Einführung
Sind Sie jemals auf einen Datensatz oder ein Bild gestoßen und haben sich gefragt, ob Sie ein System erstellen könnten, das in der Lage ist, das Bild zu unterscheiden oder zu identifizieren??
Dabei hilft uns das Konzept der Bildklassifizierung.. Die Bildklassifizierung ist eine der beliebtesten Anwendungen der Computer Vision und ein unverzichtbares Konzept für jeden, der in diesem Bereich eine Rolle spielen möchte..
In diesem Artikel, Wir werden eine sehr einfache, aber weit verbreitete Anwendung sehen, die Bildklassifizierung ist. Wir werden nicht nur sehen, wie man ein einfaches und effizientes Modell zur Klassifizierung der Daten erstellt, aber wir werden auch lernen, wie man ein zuvor trainiertes Modell implementiert und die Leistung der beiden vergleicht.
Am Ende des Artikels, finden Sie Ihren eigenen Datensatz und implementieren Sie die Bildklassifizierung mit Leichtigkeit.
Voraussetzungen vor dem Start:
Hört sich interessant an? Machen Sie sich also bereit, Ihren eigenen Bildklassifikator zu erstellen!!
Inhaltsverzeichnis
- Bildklassifizierung
- Problembeschreibung verstehen
- Bilddateneinstellungen
- Lassen Sie uns unser Bildklassifizierungsmodell erstellen
- Datenvorverarbeitung
- Datenerweiterung
- Definition und Bildung des Modells
- Auswertung der Ergebnisse
- Die Kunst des transferierten Lernens
- MobileNetV2-Basismodell importieren
- Sintonia FINA
- Ausbildung
- Auswertung der Ergebnisse
- Was kommt als nächstes?
Was ist Bildklassifizierung??
Die Bildklassifizierung ist die Aufgabe, ein Eingabebild zuzuordnen, ein Tag aus einem festen Satz von Kategorien. Dies ist eines der zentralen Probleme von Computer Vision, das, trotz seiner Einfachheit, hat eine Vielzahl von praktischen Anwendungen.
Nehmen wir ein Beispiel, um es besser zu verstehen. Wenn wir die Bildklassifizierung durchführen, unser System erhält ein Bild als Eingabe, zum Beispiel, eine Katze. Jetzt kennt das System eine Reihe von Kategorien und sein Ziel ist es, dem Bild eine Kategorie zuzuordnen.
Dieses Problem mag einfach oder einfach erscheinen, aber es ist ein sehr schwieriges Problem für den Computer zu lösen. Woher willst du wissen?, der Computer sieht ein Zahlenraster und nicht das Bild einer Katze, wie wir es sehen. Die Bilder sind dreidimensionale Arrays von ganzen Zahlen von 0 ein 255, Größe Breite x Höhe x 3. Das 3 repräsentiert die drei Kanäle in Rot, Verde, Blau.
Dann, Wie kann unser System lernen, dieses Bild zu identifizieren?? Durch die Verwendung von Convolutional Neural Networks. Convolutional Neural Networks oder CNNs sind eine Klasse von neuronalen Deep-Learning-Netzen, die einen Durchbruch in der Bilderkennung darstellen. Möglicherweise haben Sie bereits ein grundlegendes Verständnis von CNN, und wir wissen, dass CNN aus Faltungsschichten besteht, Relu-Schichten, geclusterte Schichten und vollständig verbundene dichte Schichten.
Um mehr über Bildklassifizierung und CNN zu erfahren, Sie können die folgenden Ressourcen konsultieren: –
- https://www.analyticsvidhya.com/blog/2020/02/learn-image-classification-cnn-convolutional-neural-networks-3-datasets/
- https://www.analyticsvidhya.com/blog/2019/01/build-image-classification-model-10-minutes/
Jetzt, da wir die Konzepte verstehen, Lassen Sie uns untersuchen, wie ein Bildklassifizierungsmodell erstellt und implementiert werden kann.
Problembeschreibung verstehen
Betrachten Sie das folgende Bild:

Eine sportlich versierte Person wird das Bild als Rugby erkennen können. Es kann verschiedene Aspekte des Bildes geben, die Ihnen geholfen haben, es als Rugby zu identifizieren, es kann die Form des Balls oder das Outfit des Spielers sein. Aber ist Ihnen aufgefallen, dass dieses Bild durchaus als Fußballbild identifiziert werden kann??
Betrachten wir ein anderes Bild: –

Was denkst du, repräsentiert dieses Bild?? Schwer zu erraten, Wahrheit? Das Bild für das unerfahrene menschliche Auge kann leicht als Fußball fehlklassifiziert werden, Aber in Wirklichkeit, Es ist ein Rugby-Image, da sehen wir, dass der Torpfosten dahinter kein Netz ist und größer ist. Die Frage ist nun, ob wir ein System erstellen können, das das Bild möglicherweise richtig klassifizieren kann.
Das ist die Idee hinter unserem Projekt hier, Wir möchten ein System aufbauen, das in der Lage ist, die Sportart, die in diesem Bild dargestellt wird, zu identifizieren. Die beiden Klassifizierungsklassen hier sind Rugby und Fußball. Das Problem zu formulieren kann etwas schwierig sein, da Sport viele Gemeinsamkeiten hat, aber trotzdem, Wir werden lernen, das Problem anzugehen und ein leistungsfähiges System zu erstellen.
Konfiguration unserer Bilddaten
Da wir an einem Bildklassifizierungsproblem arbeiten, Ich habe zwei der größten Quellen für Bilddaten verwendet, nämlich, ImageNet und Google OpenImages. Ich habe zwei Python-Skripte implementiert, damit wir die Bilder einfach herunterladen können. Insgesamt 3058 Bilder, die unterteilt waren in train und test. Ich habe einen Split gemacht 80-20 mit der Zugmappe die ich hatte 2448 Bilder und der Testordner hat 610. Sowohl Rugby- als auch Fußballklassen haben 1224 Bilder jeweils.
Unsere Datenstruktur ist wie folgt: –
- Eintrag – 3058
- Bahn – 2048
- Rugby – 1224
- Fußball – 1224
- Bahn – 2048
-
- Prüfen – 610
- Rugby – 310
- Fußball – 310
- Prüfen – 610
Lassen Sie uns unser Bildklassifizierungsmodell erstellen!
Paso 1: – Importieren Sie die erforderlichen Bibliotheken
Hier verwenden wir die Keras-Bibliothek, um unser Modell zu erstellen und zu trainieren. Wir verwenden auch Matplotlib und Seaborn, um unseren Datensatz zu visualisieren und ein besseres Verständnis der Bilder zu erhalten, die wir verarbeiten werden.. Eine weitere wichtige Bibliothek für den Umgang mit Bilddaten ist Opencv.
import matplotlib.pyplot als plt
Seegeboren als sns importieren
keras importieren
von keras.models importieren Sequential
aus keras.layers importieren dicht, Conv2D , MaxPool2D , Ebnen , Dropout
from keras.preprocessing.image import ImageDataGenerator
from keras.optimizers import Adam
from sklearn.metrics import classification_report,Verwirrung Matrix
Tensorflow als tf importieren
CV2 importieren
Importieren von OS
numpy als np importieren
Paso 2: – Laden der Daten
Dann, lass uns den Weg zu unseren Daten definieren. Lassen Sie uns eine Funktion namens get_data definieren () um uns die Erstellung unseres Zug- und Validierungsdatensatzes zu erleichtern. Wir definieren die beiden Labels ‚Rugby‘’ und Fußball’ was werden wir verwenden. Wir verwenden die Imread-Funktion von Opencv, um die Bilder im RGB-Format zu lesen und die Größe der Bilder auf unsere gewünschte Breite und Höhe zu ändern, in diesem Fall sind beides 224.
Etiketten = ['Rugby', 'Fußball']
img_size = 224
def get_data(data_dir):
Daten = []
für Etiketten in Etiketten:
path = os.path.join(data_dir, Etikett)
class_num = labels.index(Etikett)
für img in os.listdir(Weg):
Versuchen:
img_arr = cv2.imread(os.path.join(Weg, img))[...,::-1] #convert BGR to RGB format
resized_arr = cv2.resize(img_arr, (img_size, img_size)) # Reshaping images to preferred size
data.append([resized_arr, klasse_num])
außer Ausnahme als e:
drucken(e)
np.array zurückgeben(Daten)
Jetzt können wir unsere Zug- und Validierungsdaten einfach abrufen.
train = get_data('../input/traintestsports/Main/train')
val = get_data('../input/traintestsports/Main/test')
Paso 3: – Visualisieren Sie die Daten
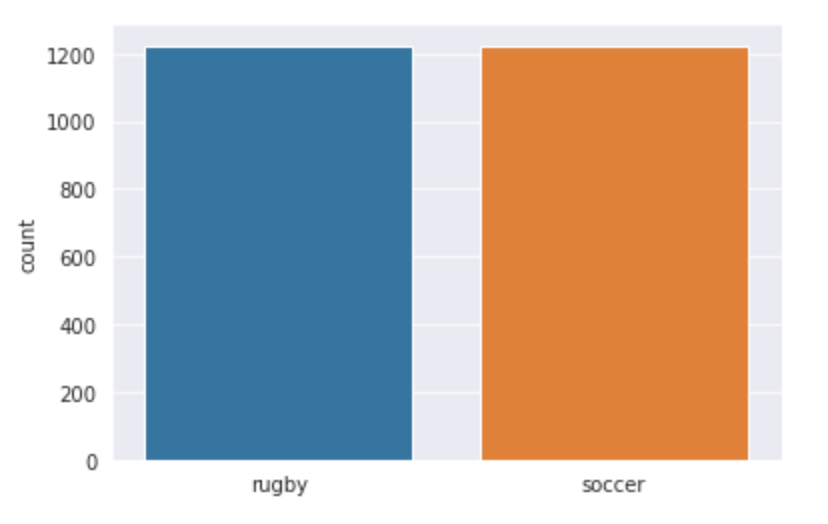
Lassen Sie uns unsere Daten visualisieren und sehen, womit wir genau arbeiten. Wir verwenden seaborn, um die Anzahl der Bilder in beiden Klassen darzustellen und Sie können sehen, wie die Ausgabe aussieht.
l = []
für mich im zug:
Wenn(ich[1] == 0):
l.append("Rugby")
else
l.append("Fußball")
sns.set_style('dunkelgrit')
sns.countplot(l)
Produktion:
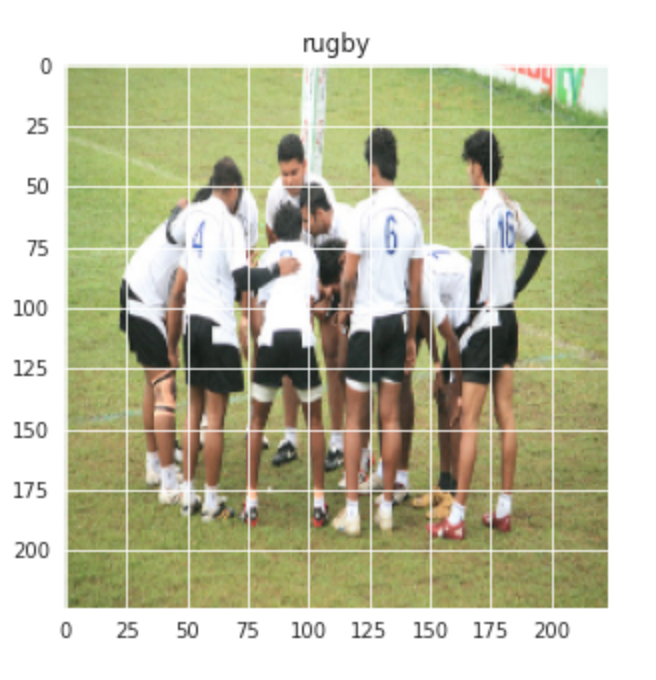
Lassen Sie uns auch ein zufälliges Bild der Rugby- und Fußballklassen visualisieren: –
plt.figur(Feigengröße = (5,5)) plt.imshow(Bahn[1][0]) plt.titel(Etiketten[Bahn[0][1]])
Produktion:-
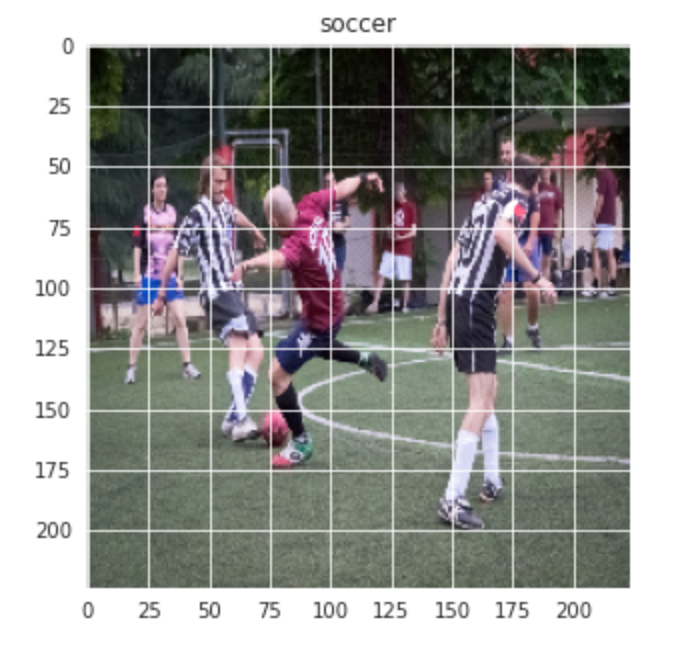
Ähnlich für das Fußballbild: –
plt.figur(Feigengröße = (5,5)) plt.imshow(Bahn[-1][0]) plt.titel(Etiketten[Bahn[-1][1]])
Produktion:-
Paso 4: – Datenvorverarbeitung und -erweiterung
Dann, Wir führen ein wenig Vorverarbeitung und Datenerweiterung durch, bevor wir mit dem Aufbau des Modells fortfahren können.
x_train = [] y_train = [] x_val = [] y_val = [] für Funktion, Etikett im Zug: x_train.append(Besonderheit) y_train.append(Etikett) für Funktion, Etikett im Wert: x_val.append(Besonderheit) y_val.append(Etikett) # Normalisieren Sie die Daten x_train = np.array(x_train) / 255 x_val = np.array(x_val) / 255 x_train.reshape(-1, img_size, img_size, 1) y_train = np.array(y_train) x_val.reshape(-1, img_size, img_size, 1) y_val = np.array(y_val)
Zunahme der Daten zu Zugdaten: –
datagen = ImageDataGenerator(
featurewise_center=Falsch, # Eingabemittelwert setzen auf 0 over the dataset
samplewise_center=False, # setze jeden Stichprobenmittelwert auf 0
featurewise_std_normalization=Falsch, # divide inputs by std of the dataset
samplewise_std_normalization=False, # divide each input by its std
zca_whitening=False, # apply ZCA whitening
rotation_range = 30, # Bilder zufällig im Bereich drehen (Grad, 0 zu 180)
zoom_range = 0.2, # Randomly zoom image
width_shift_range=0.1, # Bilder zufällig horizontal verschieben (Bruchteil der Gesamtbreite)
height_shift_range=0,1, # Bilder zufällig vertikal verschieben (Bruchteil der Gesamthöhe)
horizontal_flip = Wahr, # randomly flip images
vertical_flip=False) # Bilder nach dem Zufallsprinzip drehen
datagen.fit(x_train)
Paso 5: – Definiere das Modell
Definieren wir ein einfaches CNN-Modell mit 3 Faltungsschichten gefolgt von Schichten maximaler Gruppierung. Nach dem dritten maxpool-Vorgang wird ein Tropfenmantel hinzugefügt, um eine Überanpassung zu verhindern.
Modell = Sequentiell() model.add(Conv2D(32,3,Polsterung="gleich", Aktivierung="Lebenslauf", input_shape=(224,224,3))) model.add(MaxPool2D()) model.add(Conv2D(32, 3, Polsterung="gleich", Aktivierung="Lebenslauf")) model.add(MaxPool2D()) model.add(Conv2D(64, 3, Polsterung="gleich", Aktivierung="Lebenslauf")) model.add(MaxPool2D()) model.add(Aussteigen(0.4)) model.add(Ebnen()) model.add(Dicht(128,Aktivierung="Lebenslauf")) model.add(Dicht(2, Aktivierung="softmax")) Modell.Zusammenfassung()
Lassen Sie uns nun das Modell kompilieren, indem wir Adam als unseren Optimierer und SparseCategoricalCrossentropy als Verlustfunktion verwenden. Wir verwenden eine niedrigere Lernrate von 0.000001 für eine glattere Kurve.
opt = Adam(lr=0,000001) model.compile(Optimierer = opt , loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=Wahr) , Metriken = ['Richtigkeit'])
Jetzt, lass uns unser Modell währenddessen trainieren 500 Epochen, da unsere Lernrate sehr gering ist.
Geschichte = model.fit(x_train,y_train,Epochen = 500 , Validierung_Daten = (x_val, y_val))
Paso 6: – Auswertung des Ergebnisses
Wir werden unsere Trainings- und Validierungsgenauigkeit zusammen mit dem Trainings- und Validierungsverlust verfolgen.
acc = history.history['Richtigkeit']
val_acc = history.history['val_accuracy']
Verlust = Geschichte.Geschichte['Verlust']
val_loss = history.history['val_loss']
Epochen_Bereich = Reichweite(500)
plt.figur(Feigengröße=(15, 15))
plt.subplot(2, 2, 1)
plt.plot(Epochenbereich, acc, Etikett="Trainingsgenauigkeit")
plt.plot(Epochenbereich, val_acc, Etikett="Validierungsgenauigkeit")
plt.legende(loc ="rechts unten")
plt.titel('Trainings- und Validierungsgenauigkeit')
plt.subplot(2, 2, 2)
plt.plot(Epochenbereich, Verlust, Etikett="Trainingsverlust")
plt.plot(Epochenbereich, Wertverlust, Etikett="Validierungsverlust")
plt.legende(loc ="oben rechts")
plt.titel('Trainings- und Validierungsverlust')
plt.zeigen()
Mal sehen wie die Kurve aussieht: –
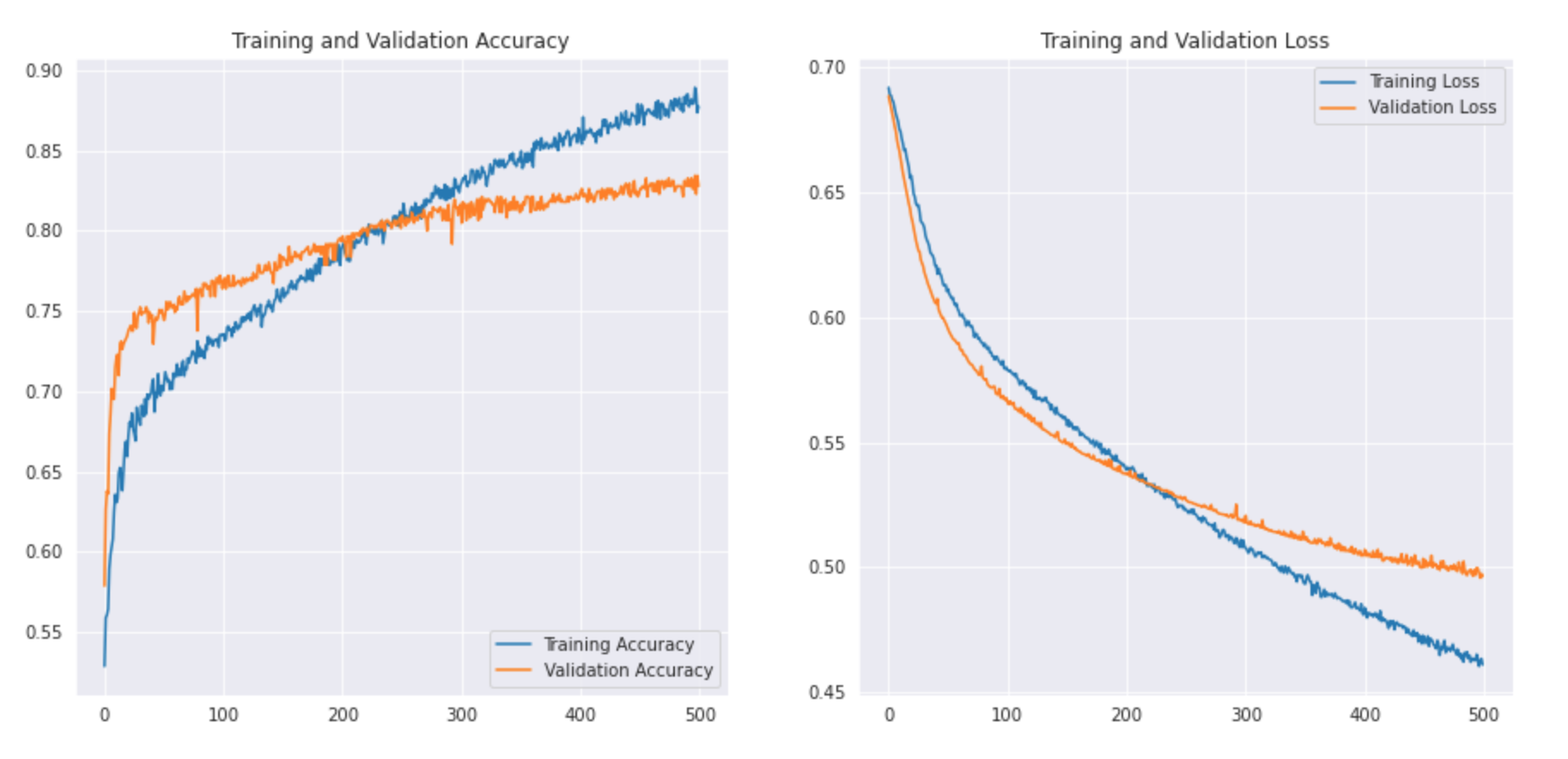
Wir können den Klassifizierungsbericht ausdrucken, um die Präzision und Genauigkeit zu sehen.
Vorhersagen = model.predict_classes(x_val) Vorhersagen = Vorhersagen.reshape(1,-1)[0] drucken(Klassifizierungsbericht(y_val, Vorhersagen, target_names = ['Rugby (Klasse 0)','Fußball (Klasse 1)']))
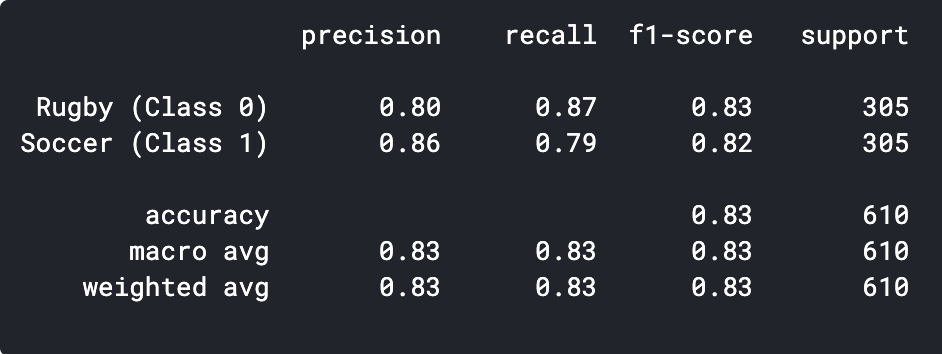
Wie wir sehen können, Unser einfaches CNN-Modell konnte eine Genauigkeit von 83%. Mit einigen Hyperparameter-Einstellungen, wir konnten eine genauigkeit von erreichen 2-3%.
Wir können auch einige der falsch vorhergesagten Bilder visualisieren und sehen, wo unser Klassifikator versagt.
Die Kunst des transferierten Lernens
Sehen wir uns zuerst an, was Transferlernen ist. Transfer Learning ist eine Technik des maschinellen Lernens, bei der ein an einer Aufgabe trainiertes Modell auf eine zweite verwandte Aufgabe umgeleitet wird. Eine weitere entscheidende Anwendung des Transferlernens ist, wenn der Datensatz klein ist, Durch die Verwendung eines zuvor trainierten Modells auf ähnlichen Bildern können wir leicht eine hohe Leistung erzielen. Da unsere Problemstellung gut zum Transferlernen passt, mal sehen, wie wir ein vortrainiertes Modell implementieren und welche Präzision wir erreichen können.
Paso 1: – Modell importieren
Wir erstellen ein Basismodell aus dem MobileNetV2-Modell. Dies ist auf dem ImageNet-Datensatz vortrainiert, ein großer Datensatz bestehend aus 1,4 Millionen Bilder und 1000 Lektionen. Diese Wissensdatenbank hilft uns, Rugby und Fußball anhand unseres spezifischen Datensatzes zu klassifizieren..
Durch Angabe des Arguments include_top = False, lädt ein Netzwerk, das die Klassifizierungsschichten oben nicht enthält.
base_model = tf.keras.applications.MobileNetV2(input_shape = (224, 224, 3), include_top = Falsch, Gewichte = "imagenet")
Es ist wichtig, unsere Datenbank einzufrieren, bevor Sie das Modell kompilieren und trainieren. Das Einfrieren verhindert, dass die Gewichte unseres Basismodells während des Trainings aktualisiert werden.
base_model.trainable = Falsch
Dann, Wir definieren unser Modell mit unserem base_model, gefolgt von einer GlobalAveragePooling-Funktion, um die Features in einen einzelnen Vektor pro Bild umzuwandeln. Wir fügen einen Ausfall von . hinzu 0.2 und die letzte dichte Schicht mit 2 Neuronen und Softmax-Aktivierung.
model = tf.keras.Sequential([base_model,
tf.keras.layers.GlobalAveragePooling2D(),
tf.keras.layers.Dropout(0.2),
tf.harte.Schichten.Dense(2, Aktivierung="softmax")
])
Dann, Lassen Sie uns das Modell kompilieren und mit dem Training beginnen.
base_learning_rate = 0.00001
model.compile(Optimizer=tf.hard.optimizers.Adam(lr=base_learning_rate),
loss=tf.keras.losses.BinaryCrossentropy(from_logits=Wahr),
Metriken=['Richtigkeit'])
Geschichte = model.fit(x_train,y_train,Epochen = 500 , Validierung_Daten = (x_val, y_val))
Paso 2: – Auswertung des Ergebnisses.
acc = history.history['Richtigkeit']
val_acc = history.history['val_accuracy']
Verlust = Geschichte.Geschichte['Verlust']
val_loss = history.history['val_loss']
Epochen_Bereich = Reichweite(500)
plt.figur(Feigengröße=(15, 15))
plt.subplot(2, 2, 1)
plt.plot(Epochenbereich, acc, Etikett="Trainingsgenauigkeit")
plt.plot(Epochenbereich, val_acc, Etikett="Validierungsgenauigkeit")
plt.legende(loc ="rechts unten")
plt.titel('Trainings- und Validierungsgenauigkeit')
plt.subplot(2, 2, 2)
plt.plot(Epochenbereich, Verlust, Etikett="Trainingsverlust")
plt.plot(Epochenbereich, Wertverlust, Etikett="Validierungsverlust")
plt.legende(loc ="oben rechts")
plt.titel('Trainings- und Validierungsverlust')
plt.zeigen()
Mal sehen wie die Kurve aussieht: –
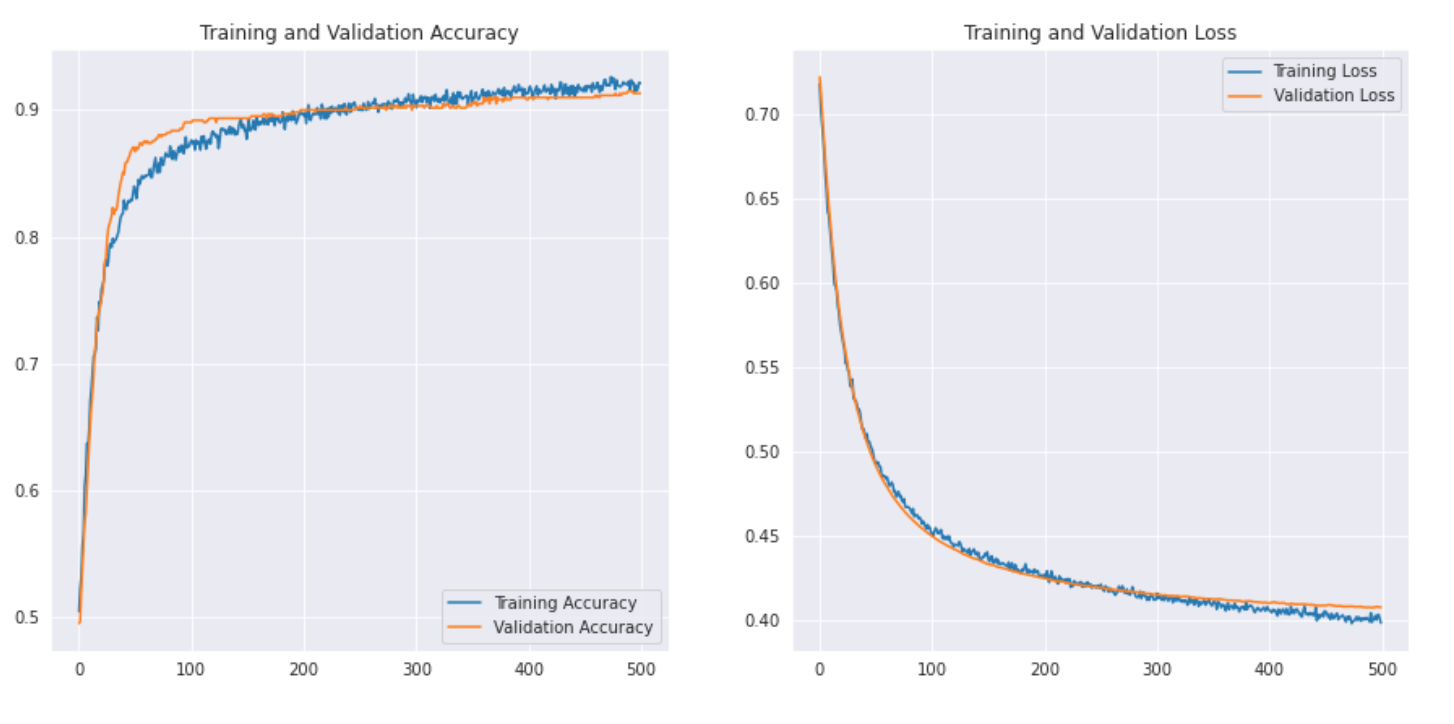
Wir drucken auch den Klassifizierungsbericht, um detailliertere Ergebnisse zu erhalten.
Vorhersagen = model.predict_classes(x_val) Vorhersagen = Vorhersagen.reshape(1,-1)[0] drucken(Klassifizierungsbericht(y_val, Vorhersagen, target_names = ['Rugby (Klasse 0)','Fußball (Klasse 1)']))
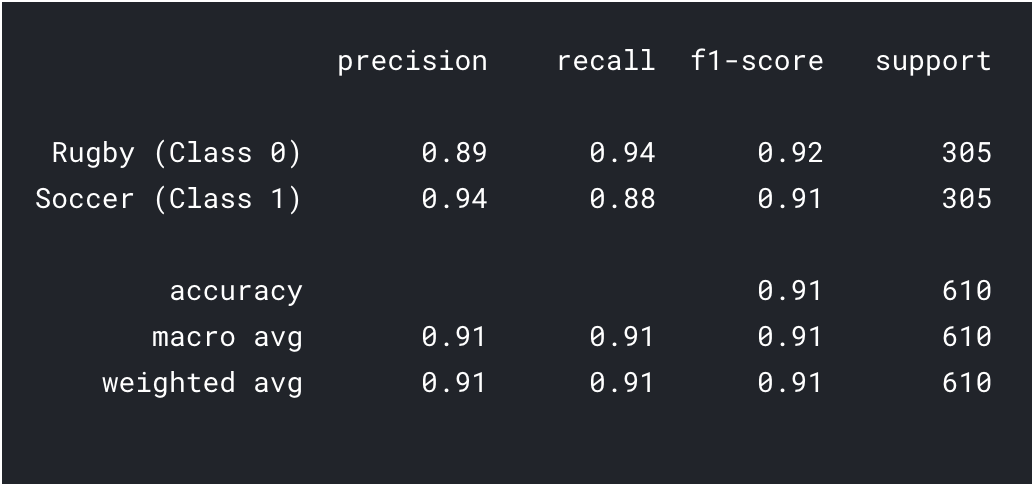
Wie wir beim Transferlernen sehen können, wir konnten ein viel besseres Ergebnis erzielen. Sowohl die Rugby- als auch die Fußballgenauigkeit sind höher als bei unserem CNN-Modell und auch die Gesamtgenauigkeit erreichte die 91%, was ist wirklich gut für so einen kleinen datensatz. Mit ein bisschen Hyperparameter-Tuning und Parameteränderungen, Wir könnten auch eine etwas bessere Leistung erzielen!!
Was kommt als nächstes?
Dies ist nur der Ausgangspunkt im Bereich Computer Vision.. Eigentlich, Versuchen Sie, Ihre grundlegenden CNN-Modelle zu verbessern, um die Benchmark-Leistung zu erreichen oder zu übertreffen.
- Sie können von VGG16-Architekturen lernen, etc. für einige Hinweise zum Hyperparameter-Tuning.
- Sie können denselben ImageDataGenerator verwenden, um Ihre Bilder zu vergrößern und die Größe des Datensatzes zu erhöhen.
- Was ist mehr, Sie können versuchen, neuere und bessere Architekturen wie DenseNet und XceptionNet zu implementieren.
- Sie können auch zu anderen Computer Vision-Aufgaben übergehen, wie Objekterkennung und Segmentierung, was Sie später feststellen werden, dass es sich auch auf die Bildklassifizierung reduzieren lässt.
Abschließende Anmerkungen
Herzliche Glückwünsche, Sie haben gelernt, wie Sie Ihren eigenen Datensatz erstellen und ein CNN-Modell erstellen oder Transfer-Lernen durchführen, um ein Problem zu lösen. Wir haben in diesem Artikel viel gelernt, vom Erlernen der Suche nach Bilddaten bis hin zur Erstellung eines einfachen CNN-Modells, das eine angemessene Leistung erzielen konnte. Wir haben auch die Anwendung von Transfer Learning gelernt, um unsere Leistung weiter zu verbessern.
Das ist nicht das Ende, Wir haben gesehen, dass unsere Models viele Bilder falsch klassifiziert haben, was bedeutet, dass es noch Raum für Verbesserungen gibt. Wir könnten damit beginnen, mehr Daten zu finden oder sogar neuere und bessere Architekturen zu implementieren, die möglicherweise besser bei der Identifizierung von Funktionen sind.
Findest du diesen Artikel hilfreich? Teilen Sie Ihr wertvolles Feedback im Kommentarbereich unten mit.. Fühlen Sie sich frei, auch Ihre vollständigen Codebücher zu teilen, das wird für die Mitglieder unserer Community nützlich sein.





