Dieser Artikel wurde im Rahmen der Data Science Blogathon.
Einführung

Web Scraping ist eine Methode oder Kunst, um Daten aus dem Internet oder Websites zu erhalten oder zu löschen und lokal auf Ihrem System zu speichern. Web Scripting ist eine programmierte Strategie, um viele Informationen von Websites zu erhalten.
Die überwiegende Mehrheit dieser Informationen sind unstrukturierte Informationen in einem HTML-Layout, die später in organisierte Informationen in einer Buchhaltungsseite oder einem Datensatz umgewandelt werden., Daher wird es in der Regel in verschiedenen Anwendungen verwendet. Es gibt eine Vielzahl von Ansätzen für das Web-Scraping, um Informationen von Websites zu erhalten. Dazu gehört die Nutzung von Webanwendungen, spezifische API aus, auf jeden Fall, Erstellen Sie Ihren Code für das Web-Scraping ohne Vorbereitung.
Zahlreiche riesige Seiten wie Google, Twitter, Facebook, Paketüberfluss, etc. über APIs verfügen, mit denen Sie in einer organisierten Organisation auf Ihre Informationen zugreifen können. Dies ist die idealste Option, aber unterschiedliche Gebietsschemata erlauben es Clients nicht, auf viele Informationen in einer organisierten Struktur zuzugreifen oder, im Wesentlichen, sie gehen nicht so mechanisch voran. Da drüben, Es ist ideal, Web Scraping zu verwenden, um Informationen auf der Website zu finden.

Web Scraper können alle Informationen zu bestimmten Zielen oder die speziellen Informationen, die ein Kunde benötigt, extrahieren. Vorzugsweise, Ideal ist es, wenn Sie die benötigten Informationen angeben, damit der Web Scraper diese Informationen einfach schnell konzentriert. Zum Beispiel, Sie sollten eine Amazon-Seite für die verfügbaren Arten von Entsaftern durchkratzen, aber trotzdem, Möglicherweise benötigen Sie nur die Informationen zu den Modellen verschiedener Entsafter und nicht die Kundenaudits.
Dann, wenn ein Web-Debugger eine Website kratzen muss, Zuerst werden Ihnen die URLs der erforderlichen Gebietsschemas zur Verfügung gestellt. An diesem Punkt, stapeln Sie den gesamten HTML-Code für diese Ziele und ein weiter entwickelter Scraper kann sogar alle CSS- und Javascript-Komponenten konzentrieren. An diesem Punkt, der Scraper entnimmt diesem HTML-Code die notwendigen Informationen und übermittelt diese Informationen an die vom Auftraggeber angegebene Organisation.
Allgemein, Dies ist wie eine Excel-Buchhaltungsseite oder ein CSV-Datensatz, aber trotzdem, Informationen können auch in verschiedenen Organisationen gespeichert werden, zum Beispiel, ein JSON-Dokument.

Beliebte Python-Bibliotheken für Web-Scraping
- Petitionen
- Schöne Suppe 4
- lxml
- Selen
- kratzig
AutoScraper
Es ist eine Python-Web-Scraping-Bibliothek, um Web-Scraping intelligent zu machen, automatisch, schnell und einfach. Es ist auch leicht, was bedeutet, dass es keinen großen Einfluss auf Ihren PC hat. Ein Benutzer kann dieses Daten-Scraping-Tool aufgrund seiner benutzerfreundlichen Oberfläche leicht verwenden.. Anfangen, Sie müssen nur ein paar Zeilen Code schreiben und Sie werden die Magie sehen.
Sie müssen nur die URL oder den HTML-Inhalt der Webseite angeben, von der Sie Daten entfernen möchten, was ist mehr, eine Zusammenfassung der Testinformationen, die wir von dieser Seite entfernen sollten. Diese Informationen können Text sein, URL oder ein HTML-Tag auf dieser Seite. Lernen Sie die Rubbelregeln selbst und geben Sie ähnliche Artikel zurück.
In diesem Artikel, Wir werden Autoscraper untersuchen und sehen, wie wir damit Informationen von uns entfernen können.

Installation
Es gibt 3 Möglichkeiten, diese Bibliothek auf Ihrem System zu installieren.
- Installation aus dem Git-Repository mit pip:
pip install git+https://github.com/alirezamika/autoscraper.git
Pip Autoscraper installieren
python setup.py installieren
Bibliothek importieren
Wir werden nur einen automatischen Schaber importieren, da es nur zum Kratzen im Web geeignet ist. Unten ist der Code zum Importieren:
aus Autoscraper importieren AutoScraper
Definition der Web-Scraping-Funktion
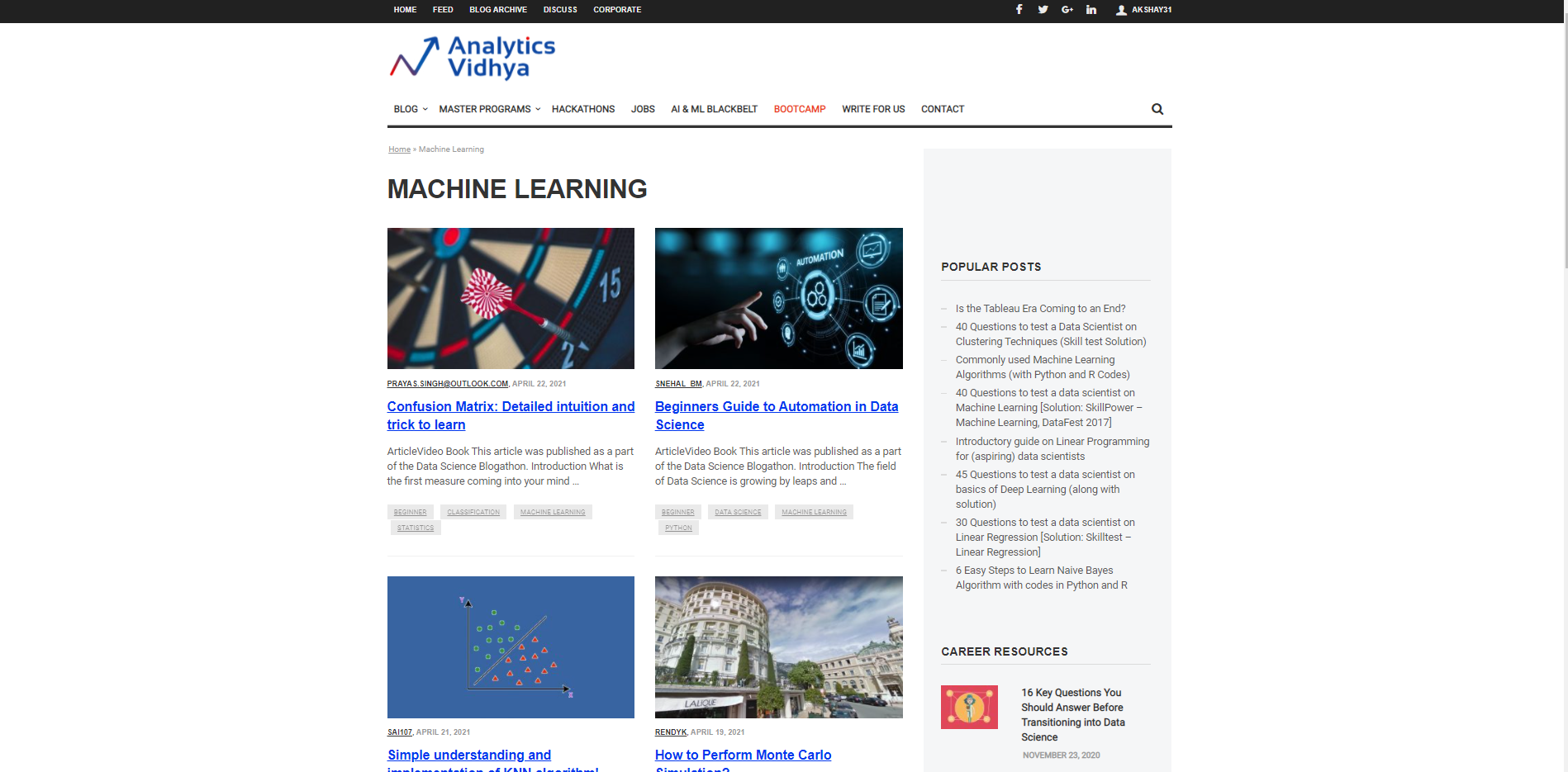
Beginnen wir damit, eine URL zu charakterisieren, von der aus sie verwendet wird, um die Informationen und den Nachweis der erforderlichen Informationen einzubringen. Angenommen, wir möchten nach dem suchen Titel für verschiedene Artikel zum Thema Machine Learning auf der DataPeaker-Website. Deswegen, wir müssen die URL des DataPeaker-Blog-Abschnitts für maschinelles Lernen und die zweite Fahndungsliste übergeben. Die Fahndungsliste ist eine Liste, die ist Beispieldaten die wir aus dieser Seite extrahieren wollen. Zum Beispiel, hier ist die gesuchte Liste der Titel eines Blogs im Blogging-Bereich für maschinelles Lernen von DataPeaker.
URL="https://www.analyticsvidhya.com/blog/category/machine-learning/" gesuchte_liste = ['Verwirrung Matrix: Detaillierte Intuition und Trick zum Lernen']
Wir können einen oder mehrere Kandidaten zur Suchliste hinzufügen. Sie können auch URLs in die Suchliste einfügen, um die URLs abzurufen.
Starten Sie den AutoScraper
Der nächste Schritt nach dem Starten der URL und der gesuchten Liste ist der Aufruf der AutoScraper-Funktion. Unser Ziel ist es, diese Funktion zu verwenden, um das Scraper-Modell zu erstellen und Web-Scraping auf dieser bestimmten Seite durchzuführen.
Dies kann mit dem folgenden Code gestartet werden:
Schaber = AutoScraper()
Das Objekt bauen
Dies ist der letzte Schritt beim Web-Scraping mit dieser speziellen Bibliothek. Hier, Erstellen Sie das Objekt und zeigen Sie das Ergebnis des Web-Scrapings an.
Schaber = AutoScraper() Ergebnis = Schaber.build(URL, Fahndungsliste) drucken(Ergebnis)

Hier, im Bild oben, du kannst sehen es kommt zurück. der Titel des Blogs auf der DataPeaker-Website im Bereich Machine Learning, ähnlich, Wir können die URLs der Blogs abrufen, indem wir einfach die Beispiel-URL in die zuvor definierte Suchliste übergeben.
URL="https://www.analyticsvidhya.com/blog/category/machine-learning/" gesuchte_liste = ['https://www.analyticsvidhya.com/blog/2021/04/confusion-matrix-detailed-intuition-and-trick-to-learn/'] Schaber = AutoScraper() Ergebnis = Schaber.build(URL, Fahndungsliste) drucken(Ergebnis)
Hier ist die Ausgabe des obigen Codes. Ihr seht, dass ich diesmal die URL in der Fahndungsliste übergeben habe, infolge, Sie können das Ergebnis sehen als Blog-URLs

Modell speichern
Es ermöglicht uns, das Modell zu speichern, das wir bauen müssen, um es bei Bedarf wieder aufladen zu können.
Um das Modell zu speichern, Verwenden Sie den folgenden Code
Schaber.save('Blogs') #Geben Sie ihm einen Dateipfad
So laden Sie das Modell, Verwenden Sie den folgenden Code:
Schaber.Laden('Blogs')
Notiz: Abgesehen von jeder dieser Funktionen, Der automatische Scraper ermöglicht es Ihnen auch, Proxy-IP-Adressen zu charakterisieren, um sie zur Informationsbeschaffung verwenden zu können. Wir müssen lediglich die Proxys charakterisieren und sie als Argument an die Build-Funktion übergeben, wie unten gezeigt:
Proxys = {
"http": 'http://127.0.0.1:8001',
"https": 'https://127.0.0.1:8001',
}
Ergebnis = Schaber.build(URL, Fahndungsliste, request_args=dict(Stellvertreter = Stellvertreter))
Für mehr Informationen, siehe den Link unten: AutoScraper
Fazit
In diesem Artikel, wir erkennen, wie wir Autoscraper für Web-Scraping verwenden können, indem wir ein einfaches und einfach zu verwendendes Modell erstellen. Wir haben mehrere Formate gesehen, in denen Informationen mit Autoscraper abgerufen werden können. Wir können das Modell auch speichern und laden, um es später zu verwenden, das spart Zeit und Mühe. Autoscraper ist unglaublich, einfach zu bedienen und effizient.
Vielen Dank für das Lesen dieses Artikels und für Ihre Geduld.. Lassen Sie mich im Kommentarbereich über Kommentare. Teile diesen Artikel, es wird mir die Motivation geben, mehr Blogs für die Data Science Community zu schreiben.
E-Mail-Identifikation: gakshay1210@ gmail.com
Folgen Sie mir auf LinkedIn: LinkedIn
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von DataPeaker und werden nach Ermessen des Autors verwendet.





