Überblick:
- Erfahren Sie, was Big Data ist und wie relevant es in der heutigen Welt ist
- Kennen Sie die Eigenschaften von Big Data
Einführung
Der Begriff “Big Data” es ist eine falsche Bezeichnung, da dies impliziert, dass die bereits vorhandenen Daten irgendwie klein sind (Sie sind nicht) oder dass die einzige Herausforderung die Größe ist (Größe ist eine davon, aber es sind oft mehr ).
Zusammenfassend, Der Begriff Big Data bezieht sich auf Informationen, die mit herkömmlichen Verfahren oder Tools nicht verarbeitet oder analysiert werden können.

Zunehmend, Unternehmen sehen sich heute immer mehr Herausforderungen im Zusammenhang mit Big Data gegenüber. Sie haben Zugang zu einer Fülle von Informationen, aber sie wissen nicht, wie sie einen Wert daraus ziehen können, weil sie in ihrer gröbsten Form oder in einem halbstrukturierten oder unstrukturierten Format vorliegen; und als Ergebnis, Sie wissen nicht einmal, ob es sich lohnt zu behalten (oder auch wenn sie es behalten können).
In diesem Artikel, Wir analysieren das Konzept von Big Data und worum es dabei geht.
Inhaltsverzeichnis
- Was ist Big Data??
- Merkmale von Big Data
- Datenvolumen
- Die Vielfalt der Daten
- Datengeschwindigkeit
Was ist Big Data??
Wir sind ein Teil davon, jeden Tag!
Eine IBM-Umfrage ergab, dass mehr als die Hälfte der heutigen Führungskräfte erkennen, dass sie keinen Zugriff auf die Informationen haben, die sie für ihre Arbeit benötigen. Unternehmen stehen diesen Herausforderungen in einem Klima gegenüber, in dem sie die Möglichkeit haben, alles zu speichern und Daten zu generieren wie nie zuvor in der Geschichte.; kombiniert, das stellt eine echte informationsherausforderung dar.

Es ist ein Rätsel: Unternehmen haben heute mehr Zugang zu potenziellen Informationen als je zuvor, aber trotzdem, wie sich diese potenzielle Goldmine an Daten anhäuft, Der Prozentsatz der Daten, die das Unternehmen verarbeiten kann, wird schnell reduziert. In einer Nussschale, das Big-Data-Zeitalter ist heute in vollem Gange, denn die Welt verändert sich.
Durch Instrumentierung, wir können mehr Dinge fühlen und, wenn wir es fühlen können, wir neigen dazu, es zu speichern (oder zumindest ein Teil davon). Durch Fortschritte in der Kommunikationstechnologie, Menschen und Dinge sind zunehmend miteinander verbunden, und nicht nur manchmal, aber die ganze zeit. Diese Interkonnektivitätsgebühr ist ein außer Kontrolle geratener Zug. Allgemein bekannt als Maschine zu Maschine (M2M), Interkonnektivität ist verantwortlich für zweistellige Datenwachstumsraten von Jahr zu Jahr (YoY).
Schließlich, weil kleine ICs jetzt so günstig sind, Wir können fast allem Intelligenz hinzufügen. Sogar etwas so Alltägliches wie ein Eisenbahnwaggon hat Hunderte von Sensoren. In einem Eisenbahnwaggon, Diese Sensoren verfolgen Dinge wie Bedingungen, die der Wagen erlebt, den Status von Einzelteilen und GPS-basierte Daten für Tracking und Versandlogistik. Nach Zugentgleisungen, die viele Menschenleben forderten, Regierungen haben Vorschriften für die Speicherung und Analyse dieser Art von Daten eingeführt, um zukünftige Katastrophen zu verhindern.
Auch Eisenbahnwaggons werden immer intelligenter: Prozessoren wurden hinzugefügt, um Daten von Sensoren an verschleißanfälligen Teilen zu interpretieren, wie Lager, um Teile zu identifizieren, die repariert werden müssen, bevor sie ausfallen und weiteren Schaden anrichten, oder noch schlimmer, ein Disaster. Aber nicht nur die Waggons sind smart, echte Schienen haben alle paar Meter Sensoren. Was ist mehr, Anforderungen an die Datenspeicherung gelten für das gesamte Ökosystem: Autos, Schienen, Bahnübergangssensoren, Wettermuster, die Bahnbewegungen verursachen, etc.
Fügen Sie dies nun hinzu, um die Ladung eines Waggons zu verfolgen, An- und Abfahrtszeiten, und Sie sehen sehr schnell, dass Sie ein Big-Data-Problem in der Hand haben. Auch wenn jedes Bit dieser Daten relational war (und es ist nicht), sie werden alle roh sein und sehr unterschiedliche Formate haben, was eine Verarbeitung in einem traditionellen relationalen System unpraktisch oder unmöglich macht. Die Waggons sind nur ein Beispiel, aber wohin wir auch schauen, wir sehen Domains mit Geschwindigkeit, Volumen und Vielfalt, die zusammen das Big-Data-Problem erzeugen.
Was sind die Merkmale von Big Data??
Drei Merkmale definieren Big Data: Volumen, Abwechslung und Geschwindigkeit.
Dichtungen, diese Eigenschaften definieren "Große Daten". Sie haben die Notwendigkeit einer neuen Klasse von Fähigkeiten geschaffen, um die Art und Weise, wie Dinge heute getan werden, zu erweitern, um eine bessere Sicht und Kontrolle über unsere bestehenden Wissensdomänen und die Fähigkeit zu bieten, darauf zu reagieren..
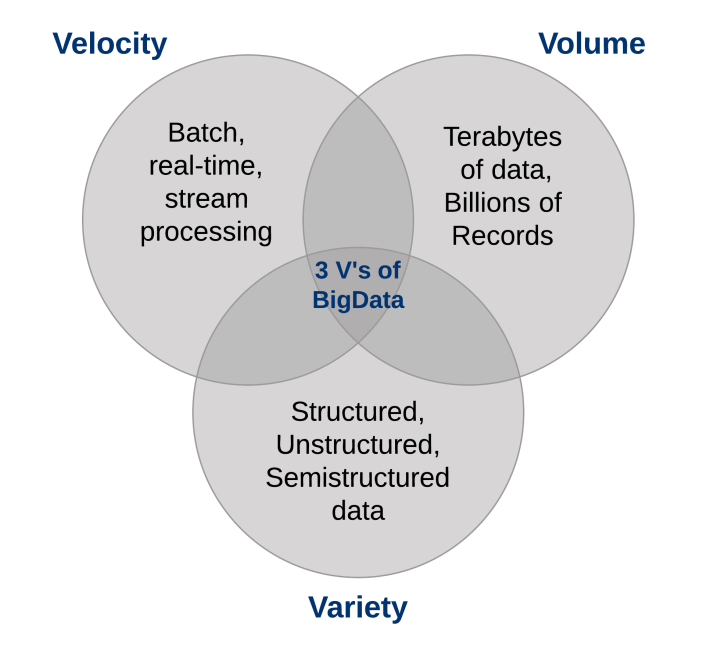
1. Datenvolumen
Die schiere Menge an Daten, die heute gespeichert wird, steigt in die Höhe. Im Jahr 2000, sie wurden gespeichert 800.000 Petabyte (PB) von Daten in der Welt. Natürlich, Viele der Daten, die heute erstellt werden, werden überhaupt nicht analysiert und das ist ein weiteres Thema, das berücksichtigt werden muss. Diese Zahl wird voraussichtlich erreicht 35 Zettabytes (ZB) zu 2020. Twitter generiert nur mehr als 7 Terabyte (TB) von Daten jeden Tag, Facebook 10 TB und einige Unternehmen generieren stündlich an jedem Tag des Jahres Terabyte an Daten. Es ist nicht mehr ungewöhnlich, dass einzelne Unternehmen über Speichercluster mit Petabyte an Daten verfügen.

Wenn du aufhörst und darüber nachdenkst, Es ist irgendwie seltsam, dass wir in Daten ertrinken. Wir lagern alles: Umweltdaten, Finanzdaten, medizinische Daten, Überwachungsdaten und die Liste geht weiter und weiter. Zum Beispiel, Wenn du dein Smartphone aus der Hülle nimmst, wird ein Ereignis erzeugt; wenn sich die Tür Ihres S-Bahn zum Einsteigen öffnet, Es ist eine Veranstaltung; registriere dich, um ein Flugzeug zu nehmen, Arbeit eingeben, einen Song bei iTunes kaufen, wechsel den fernsehkanal, eine elektronische Mautroute nehmen: jede dieser Aktionen generiert Daten.
Sich einigen, du verstehst den Punkt: es gibt mehr Daten denn je und alles, was Sie tun müssen, ist die Terabyte-Penetrationsrate für Heim-PCs als verräterisches Zeichen zu betrachten. Früher führten wir eine Liste aller uns bekannten Datenspeicher, die vor fast einem Jahrzehnt ein Terabyte überschritten haben; Es genügt zu sagen, dass sich die Dinge in Bezug auf die Lautstärke geändert haben.
Wie der Begriff schon sagt “Big Data”, Unternehmen sind mit riesigen Datenmengen konfrontiert. Organisationen, die nicht wissen, wie sie diese Daten verwalten sollen, sind davon überfordert. Aber die Möglichkeit besteht, mit der richtigen technologischen Plattform, um fast alle Daten zu analysieren (oder zumindest mehr von ihnen, die die für Sie nützlichen Daten identifizieren) um Ihr Geschäft besser zu verstehen, Ihre Kunden und der Markt. Und dies führt zu dem aktuellen Rätsel, mit dem sich Unternehmen aller Branchen heute konfrontiert sehen..
Mit zunehmender Datenmenge, die dem Unternehmen zur Verfügung steht, der Prozentsatz der Daten, die verarbeitet werden können, Verstehen und Analysieren nimmt ab, so entsteht die blinde Zone.
Was ist in dieser blinden Zone??
Du weisst es nicht: es kann etwas tolles sein oder vielleicht gar nichts, aber das "ich weiß nicht" ist das problem (oder die Gelegenheit, je nachdem wie man es betrachtet). Die Diskussion über Datenmengen hat sich von Terabyte zu Petabyte verlagert, mit einer unvermeidlichen Verschiebung zu Zettabytes, und all diese Daten können nicht in Ihren herkömmlichen Systemen gespeichert werden.
2. Die Vielfalt der Daten
Das mit dem Big-Data-Phänomen verbundene Volumen bringt neue Herausforderungen für Rechenzentren mit sich, die versuchen, damit umzugehen: seine Vielfalt.
Mit der Explosion von Sensoren und intelligenten Geräten, sowie Social Collaboration-Technologien, Daten in einem Unternehmen sind komplex geworden, weil sie nicht nur traditionelle relationale Daten enthalten, aber auch Rohdaten, halbstrukturierte und unstrukturierte Webseiten, Weblog-Dateien (einschließlich Clickstream-Daten), Suchindizes, Social-Media-Foren, Email, Unterlagen, Sensordaten von aktiven und passiven Systemen, etc.
Was ist mehr, Herkömmliche Systeme haben möglicherweise Schwierigkeiten, die zum Verständnis des Inhalts dieser Datensätze erforderlichen Analysen zu speichern und durchzuführen, da viele der generierten Informationen für herkömmliche Datenbanktechnologien nicht geeignet sind.. Durch meine Erfahrung, obwohl sich einige Unternehmen auf dem Weg dorthin bewegen, allgemein, die meisten fangen gerade erst an, die Möglichkeiten von Big Data zu verstehen.
In einer Nussschale, die Vielfalt repräsentiert alle Datentypen: eine grundlegende Änderung von den Anforderungen der traditionellen strukturierten Datenanalyse hin zur Einbeziehung von Rohdaten, halbstrukturiert und unstrukturiert als Teil des Wissens- und Entscheidungsprozesses. Herkömmliche Analyseplattformen können mit Vielfalt nicht umgehen. Aber trotzdem, Der Erfolg einer Organisation hängt von ihrer Fähigkeit ab, Wissen aus den verschiedenen verfügbaren Datentypen zu extrahieren, die sowohl traditionelle als auch nicht-traditionelle umfassen.
Wenn wir auf unsere Datenbankkarrieren zurückblicken, manchmal ist es demütigend zu sehen, dass wir mehr Zeit nur im 20 Prozent der Daten: der relationale Typ, der perfekt formatiert ist und sich gut in unsere strengen Schemata einfügt. Aber die Wahrheit ist, dass die 80 Prozent der weltweiten Daten (und immer mehr dieser Daten sind dafür verantwortlich, neue Rekorde bei Geschwindigkeit und Lautstärke aufzustellen) sind nicht strukturiert oder, Im besten Fall, halbstrukturiert. Wenn Sie sich einen Twitter-Feed ansehen, Sie sehen die Struktur im JSON-Format, aber der eigentliche Text ist unstrukturiert und das Verständnis kann sich lohnen.
Videobilder und Bilder werden nicht einfach oder effizient in einer relationalen Datenbank gespeichert, bestimmte Ereignisinformationen können sich dynamisch ändern (wie Wettermuster), was nicht für strenge Schemata geeignet ist, und mehr. Um von der Big-Data-Chance zu profitieren, Unternehmen müssen alle Arten von Daten analysieren können, sowohl relational als auch nicht-relational: Text, Sensordaten, Audio-, Video, transaktional und mehr.
3. Datengeschwindigkeit
Genauso wie sich die Menge und Vielfalt der von uns gesammelten Daten geändert hat und der Speicher, auch die Geschwindigkeit, mit der sie erzeugt und verarbeitet werden müssen, hat sich geändert. Ein konventionelles Verständnis von Geschwindigkeit berücksichtigt im Allgemeinen, wie schnell Daten ankommen und gespeichert werden, und die damit verbundenen Wiederfindungsraten. Das alles schnell zu managen ist gut, und die Datenmengen, die wir sehen, sind eine Folge der Geschwindigkeit, mit der die Daten ankommen.
Um sich der Geschwindigkeit anzupassen, eine neue Denkweise über ein Problem muss am Ausgangspunkt der Daten beginnen. Anstatt den Geschwindigkeitsgedanken auf die Wachstumsraten Ihrer Datenbestände zu beschränken, Wir empfehlen Ihnen, diese Definition auf Daten in Bewegung anzuwenden: die Geschwindigkeit, mit der Daten fließen.
Schließlich, Wir sind uns einig, dass Unternehmen heute mit Petabytes an Daten statt mit Terabytes umgehen, und das Aufkommen von RFID-Sensoren und anderen Informationsflüssen hat zu einem konstanten Datenfluss mit einer Geschwindigkeit geführt, die dies für herkömmliche Systeme unmöglich gemacht hat. handhaben. Manchmal, Einen Vorteil gegenüber der Konkurrenz zu erlangen kann bedeuten, einen Trend zu erkennen, Problem oder Gelegenheit nur Sekunden, oder sogar Mikrosekunden, vor jemand anderem.
Was ist mehr, immer mehr Daten, die heute produziert werden, haben eine sehr kurze Haltbarkeit, Daher müssen Unternehmen in der Lage sein, diese Daten nahezu in Echtzeit zu analysieren, wenn sie in diesen Daten wertvolle Erkenntnisse gewinnen möchten.. In traditioneller Verarbeitung, Sie können sich vorstellen, Abfragen mit relativ statischen Daten auszuführen: zum Beispiel, die Abfrage “Zeig mir alle Menschen, die im ABC-Überschwemmungsgebiet leben” würde zu einem einzigen Ergebnissatz führen, der als eingehende Wetterwarnliste verwendet würde. Muster. Mit Flow-Computing, Sie können einen Prozess ausführen, der einer kontinuierlichen Abfrage ähnelt, die Personen identifiziert, die sich gerade befinden “in den ABC-Überschwemmungsgebieten”, Sie erhalten jedoch kontinuierlich aktualisierte Ergebnisse, da die Standortinformationen aus den GPS-Daten in Echtzeit aktualisiert werden.
Der effektive Umgang mit Big Data erfordert, dass Sie die Datenmenge und -vielfalt analysieren, während sie noch in Bewegung sind., nicht nur nachdem sie in ruhe sind. Betrachten Sie Beispiele von der Nachverfolgung der Gesundheit von Neugeborenen bis hin zu den Finanzmärkten; auf alle Fälle, erfordern einen neuen Umgang mit der Menge und Vielfalt der Daten.
Abschließende Anmerkungen
Sie können es sich nicht leisten, alle Daten zu untersuchen, die Ihnen in Ihren traditionellen Prozessen zur Verfügung stehen; es sind zu viele Daten mit zu wenig bekanntem Wert und zu hohen abgesteckten Kosten. Big-Data-Plattformen bieten Ihnen die Möglichkeit, all diese Daten kostengünstig zu speichern und zu verarbeiten und herauszufinden, was wertvoll ist und was es wert ist, genutzt zu werden. Was ist mehr, da wir über Datenanalyse im Ruhezustand und Daten in Bewegung sprechen, Die tatsächlichen Daten, aus denen Sie einen Wert finden können, sind nicht nur umfassender, sie können sie auch schneller in Echtzeit verwenden und analysieren.
Ich empfehle Ihnen, diese Artikel zu lesen, um sich mit den Tools für Big Data vertraut zu machen:
Teilen Sie uns Ihre Gedanken in den Kommentaren unten mit..
Referenz
Big Data verstehen: Analytics für Hadoop und Streaming-Daten der Enterprise-Klasse.





