Dieser Artikel wurde im Rahmen der Data Science Blogathon
Einführung
Die Stimmungsanalyse bezieht sich auf die Identifizierung und Klassifizierung der Gefühle, die in der Quelle des Textes ausgedrückt werden. Tweets sind oft nützlich, um nach der Analyse eine große Menge an Stimmungsdaten zu generieren. Diese Daten sind nützlich, um die Meinung der Menschen zu einer Vielzahl von Themen zu verstehen..
Deswegen, wir müssen ein entwickeln Automatisiertes Machine-Learning-Sentimentanalysemodell um die Kundenwahrnehmung zu berechnen. Aufgrund des Vorhandenseins von nicht nützlichen Zeichen (zusammenfassend als Lärm bezeichnet) zusammen mit nützlichen Daten, schwierig, Modelle in ihnen zu implementieren.
In diesem Artikel, Unser Ziel ist es, die Stimmung der Tweets zu analysieren, die von der . bereitgestellt werden Datensatz Sentiment140 durch die Entwicklung einer Pipeline für maschinelles Lernen, die die Verwendung von drei Klassifikatoren umfasst (Logistische Regression, Bernoulli Naive Bayes und SVM) zusammen mit der Verwendung Begriff Häufigkeit – Beleghäufigkeit umkehren (TF-IDF). Die Leistung dieser Klassifikatoren wird dann mit Präzision Ja F1-Ergebnisse.

Bildquelle: Google Bilder
Problemstellung
In diesem Projekt, wir versuchen a . umzusetzen Twitter-Sentiment-Analysemodell was hilft, die Herausforderungen bei der Identifizierung von Stimmungen aus Tweets zu überwinden. Die erforderlichen Angaben zum Datensatz sind:
Der bereitgestellte Datensatz ist der Datensatz Sentiment140 bestehend aus 1,600,000 twittert die mit der Twitter API extrahiert wurden. Die verschiedenen im Datensatz vorhandenen Spalten sind:
- Zielsetzung: die Polarität des Tweets (positiv oder negativ)
- Kennungen: Eindeutige Tweet-ID
- Datum: das Datum des Tweets
- Flagge: Bezieht sich auf die Abfrage. Wenn es keine solche Abfrage gibt, dann ist es KEINE BERATUNG.
- Nutzername: Bezieht sich auf den Namen des Benutzers, der getwittert hat.
- Text: Bezieht sich auf den Text des Tweets.
Projektpipeline
Die verschiedenen Schritte bei der Pipeline für maschinelles Lernen ist es so :
- Erforderliche Abhängigkeiten importieren
- Lesen und laden Sie den Datensatz
- Explorative Datenanalyse
- Datenvisualisierung von Zielvariablen
- Datenvorverarbeitung
- Teilen Sie unsere Daten in Trainings- und Testuntergruppen auf
- Transformieren Sie den Datensatz mit dem TF-IDF Vectorizer
- Funktion zur Modellbewertung
- Bau des Modells
- Fazit
Lasst uns beginnen,
Paso 1: Importieren Sie die notwendigen Abhängigkeiten
# Versorgungsunternehmen
Importieren
numpy als np importieren
Pandas als pd importieren
# Plotten
Seegeboren als sns importieren
aus Wordcloud importieren WordCloud
import matplotlib.pyplot als plt
# nltk
aus nltk.stem importieren WordNetLemmatizer
# sklearn
aus sklearn.svm importieren LinearSVC
von sklearn.naive_bayes importieren BernoulliNB
from sklearn.linear_model import LogisticRegression
aus sklearn.model_selection import train_test_split
aus sklearn.feature_extraction.text import TfidfVectorizer
von sklearn.metrics importieren Confusion_matrix, Klassifizierungsbericht
Paso 2: den Datensatz lesen und laden
# Importieren des Datensatzes
DATASET_COLUMNS=['Ziel','ids','Datum','Flagge','Benutzer','Text']
DATASET_ENCODING = "ISO-8859-1"
df = pd.read_csv('Project_Data.csv', Kodierung=DATASET_ENCODING, name=DATASET_COLUMNS)
df.probe(5)
Produktion:

Paso 3: Explorative Datenanalyse
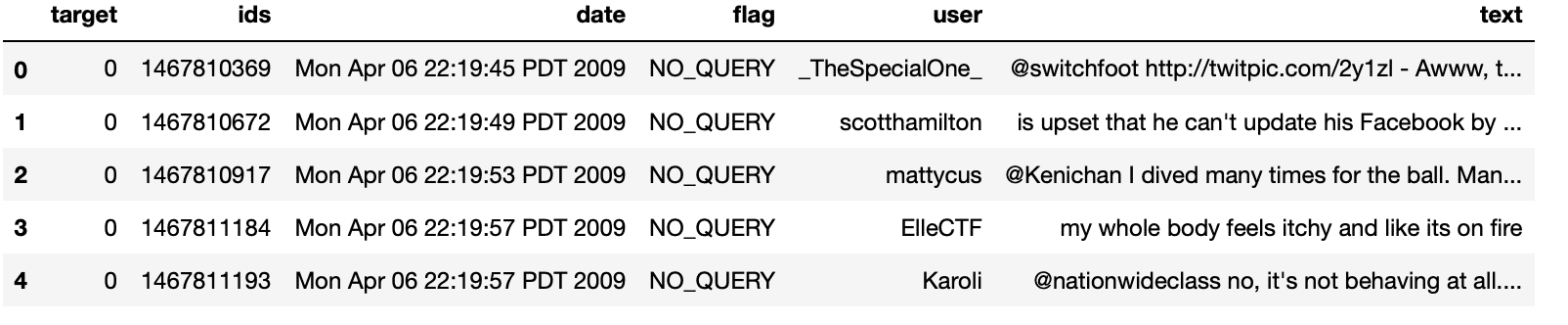
3.1: Fünf Hauptdatenregister
df.kopf()
Produktion:
3.2: Säulen / Merkmale in den Daten
df.spalten
Produktion:
Index(['Ziel', 'ids', 'Datum', 'Flagge', 'Benutzer', 'Text'], dtyp="Objekt")
3.3: Datensatzlänge
drucken('Länge der Daten ist', len(df))
Produktion:
Länge der Daten ist 1048576
3.4: Datenformular
df. Form
Produktion:
(1048576, 6)
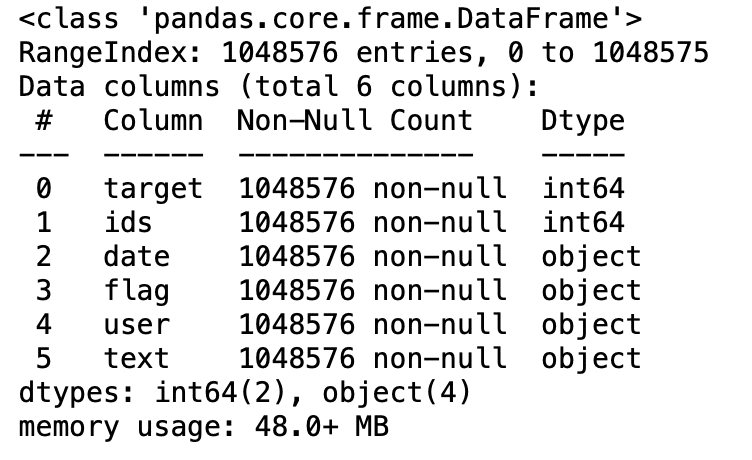
3.5: Dateninformationen
df.info()
Produktion:
3.6: Datentypen aller Spalten
df.dtypes
Produktion:
Ziel int64 ids int64 Datumsobjekt Flaggenobjekt Benutzerobjekt Textobjekt dtyp: Objekt
3.7: Auf Nullwerte prüfen
np.sum(df.isnull().irgendein(Achse=1))
Produktion:
0
3.8: Zeilen und Spalten im Datensatz
drucken('Anzahl der Spalten in den Daten ist: ', len(df.spalten))
drucken('Zählung der Zeilen in den Daten ist: ', len(df))
Produktion:
Anzahl der Spalten in den Daten ist: 6 Anzahl der Zeilen in den Daten ist: 1048576
3.9: Einzelzielwerte prüfen
df['Ziel'].einzigartig()
Produktion:
Array([0, 4], dtype=int64)
3.10: Überprüfen Sie die Anzahl der Zielwerte
df['Ziel'].nuniquam()
Produktion:
2
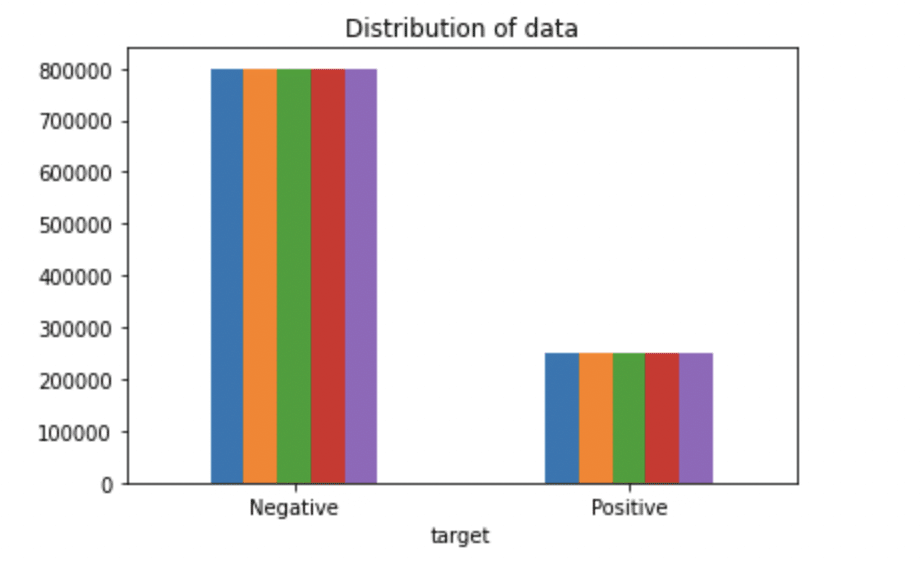
Paso 4: Anzeigen von Zielvariablendaten
# Plotten der Verteilung für den Datensatz.
ax = df.groupby('Ziel').zählen().Handlung(kind='bar', Titel="Verteilung von Daten",Legende=Falsch)
ax.set_xticklabels(['Negativ','Positiv'], Drehung=0)
# Daten in Listen speichern.
Text, Stimmung = Liste(df['Text']), aufführen(df['Ziel'])
Produktion:
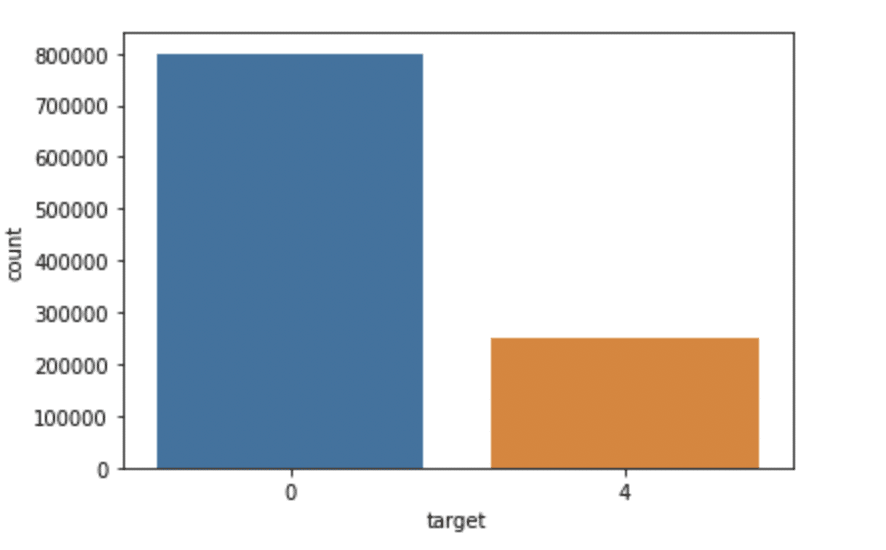
Seegeboren als sns importieren
sns.countplot(x='Ziel', Daten=df)
Produktion:
Paso 5: Datenvorverarbeitung
In der obigen Problemstellung vor dem Training des Modells, Wir haben mehrere Vorverarbeitungsschritte für den Datensatz durchgeführt, die sich hauptsächlich mit dem Entfernen von Stoppwörtern befassten, Emojis löschen. Später, Textdokument wird zur besseren Verallgemeinerung in Kleinbuchstaben umgewandelt.
Anschließend, Partituren wurden bereinigt und entfernt, Dadurch wird unnötiges Rauschen aus dem Datensatz reduziert. Danach, Wir haben auch die sich wiederholenden Zeichen aus den Wörtern entfernt und die URLs entfernt, da sie keine wesentliche Bedeutung haben.
Schließlich, Wir führen Stemmen (Wörter auf ihre abgeleiteten Wurzeln reduzieren) Ja Lematización (Reduzieren abgeleiteter Wörter auf ihre Wurzelform, bekannt als Lemma) für beste Ergebnisse.
5.1: Wählen Sie den Zieltext und die Spalte für unsere weitere Analyse aus
Daten=df[['Text','Ziel']]
5.2: Ersetzen von Werten zur besseren Verständlichkeit. (Zuweisen 1 zum positiven Gefühl 4)
Daten['Ziel'] = Daten['Ziel'].ersetzen(4,1)
5.3: Drucken Sie eindeutige Werte von Zielvariablen
Daten['Ziel'].einzigartig()
Produktion:
Array([0, 1], dtype=int64)
5.4: Trennung von positiven und negativen Tweets
data_pos = Daten[Daten['Ziel'] == 1] data_neg = Daten[Daten['Ziel'] == 0]
5.5: ein Viertel der Daten nehmen, damit wir problemlos auf unserem Computer laufen können
data_pos = data_pos.iloc[:int(20000)] data_neg = data_neg.iloc[:int(20000)]
5.6: Kombinieren von positiven und negativen Tweets
Datensatz = pd.concat([data_pos, data_neg])
5.7: Machen Sie den Deklarationstext klein
Datensatz['Text']=Datensatz['Text'].Str.unten() Datensatz['Text'].Schwanz()
Produktion:

5.8: Definitionssatz mit allen Stoppwörtern in Englisch.
Stoppwortliste = ['ein', 'Über', 'Oben', 'nach', 'wieder', 'ist', 'alle', 'bin', 'ein',
'und','irgendein','sind', 'wie', 'bei', 'Sein', 'da', 'gewesen', 'Vor',
'Sein', 'unter', 'zwischen','beide', 'von', 'kann', 'D', 'Tat', 'tun',
'tut', 'tun', 'Nieder', 'während', 'jede einzelne','wenig', 'zum', 'von',
'weiter', 'hatte', 'hat', 'verfügen über', 'haben', 'er', 'Sie', 'Hier',
'ihres', 'Sie selbst', 'ihm', 'selbst', 'seine', 'wie', 'ich', 'wenn', 'in',
'hinein','ist', 'es', 'es ist', 'selbst', 'nur', 'NS', 'm', 'ma',
'mich', 'mehr', 'die meisten','mein', 'mich selber', 'jetzt', 'Ö', 'von', 'An', 'wenn',
'nur', 'oder', 'Sonstiges', 'unsere', 'unsere','uns selbst', 'aus', 'besitzen', 'betreffend','S', 'gleich', 'Sie', "sie", 'sollen', "sollte",'so', 'etwas', 'eine solche',
'T', 'als', 'das', "das wird", 'das', 'ihr', 'ihre', 'Sie',
'sich', 'dann', 'dort', 'diese', 'Sie', 'Dies', 'jene',
'durch', 'zu', 'auch','unter', 'bis um', 'hoch', 'und', 'sehr', 'war',
'wir', 'wurden', 'was', 'Wenn', 'wo','welcher','während', 'Wer', 'dem',
'warum', 'Wille', 'mit', 'gewonnen', 'und', 'Sie', "du bist","du wirst", "du bist",
"du hast", 'Ihre', 'dein', 'du selbst', 'euch']
5.9: Bereinigen und entfernen Sie die alte Stoppwortliste aus dem Tweet-Text
STOPWÖRTER = gesetzt(Stoppwortliste)
def clean_stopwords(Text):
Rückkehr " ".beitreten([Wort für Wort in str(Text).Teilt() wenn Wort nicht in STOPWÖRTER])
Datensatz['Text'] = Datensatz['Text'].anwenden(Lambda-Text: clean_stopwords(Text))
Datensatz['Text'].Kopf()
Produktion:

5.10: Reinigen und Entfernen von Riefen
Import-String
english_punctuations = string.punctuation
punctuations_list = english_punctuations
Def Reinigung_Zeichensetzungen(Text):
Übersetzer = str.maketrans('', '', Satzzeichen_Liste)
Text zurückgeben.übersetzen(Übersetzer)
Datensatz['Text']= Datensatz['Text'].anwenden(Lambda x: reinigung_satzzeichen(x))
Datensatz['Text'].Schwanz()
Produktion:

5.11: Bereinigen und Entfernen von sich wiederholenden Zeichen
def clean_repeating_char(Text):
zurück re.sub(R'(.)1+', r'1', Text)
Datensatz['Text'] = Datensatz['Text'].anwenden(Lambda x: clean_repeating_char(x))
Datensatz['Text'].Schwanz()
Produktion:

5.12: URL-Bereinigung und -Entfernung
def clean_URLs(Daten):
zurück re.sub('((www.[^s]+)|(https?://[^s]+))',' ',Daten)
Datensatz['Text'] = Datensatz['Text'].anwenden(Lambda x: clean_URLs(x))
Datensatz['Text'].Schwanz()
Produktion:

5.13: Bereinigen und Entfernen von numerischen Zahlen
def clean_numbers(Daten):
zurück re.sub('[0-9]+', '', Daten)
Datensatz['Text'] = Datensatz['Text'].anwenden(Lambda x: Reinigungszahlen(x))
Datensatz['Text'].Schwanz()
Produktion:

5.14: Tokenisierung von Tweet-Text erhalten
von nltk.tokenize importieren RegexpTokenizer Tokenizer = RegexpTokenizer(r'w+') Datensatz['Text'] = Datensatz['Text'].anwenden(tokenizer.tokenize) Datensatz['Text'].Kopf()
Produktion:

5.15: Antrag umgehen
nltk importieren
st = nltk.PorterStemmer()
def stemming_on_text(Daten):
Text = [st.stamm(Wort) für Wort in Daten]
Daten zurückgeben
Datensatz['Text']= Datensatz['Text'].anwenden(Lambda x: stemmen_on_text(x))
Datensatz['Text'].Kopf()
Produktion:

5.16: Lemmatizer-Anwendung
lm = nltk.WordNetLemmatizer()
def lemmatizer_on_text(Daten):
Text = [lm.lemmatisieren(Wort) für Wort in Daten]
Daten zurückgeben
Datensatz['Text'] = Datensatz['Text'].anwenden(Lambda x: lemmatizer_on_text(x))
Datensatz['Text'].Kopf()
Produktion:

5.17: Trennung von Eingabefunktion und Label
X=data.text y=data.target
5.18: Zeichnen Sie eine Wortwolke für negative Tweets
data_neg = Daten['Text'][:800000]
plt.figur(Feigengröße = (20,20))
wc = WordCloud(max_words = 1000 , Breite = 1600 , Höhe = 800,
Kollokationen=Falsch).generieren(" ".beitreten(data_neg))
plt.imshow(Toilette)
Produktion:
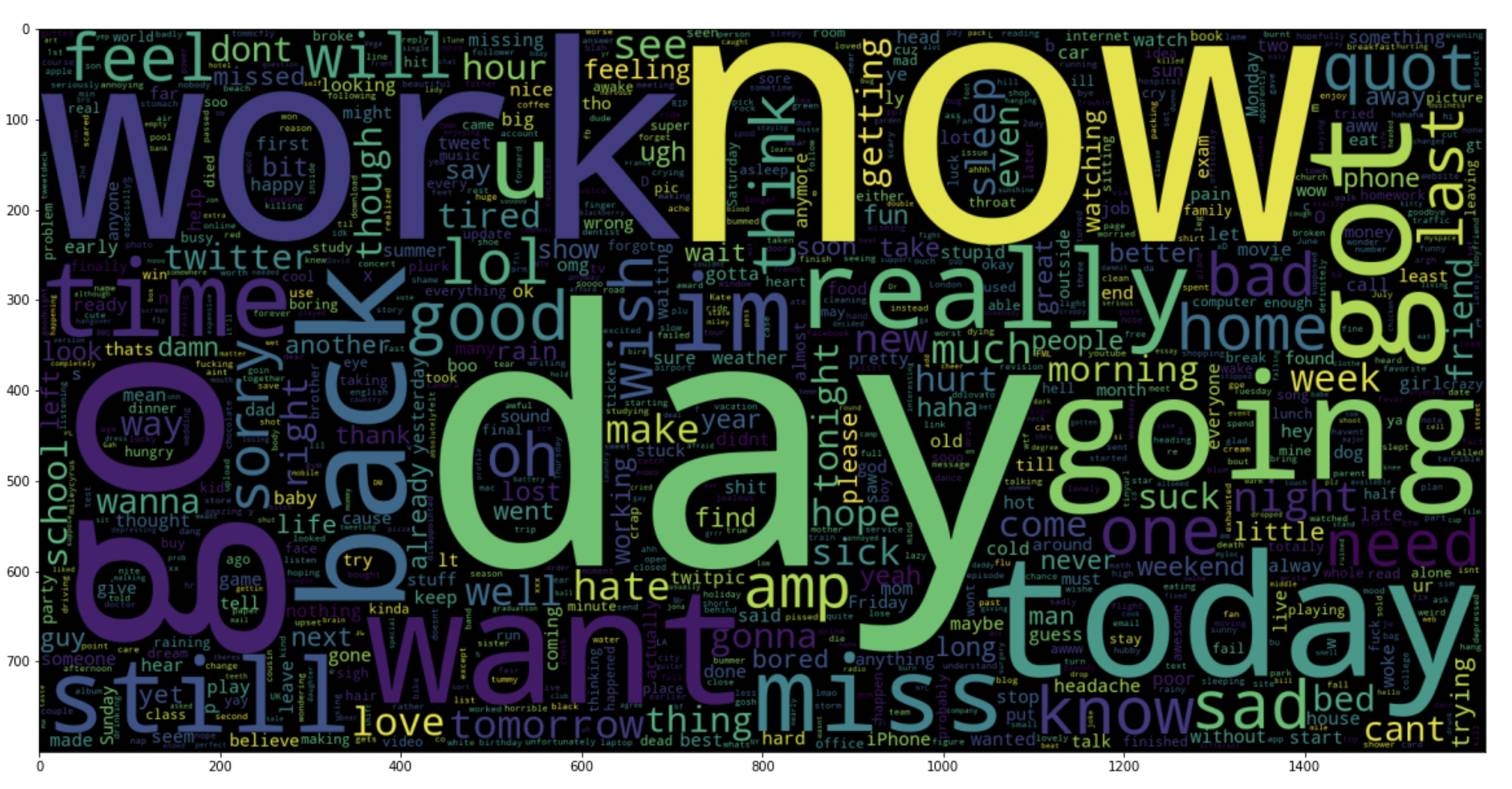
5.19: Zeichnen Sie eine Wortwolke für positive Tweets
data_pos = Daten['Text'][800000:]
wc = WordCloud(max_words = 1000 , Breite = 1600 , Höhe = 800,
Kollokationen=Falsch).generieren(" ".beitreten(data_pos))
plt.figur(Feigengröße = (20,20))
plt.imshow(Toilette)
Produktion:
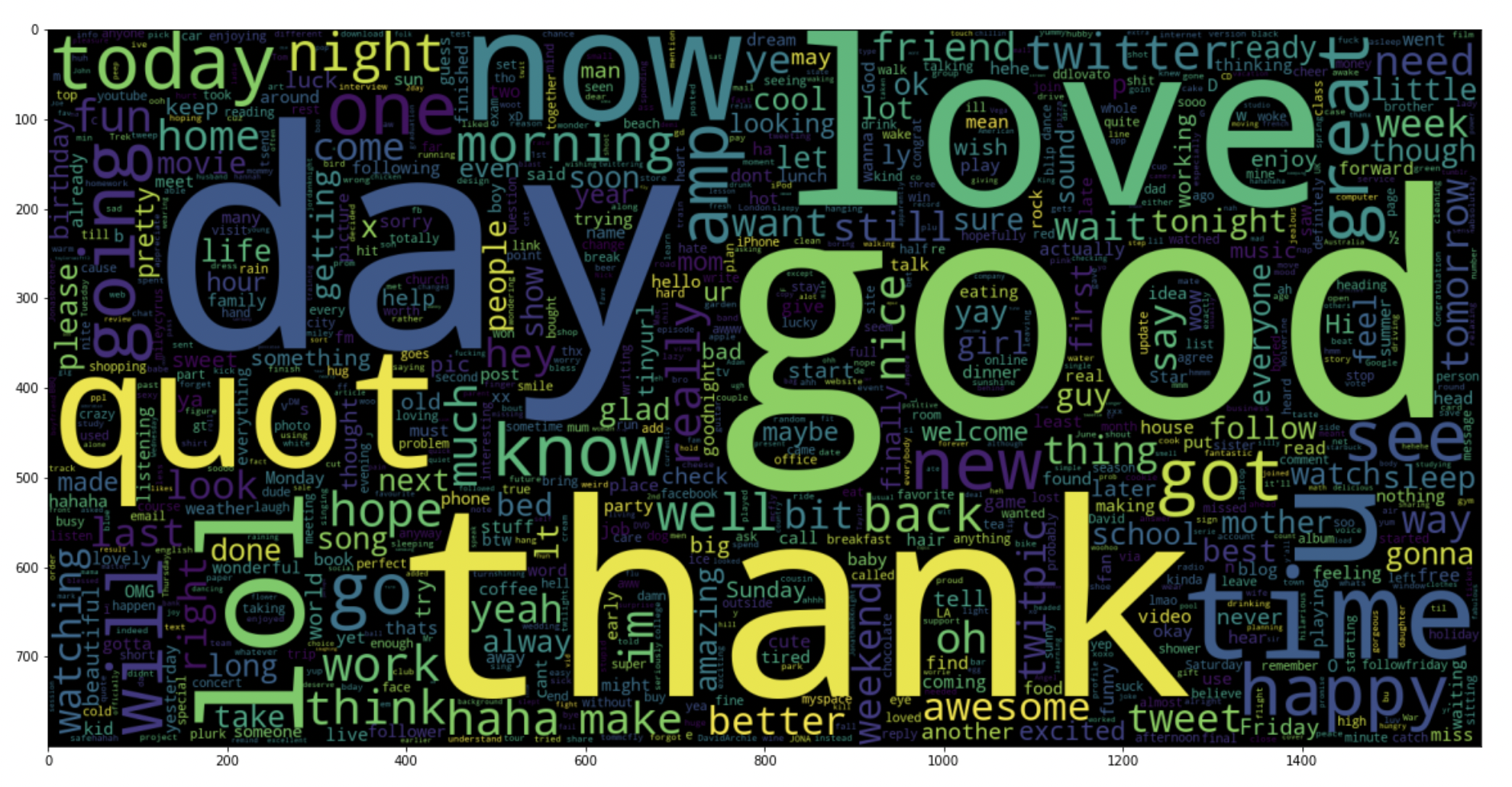
Paso 6: Teilen Sie unsere Daten in Trainings- und Testuntergruppen auf
# Trennen der 95% Daten für Trainingsdaten und 5% zum Testen von Daten X_Zug, X_test, y_train, y_test = train_test_split(x,Ja,test_size = 0.05, random_state =26105111)
Paso 7: Transformieren Sie den Datensatz mit dem TF-IDF Vectorizer
7.1: TF-IDF Vectorizer installieren
Vektorisierer = TfidfVektorisierer(ngram_range=(1,2), max_features=500000)
vectoriser.fit(X_Zug)
drucken('Nein. von feature_words: ', len(vectoriser.get_feature_names()))
Produktion:
Nein. von feature_words: 500000
7.2: Transformieren Sie die Daten mit dem TF-IDF Vectorizer
X_train = vectoriser.transform(X_Zug) X_test = vectoriser.transform(X_test)
Paso 8: Funktion zur Modellbewertung
Nach dem Training des Modells, Wir wenden die Bewertungsmaßnahmen an, um die Leistung des Modells zu überprüfen. Folglich, Wir verwenden die folgenden Bewertungsparameter, um die Leistung der jeweiligen Modelle zu überprüfen:
- Genauigkeitsbewertung
- Schraffur-Verwirrungsmatrix
- Curva ROC-AUC
def model_Evaluate(Modell):
# Vorhersagewerte für Testdatensatz
y_pred = model.predict(X_test)
# Drucken Sie die Bewertungsmetriken für den Datensatz.
drucken(Klassifizierungsbericht(y_test, y_pred))
# Berechnen und zeichnen Sie die Konfusionsmatrix
cf_matrix = verwirrt_matrix(y_test, y_pred)
Kategorien = ['Negativ','Positiv']
Gruppennamen = ['Wahres Neg','Falsche Pos', 'Falsches Neg','Echte Pos']
group_percentages = ['{0:.2%}'.Format(Wert) für Wert in cf_matrix.flatten() / np.sum(cf_matrix)]
Etiketten = [F'{v1}n{v2}' für v1, v2 in zip(Gruppennamen,group_percentages)]
Labels = np.asarray(Etiketten).umformen(2,2)
sns.heatmap(cf_matrix, annot = Etiketten, cmap = 'Blues',fmt="",
xticklabels = Kategorien, yticklabels = Kategorien)
plt.xlabel("Vorhergesagte Werte", fontdict = {'Größe':14}, Labelpfad = 10)
plt.ylabel("Istwerte" , fontdict = {'Größe':14}, Labelpfad = 10)
plt.titel ("Verwirrung Matrix", fontdict = {'Größe':18}, Pad = 20)
Paso 9: Modellbau
In der Problemstellung haben wir jeweils drei verschiedene Modelle verwendet:
- Bernoulli ingenuo Bayes
- SVM (Support-Vektor-Maschine)
- Logistische Regression
Die Idee hinter der Auswahl dieser Modelle ist, dass wir alle Klassifikatoren im Datensatz testen möchten, von einfachen bis hin zu komplexen Modellen, und versuchen Sie dann, diejenige zu finden, die die beste Leistung bietet.
8.1: Modell 1
BNBmodel = BernoulliNB() BNBmodel.fit(X_Zug, y_train) model_Evaluate(BNB-Modell) y_pred1 = BNBmodel.predict(X_test)
Produktion:
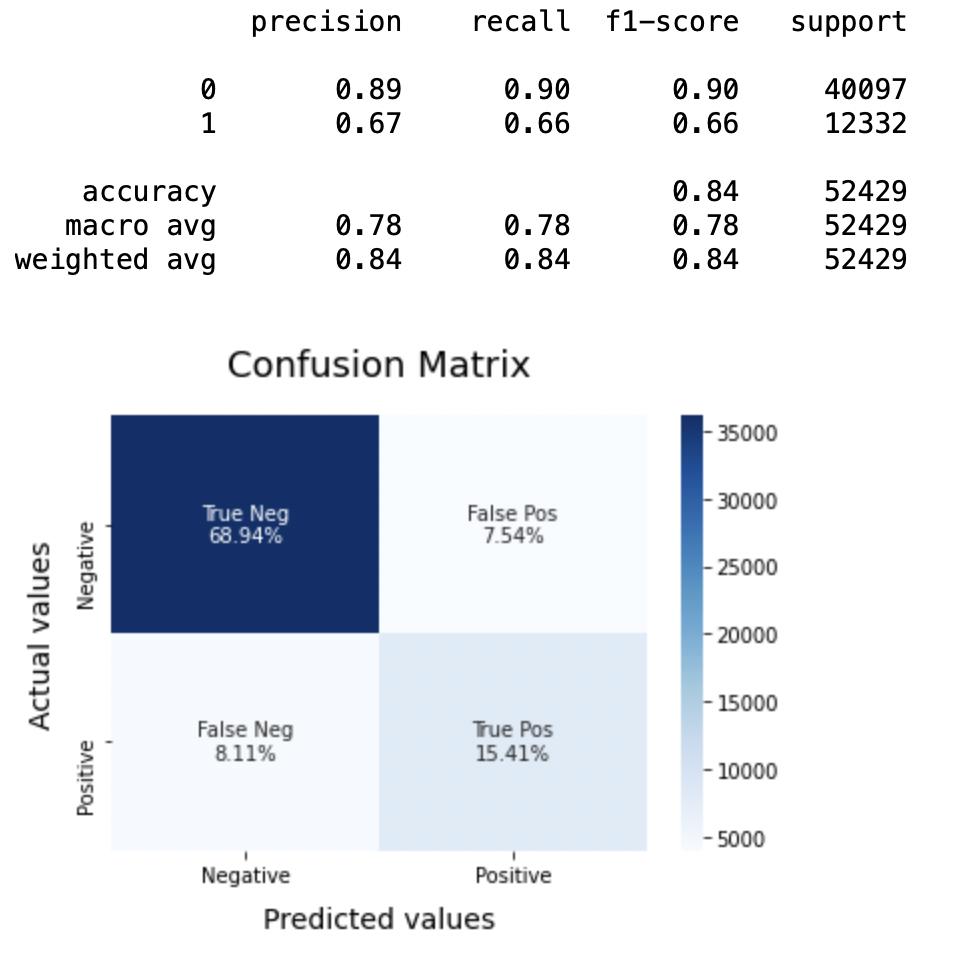
8.2: Zeichnen Sie die ROC-AUC-Kurve für das Modell 1
aus sklearn.metrics importieren roc_curve, auc
fpr, tpr, Schwellen = roc_curve(y_test, y_pred1)
roc_auc = auc(fpr, tpr)
plt.figur()
plt.plot(fpr, tpr, Farbe="dunkelorange", lw=1, Etikett="ROC-Kurve (Fläche = %0.2f)" % roc_auc)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('Falsch-Positiv-Rate')
plt.ylabel('Echte positive Rate')
plt.titel('ROC-KURVE')
plt.legende(loc ="rechts unten")
plt.zeigen()
Produktion:
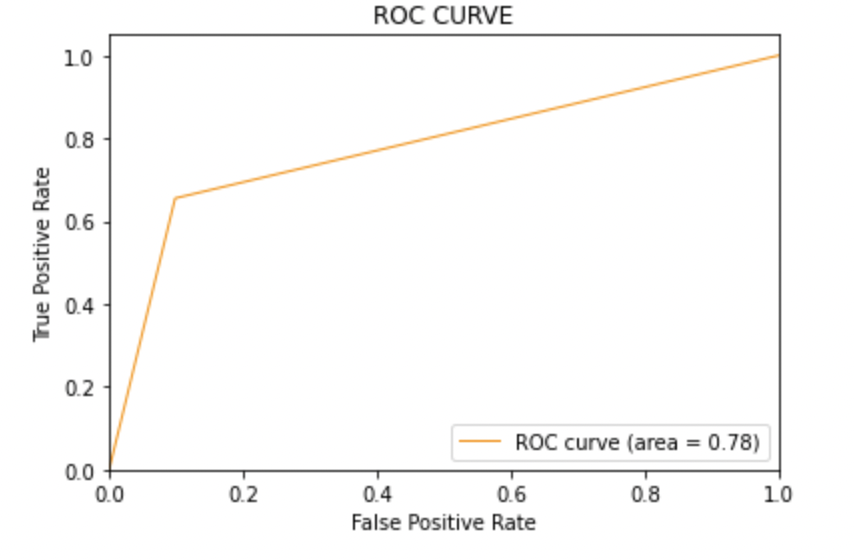
8.3: Modell-2:
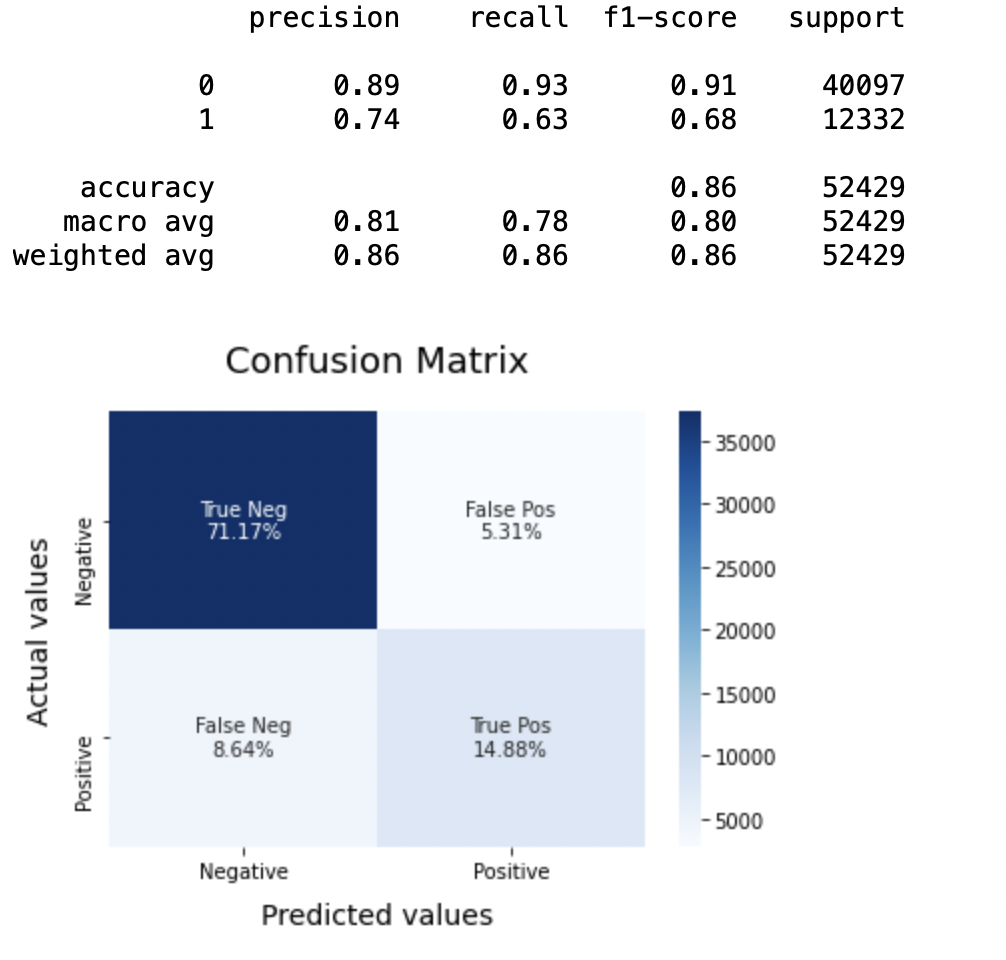
SVCmodel = LinearSVC() SVCmodel.fit(X_Zug, y_train) model_Evaluate(SVC-Modell) y_pred2 = SVCmodel.predict(X_test)
Produktion:
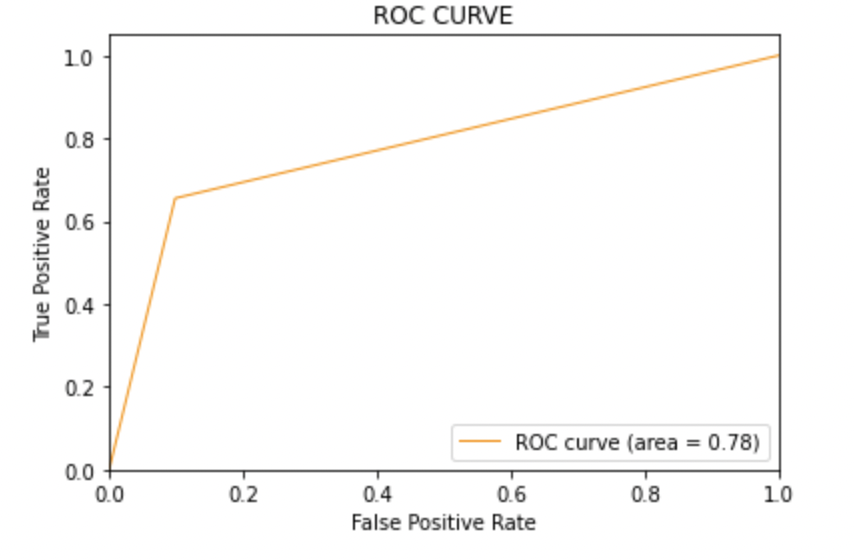
8.4: Zeichnen Sie die ROC-AUC-Kurve für das Modell 2
aus sklearn.metrics importieren roc_curve, auc
fpr, tpr, Schwellen = roc_curve(y_test, y_pred2)
roc_auc = auc(fpr, tpr)
plt.figur()
plt.plot(fpr, tpr, Farbe="dunkelorange", lw=1, Etikett="ROC-Kurve (Fläche = %0.2f)" % roc_auc)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('Falsch-Positiv-Rate')
plt.ylabel('Echte positive Rate')
plt.titel('ROC-KURVE')
plt.legende(loc ="rechts unten")
plt.zeigen()
Produktion:
8.5: Modell-3
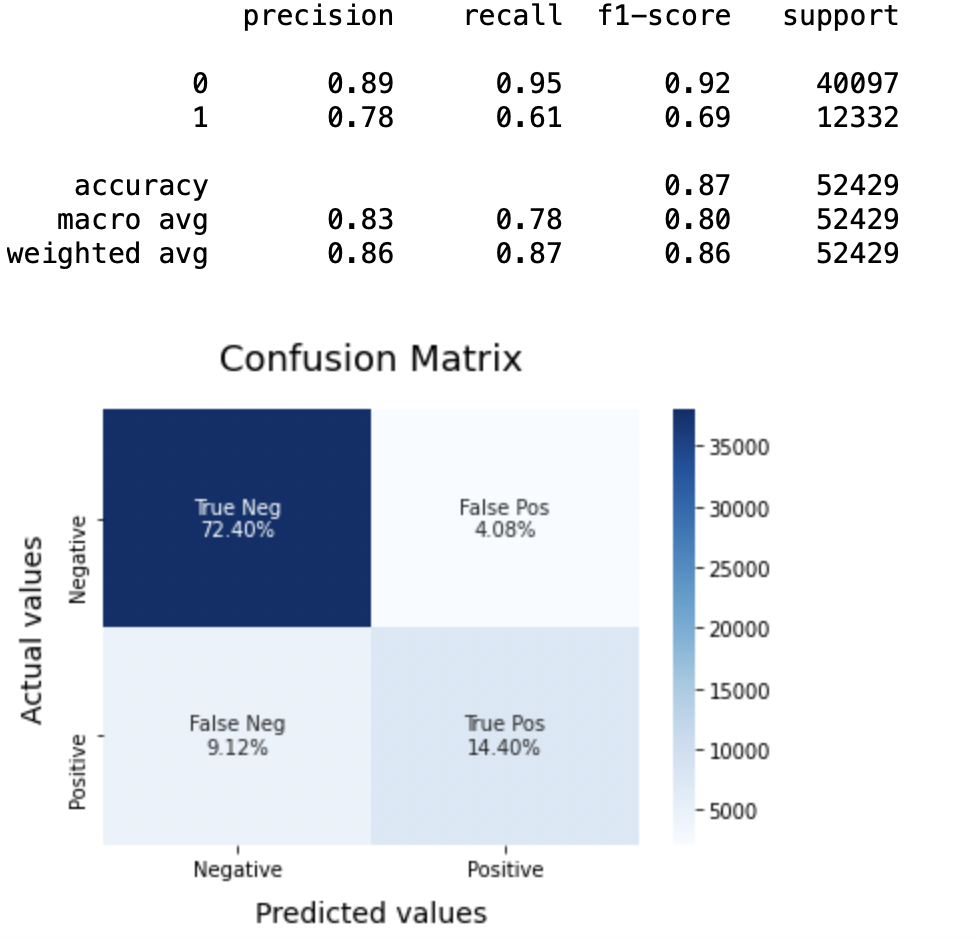
LRmodel = LogistischeRegression(C = 2, max_iter = 1000, n_jobs=-1) LRmodel.fit(X_Zug, y_train) model_Evaluate(LRmodel) y_pred3 = LRmodel.predict(X_test)
Produktion:
8.6: Zeichnen Sie die ROC-AUC-Kurve für das Modell 3
aus sklearn.metrics importieren roc_curve, auc
fpr, tpr, Schwellen = roc_curve(y_test, y_pred3)
roc_auc = auc(fpr, tpr)
plt.figur()
plt.plot(fpr, tpr, Farbe="dunkelorange", lw=1, Etikett="ROC-Kurve (Fläche = %0.2f)" % roc_auc)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('Falsch-Positiv-Rate')
plt.ylabel('Echte positive Rate')
plt.titel('ROC-KURVE')
plt.legende(loc ="rechts unten")
plt.zeigen()
Produktion:
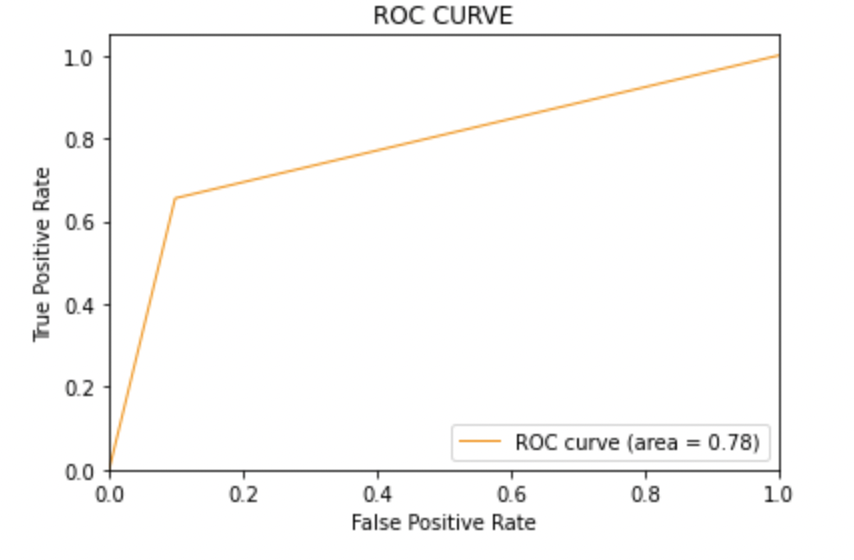
Paso 10: Fazit
Bei der Auswertung aller Modelle können wir auf folgende Details schließen, d.h.
Präzision: Zur Genauigkeit des Modells, logistische Regression funktioniert besser als SVM, was wiederum besser funktioniert als Bernoulli Naive Bayes.
F1-Ergebnis: F1-Ergebnisse für die Klasse 0 und die klasse 1 Sohn:
(ein) Für die Klasse 0: Bernoulli Naive Bayes (Präzision = 0,90) <SVM (Präzision = 0,91) <Logistische Regression (Präzision = 0,92)
(B) Für die Klasse 1: Bernoulli Naive Bayes (Präzision = 0,66) <SVM (Präzision = 0,68) <Logistische Regression (Präzision = 0,69)
AUC-Score: Alle drei Modelle haben den gleichen ROC-AUC-Score.
Deswegen, wir schließen daraus, dass die logistische Regression das beste Modell für den obigen Datensatz ist.
In unserer Problemstellung, Logistische Regression folgt dem Prinzip von Ockhams Rasiermesser was das für eine bestimmte Problemstellung definiert, wenn die Daten keine Annahmen enthalten, das einfachste Modell funktioniert also am besten. Da unser Datensatz keine Annahmen hat und die logistische Regression ein einfaches Modell ist, das Konzept gilt für den oben genannten Datensatz.
Abschließende Anmerkungen
Hoffe dir hat der Artikel gefallen.
Wenn du dich mit mir verbinden möchtest, Zögern Sie nicht, mit mir in Kontakt zu bleiben. Über Email
Ihre Vorschläge und Zweifel sind hier im Kommentarbereich willkommen. Danke, dass du meinen Artikel gelesen hast!
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von Analytics Vidhya und werden nach Ermessen des Autors verwendet.





