Einführung
Ich liebe es mit C . zu arbeiten ++, auch nach der Entdeckung der Programmiersprache Python für maschinelles Lernen. C ++ Es war die erste Programmiersprache, die ich gelernt habe und ich freue mich, sie im Bereich des maschinellen Lernens einzusetzen.
Ich habe in meinem vorherigen Beitrag über das Erstellen von Modellen für maschinelles Lernen geschrieben und die Community liebte die Idee. Ich habe eine überwältigende Antwort erhalten und eine Anfrage hat sich für mich herausgestellt (von mehreren Personen): Gibt es C-Bibliotheken? ++ für maschinelles Lernen?
Es ist eine berechtigte Frage. Sprachen wie Python und R verfügen über eine große Anzahl von Paketen und Bibliotheken, um verschiedenen Aufgaben des maschinellen Lernens gerecht zu werden.. Dann, C ++ Haben Sie ein Angebot dieser Art??

Jawohl, macht es! Ich werde zwei dieser C-Bibliotheken hervorheben ++ in diesem Beitrag, und wir werden sie auch in Aktion sehen (mit Code). Wenn Sie neu bei C . sind ++ für maschinelles Lernen, Ich werde dir wieder empfehlen, den ersten Beitrag zu lesen.
Inhaltsverzeichnis
- Warum sollten wir Bibliotheken für maschinelles Lernen verwenden??
- Bibliotheken für maschinelles Lernen in C ++
- Biblioteca SHARK
- MLPACK-Bibliothek
Warum sollten wir Bibliotheken für maschinelles Lernen verwenden??
Diese Frage werden sich viele Neulinge stellen.. Welche Bedeutung haben Bibliotheken für maschinelles Lernen?? Lassen Sie mich versuchen, Ihnen das in diesem Abschnitt zu erklären.
Nehmen wir an, erfahrene Fachleute und Branchenveteranen haben sich alle Mühe gegeben und eine Lösung für eine Straßensperre gefunden.. Würden Sie das lieber verwenden oder würden Sie lieber Stunden damit verbringen, dasselbe von Grund auf neu zu erstellen?? Wie gewöhnlich, es macht wenig Sinn, sich für die letztere Methode zu entscheiden, vor allem, wenn Sie innerhalb der gesetzten Fristen arbeiten oder lernen.
Das Beste an unserer Machine-Learning-Community ist, dass es bereits viele Lösungen in Form von Bibliotheken und Paketen gibt. Jemand anderes, vom Experten bis zum Enthusiasten, Sie haben sich schon die Mühe gemacht und die Antwort schön verpackt in einer Bibliothek zusammengestellt.
Diese Bibliotheken für maschinelles Lernen sind effizient und optimiert, und gründlich getestet für mehrere Anwendungsfälle. Das Vertrauen in diese Bibliotheken treibt unser Lernen an und macht das Schreiben von Code aus, entweder in C ++ oder Python, viel einfacher und intuitiver sein.
Bibliotheken für maschinelles Lernen in C ++
In diesem Abschnitt, Wir werden uns die beiden beliebtesten Bibliotheken für maschinelles Lernen in C ansehen +:
- Biblioteca SHARK
- MLPACK-Bibliothek
Schauen wir uns jeden einzeln an und sehen wir, wie der C-Code funktioniert ++.
1) Biblioteca SHARK C ++
Shark ist eine schnelle modulare Bibliothek und bietet eine überwältigende Unterstützung für überwachte Lernalgorithmen, als lineare Regression, Neuronale Netze, Gruppierung, k-socken, etc. Es beinhaltet auch die Funktionalität der linearen Algebra und der numerischen Optimierung. Dies sind mathematische Schlüsselfunktionen oder Bereiche, die bei der Ausführung von Aufgaben des maschinellen Lernens sehr wichtig sind.
Wir werden zuerst sehen, wie man Shark installiert und eine Umgebung konfiguriert. Nach, wir implementieren lineare Regression mit Shark.
Installieren Sie Shark und konfigurieren Sie die Umgebung (Ich werde das für Linux tun)
- Shark vertraut Boost und cmake. Glücklicherweise, alle Abhängigkeiten können mit dem folgenden Befehl installiert werden:
sudo apt-get install cmake cmake-curses-gui libatlas-base-dev libboost-all-dev
- So installieren Sie Shark, Führen Sie die folgenden Befehle Zeile für Zeile in Ihrem Terminal aus:
- Klon de git https://github.com/Shark-ML/Shark.git (Sie können auch die Zip-Datei herunterladen und entpacken)
- CD Hai
- mkdir Zusammenstellung
- CD-Build
- cmake ..
- tun
Falls du das noch nicht gesehen hast, das ist kein hindernis. Es ist ziemlich einfach und es gibt viele Informationen online, wenn Sie in Schwierigkeiten geraten. Für Windows und andere Betriebssysteme, Sie können eine schnelle Google-Suche durchführen, um Shark zu installieren. Hier ist die Referenzseite Shark-Installationsanleitung.
Kompilieren Sie Programme mit Shark
Implementieren der linearen Regression mit Shark
Mein erster Beitrag in dieser Serie hatte eine Einführung in die lineare Regression. Ich werde die gleiche Idee in diesem Beitrag verwenden, aber diesmal mit der Shark C-Bibliothek ++.
Initialisierungsphase
Wir beginnen mit der Einbeziehung der Bibliotheken und Header-Funktionen für die lineare Regression:
Als nächstes kommt der Datensatz. Ich habe zwei CSV-Dateien erstellt. Die Datei input.csv enthält die x-Werte und die Datei labels.csv enthält die y-Werte. Unten ist eine Momentaufnahme der Daten:
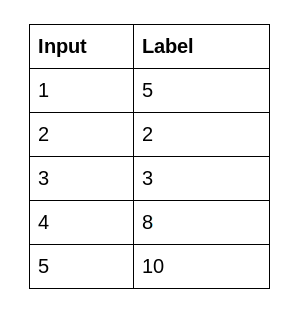
Beide Dateien finden Sie hier: Maschinelles Lernen mit C ++. Zuerst, wir werden Datencontainer erstellen, um die Werte der CSV-Dateien zu speichern:
Dann, wir müssen sie importieren. Shark kommt mit einer netten CSV-Importfunktion, und wir geben den Datencontainer an, den wir initialisieren möchten, und auch der Speicherort der CSV-Pfaddatei:
Nach, wir müssen einen Regressions-Dataset-Typ instanziieren. Jetzt, Dies ist nur ein allgemeines Objekt für die Regression, und was wir im Konstruktor tun werden, ist unsere Eingaben und auch unsere Labels für die Daten zu übergeben.
Dann, Wir müssen das lineare Regressionsmodell trainieren. wie machen wir das? Wir müssen einen Trainer instanziieren und ein lineares Modell erstellen:
Trainingsphase
Dann kommt der entscheidende Schritt, in dem wir das Modell wirklich trainieren. Hier, Der Coach hat eine Member-Funktion namens Bahn. Dann, diese Funktion trainiert dieses Modell und findet die Parameter für das Modell, was genau wollen wir machen.
Vorhersagephase
Abschließend, Lassen Sie uns die Modellparameter generieren:
Lineare Modelle haben eine Memberfunktion namens wieder gut machen was den Schnittpunkt der Geraden der besten Anpassung erzeugt. Dann, wir erzeugen eine Matrix anstelle eines Multiplikators. Dies liegt daran, dass das Modell verallgemeinert werden kann (nicht nur linear, könnte ein Polynom sein).
Wir berechnen die Linie der besten Anpassung, indem wir die kleinsten Quadrate minimieren, Mit anderen Worten, Minimierung des Verlusts im Quadrat.
Dann, Glücklicherweise, Das Modell ermöglicht es uns, diese Informationen zu generieren. Die Shark-Bibliothek ist sehr nützlich, um einen Hinweis darauf zu geben, wie gut die Modelle passen:
Zuerst, wir müssen ein quadriertes Verlustobjekt initialisieren, und dann müssen wir einen Datencontainer instanziieren. Nach, die Prognose wird basierend auf den Eingaben in das System berechnet, Und dann machen wir nur noch den Verlust, die berechnet wird, indem die Labels und auch der Vorhersagewert übergeben werden.
Abschließend, wir müssen kompilieren. Im Terminal, Geben Sie den folgenden Befehl ein (Stellen Sie sicher, dass das Verzeichnis richtig konfiguriert ist):
g++ -o lr linear_regression.cpp -std=c++11 -lboost_serialization -lshark -lcblas
Einmal kompiliert, würde erstellt haben lr Objekt. Jetzt einfach das Programm ausführen. Die Ausgabe, die wir erhalten, ist:
B : [1](-0,749091)
EIN :[1,1]((2.00731))
Hat verloren: 7.83109
Der Wert von b ist ein bisschen weit von 0, aber das liegt am rauschen auf den etiketten. Der Wert des Multiplikators liegt nahe bei 2, was ziemlich äquivalent zu den Daten ist. Und so können Sie die Shark-Bibliothek in C verwenden! ++ um ein lineares Regressionsmodell zu erstellen!
2) MLPACK C-Bibliothek ++
mlpack ist eine schnelle und flexible Bibliothek für maschinelles Lernen, die in C . geschrieben ist ++. Sein Ziel ist es, schnelle und erweiterbare Implementierungen modernster Algorithmen für maschinelles Lernen bereitzustellen. mlpack stellt diese Algorithmen als einfache Kommandozeilenprogramme zur Verfügung, verließ die Python, Julia Links und C-Klassen ++ die dann in größere Machine-Learning-Lösungen integriert werden können.
Wir werden zuerst sehen, wie man mlpack und die Konfigurationsumgebung installiert. Dann implementieren wir den k-means-Algorithmus mit mlpack.
mlpack und die Konfigurationsumgebung installieren (Ich werde das für Linux tun)
mlpack hängt von den folgenden Bibliotheken ab, die auf dem System installiert werden müssen und über Header verfügen:
- Gürteltier> = 8.400.0 (mit LAPACK-Unterstützung)
- Schub (math_c99, program_options, Serialisierung, unit_test_framework, Haufen, Geist)> = 1.49
- verkleinern> = 2.10.0
Unter Ubuntu und Debian, Sie können alle diese Abhängigkeiten erhalten, indem Sie fit:
sudo apt-get install libboost-math-dev libboost-program-options-dev libboost-test-dev libboost-serialization-dev binutils-dev python-pandas python-numpy cython python-setuptools
Jetzt sind alle Abhängigkeiten auf Ihrem System installiert, Sie können die folgenden Befehle direkt ausführen, um mlpack zu kompilieren und zu installieren:
- wget
- tar -xvzpf mlpack-3.2.2.tar.gz
- mkdir mlpack-3.2.2 / kompilieren && CD mlpack-3.2.2 / bauen
- cmake ../
- mache -j4 # Das -j ist die Anzahl der Kerne, die Sie für einen Build verwenden möchten
- sudo machen installieren
Auf vielen Linux-Systemen, mlpack wird standardmäßig installiert für / usr / lokal / lib und Sie müssen möglicherweise die Umgebungsvariable LD_LIBRARY_PATH setzen:
exportiere LD_LIBRARY_PATH=/usr/local/lib
Die obigen Anweisungen sind der einfachste Weg, um, mlpack kompilieren und installieren. Wenn Ihre Linux-Distribution Binärdateien unterstützt, Folgen Sie dieser Site, um mlpack je nach Distribution mit einem einzeiligen Befehl zu installieren: MLPACK-Installationsanweisungen. Die obige Methode funktioniert für alle Distributionen.
Kompilieren Sie Programme mit mlpack
- Binden Sie die relevanten Header-Dateien in Ihr Programm ein (unter der Annahme einer k-means-Implementierung):
-
- #enthalten
- #enthalten
- #enthalten
- Zum Kompilieren müssen wir die folgenden Bibliotheken verlinken:
-
- std = c ++ 11 -larmadillo -lmlpack -lboost_serialization
Implementando K-Means con mlpack
K-means ist ein zentroidbasierter Algorithmus, oder ein entfernungsbasierter Algorithmus, wobei wir die Entfernungen berechnen, um einen Punkt einer Gruppe zuzuordnen. En K-Mittel, jede Gruppe bezieht sich auf einen Schwerpunkt.
Das Hauptziel des K-Means-Algorithmus besteht darin, die Summe der Abstände zwischen den Punkten und ihrem jeweiligen Clusterschwerpunkt zu minimieren.
K-Means ist praktisch ein iteratives Verfahren, bei dem wir die Daten in bestimmte Gruppen segmentieren wollen. Zuerst, wir weisen einige Anfangsschwerpunkte zu, also können diese absolut zufällig sein. Dann, für jeden Datenpunkt, wir finden den nächsten Schwerpunkt. Dann weisen wir diesen Datenpunkt diesem Schwerpunkt zu. Dann, jeder Schwerpunkt repräsentiert eine Klasse. Und sobald wir jedem Schwerpunkt alle Datenpunkte zugewiesen haben, Wir berechnen den Mittelwert dieser Schwerpunkte.
Für ein detailliertes Verständnis des K-Means-Algorithmus, Lesen Sie dieses Tutorial: Die umfassendste Anleitung zum Gruppieren von K-Mitteln, die Sie jemals brauchen werden.
Hier, wir implementieren k-means mit der mlpack-Bibliothek in C ++.
Initialisierungsphase
Wir beginnen damit, dass wir die Bibliotheken und Header-Funktionen für k-means einschließen:
Dann, Wir werden einige grundlegende Variablen erstellen, um die Anzahl der Cluster zu bestimmen, die Dimensionalität des Programms, die Anzahl der Samples und die maximale Anzahl von Iterationen, die wir durchführen möchten. Warum? Weil K-Means ein iteratives Verfahren ist.
Dann, wir erstellen die daten. Hier werden wir also zuerst die Gürteltier Bücherei. Wir werden eine Kartenklasse erstellen, die effektiv ein Datencontainer ist:
Da gehst du! Diese Klassenmatte, die Daten des Objekts, das Sie haben, wir haben ihm eine Dimensionalität von zwei gegeben, und er weiß, dass er es haben wird 50 Proben, und Sie haben all diese Datenwerte initialisiert, um zu sein 0.
Dann, Wir werden dieser Datenklasse einige zufällige Daten zuweisen und dann K-Means effektiv ausführen. Ich werde erstellen 25 Punkte um Position 1 1, und wir können dies tun, indem wir effektiv sagen, dass jeder Datenpunkt 1 1 oder an Position X ist gleich 1, und ist gleich 1. Nach, wir werden ein paar zufällige Geräusche hinzufügen. für jeden der 25 Datenpunkte. Sehen wir uns das in Aktion an:
Hier, gehen von 0 ein 25, die i-te Spalte muss dieser Waffentypvektor an Position . sein 11, und dann werden wir eine gewisse Menge an zufälligem Rauschen der Größe hinzufügen 2. Dann, wird a sein Der zweidimensionale Zufallsrauschvektor multipliziert mit 0,25 bis zu dieser Position, und das wird unsere Datenspalte. Und dann machen wir genau dasselbe für den Punkt x ist gleich 2 und y ist gleich 3.
Und unsere Daten sind fertig! Zeit für die Trainingsphase.
Trainingsphase
Dann, erste, Lassen Sie uns einen Mattenwaffen-Reihentyp instanziieren, um die Gruppen zu enthalten, und dann instanziieren wir eine Mattenwaffe, um die Schwerpunkte zu enthalten:
Jetzt, wir müssen eine Instanz der K-Means-Klasse erstellen:
Wir haben die K-Means-Klasse instanziiert und die maximale Anzahl von Iterationen angegeben, die an den Konstruktor übergeben werden sollen. So, jetzt können wir weitermachen und gruppieren.
Wir nennen die Memberfunktion Cluster dieser Klasse K-means. Wir müssen die Daten weitergeben, die Anzahl der Cluster, und dann müssen wir auch das Cluster-Objekt und das Schwerpunktobjekt übergeben.
Jetzt, Diese Clusterfunktion führt K-Means auf diesen Daten mit einer bestimmten Anzahl von Clustern aus, und dann werden diese beiden Objekte initialisiert: Cluster und Schwerpunkte.
Ergebnisse generieren
Die Ergebnisse können wir einfach über die Schwerpunkte.print Funktion. Dadurch erhalten Sie die Position der Schwerpunkte:
Dann, wir müssen kompilieren. Im Terminal, Geben Sie den folgenden Befehl ein (nochmal, Stellen Sie sicher, dass das Verzeichnis richtig konfiguriert ist):
g++ k_means.cpp -o kmeans_test -O3 -std=c++11 -larmadillo -lmlpack -lboost_serialization && ./kmeans_test
Einmal kompiliert, hätte ein kmeans-Objekt erstellt. Jetzt einfach das Programm ausführen. Die Ausgabe, die wir erhalten, ist:
Schwerpunkte:
0,9497 1,9625
0,9689 3,0652
Und das ist!
Abschließende Anmerkungen
In diesem Beitrag, Wir haben zwei beliebte Machine-Learning-Bibliotheken gesehen, die uns bei der Implementierung von Machine-Learning-Modellen in c . helfen ++. Ich liebe die umfangreiche Unterstützung, die in der offiziellen Dokumentation verfügbar ist, also schau es dir an. Wenn du Hilfe benötigst, Kontaktieren Sie mich unten und ich melde mich gerne bei Ihnen zurück.
Im nächsten Beitrag, Wir werden einige interessante Machine-Learning-Modelle wie Entscheidungsbäume und Random Forest implementieren. Also bleibt gespannt!





