Dieser Beitrag wurde im Rahmen der . veröffentlicht Data Science Blogathon
Einführung
Als Datenwissenschaftler, Web Scraping ist eine der wichtigsten Fähigkeiten, die Sie beherrschen müssen, und Sie sollten nach nützlichen Daten suchen, sammeln und verarbeiten Sie Daten, damit Ihre Ergebnisse aussagekräftig und genau sind.
Bevor wir uns mit den Tools befassen, die bei Data-Mining-Aktivitäten helfen könnten, Lassen Sie uns bestätigen, dass diese Aktivität legal ist, da Web-Scraping ein rechtlicher Graubereich war. Das EE-Gericht. UU. Vollständig legalisiertes Web-Scraping von öffentlich zugänglichen Daten über 2020. Das bedeutet, dass, wenn Sie Informationen online gefunden haben (wie Wiki-Beiträge), dann ist es legal, die Daten zu kratzen.
Auch so, Wenn du es tust, sicher sein zu:
- Daten nicht in einer Weise wiederverwenden oder veröffentlichen, die das Urheberrecht verletzt.
- Dass Sie die Nutzungsbedingungen des Webportals einhalten, das Sie kratzen.
- Dass Sie eine faire Tracking-Rate haben.
- Versuchen Sie nicht, private Teile des Webportals zu extrahieren.
Solange es nicht gegen die oben genannten Bedingungen verstößt, Ihre Web-Scraping-Aktivität wird auf der rechtlichen Seite sein.
Ich denke, einige von Ihnen haben möglicherweise BeautifulSoup und Anfragen verwendet, um die Daten und Pandas zu sammeln, um sie für Ihre Projekte zu analysieren. In diesem Beitrag erhalten Sie fünf Web-Scraping-Tools, die BeautifulSoup nicht enthalten; ist kostenlos nutzbar und sammelt die Daten für Ihr nächstes Projekt.
Der Schöpfer von Common Crawl hat dieses Tool entwickelt, weil es davon ausgeht, dass jeder die Möglichkeit haben sollte, die Daten in seiner Umgebung zu untersuchen und zu analysieren und nützliche Informationen zu finden. Sie liefern qualitativ hochwertige Daten, die nur großen Institutionen und Forschungsinstituten zugänglich waren, ohne Kosten für jeden neugierigen Geist, um ihre Open-Source-Überzeugungen zu fördern..
Sie können dieses Tool verwenden, ohne sich um Gebühren oder andere finanzielle Schwierigkeiten kümmern zu müssen. Wenn Sie Student sind, ein Neuling, der in die Datenwissenschaft eintaucht oder einfach nur eine eifrige Person, die es liebt, Wissen zu erforschen und neue Trends zu entdecken, Dieses Tool wäre nützlich. Stellen Sie Webseiten-Rohdaten und Wortextrakte als offene Datensätze bereit. Es bietet auch Ressourcen für Dozenten, die Datenanalyse und Unterstützung für nicht-codebasierte Anwendungsfälle unterrichten..
Durchgehen Webseite für weitere Informationen zur Verwendung von Datensätzen und Alternativen zum Extrahieren der Daten.
Crawly ist eine weitere Alternative, vor allem, wenn Sie nur einfache Daten aus einem Webportal extrahieren müssen oder wenn Sie Daten im CSV-Format extrahieren möchten, damit Sie sie untersuchen können, ohne Code schreiben zu müssen. Benutzer muss eine URL eingeben, eine E-Mail-Identifikation, um die extrahierten Daten zu senden, das Format der benötigten Daten (Wählen Sie zwischen CSV oder JSON) und fertig, Die extrahierten Daten befinden sich zur Verwendung in Ihrem Posteingang.
Man kann JSON-Daten verwenden und sie mit Pandas und Matplotlib analysieren, oder eine andere Programmiersprache. Wenn Sie ein Neuling in Data Science und Web Scraping sind, kein Programmierer, das ist gut und hat seine grenzen. Ein begrenzter Satz von HTML-Tags einschließlich Titel kann extrahiert werden, Autor, Bild-URL und Editor.
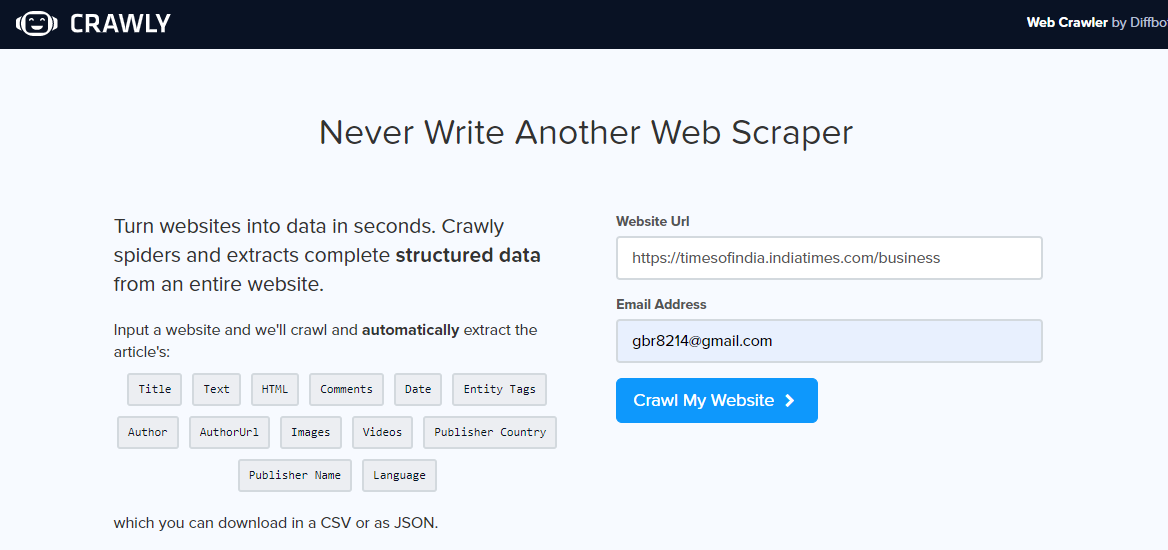
Sobald Sie das Tracking-Webportal geöffnet haben, Geben Sie die URL ein, um zu kratzen, Wählen Sie das Datenformat und Ihre E-Mail-ID aus, um die Daten zu erhalten. Überprüfen Sie Ihren Posteingang, um die Daten zu sehen.
Der Content Grabber ist ein flexibles Werkzeug, wenn Sie eine Webseite scratchen möchten und keine anderen Parameter angeben möchten, Benutzer kann dies mit seiner einfachen GUI tun. Auch so, bietet die Möglichkeit der vollständigen Kontrolle der Extraktionsparameter, die angepasst werden können.
Der Benutzer kann das Scraping von Informationen aus dem Web automatisch planen, ist einer seiner Vorteile. Heutzutage, wir alle wissen, dass Webseiten regelmäßig aktualisiert werden, Daher wäre eine häufige Inhaltsextraktion hilfreich.
Bietet verschiedene extrahierte Datenformate wie CSV, JSON ein SQL Server oder MySQL.
Ein kurzes Beispiel zum Scrapen der Daten
Sie können dieses Tool verwenden, um visuell durch das Webportal zu navigieren und auf Datenelemente in der Reihenfolge zu klicken, in der Sie sie sammeln möchten.. Es erkennt automatisch den richtigen Aktionstyp und stellt Standardnamen für jeden Befehl bereit, während der Agent basierend auf den angegebenen Inhaltselementen erstellt wird.
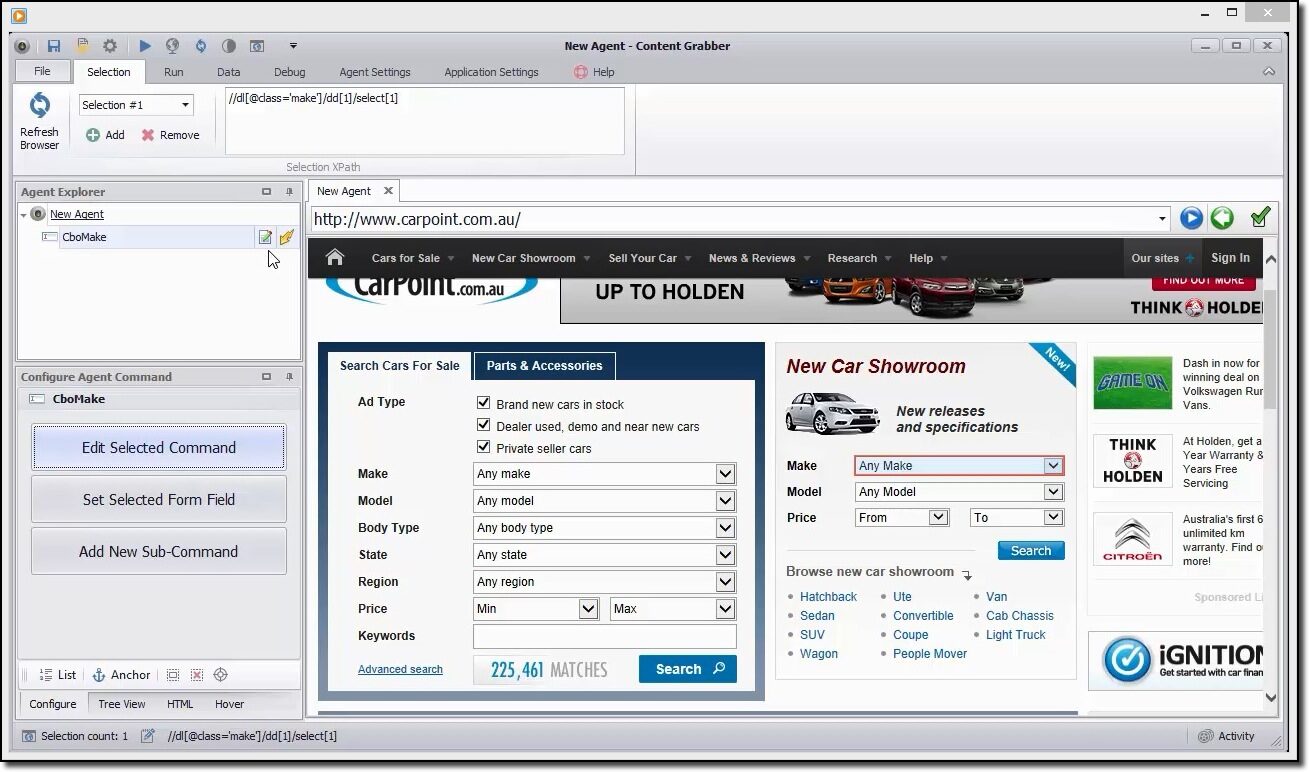
Dieses Tool ist eine Sammlung von Befehlen, die der Reihe nach ausgeführt werden, bis sie abgeschlossen sind. Die Ausführungsreihenfolge wird im Agent-Explorer-Panel aktualisiert. Sie können die Befehlsanzeige des Konfigurations-Agenten verwenden, um den Befehl an Ihre speziellen Datenanforderungen anzupassen.. Benutzer können auch neue Befehle hinzufügen.
ParseHub ist ein leistungsstarkes Web-Scraping-Tool, das jeder kostenlos nutzen kann. Bietet sichere und genaue Datenextraktion mit einem Klick. Benutzer können auch Extraktionszeiten bestimmen, um die Relevanz ihrer Überreste zu erhalten..
Eine seiner Stärken ist, dass es selbst die kompliziertesten Webseiten problemlos löschen kann.. Der Benutzer kann Anweisungen wie Suchformulare angeben, Melden Sie sich bei Websites an und klicken Sie auf Karten oder Bilder für eine spätere Datenerfassung.
Benutzer können auch mit vielen Links und Schlüsselwörtern teilnehmen, wo sie in Sekundenschnelle relevante Informationen extrahieren können. Beenden, Sie können die REST-API verwenden, um die extrahierten Daten zur Analyse im CSV- oder JSON-Format herunterzuladen. Benutzer können die gesammelten Informationen auch als Google- oder Tableau-Blatt exportieren..
Beispiel für ein E-Commerce-Scraping-Webportal
Sobald die Installation abgeschlossen ist, öffne ein neues Projekt auf ParseHub, Verwenden Sie die E-Commerce-URL und die Seite wird in der App gerendert.
- Klicken Sie auf den Produktnamen des ersten Ergebnisses auf der Seite, nachdem die Site geladen wurde. Wenn Sie das Produkt auswählen, wird grün, um anzuzeigen, dass es ausgewählt wurde.
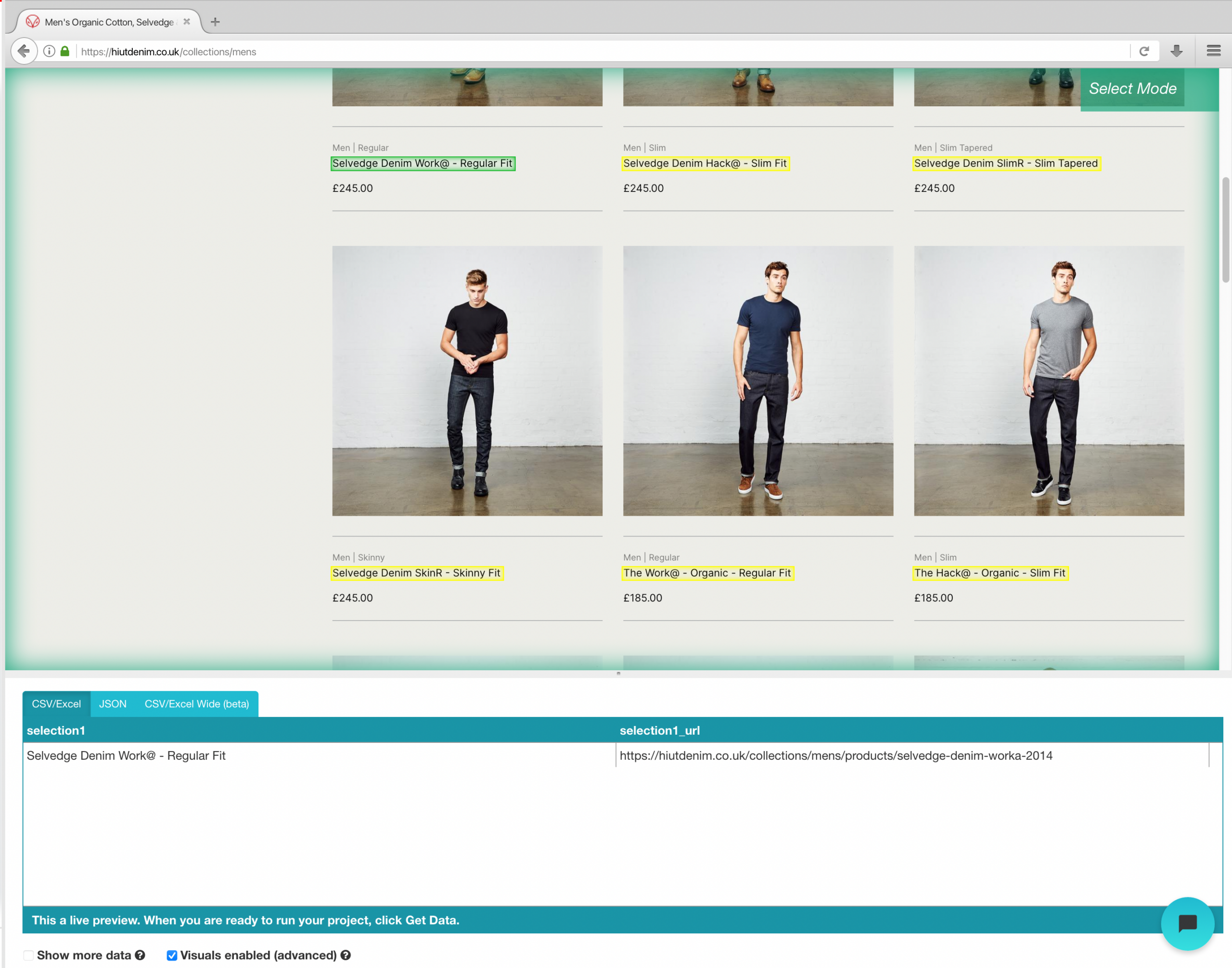
- Gelb wird verwendet, um den Rest der Produktnamen hervorzuheben. Wählen Sie die zweite Option aus der Liste. Grün wird jetzt verwendet, um alle Objekte hervorzuheben.
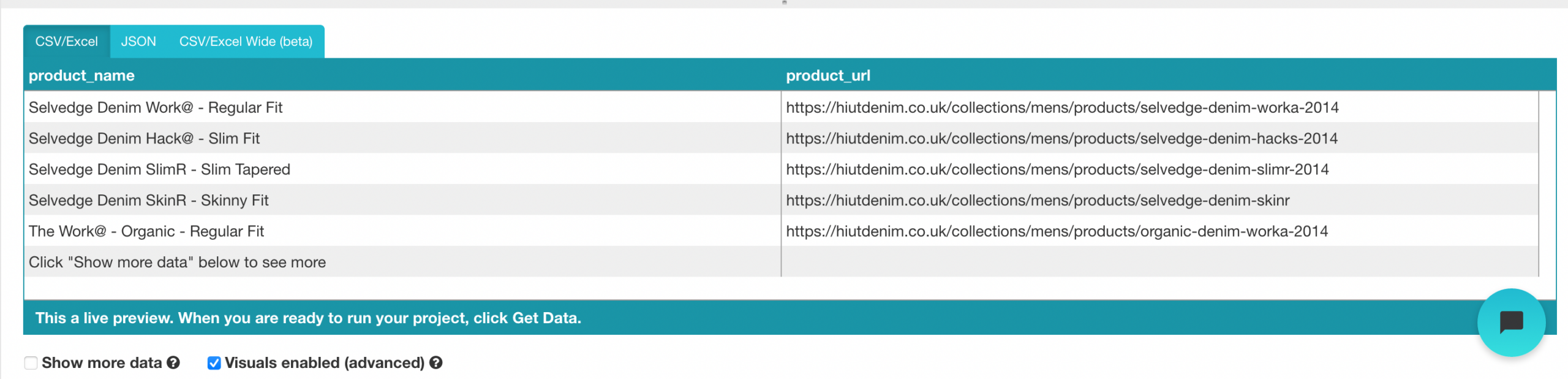
- Ändern Sie den Namen Ihrer Wahl in “Produkt” in der linken Seitenleiste. Sie können jetzt den Produktnamen und die URL sehen, die von ParseHub gezogen wurden.
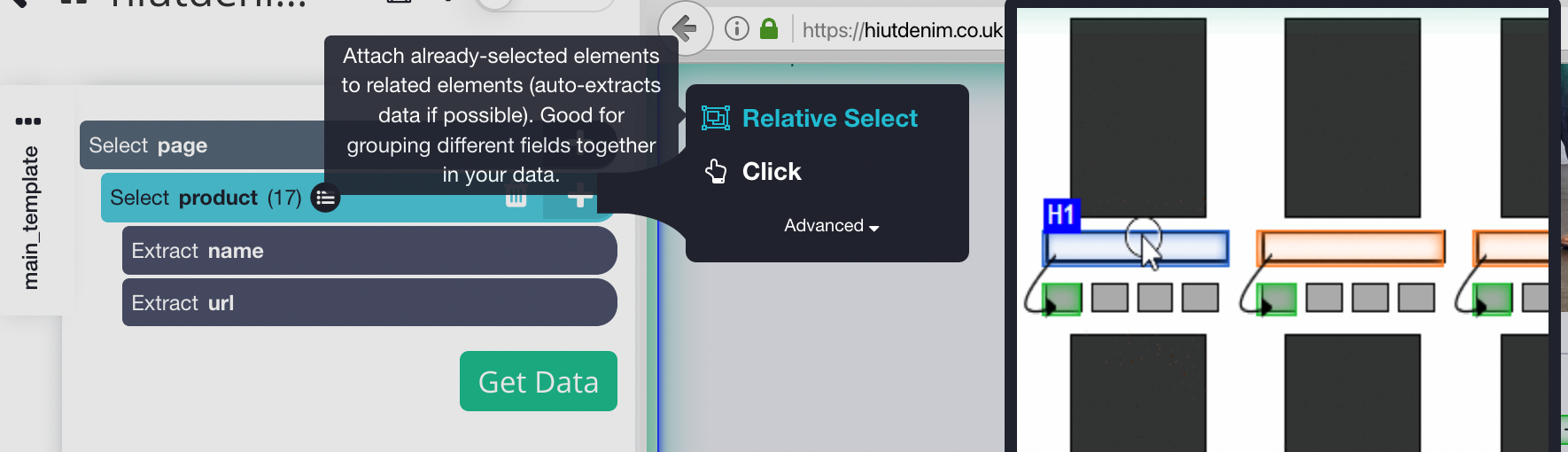
- Klicken Sie auf das PLUS-Zeichen (+) neben der Produktauswahl in der linken Seitenleiste und wählen Sie den Befehl Relative Auswahl.
- Klicken Sie auf den ersten Produktnamen auf der Seite, gefolgt vom Preis des Produkts, mit dem Befehl Relative Auswahl. Es erscheint ein Pfeil, der die beiden Optionen verbindet. Dieser Schritt muss mehrmals wiederholt werden, um Parsehub in dem zu trainieren, was Sie extrahieren möchten.
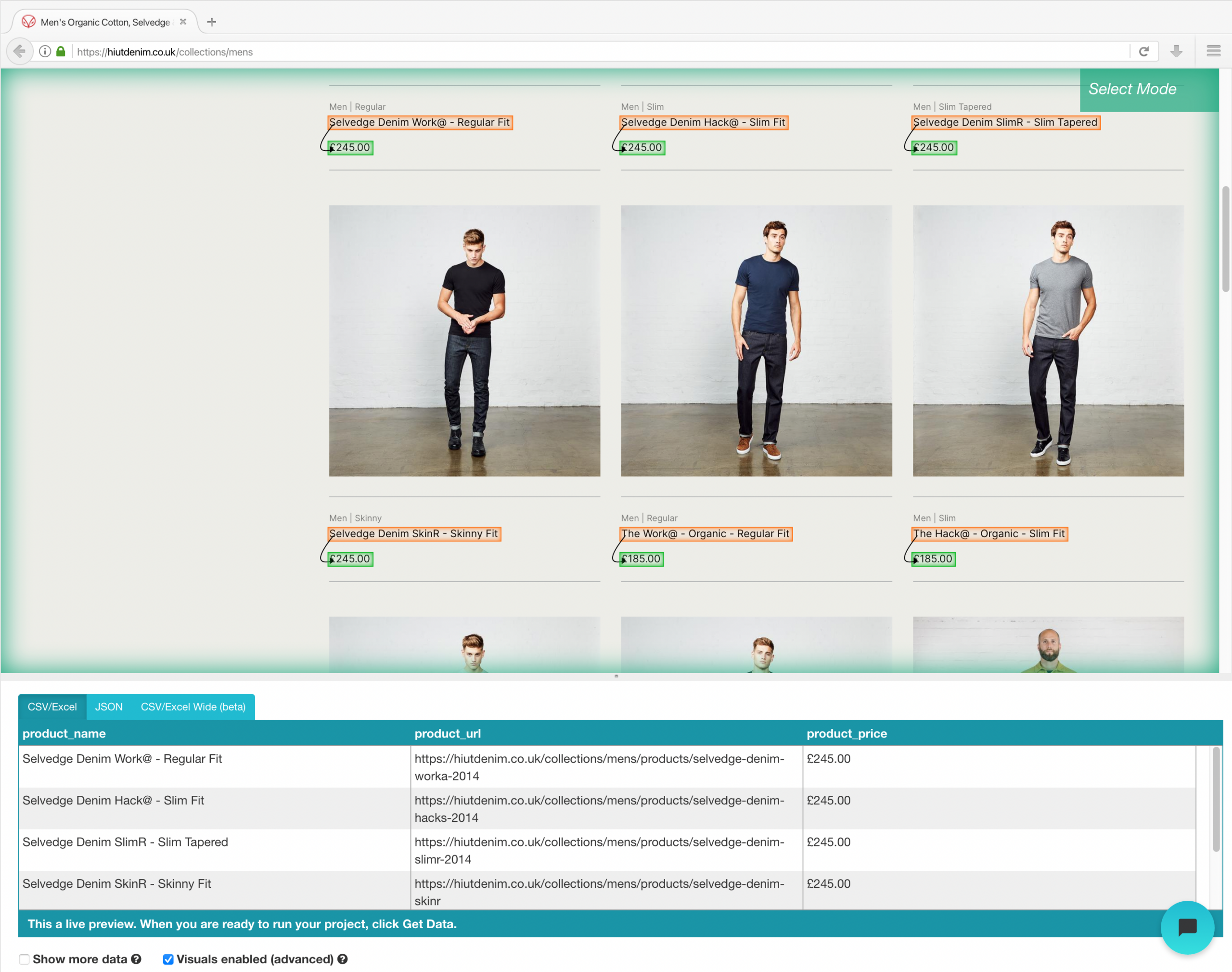
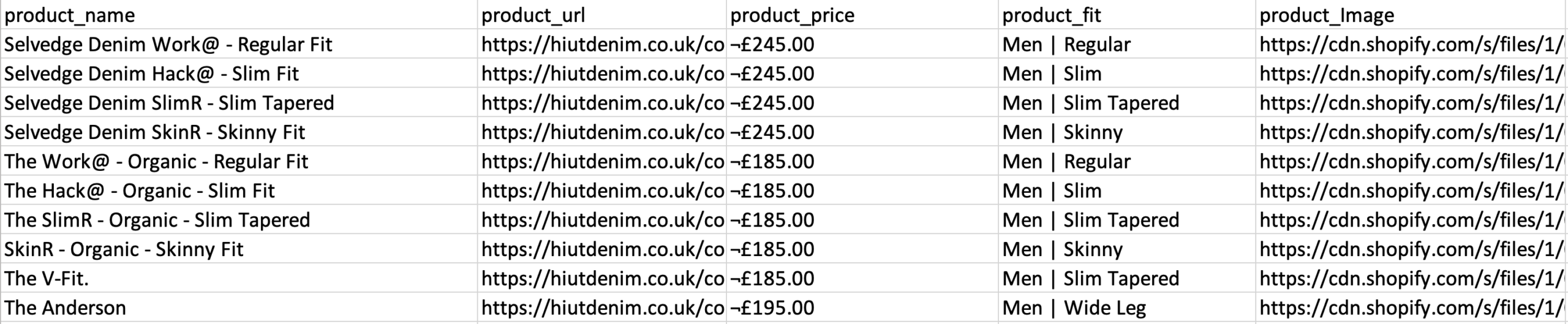
- Wiederholen Sie den vorherigen Schritt, um auch den Fit-Stil und das Produktbild zu extrahieren. Benennen Sie Ihre neuen Optionen entsprechend um.
Ausführung und Export Ihres Projekts
Nachdem wir die Konfiguration des Projekts abgeschlossen haben, Es ist Zeit, unseren Scrape-Job auszuführen.
Um dein Schaben laufen zu lassen, Klicken Sie in der linken Seitenleiste auf die Schaltfläche Daten abrufen und dann auf die Schaltfläche Ausführen.. Für größere Projekte, Wir empfehlen, einen Testlauf durchzuführen, um sicherzustellen, dass Ihre Daten das richtige Format haben.
Es ist das letzte Schabewerkzeug auf der Liste. Es verfügt über eine Web-Scraping-API, die selbst die komplexesten Javascript-Seiten verarbeiten und sie für die Benutzer in Roh-HTML konvertieren kann.. Es bietet auch eine spezielle API zum Scratchen von Websites über die Google-Suche..
Wir können dieses Tool auf eine von drei Arten verwenden:
- Web Scraping allgemein, als Beispiel, Extrahieren von Kundenbewertungen oder Aktienkursen.
- Suchmaschinen-Ergebnisseite für Keyword-Tracking oder SEO.
- Die Extraktion von Kontaktinformationen oder Daten aus sozialen Netzwerken beinhaltet Growth Hacking.
Dieses Tool bietet einen kostenlosen Plan, der Folgendes beinhaltet: 1000 Credits und kostenpflichtige Pläne zur unbegrenzten Nutzung.
Tutorial zur Verwendung der Scrapingbee-API
Melden Sie sich für einen kostenlosen Plan im ScrapingBee-Webportal an und Sie erhalten 1000 kostenlose API-Anfragen, was ausreichen sollte, um diese API zu lernen und zu testen.
Gehen Sie nun zum Control Panel und kopieren Sie den API-Schlüssel, den wir später in dieser Anleitung benötigen. ScrapingBee bietet jetzt mehrsprachige Unterstützung, damit Sie den API-Schlüssel direkt in Ihren Anwendungen verwenden können.
Da Scaping Bee REST-APIs unterstützt, ist für jede Programmiersprache geeignet, einschließlich CURL, Python, KnotenJS, Java, PHP und Go. Weitere Informationen zum Schaben, Wir werden Python verwenden und Framework anfordern, sowie SchöneSoup. Installieren Sie sie mit PIP wie folgt:
# So installieren Sie die Python Requests-Bibliothek: Pip-Installationsanfragen # Zusätzliche Module, die wir brauchten: pip installiert BeautifulSoup
Verwenden Sie den folgenden Code, um die ScrapingBee-Web-API zu starten. Wir machen einen Anfrageaufruf mit den URL- und API-Schlüsselparametern, und die API antwortet mit dem HTML-Inhalt der Ziel-URL.
Importanfragen
def get_data():
Antwort = Anfragen.get(
URL-Adresse ="https://app.scrapingbee.com/api/v1/",
Parameter={
"API-Schlüssel": "EINFÜGEN-IHREN-API-SCHLÜSSEL",
"URL-Adresse": "https://beispiel.com/", #Website zu kratzen
},
)
drucken('HTTP-Statuscode: ', response.status_code)
drucken("HTTP-Antworttext": ', antwort.inhalt)
Daten bekommen()
Beim Hinzufügen eines Verschönerungscodes, Wir können diese Ausgabe mit BeautifulSoup besser lesbar machen.
Codierung
Zusätzlich können Sie urllib.parse verwenden, um die URL zu verschlüsseln, die Sie kopieren möchten, wie im Folgenden gezeigt:
import urllib.parse
encoded_url = urllib.parse.quote("URL zum Scrapen")
Fazit
Das Sammeln von Daten für Ihre Projekte ist der mühsamste und am wenigsten Spaß machende Schritt. Diese Aufgabe kann lange dauern, und wenn Sie in einem Unternehmen oder als Freiberufler arbeiten, Ich wusste, dass Zeit Geld ist, und wenn es einen wichtigeren Weg gibt, eine Aufgabe zu erledigen, du nutzt es besser. Die gute Nachricht ist, dass Web-Scraping nicht mühsam sein muss, da Sie mit dem richtigen Werkzeug viel Zeit sparen können, Geld und Mühe. Diese Tools können für Analysten oder Personen ohne Programmierkenntnisse von Vorteil sein.. Vor der Auswahl eines Schabewerkzeugs, Es gibt einige Faktoren zu beachten, wie API-Integration und groß angelegte Scraping-Erweiterbarkeit. In diesem Beitrag wurden Ihnen einige nützliche Tools für verschiedene Datenerfassungsaufgaben vorgestellt., wo Sie diejenige auswählen können, die die Datenerfassung erleichtert.
Ich hoffe, dieser Artikel ist nützlich. Vielen Dank.
Die in diesem Beitrag gezeigten Medien sind nicht Eigentum von DataPeaker und werden nach Ermessen des Autors verwendet.





