Seit dem letzten Jahrzehnt, Wir haben gesehen, dass die GPU in Bereichen wie HPC häufiger ins Spiel kam (High Performance Computing) und das beliebteste Feld, nämlich, die Spiele. GPUs haben sich Jahr für Jahr verbessert und sind jetzt in der Lage, wahnsinnig coole Dinge zu tun, aber in den letzten Jahren haben sie durch Deep Learning noch mehr Aufmerksamkeit erregt.

Wie Deep-Learning-Modelle viel Zeit mit dem Training verbringen, selbst leistungsstarke CPUs waren nicht effizient genug, um so viele Berechnungen zu einem bestimmten Zeitpunkt zu bewältigen, und in diesem Bereich übertrafen GPUs die CPUs einfach aufgrund ihrer Parallelität. Aber bevor wir tief tauchen, Lassen Sie uns zuerst ein paar Dinge über die GPU verstehen.
Was ist die GPU??
Eine GPU oder "Graphics Processing Unit"’ Es ist eine Mini-Version eines vollständigen Computers, aber nur einer bestimmten Aufgabe gewidmet. Es unterscheidet sich von einer CPU, die mehrere Aufgaben gleichzeitig ausführt. Die GPU verfügt über einen eigenen Prozessor, der zusammen mit V-RAM oder Video-RAM in das eigene Motherboard integriert ist, und auch ein passendes thermisches Design zur Belüftung und Kühlung.
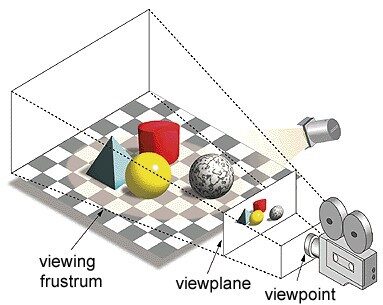
Im Begriff 'Graphics Processing Unit', 'Grafik’ bezieht sich auf das Rendern eines Bildes an bestimmten Koordinaten im 2D- oder 3D-Raum. Ein Fenster oder Blickwinkel ist die Perspektive eines Zuschauers, um ein Objekt entsprechend der verwendeten Projektionsart zu betrachten. Rasterung und Raytracing sind einige der Möglichkeiten zum Rendern von 3D-Szenen, Beide Konzepte basieren auf einer Projektionsart, die als perspektivische Projektion bezeichnet wird. Was ist perspektivische Projektion??
Zusammenfassend, ist die Art und Weise, wie ein Bild auf einer Ansichtsebene oder Leinwand erzeugt wird, bei der parallele Linien zu einem konvergenten Punkt namens "Projektionszentrum" zusammenlaufen’ auch wenn sich das Objekt vom Blickpunkt wegbewegt, erscheint es kleiner , genau wie unsere Augen in der realen Welt dargestellt werden und dies hilft auch, die Tiefe eines Bildes zu verstehen, Das ist der Grund, warum es realistische Bilder erzeugt.
Was ist mehr, GPUs verarbeiten auch komplexe Geometrie, Vektor, Lichtquellen oder Beleuchtungen, Texturen, Formen, etc. Da wir jetzt eine grundlegende Vorstellung von der GPU haben, Lassen Sie uns verstehen, warum es häufig für Deep Learning verwendet wird.
Warum sind GPUs besser für Deep Learning geeignet??
Eine der am meisten bewunderten Eigenschaften einer GPU ist die Fähigkeit, Prozesse parallel zu berechnen. Dies ist der Punkt, an dem das Konzept von paralleles Rechnen in Aktion gehen. Eine CPU erledigt ihre Aufgabe in der Regel sequentiell. Eine CPU kann in Kerne unterteilt werden und jeder Kern führt jeweils eine Aufgabe aus. Angenommen, eine CPU hat 2 Kerne. Später, Auf diesen beiden Kernen können zwei verschiedene Taskprozesse ausgeführt werden, so erreichen Sie Multitasking.
Aber dennoch, diese Prozesse laufen seriell.
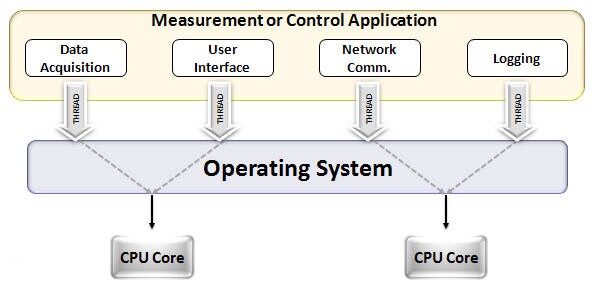
Dies bedeutet nicht, dass die CPUs nicht gut genug sind.. Eigentlich, CPUs sind wirklich gut darin, verschiedene Aufgaben im Zusammenhang mit verschiedenen Operationen zu bewältigen, wie z. B. den Umgang mit Betriebssystemen, Tabellenkalkulationen liefern, HD-Videos abspielen, große Zip-Dateien extrahieren, Alles zur selben Zeit. Dies sind einige der Dinge, die eine GPU nicht kann.
Wo ist der Unterschied?
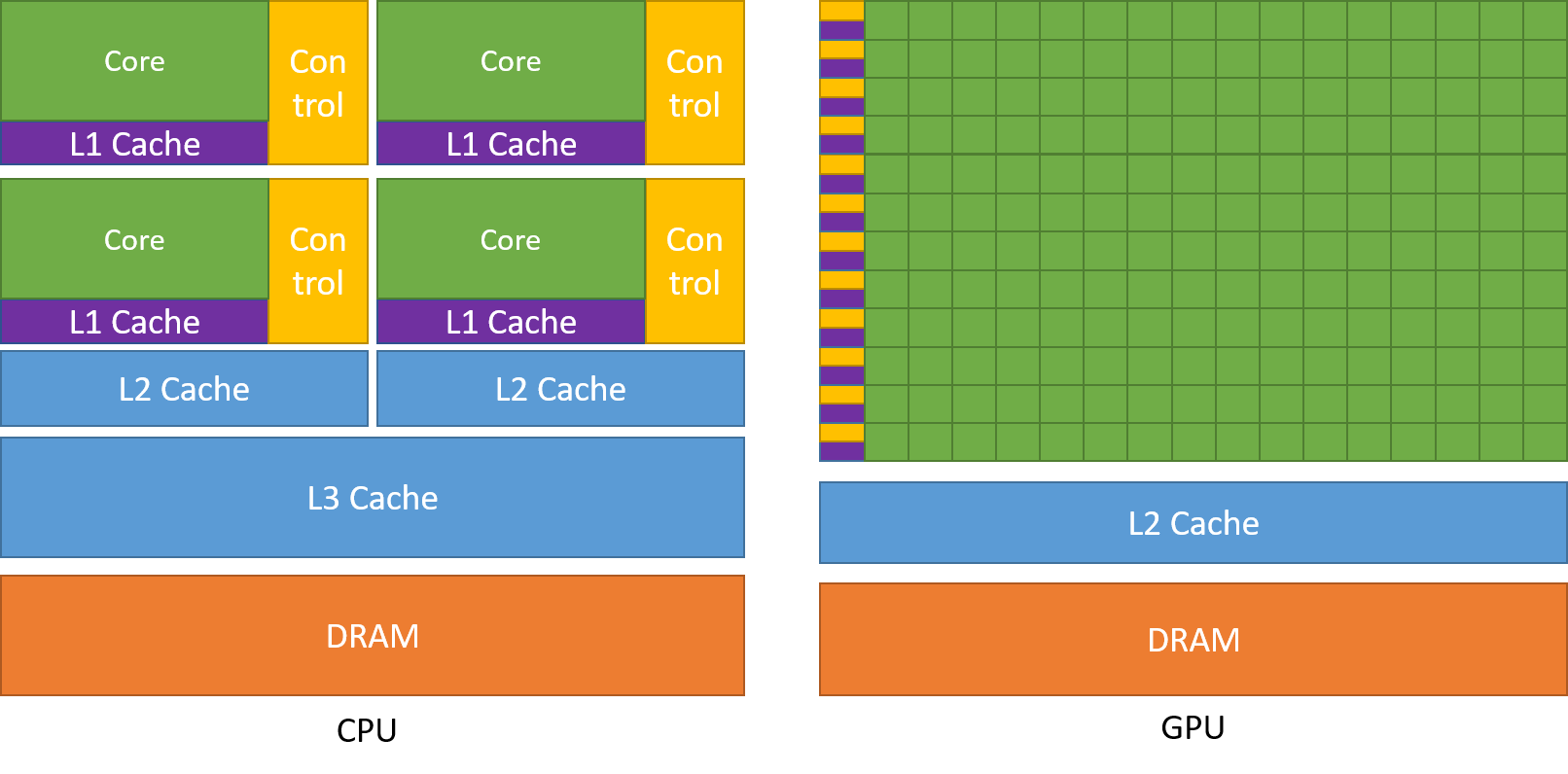
Wie bereits erwähnt, eine CPU ist in mehrere Kerne unterteilt, damit sie gleichzeitig Multitasking ausführen können, während die GPU Hunderte und Tausende von Kernen haben wird, die alle einer einzigen Aufgabe gewidmet sind. Dies sind einfache Berechnungen, die häufiger durchgeführt werden und voneinander unabhängig sind.. Und beide speichern häufig benötigte Daten in ihrem jeweiligen Cache, also nach dem Prinzip von ‘Ortsbezug‘.
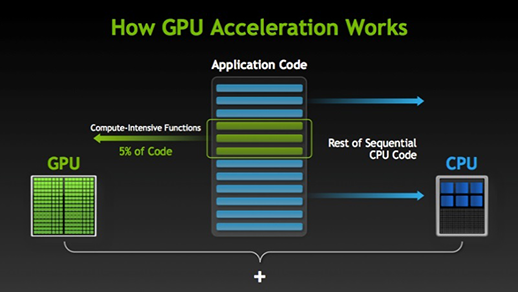
Es gibt viele Programme und Spiele, die GPUs zum Laufen nutzen können. Die Idee dahinter ist, einige Teile des Aufgaben- oder Anwendungscodes parallel zu machen, aber nicht alle Prozesse. Dies liegt daran, dass die meisten Aufgabenprozesse nur sequentiell ausgeführt werden müssen. Zum Beispiel, Die Anmeldung bei einem System oder einer Anwendung muss nicht parallel erfolgen.
Wenn ein Teil der Ausführung parallel durchgeführt werden kann, Zur Verarbeitung einfach auf GPU wechseln, wobei gleichzeitig die sequentielle Task auf der CPU ausgeführt wird, dann werden beide Teile der Aufgabe wieder kombiniert.
Auf dem GPU-Markt, Es gibt zwei Hauptakteure, nämlich, AMD und Nvidia. Nvidia-GPUs werden häufig für Deep Learning verwendet, da sie in der Forensoftware weit verbreitet sind, Controller, CUDA und cuDNN. Dann, in Bezug auf künstliche Intelligenz und Deep Learning, Nvidia ist schon lange Vorreiter.
Neuronale Netze heißen peinlich parallel, wodurch Berechnungen in neuronalen Netzen einfach parallel und unabhängig voneinander ausgeführt werden können.
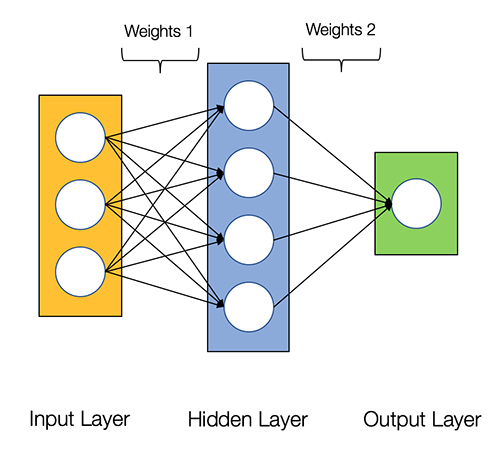
Einige Berechnungen wie die Berechnung von Gewichten und Aktivierungsfunktionen jeder Schicht, Backpropagation kann parallel erfolgen. Auch hierzu gibt es zahlreiche Forschungsartikel..
Nvidia-GPUs werden mit spezialisierten Kernen geliefert, die als . bekannt sind WUNDER Kerne, die Deep Learning beschleunigen.
Was ist CUDA?
CUDA-Significa „Compute Unified Device Architecture“’ die im Jahr auf den Markt kam 2007, Auf diese Weise können Sie paralleles Computing erreichen und das Beste aus Ihrer GPU-Leistung herausholen, was zu einer viel besseren Leistung bei der Ausführung von Aufgaben führt.
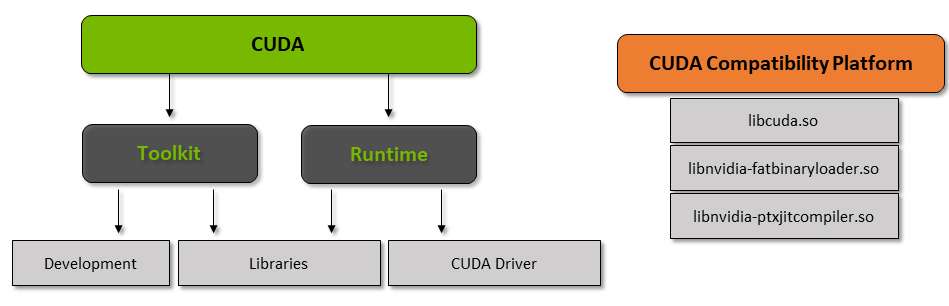
Das CUDA Toolkit ist ein komplettes Paket bestehend aus einer Entwicklungsumgebung, die verwendet wird, um Anwendungen zu erstellen, die GPUs verwenden.. Dieses Toolkit enthält hauptsächlich den Compiler, der Debugger und die C-Bibliotheken / C ++. Was ist mehr, die CUDA-Laufzeit hat ihre Treiber, damit sie mit der GPU kommunizieren kann. CUDA ist auch eine Programmiersprache, die speziell entwickelt wurde, um die GPU anzuweisen, eine Aufgabe auszuführen.. Auch bekannt als GPU-Scheduling.
Unten ist ein einfaches Hello-World-Programm, nur um eine Vorstellung davon zu bekommen, wie der CUDA-Code aussieht.
/* Hallo Weltprogramm in Cuda * #enthalten<stdio.h> #enthalten<stdlib.h> #enthalten<cuda.h>__global__ ungültige Demo() { druckenf("Hallo Welt!,mein erstes cuda-programm"); }int main() { druckenf("Von Haupt!n"); Demo<<<1,1>>>(); Rückkehr 0; }

Was ist cuDNN?

cuDNN ist eine neuronale Netzwerkbibliothek, die GPU-optimiert ist und die Nvidia-GPU voll ausnutzen kann. Diese Bibliothek besteht aus der Faltungsimplementierung, Vorwärts- und Rückwärtsspreizung, Aktivierungs- und Gruppierungsfunktionen. Es ist eine unverzichtbare Bibliothek, ohne die Sie die GPU nicht zum Trainieren neuronaler Netze verwenden können.
Großer Sprung mit Tensor-Kernen!!
Im Jahr 2018, Nvidia hat eine neue Reihe seiner GPUs auf den Markt gebracht, nämlich, die Serie 2000. Auch RTX genannt, Diese Karten werden mit Tensor-Kernen geliefert, die für Deep Learning bestimmt sind und auf der Volta-Architektur basieren.
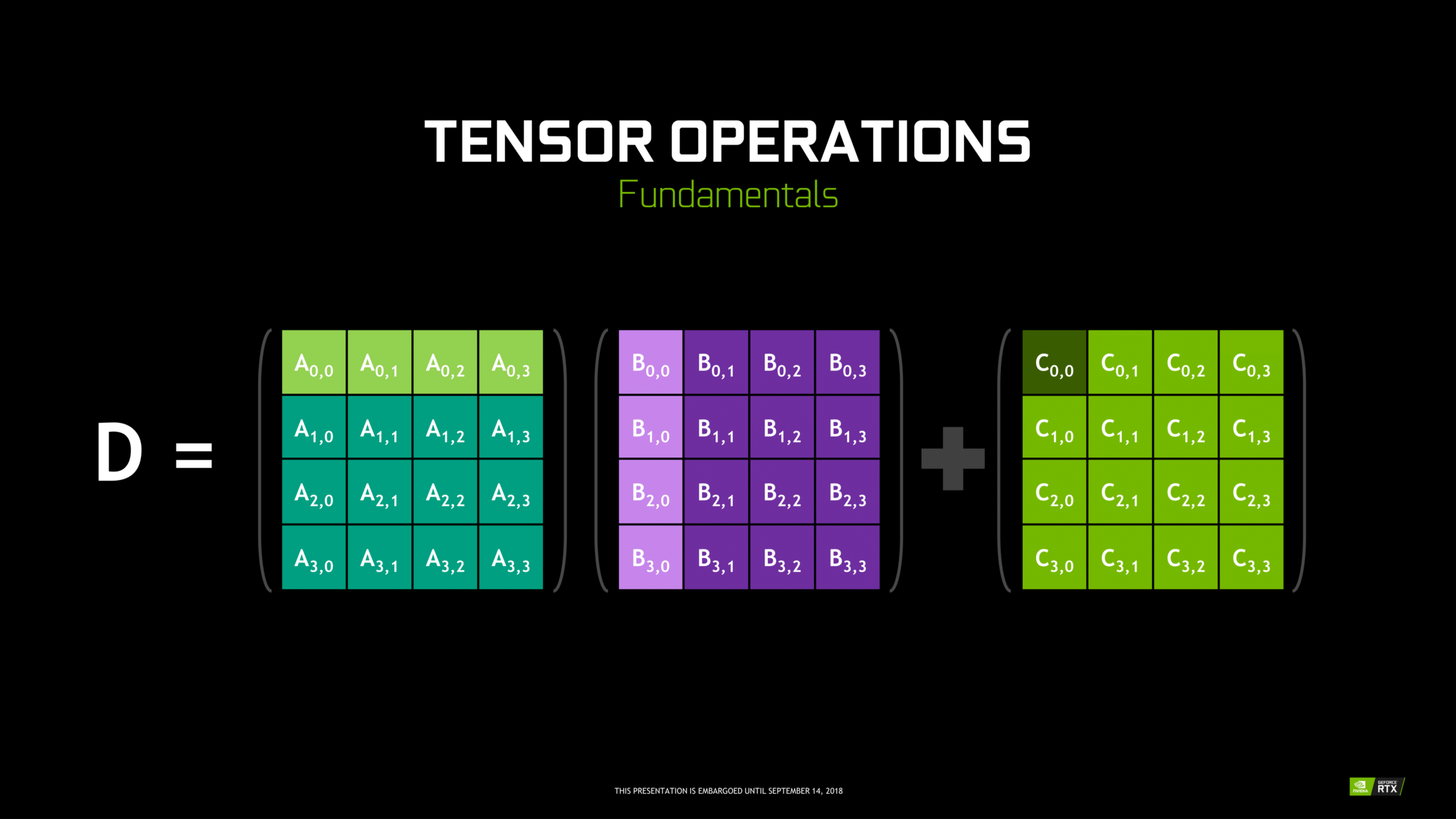
Tensorkerne sind bestimmte Kerne, die eine Matrixmultiplikation durchführen 4 x 4 FP16 und die Summe mit 4 x 4 FP16- oder FP32-Matrix in mittlerer Präzision, die Ausgabe führt zu einem Array 4 x 4 FP16 oder FP32 mit voller Präzision.
Notiz: ‘FP’ bedeutet Gleitkomma, um mehr über Gleitkomma und Genauigkeit zu erfahren, Überprüfen Sie dies Blog.
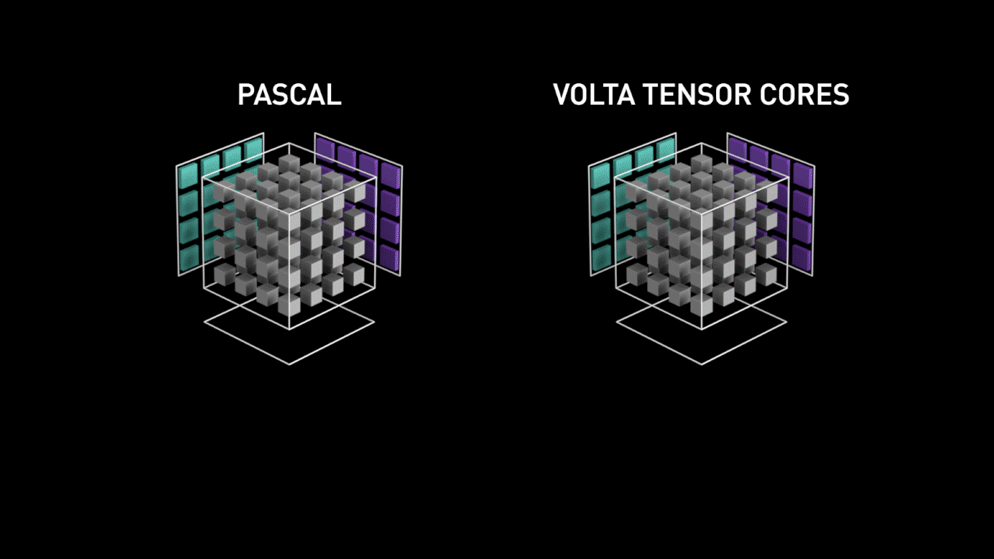
Wie von Nvidia angegeben, Tensor-Kerne der neuen Generation basierend auf der Volta-Architektur sind viel schneller als CUDA-Kerne basierend auf der Pascal-Architektur. Dies hat dem Deep Learning einen enormen Schub gegeben..
Zum Zeitpunkt des Schreibens dieses Blogs, Nvidia hat die neueste Serie angekündigt 3000 seiner GPU-Reihe, die mit Ampere-Architektur ausgestattet ist. In diesem, verbesserte Leistung der Tensorkerne um 2x. Es bringt auch neue Präzisionswerte wie TF32 (Tensor Schwimmer 32), FP64 (Gleitkomma 64). Der TF32 funktioniert genauso wie der FP32, jedoch mit bis zu 20-facher Beschleunigung, infolge all dessen, Nvidia behauptet, dass die Schulungs- oder Inferenzzeit für das Modell von Wochen auf Stunden reduziert wird.
AMD vs. Nvidia

AMD GPUs sind für Spiele anständig, aber sobald Deep Learning einsetzt, einfach Nvidia ist weit voraus. Bedeutet nicht, dass AMD-GPUs schlecht sind. Dies liegt an der Softwareoptimierung und an den Treibern, die nicht aktiv aktualisiert werden, auf der Nvidia-Seite gibt es bessere Treiber mit häufigen Updates und obendrein CUDA, cuDNN hilft, die Berechnung zu beschleunigen.
Einige Bibliotheken, bekannt als Tensorflow, PyTorch-Unterstützung für CUDA. Damit können Einsteiger-GPUs der GTX-Serie verwendet werden 1000. Auf der AMD-Seite, hat sehr wenig Softwareunterstützung für seine GPUs. Auf der Hardwareseite, Nvidia hat dedizierte Spannerkerne eingeführt. AMD hat ROCm zur Beschleunigung, aber nicht gut als Tensorkerne, und viele Deep-Learning-Bibliotheken unterstützen ROCm nicht. In den letzten Jahren, leistungstechnisch war kein großer Sprung zu verzeichnen.
Aufgrund all dieser Punkte, Nvidia zeichnet sich einfach durch Deep Learning aus.
Zusammenfassung
Um aus all dem zu schließen, was wir gelernt haben, es ist klar, dass Nvidia ab sofort Marktführer in Sachen GPU ist, aber ich hoffe sehr, dass auch AMD in Zukunft aufholen oder zumindest einige bemerkenswerte Verbesserungen an der nächsten Reihe ihrer GPUs vornehmen wird.. da sie bereits einen tollen Job in Bezug auf ihre CPUs machen, nämlich, Ryzen-Reihe.
Die Reichweite von GPUs in den kommenden Jahren ist enorm, da wir neue Innovationen und Fortschritte im Bereich Deep Learning machen, maschinelles Lernen und HPC. Die GPU-Beschleunigung wird für viele Entwickler und Studenten immer hilfreich sein, um in dieses Feld einzusteigen, da auch ihre Preise günstiger werden. Auch dank der breiten Community, die auch zur Entwicklung von KI und HPC beiträgt.

Prathmesh Patil
Enthusiast für maschinelles Lernen, Datenwissenschaft, Python-Entwickler.
LinkedIn: https://www.linkedin.com/in/prathmesh





