Thema zu behandeln
- Was ist explorative Datenanalyse?
- Was ist notwendig, um die explorative Datenanalyse zu automatisieren??
- Python-Bibliotheken zur Automatisierung der explorativen Datenanalyse
Explorative Datenanalyse
ist eine Datenexplorationstechnik, um verschiedene Aspekte von Daten zu verstehen. Es ist ein bisschen wie Datenzusammenfassung. Dies ist einer der wichtigsten Schritte, bevor Sie eine maschinelle Lern- oder Deep-Learning-Aufgabe durchführen..
Data Scientists führen explorative Datenanalyseverfahren durch, um zu erkunden, die grundlegenden Eigenschaften von Datensätzen sezieren und zusammenfassen, regelmäßiger Einsatz von Informationsrepräsentationsansätzen. EDA-Verfahren berücksichtigen überzeugende Kontrolle der Informationsquellen, Datenwissenschaftlern ermöglichen, die richtigen Antworten zu finden, die sie beim Finden von Informationsdesigns benötigen, Inkonsistenzen erkennen, Annahmen überprüfen oder Spekulationen testen.
Data Scientists nutzen explorative Datenanalyse um zu sehen, welche Datensätze sie über die herkömmliche Anzeige von Informationen hinaus entdecken können oder Spekulationstestaufgaben. Auf diese Weise können sie sich von oben nach unten über die Faktoren in den Datensätzen und deren Zusammenhänge informieren.. Explorative Datenanalyse kann helfen, eindeutige Fehler zu erkennen, Ausnahmen in Datensätzen unterscheiden, Verbindungen bekommen, wichtige Elemente entdecken, Insider-Designs entdecken und neue Erkenntnisse liefern.
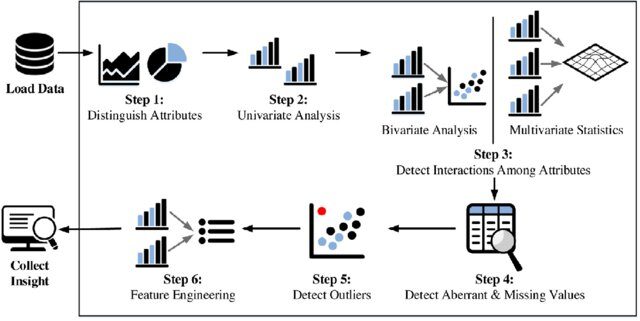
Schritte in der explorativen Datenanalyse
Notwendigkeit, die explorative Datenanalyse zu automatisieren
Die erweiterte Bewegung der Kunden im Web, die raffinierten Tools zur Kontrolle des Web-Traffics, die Vermehrung von Mobiltelefonen, webfähige Geräte und IoT-Sensoren sind die wesentlichen Elemente, die das Tempo des heutigen Informationszeitalters beschleunigen. In diesem computerisierten Zeitalter, Verbände jeder Größe wissen, dass Informationen eine entscheidende Rolle bei der Verbesserung ihrer Kompetenz spielen können, Rentabilität und dynamische Fähigkeiten, was zu größeren Vereinbarungen führt, Einkommen und Leistungen.
Heute, die meisten Organisationen gehen mit riesigen Datensätzen um, aber trotzdem, Nur große Mengen an Informationen zu haben, verbessert das Geschäft nicht, es sei denn, Unternehmen recherchieren zugängliche Daten und drängen auf autorisierte Entwicklung.

Im Lebenszyklus eines Data-Science-Projekts oder eines Machine-Learning-Projekts, mehr als 60% deiner Zeit in Sachen Datenanalyse einsteigen, Merkmalsauswahl, Feature-Engineering, etc. Weil es der wichtigste Teil oder das Rückgrat eines Data-Science-Projekts ist, es ist dieser spezielle Teil, in dem Sie viele Aktivitäten wie das Bereinigen der Daten durchführen müssen, mit fehlenden Werten umgehen , mit Ausreißern umgehen, Umgang mit unausgeglichenen Datensätzen, Umgang mit kategorialen Merkmalen und vieles mehr. Also wenn du willst Sparen Sie Ihre Zeit in der explorativen Datenanalyse, wir können Python-Bibliotheken verwenden wie dtale, Pandas Profil, Sweetviz und Autoviz um unsere Aufgaben zu automatisieren.

Bibliotheken automatisieren explorative Datenanalyse
In diesem Blog, wir haben vier wichtige Python-Bibliotheken besprochen. Diese sind unten aufgeführt:
- Geschichte
- Pandas Profil
- süßviz
- autoviz
D-Geschichte
Es ist eine Bibliothek, die im Februar gestartet wurde 2020 was es uns ermöglicht, den Pandas-Datenrahmen einfach zu visualisieren. Es verfügt über viele Funktionen, die für die explorative Datenanalyse sehr nützlich sind. Es wird mit dem Flask-Backend erstellt und reagiert auf das Frontend. Unterstützt interaktive Grafiken, 3D-Grafik, Heatmaps, die Korrelation zwischen den Eigenschaften, Erstellen Sie benutzerdefinierte Spalten und vieles mehr. Er ist der bekannteste und der Favorit von allen.
Installation
dtale kann mit dem folgenden Code installiert werden:
pip installiere dtale
Explorative Datenanalyse mit D-tale
Tauchen wir mit dieser Bibliothek tiefer in die explorative Datenanalyse ein. Zuerst, Wir müssen einen Code schreiben, um die interaktive d-tale-Anwendung lokal zu starten:
Daten importieren
Pandas als pd importieren
df = pd.read_csv('data.csv')
d = dtale.show(df)
d.open_browser()
Hier importieren wir Pandas und geben es. Wir lesen den Datensatz mit der Funktion read_csv () und schließlich zeigen wir die Daten im Browser lokal über die Funktion anzeigen an und öffnen den Browser.
Zeigen Sie Daten auf die gleiche Weise an wie Pandas, aber es hat eine zusätzliche Funktion, Es hat ein Menü in der oberen linken Ecke, mit dem wir viele Dinge tun können und die Anzahl der Spalten und Zeilen in unserem Datensatz anzeigt.
Die Ausgabe des obigen Codes ist unten gezeigt:
Wenn Sie auf eine Spaltenüberschrift klicken, Dropdown-Menü wird angezeigt. Es wird Ihnen viele Möglichkeiten bieten, So sortieren Sie die Daten, den Datensatz beschreiben, Säulenanalyse und vieles mehr. Sie können diese Funktion auch selbst überprüfen
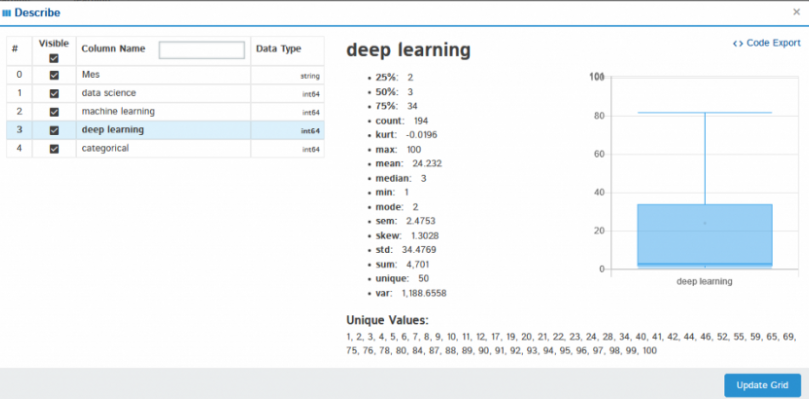
Wenn Sie auf Beschreiben klicken, zeigt die statistische Analyse der ausgewählten Spalte als Mittelwert an, Median, maximal, minimale Varianz, Standardabweichung, Quartile und viele mehr.
Auf die gleiche Weise, Sie können andere Funktionen selbst ausprobieren, als Säulenanalyse, Formate, Filter.
Magie von dtale: Klicken Sie auf die Menüschaltfläche und Sie finden alle verfügbaren Optionen
Nicht alle Funktionen können abgedeckt werden, aber ich beschreibe die interessantesten.
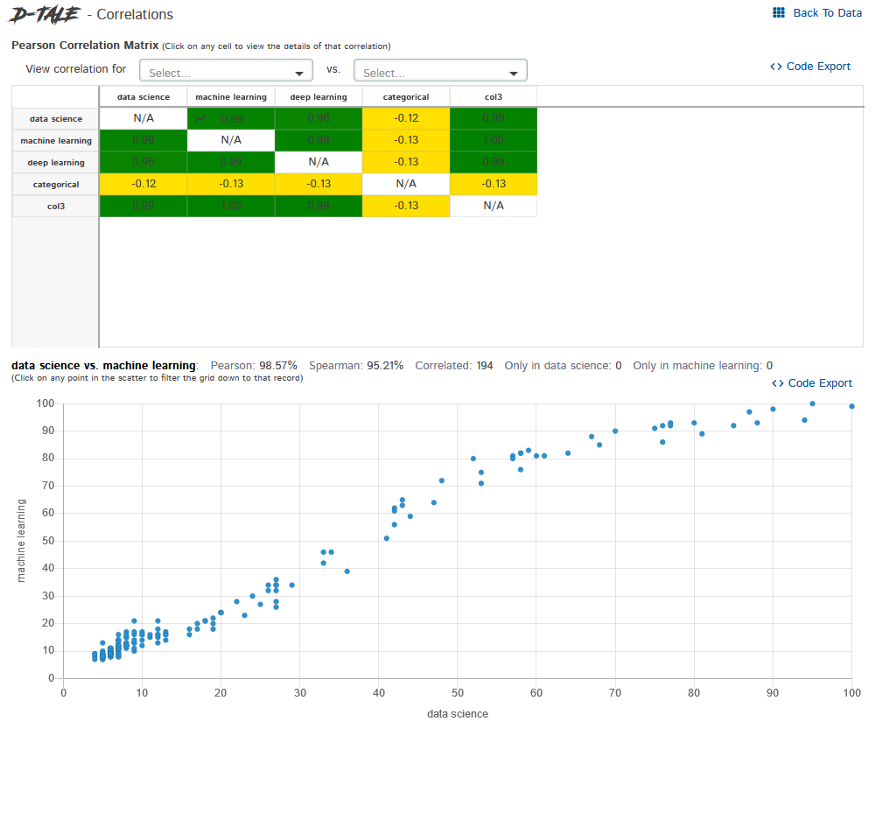
Korrelationen – Es zeigt uns, wie die Spalten miteinander korrelieren.
Grafik– Zolldiagramme als Liniendiagramme erstellen, Balkendiagramme, Kreisdiagramme, gestapelte Grafiken, Streudiagramme, geologische Karten, etc.
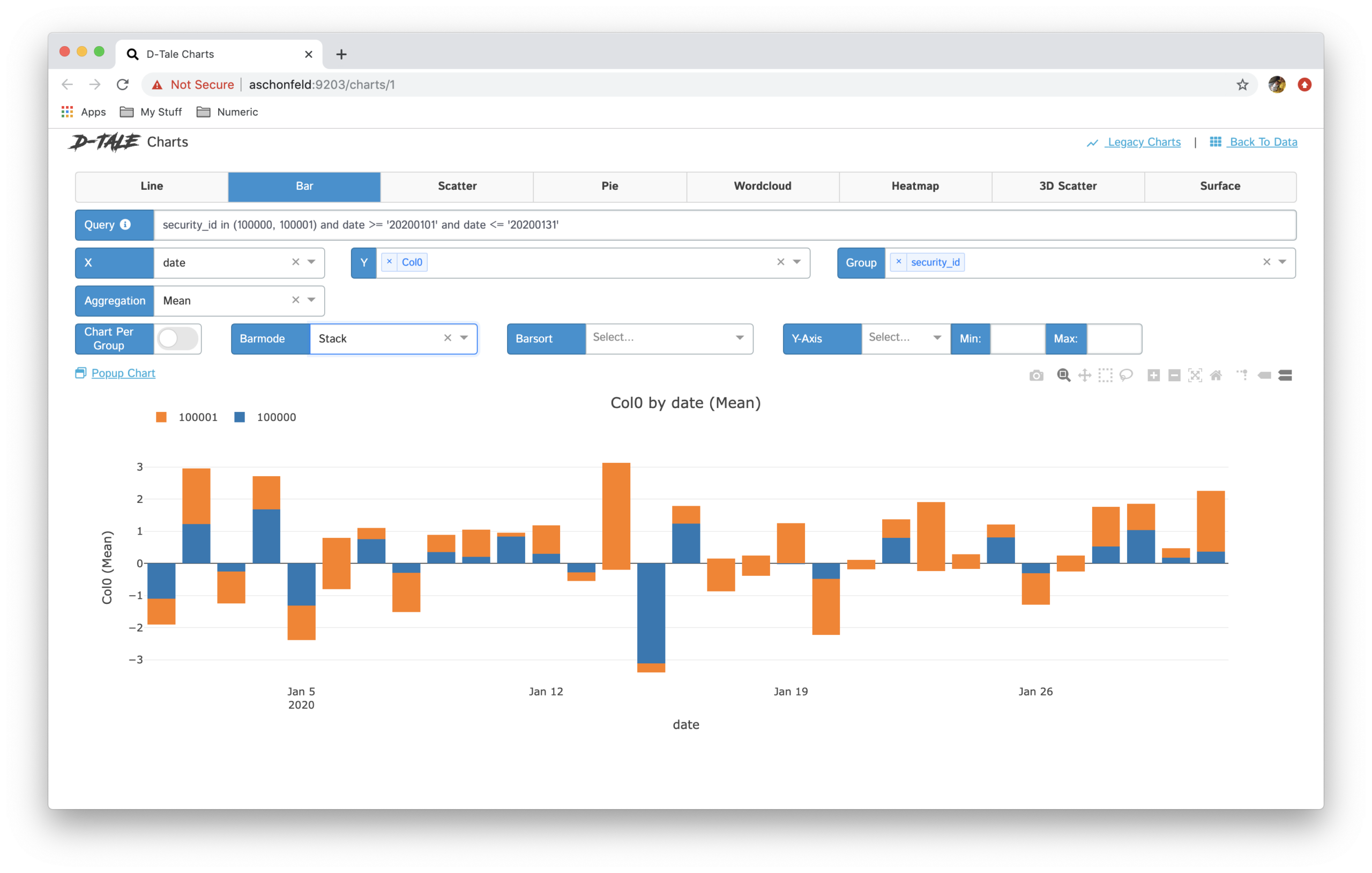
In dieser Bibliothek stehen viele Optionen für die Datenanalyse zur Verfügung. Dieses Tool ist sehr nützlich und macht die explorative Datenanalyse viel schneller als die Verwendung herkömmlicher Bibliotheken für maschinelles Lernen wie Pandas, matplotlib, etc.
Um offizielle Dokumente zu erhalten, Überprüfen Sie diesen Link:
Pandas-Profiling

Es ist eine in Python geschriebene Open-Source-Bibliothek, die interaktive HTML-Berichte generiert und verschiedene Aspekte des Datensatzes beschreibt. Zu den wichtigsten Funktionen gehört der Umgang mit fehlenden Werten, Datensatzstatistik als Mittelwert, Mode, Median, Asymmetrie, Standardabweichung, etc., auch Grafiken wie Histogramme und Korrelationen.
Installation
Pandas Profiling kann mit dem folgenden Code installiert werden:
pip install Pandas-Profiling
Explorative Datenanalyse mit Pandas Profiling
Tauchen wir mit dieser Bibliothek tiefer in die explorative Datenanalyse ein. Ich verwende ein Beispiel-Dataset, um mit der Profilerstellung von Pandas zu beginnen, Überprüfen Sie den folgenden Code:
#Importieren erforderlicher Pakete
Pandas als pd importieren
pandas_profiling importieren
numpy als np importieren
#Daten importieren
df = pd.read_csv('sample.csv')
#beschreibende Statistik
pandas_profiling.ProfileReport(df)
Unten ist die magische Ausgabe des obigen Codes
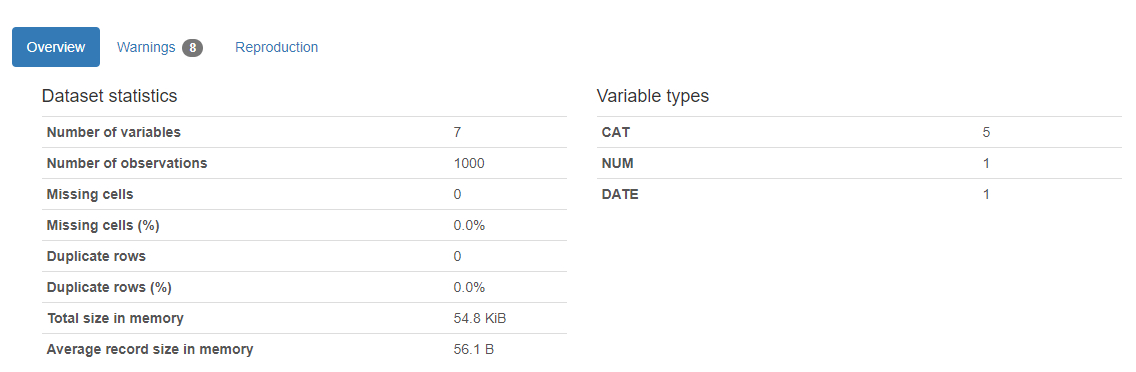
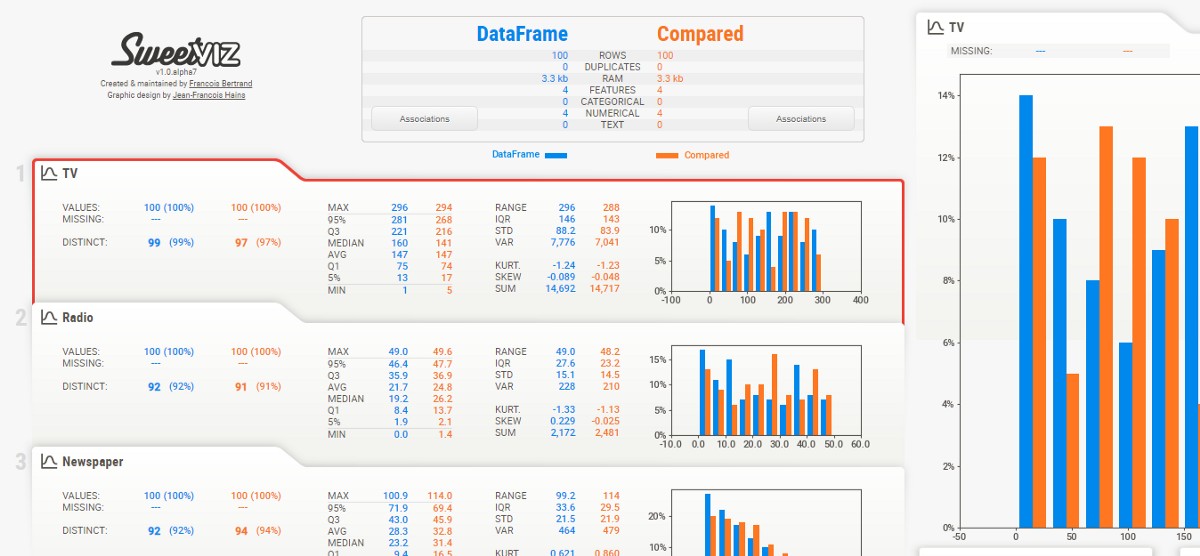
Hier ist das Ergebnis. Ein Bericht wird angezeigt und gibt an, wie viele Variablen sich in unserem Datensatz befinden, die Anzahl der Reihen, die fehlenden Zellen im Datensatz, der Prozentsatz der fehlenden Zellen, die Anzahl und der Prozentsatz der doppelten Zeilen. Fehlende und doppelte Zelldaten sind für unsere Analyse sehr wichtig, da sie das größere Bild des Datensatzes beschreiben. Der Bericht zeigt auch die Gesamtspeichergröße an. Es zeigt auch die Variablentypen auf der rechten Seite der Ausgabe an.
Der Variablenbereich zeigt die Analyse einer bestimmten Spalte. Zum Beispiel für die kategoriale Variable, die folgende Ausgabe erscheint.
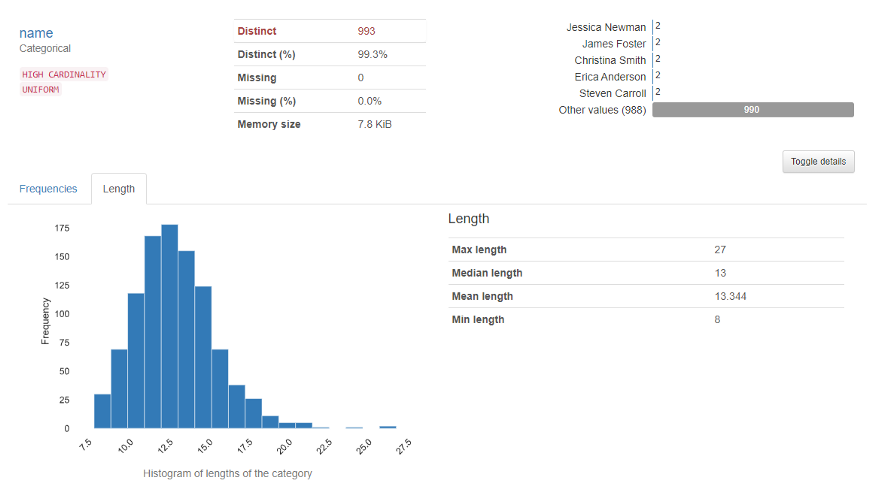
Für ihn numerische Variable, die folgende Ausgabe erscheint
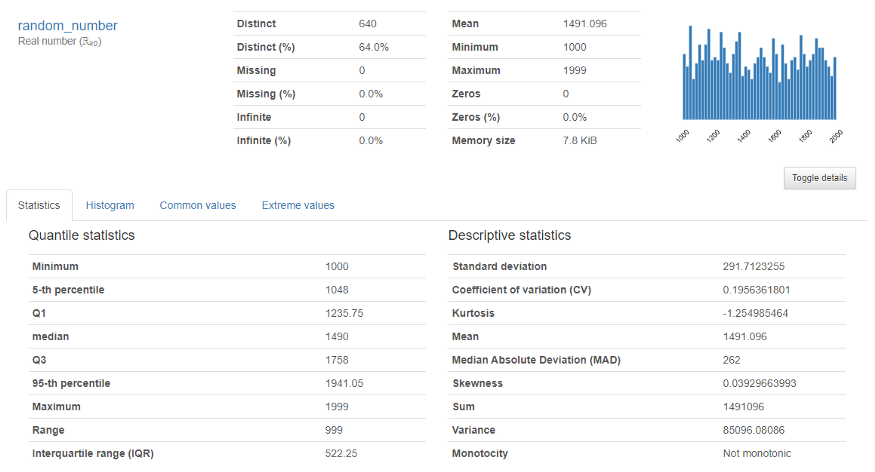
Bietet eine eingehende Analyse numerischer Variablen als Quantil, Medien, Mediansumme, Abweichung, Monotonie, Rang, Krümmung, Interquartilsabstand und viele mehr.
Korrelationen und Interaktion: Beschreiben Sie, wie Variablen miteinander korreliert sind mit. Diese Daten werden von Data Scientists dringend benötigt.
Für mehr Informationen, konsultieren Sie die offizielle Dokumentation:
Süßviz
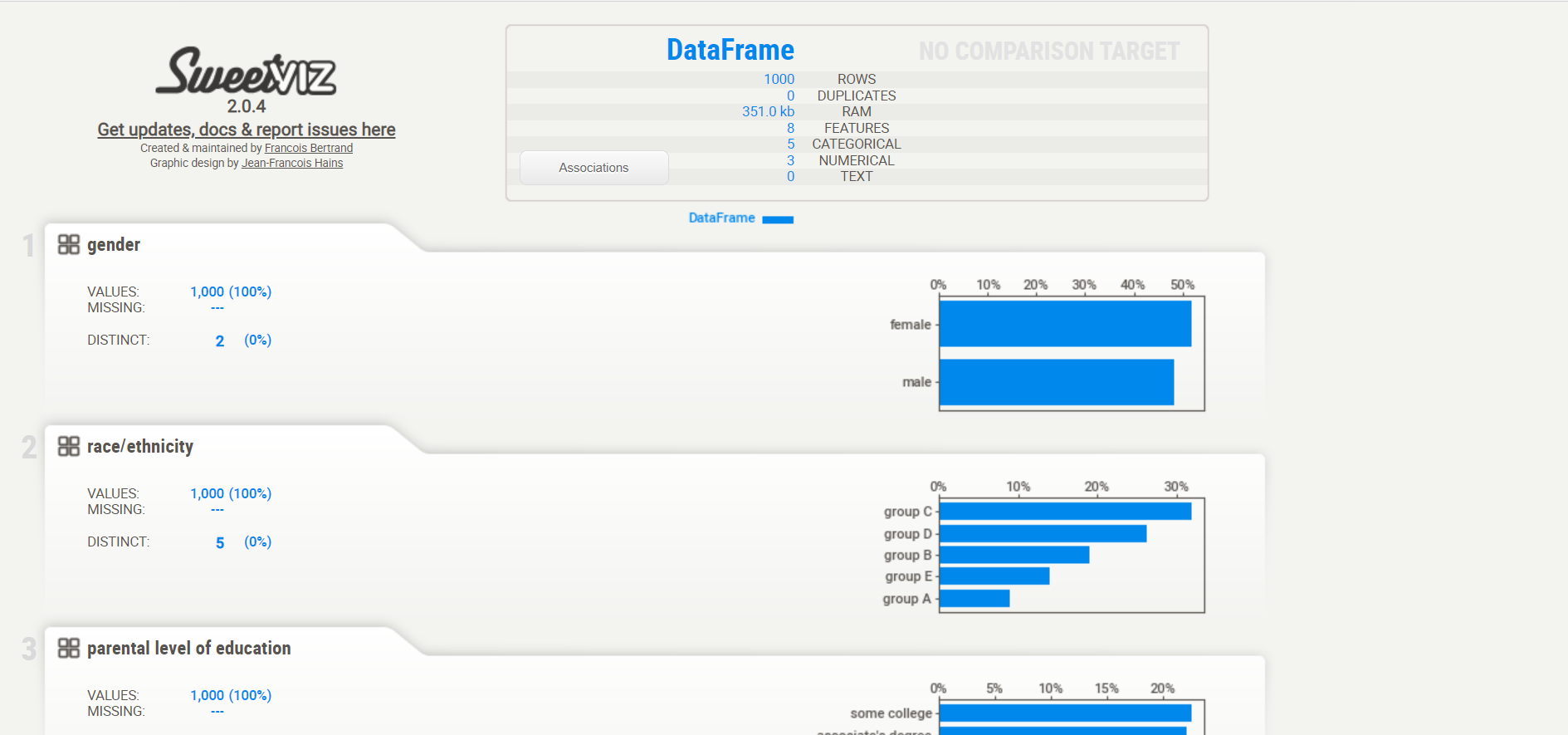
Es ist eine Open-Source-Python-Bibliothek, die verwendet wurde, um Visualisierungen zu erhalten, was bei der explorativen Datenanalyse mit nur wenigen Codezeilen nützlich ist. Die Bibliothek kann verwendet werden, um die Variablen zu visualisieren und den Datensatz zu vergleichen.
Installation
Diese Bibliothek kann mit dem folgenden Code installiert werden:
pip installieren sweetviz
Explorative Datenanalyse mit SweetViz
Tauchen wir mit dieser Bibliothek tiefer in die explorative Datenanalyse ein. Ich verwende ein Beispiel-Dataset, um zu beginnen, Überprüfen Sie den folgenden Code
Sweetviz importieren
Pandas als pd importieren
df = pd.read_csv('sample.csv')
my_report = sweetviz.analyze([df,'Bahn'], target_feat="VerkaufPreis")
my_report.show_html('FinalReport.html')
Abschlussbericht:
Für mehr Informationen, konsultieren Sie die offizielle Dokumentation:
Autoviz
Bedeutet Anzeige automatisch. Visualisierung ist bei jeder Größe des Datensatzes mit wenigen Codezeilen möglich.

Installation
pip install autoviz
Anzeige
Beispielcode:
aus autoviz.AutoViz_Class importieren AutoViz_Class
AV = AutoViz_Class()
df = AV.AutoViz('sample.csv')
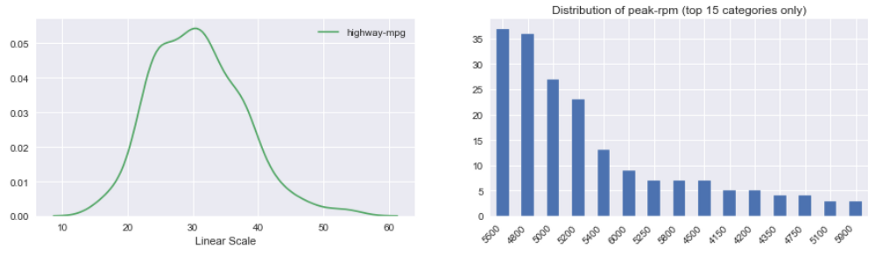
Kontinuierliches Variablenhistogramm:
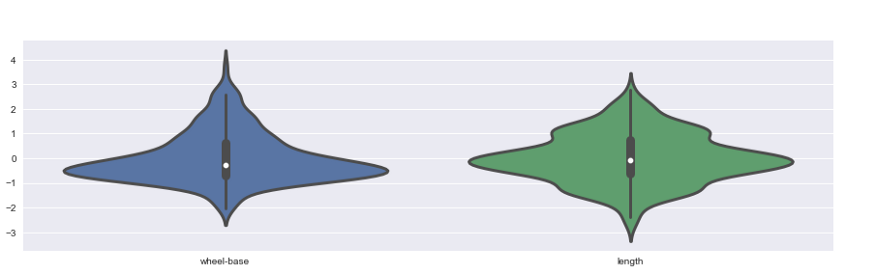
Violinrahmen:
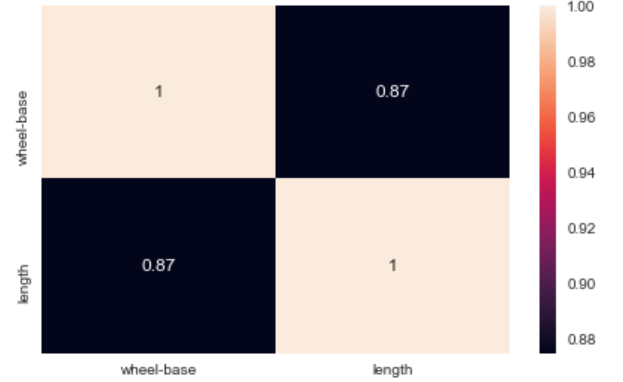
Heatmap:
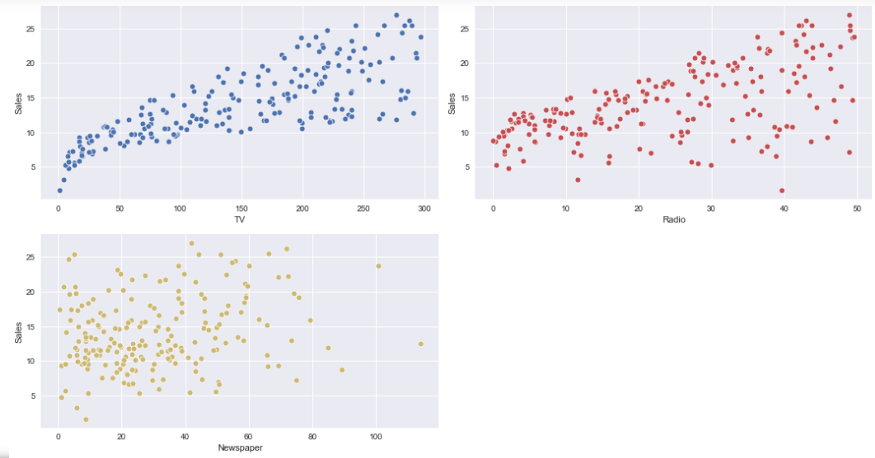
Streudiagramm:
Für mehr Informationen, konsultieren Sie die offizielle Dokumentation:
Danke, dass du das gelesen hast. Wenn dir dieser Artikel gefällt, Teile es mit deinen Freunden. Bei Anregungen / Zweifel, kommentiere unten.
E-Mail-Identifikation: [E-Mail geschützt]
Folgen Sie mir auf LinkedIn: LinkedIn
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von DataPeaker und werden nach Ermessen des Autors verwendet.





