerung von 118 MM. Nehmen wir an, der Random Forest-Algorithmus sammelt 10.000 Beobachtungen mit nur einer Variablen (vereinfachen) jedes CART-Modell zu bauen. Gesamt, wir schauen uns das modell von . an 5 CART wird mit verschiedenen Variablen erstellt. In einem echten Lebenshindernis, Sie haben mehr Bevölkerungsstichproben und verschiedene Kombinationen von Eingabevariablen.
Gehaltsbänder:
Band 1: Weniger als $ 40,000
Band 2: $ 40 000 – 150 000
Band 3: mehr von $ 150,000
Nachfolgend die Ergebnisse der 5 verschiedene CART-Modelle.
WAGEN 1: Variables Alter
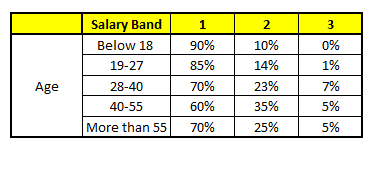
WAGEN 2: Variables Geschlecht
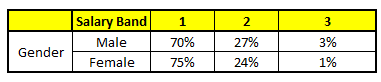
WAGEN 3: Variable Ausbildung
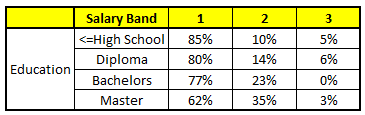
WAGEN 4: Variabler Wohnsitz

WAGEN 5: Variable Branche
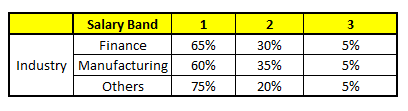
Diese verwenden 5 WARENKORB, wir müssen zu einer einzelnen Wahrscheinlichkeitsmenge gelangen, die zu jeder der Lohnklassen gehört. Vereinfachen, wir werden in dieser Fallstudie nur einen Mittelwert der Wahrscheinlichkeiten nehmen. Abgesehen vom einfachen Mittel, wir betrachten auch die Abstimmungsmethode, um zur endgültigen Prognose zu gelangen. Um die endgültige Prognose zu erreichen, Suchen wir das folgende Profil in jedem CART-Modell:
1. Alter: 35 Jahre, 2, Geschlecht: Männlich, 3. Höchster Bildungsabschluss: Diplomat, 4. Industrie: Herstellung, 5. Heim: Metro
Für jedes dieser CART-Modelle, Die Verteilung zwischen den Gehaltsbändern ist unten dargestellt.:
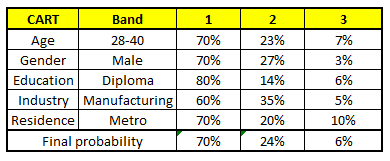
Die endgültige Wahrscheinlichkeit ist einfach der Durchschnitt der Wahrscheinlichkeit in den gleichen Gehaltsbändern in verschiedenen CART-Modellen. Wie Sie in dieser Analyse sehen können, Da ist ein 70% Chancen, dass diese Person in die Klasse fällt 1 (weniger als $ 40,000) und um die 24% Chancen, dass einzelne in die Klasse fallen 2.
Abschließende Anmerkungen
Random Forest bietet viel genauere Vorhersagen im Vergleich zu einfachen CART-Modellen / CHAID oder Regression in vielen Szenarien. Diese Fälle haben im Allgemeinen eine große Anzahl prädiktiver Variablen und eine riesige Stichprobengröße. Dies liegt daran, dass es die Varianz mehrerer Eingangsvariablen gleichzeitig erfasst und eine große Anzahl von Beobachtungen in die Prognose einfließen lässt.. In einigen der nächsten Beiträge, wir werden ausführlicher über den Algorithmus sprechen und darüber sprechen, wie man einen einfachen Zufallswald in R . erstellt.





