Einführung
Haben Sie schon einmal ein einmaliges Problem mit maschinellem Lernen gelöst??
Ein Problem mit maschinellem Lernen zu lösen ist nicht einfach. Es erfordert mehrere Schritte, um zu einer genauen Lösung zu gelangen. Der Prozess / Schritte zur Lösung eines ml-Problems, das als ML-Pipeline bekannt ist / ML-Zyklus.
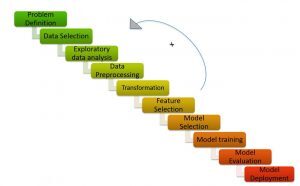
ML-Pipeline / ML-Zyklus (Credits: https://medium.com/analytics-vidhya/machine-learning-development-life-cycle-dfe88c44222e)
wie das bild zeigt, Die Machine Learning-Pipeline besteht aus verschiedenen Schritten, wie z:
Verstehen Sie die Problemstellung, Hypothesengenerierung, explorative Datenanalyse, Datenvorverarbeitung, Feature-Engineering, Merkmalsauswahl, Modellbau, Modellanpassung und Modellimplementierung.
Ich würde empfehlen, die folgenden Artikel zu lesen, um ein detailliertes Verständnis der Machine Learning-Pipeline zu erhalten:
- Erklärung des Lebenszyklus des maschinellen Lernens!
- Schritte zum Abschließen eines Machine-Learning-Projekts
Der Prozess der Lösung eines maschinellen Lernproblems erfordert viel Zeit und menschlichen Aufwand. Hurra! Es ist kein mühsamer und zeitaufwändiger Prozess mehr! Vielen Dank an AutoML für die Bereitstellung sofortiger Lösungen für Probleme des maschinellen Lernens.
Bei AutoML dreht sich alles um die automatische Erstellung des Hochleistungsmodells mit dem geringsten menschlichen Eingriff.
AutoML-Bibliotheken bieten Low-Code- und No-Code-Programmierung.
Du hast wahrscheinlich schon von den Begriffen gehört “niedriger Code” Ja “ohne Code”.
- Ohne Code Frameworks sind einfache Benutzeroberflächen, die es selbst technisch nicht versierten Benutzern ermöglichen, Modelle zu erstellen, ohne eine einzige Codezeile schreiben zu müssen.
- Niedriger Code bezieht sich auf die minimale Kodierung.
Obwohl No-Code-Plattformen es einfach machen, ein Modell für maschinelles Lernen mithilfe einer Drag-and-Drop-Oberfläche zu trainieren, sind in der Flexibilität eingeschränkt. Die Low-Code-ML, Zweitens, ist der optimale Punkt und die Mittelfrist, da sie Flexibilität und einfach zu verwendenden Code bieten.
In diesem Artikel, Lassen Sie uns verstehen, wie Sie mit einer Low-Code-AutoML-Bibliothek ein Textklassifizierungsmodell innerhalb weniger Codezeilen erstellen, PyCaret.
Inhaltsverzeichnis
- Was ist PyCaret?
- Warum brauchen wir PyCaret?
- Verschiedene Ansätze zur Lösung der Textklassifizierung in PyCaret
- Themenmodellierung
- Zählvektorisierer
- Fallstudie: Textklassifizierung mit PyCaret
Was ist PyCaret?
PyCaret ist eine Low-Code-Open-Source-Bibliothek für maschinelles Lernen in Python, mit der Sie in wenigen Minuten von der Vorbereitung Ihrer Daten zur Implementierung Ihres Modells gelangen können..

PyCaret (Credits: https://pycaret.org/)
PyCaret ist im Wesentlichen eine Low-Code-Bibliothek, die Hunderte von Codezeilen in scikit Learn ersetzt 5-6 Zeilen von Code. Erhöht die Teamproduktivität und hilft dem Team, sich auf das Verständnis des Problems und der technischen Merkmale zu konzentrieren, anstatt das Modell zu optimieren.
PyCaret (Credits: https://pycaret.org/about/)
PyCaret basiert auf einer Scikit-Lernbibliothek. Infolge, alle in scikit learn verfügbaren Algorithmen für maschinelles Lernen sind in pycaret verfügbar. Im Folgenden, PyCaret kann klassifikationsbezogene Probleme lösen, Rückschritt, Gruppierung, Anomalieerkennung, Textklassifizierung, Mining-bezogene Regeln und Zeitreihen.
Jetzt, Lassen Sie uns die Gründe für die Verwendung von PyCaret analysieren.
Warum brauchen wir PyCaret?
PyCaret erstellt automatisch das Referenzmodell mit einem Datensatz innerhalb von 5-6 Zeilen von Code. Sehen wir uns an, wie pycaret jeden Schritt in der Pipeline für maschinelles Lernen vereinfacht.
- Datenaufbereitung: PyCaret führt die Bereinigung und Datenvorverarbeitung mit dem geringsten manuellen Eingriff durch.
- Funktionsengineering: PyCaret erstellt die mathematischen Merkmale automatisch und wählt die wichtigsten für das Modell benötigten Merkmale aus
- Bau des Modells: Vereinfacht den Modellierungsteil Ihres Projekts erheblich. Wir können verschiedene Modelle erstellen und die Modelle mit der besten Leistung mit einer einzigen Codezeile auswählen.
- Modell fit: PyCaret stimmt das Modell ab, ohne explizit Hyperparameter an jedes Modell zu übergeben.
Dann, Wir konzentrieren uns auf die Lösung eines Textklassifikationsproblems in PyCaret.
Verschiedene Ansätze zur Lösung der Textklassifizierung in PyCaret
Lassen Sie uns ein Textklassifikationsproblem in PyCaret mit lösen 2 verschiedene Techniken:
- Themenmodellierung
- Zählvektorisierer
Ich werde jeden Fokus im Detail berühren
Themenmodellierung
Themenmodellierung, Wie der Name andeutet, ist eine Technik, um verschiedene Themen in den Textdaten zu identifizieren.
Themen werden als eine sich wiederholende Gruppe von Symbolen definiert (oder Worte) statistisch signifikant in einem Korpus. Hier, statistische Signifikanz bezieht sich auf wichtige Wörter im Dokument. Allgemein, Wörter, die häufig mit höheren TF-IDF-Werten vorkommen, gelten als statistisch signifikante Wörter.
Die Themenmodellierung ist eine unbeaufsichtigte Technik, um automatisch versteckte Themen in Textdaten zu finden. Es kann auch als Text-Mining-Ansatz bezeichnet werden, um wiederkehrende Muster in Textdokumenten zu finden.
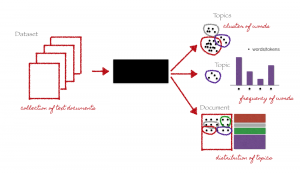
Themenmodellierung (Credits: https://medium.com/analytics-vidhya/topic-modeling-using-lda-and-gibbs-sampling-explained-49d49b3d1045)
Einige häufige Anwendungsfälle für die Themenmodellierung sind die folgenden:
-  Klassifikationsprobleme lösen / Textregression
- Erstellen Sie relevante Tags für Dokumente
- Informationen für Kundenfeedbackformulare generieren, Kundenbewertungen, Umfrageergebnisse, etc.
Beispiel für Themenmodellierung
Angenommen, Sie arbeiten für eine Anwaltskanzlei und Sie arbeiten mit einem Unternehmen zusammen, bei dem Geld veruntreut wurde und Sie wissen, dass in den E-Mails, die im Unternehmen verteilt wurden, wichtige Informationen enthalten sind.
- Dann, E-Mails checken und es gibt Hunderttausende von E-Mails. Jetzt, Was Sie tun müssen, ist herauszufinden, welche im Vergleich zu anderen Themen mit Geld zu tun haben.
- Sie können sie von Hand beschriften, basierend auf dem, was Sie im Text lesen, was lange dauern würde, oder Sie können die Technik namens . verwenden Themenmodellierung um herauszufinden, was diese Tags sind und alle diese E-Mails automatisch markieren.
Wie oben erklärt, Das Ziel der Themenmodellierung ist es, verschiedene Themen aus dem Rohtext zu extrahieren. Aber, Was ist der zugrunde liegende Algorithmus, um dies zu erreichen??
Dies bringt uns zu den verschiedenen Algorithmen / Techniken zur Modellierung von Themen: latente Dirichlet-Zuordnung (LDA), nicht negative Matrixfaktorisierung (NNMF), latente semantische Zuordnung (LSA).
Ich würde Ihnen empfehlen, sich auf die folgenden Ressourcen zu beziehen, um sich im Detail über die Algorithmen zu informieren
- Teil 2: Themenmodellierung und latente Dirichlet-Zuordnung (LDA) mit Gensim und Sklearn
- Anfängerleitfaden zur Themenmodellierung in Python
- Themenmodellierung mit LDA: eine praktische Einführung
Kommen wir zur Themenmodellierung, ist ein Prozess von 2 Schritte:
- Begriffsthemenverteilung: Finden Sie die wichtigsten Themen im Korpus.
- Dokument-zu-Themen-Verteilung: Weisen Sie jedem Dokument Punktzahlen für jedes Thema zu.
Themenmodellierung verstanden haben, Wir werden anhand eines Beispiels sehen, wie man die Textklassifikation mittels Topic Modeling löst.
Betrachten Sie ein Korpus:
- Dokumentieren 1: Ich möchte Obst zum Frühstück haben.
- Dokumentieren 2: Ich esse gerne Mandeln, Eier und Früchte.
- Dokumentieren 3: Ich nehme Obst und Kekse mit, wenn ich in den Zoo gehe.
- Dokumentieren 4: Der Tierpfleger füttert den Löwen sehr sorgfältig.
- Dokumentieren 5: Ihren Hunden sollten Kekse von guter Qualität gegeben werden.
Der Themenmodellierungsalgorithmus (LDA) identifiziert die wichtigsten Themen in den Dokumenten.
- Thema 1: 30% Früchte, 15% Eier, 10% Kekse,… (Mahlzeit)
- Thema 2: 20% Löwe, 10% Hunde, 5% Zoo,… (Tiere)
Dann, Weisen Sie Dokumenten wie folgt Punkte für jedes Thema zu.
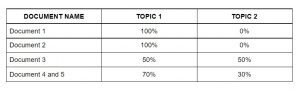
Weisen Sie jedem Dokument mithilfe von LDA Themen zu
Diese Matrix fungiert als Charakteristik des maschinellen Lernalgorithmus. Dann, Wir werden den Sack voller Worte sehen.
Beutel voller Worte
Beutel voller Worte (SICH BEUGEN) ist ein weiterer beliebter Algorithmus zur Darstellung von Text in Zahlen. Es hängt von der Häufigkeit der Wörter im Dokument ab. BOW hat zahlreiche Anwendungen wie die Dokumentenklassifizierung, Themenmodellierung und Textähnlichkeit. Und BOW, jedes Dokument wird als Häufigkeit der im Dokument vorkommenden Wörter dargestellt. Dann, die Häufigkeit der Wörter repräsentiert die Bedeutung der Wörter im Dokument.
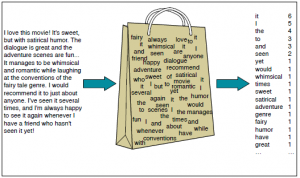
Beutel voller Worte (Credits: Jurafskyet al., 2018)
Folgen Sie dem folgenden Artikel, um ein detailliertes Verständnis von Bag Of Words zu erhalten:
Im nächsten Abschnitt, wir lösen das Textklassifikationsproblem in PyCaret.
Fallstudie: Textklassifizierung mit PyCaret
Lassen Sie uns die Problemstellung verstehen, bevor wir sie lösen.
Problembeschreibung verstehen
Steam ist ein digitaler Videospiel-Vertriebsdienst mit einer riesigen Community von Spielern weltweit. Viele Spieler schreiben Rezensionen auf der Spielseite und haben die Möglichkeit zu wählen, ob sie dieses Spiel anderen empfehlen oder nicht.. Aber trotzdem, Das automatische Bestimmen dieser Stimmung aus dem Text kann Steam dabei helfen, Bewertungen aus anderen Internetforen automatisch zu markieren und die Popularität von Spielen besser einzuschätzen.
Angesichts des Bewertungstextes mit der Empfehlung des Benutzers, die Aufgabe besteht darin, anhand des Rezensionstextes und anderer Informationen vorherzusagen, ob der Rezensent die im Testset verfügbaren Spieletitel empfohlen hat.
In einfacheren Worten, Die Aufgabe besteht darin zu erkennen, ob eine gegebene Benutzerbewertung gut oder schlecht ist. Sie können den Datensatz herunterladen von hier.
Implementierung
So bewerten Sie Steam-Spielebewertungen mit PyCaret, ich habe diskutiert 2 verschiedene Ansätze im Artikel.
- Der erste Ansatz verwendet die Themenmodellierung mit PyCaret.
- Der zweite Ansatz nutzt die Funktionen von Bag Of Words. Verwenden Sie diese Funktionen für die Klassifizierung mit PyCaret.
Wir werden den BOW-Ansatz jetzt implementieren.
Notiz: Das Tutorial ist in Google Colab implementiert. Ich würde empfehlen, den Code darin auszuführen.
PyCaret-Installation
Sie können PyCaret wie jede andere Python-Bibliothek installieren.
- PyCaret auf Google Colab oder Azure Notebooks installieren
Bibliotheken importieren
Lade Daten
Wie PyCaret den Zählvektorisierer nicht unterstützt, Importieren Sie das CountVectorizer-Modul von sklearn.feature_extraction.
Später, Ich initialisiere ein CountVectorizer-Objekt namens 'tf_vectorizer'.
Was genau macht die Funktion fit_transform mit Ihren Daten??
- “Anpassen” extrahiert die Eigenschaften des Datensatzes.
- “Umformen” führt tatsächlich die Transformationen des Datensatzes durch.
Lassen Sie uns die Ausgabe von fit_transform in den Datenrahmen konvertieren.
Jetzt, Verketten Sie die Merkmale und das Ziel entlang der Spalte.
Dann, wir werden den Datensatz in Test- und Trainingsdaten aufteilen.
Jetzt ist die Merkmalsextraktion abgeschlossen. Lassen Sie uns diese Funktionen verwenden, um verschiedene Modelle zu erstellen. Dann, der nächste Schritt ist die Konfiguration der Umgebung in PyCaret.
Umgebung einstellen
- Diese Funktion legt den Trainingsrahmen fest und baut den Übergangsprozess auf. Die Setup-Funktion muss aufgerufen werden, bevor eine andere Funktion aufgerufen werden kann.
- Der einzige obligatorische Parameter sind die Daten und das Ziel.
Erstellung von Modellen
Modell fit
Aus der vorherigen Ausgabe, Wir können sehen, dass die Metriken des angepassten Modells besser sind als die Metriken des Basismodells.
Bewerten und prognostizieren Sie das Modell
Hier, Ich habe die Flagwerte für unseren verarbeiteten Datensatz vorhergesagt, ‘tuned_lightgbm’.
Abschließende Anmerkungen
PyCaret, Trainieren von Machine-Learning-Modellen in einer Low-Code-Umgebung, hat mein Interesse geweckt. Von Ihrer bevorzugten Laptop-Umgebung, PyCaret hilft Ihnen, in Sekunden von der Datenaufbereitung zur Modellimplementierung zu gelangen. Vor der Verwendung von PyCaret, Ich habe andere traditionelle Methoden ausprobiert, um das JanataHack NLP-Hackathon-Problem zu lösen, Aber die Ergebnisse waren nicht sehr zufriedenstellend!!
PyCaret hat sich im Vergleich zu den anderen Open-Source-Machine-Learning-Bibliotheken als exponentiell schnell und effizient erwiesen und hat auch den Vorteil, mehrere Codezeilen mit nur wenigen Worten zu ersetzen..
Hier, wenn Sie den ersten Teil meines Ansatzes vermeiden, in dem ich die Einbettungstechniken des Zählvektorisierers in meinen Datensatz verwende und dann mit der Konfiguration und Erstellung von Modellen mit PyCaret fortfahre, dann kannst du feststellen, dass alle Transformationen, wie heißes Coding , die Anrechnung verlorener Werte, etc., passiert automatisch hinter den Kulissen, und dann erhalten Sie einen Datenrahmen mit Vorhersagen, Wie was wir haben!
Ich hoffe, ich habe meine generelle Herangehensweise an den Hackathon klar gemacht.





