Dieser Artikel wurde im Rahmen der Data Science Blogathon
Datenvorverarbeitung
Es ist auch ein wichtiger Schritt beim Data Mining, da wir nicht mit Rohdaten arbeiten können. Die Datenqualität sollte überprüft werden, bevor Algorithmen für maschinelles Lernen oder Data Mining angewendet werden.
Warum ist die Datenvorverarbeitung wichtig?
Die Datenvorverarbeitung dient in erster Linie der Überprüfung der Datenqualität. Die Qualität kann wie folgt überprüft werden
- Präzision: Um zu überprüfen, ob die eingegebenen Daten korrekt sind oder nicht.
- Ich vervollständige es: Um zu überprüfen, ob die Daten verfügbar oder nicht aufgezeichnet sind.
- Konsistenz: Um zu überprüfen, ob an allen übereinstimmenden Orten die gleichen Daten gespeichert sind oder nicht.
- Chance: Die Daten müssen korrekt aktualisiert werden.
- Glaubwürdigkeit: Daten müssen zuverlässig sein.
- Interpretierbarkeit: Die Verständlichkeit der Daten.
- Datenbereinigung
- Datenintegration
- Datenreduzierung
- Datentransformation
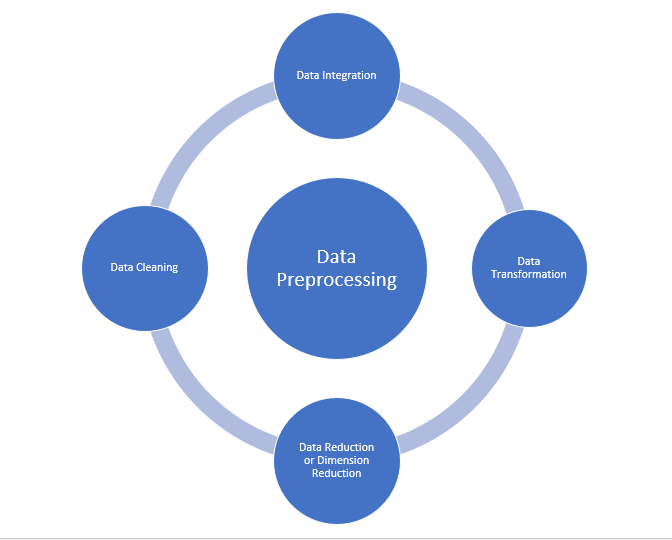
Quelle: medium.com
Datenbereinigung:
Datenbereinigung ist der Prozess der Entfernung fehlerhafter Daten, unvollständige Daten und ungenaue Daten aus Datensätzen, und auch fehlende Werte ersetzen. Es gibt einige Techniken zur Datenbereinigung
Umgang mit fehlenden Werten:
- Sie können Standardwerte verwenden wie „Nicht verfügbar“ Ö „N / A“ fehlende Werte ersetzen.
- Fehlende Werte können auch manuell ausgefüllt werden, aber nicht empfohlen, wenn der Datensatz groß ist.
- Der mittlere Wert des Attributs kann verwendet werden, um den fehlenden Wert zu ersetzen, wenn die Daten normalverteilt sind.
in welchem, im Fall einer Nicht-Normalverteilung, Sie können den Medianwert des Attributs verwenden. - Bei Verwendung von Regressions- oder Entscheidungsbaumalgorithmen, der fehlende Wert kann durch den wahrscheinlichsten Wert ersetzt werden.
Wert.
Ruidoso:
Noisy bedeutet im Allgemeinen zufälliger Fehler oder enthält unnötige Datenpunkte. Hier sind einige der Methoden zum Umgang mit verrauschten Daten.
- Klasseneinteilung: Diese Methode dient zum Glätten oder Bearbeiten von verrauschten Daten. Zuerst, die Daten werden sortiert und dann werden die geordneten Werte getrennt und in Form von Containern gespeichert. Es gibt drei Methoden, um die Containerdaten zu glätten. Glättung nach Bin-Mean-Methode: Bei dieser Methode, die Containerwerte werden durch den Containermittelwert ersetzt; Geglättet durch MedianDer Median ist ein statistisches Maß, das den zentralen Wert eines Satzes geordneter Daten darstellt. Um es zu berechnen, Die Daten werden von der niedrigsten zur höchsten sortiert und die Zahl in der Mitte wird identifiziert. Wenn es eine gerade Anzahl von Beobachtungen gibt, Die beiden Kernwerte werden gemittelt. Dieser Indikator ist besonders nützlich bei asymmetrischen Verteilungen, da es nicht von Extremwerten beeinflusst wird.... Aus dem Papierkorb: Bei dieser Methode, die Containerwerte werden durch den Medianwert ersetzt; Glättung der Behältergrenzen: Bei dieser Methode, die minimalen und maximalen Nutzungswerte werden aus den Standortwerten übernommen und die Werte werden durch den nächsten Grenzwert ersetzt.
- Rückschritt: Es wird verwendet, um die Daten zu glätten und hilft beim Umgang mit den Daten, wenn unnötige Daten vorhanden sind. Zur Analyse, Die Zweckregression hilft bei der Entscheidung, ob VariableIn Statistik und Mathematik, ein "Variable" ist ein Symbol, das einen Wert darstellt, der sich ändern oder variieren kann. Es gibt verschiedene Arten von Variablen, und qualitativ, die nicht-numerische Eigenschaften beschreiben, und quantitative, numerische Größen darstellen. Variablen sind grundlegend in Experimenten und Studien, da sie die Analyse von Beziehungen und Mustern zwischen verschiedenen Elementen ermöglichen, das Verständnis komplexer Phänomene zu erleichtern.... die für unsere Analyse geeignet ist.
- Gruppierung: Wird verwendet, um Ausreißer zu finden und Daten zu gruppieren. Clustering wird im Allgemeinen in der Unüberwachtes LernenUnüberwachtes Lernen ist eine Technik des maschinellen Lernens, die es Modellen ermöglicht, Muster und Strukturen in Daten ohne vordefinierte Beschriftungen zu identifizieren. Durch Algorithmen wie k-means und Hauptkomponentenanalyse, Dieser Ansatz wird in einer Vielzahl von Anwendungen eingesetzt, wie z. B. Kundensegmentierung, Anomalieerkennung und Datenkomprimierung. Seine Fähigkeit, verborgene Informationen preiszugeben, macht es zu einem wertvollen Werkzeug in der....
Datenintegration:
Der Prozess der Kombination mehrerer Quellen in einem einzigen Datensatz. Der Datenintegrationsprozess ist einer der Hauptbestandteile des Datenmanagements. Bei der Datenintegration sind einige Probleme zu beachten.
- Schemaintegration: Metadaten integrieren (ein Datensatz, der andere Daten beschreibt) aus verschiedenen Quellen.
- Problem bei der Identifizierung der Entität: Identifizierung von Entitäten aus mehreren Datenbanken. Zum Beispiel, Das System bzw. die Nutzung muss die studentische _id eines DatenbankEine Datenbank ist ein organisierter Satz von Informationen, mit dem Sie, Effizientes Verwalten und Abrufen von Daten. Einsatz in verschiedenen Anwendungen, Von Unternehmenssystemen bis hin zu Online-Plattformen, Datenbanken können relational oder nicht-relational sein. Das richtige Design ist entscheidend für die Optimierung der Leistung und die Gewährleistung der Informationsintegrität, und erleichtert so eine fundierte Entscheidungsfindung in verschiedenen Kontexten.... und der Name des Schülers aus einer anderen Datenbank gehört zur gleichen Entität.
- Datenwertkonzepte erkennen und lösen: Daten, die während der Zusammenführung aus verschiedenen Datenbanken entnommen wurden, können sich unterscheiden. Wie sich Attributwerte in einer Datenbank von einer anderen Datenbank unterscheiden können. Zum Beispiel, das Datumsformat kann abweichen, da „MM / DD / YYYY“ Ö „DD / MM / YYYY“.
Datenreduzierung:
Dieser Prozess hilft, das Datenvolumen zu reduzieren, was die Analyse erleichtert und zum gleichen oder fast zum gleichen Ergebnis führt. Diese Reduzierung trägt auch dazu bei, den Speicherplatz zu reduzieren.. Einige der Techniken bei der Datenreduktion sind Dimensionalitätsreduktion, Zahlenreduktion, Datenkompression.
- Dimensionsreduktion: Dieser Prozess ist für reale Anwendungen notwendig, da die Datengröße groß ist. In diesem Prozess, die Reduktion von Attributen oder Zufallsvariablen erfolgt so, dass die Dimensionalität des Datensatzes reduziert werden kann. Kombinieren und fügen Sie die Attribute der Daten zusammen, ohne ihre ursprünglichen Eigenschaften zu verlieren. Dies hilft auch, Speicherplatz und Rechenzeit zu reduzieren.. Wenn Daten sehr dimensional sind, das Problem nannte sich „Der Fluch der Dimensionalität“.
- Reduzierung der Anzahl: Bei dieser Methode, Die Datendarstellung wird kleiner, wenn das Volumen reduziert wird. Bei dieser Reduzierung gibt es keinen Datenverlust.
- Datenkompression: Die komprimierte Form der Daten wird als Datenkompression bezeichnet. Diese Komprimierung kann verlustfrei oder verlustbehaftet sein. Wenn während der Komprimierung kein Informationsverlust auftritt, heißt verlustfreie Komprimierung. Während verlustbehaftete Komprimierung Informationen reduziert, aber es entfernt nur die unnötigen Informationen.
Datentransformation:
Die Änderung des Formats oder der Struktur der Daten wird als Datentransformation bezeichnet. Dieser Schritt kann je nach Anforderung einfach oder komplex sein. Es gibt einige Methoden bei der Datentransformation.
- Glätten: Mit Hilfe von Algorithmen, Wir können das Rauschen aus dem Datensatz entfernen und helfen, die wichtigen Eigenschaften des Datensatzes zu kennen. Durch Glätten können wir sogar eine einfache Änderung finden, die bei der Vorhersage hilft.
- Anhäufung: Bei dieser Methode, Daten werden gespeichert und in zusammenfassender Form dargestellt. Der aus mehreren Quellen stammende Datensatz wird in die Beschreibung der Datenanalyse integriert. Dies ist ein wichtiger Schritt, da die Genauigkeit der Daten von der Quantität und Qualität der Daten abhängt.. Wenn Qualität und Quantität der Daten stimmen, die Ergebnisse sind relevanter.
- Diskretisierung: Kontinuierliche Daten sind hier in Intervalle unterteilt. Diskretisierung reduziert die Datengröße. Zum Beispiel, anstatt die Unterrichtszeit anzugeben, Wir können ein Intervall festlegen wie (3 Uhr-17 Uhr, 6 Uhr-20 Uhr).
- NormalisierungNormung ist ein grundlegender Prozess in verschiedenen Disziplinen, , die darauf abzielt, einheitliche Standards und Kriterien zur Verbesserung von Qualität und Effizienz festzulegen. In Kontexten wie dem Ingenieurwesen, Bildung und Verwaltung, Standardisierung erleichtert den Vergleich, Interoperabilität und gegenseitiges Verständnis. Bei der Implementierung von Standards, Der Zusammenhalt wird gefördert und die Ressourcen werden optimiert, die zu einer nachhaltigen Entwicklung und zur kontinuierlichen Verbesserung der Prozesse beiträgt....: Es ist die Methode zum Skalieren der Daten, damit sie in einem kleineren Bereich dargestellt werden können. Beispiel, das von geht -1.0 ein 1.0.
Schritte zur Datenvorverarbeitung beim maschinellen Lernen
Bibliotheken und den Datensatz importieren
import pandas as pd
import numpy as np
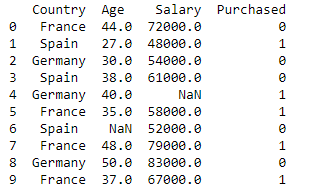
dataset = pd.read_csv('Datensätze.csv')
drucken (data_set)
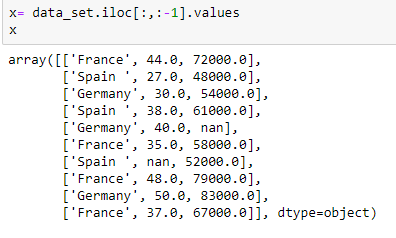
Extrahieren unabhängiger Variablen:
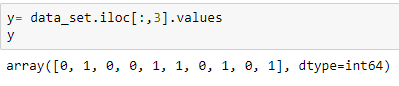
Extrahieren der abhängigen Variablen:
Füllen Sie den Datensatz mit dem Mittelwert des Attributs
aus sklearn.preprocessing import Imputer anrechnen = anrechnen(fehlende_Werte="NaN", Strategie = 'gemein', Achse = 0) imputerimputer = imputer.fit(x[:, 1:3]) x[:, 1:3]= imputer.transform(x[:, 1:3]) x
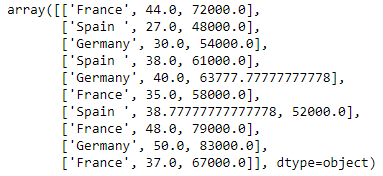
Codierung der Ländervariablen
Modelle für maschinelles Lernen verwenden mathematische Gleichungen. Dann, kategoriale Daten werden nicht akzeptiert, also wandeln wir sie in numerische Form um.
aus sklearn.preprocessing import LabelEncoder label_encoder_x= LabelEncoder() x[:, 0]= label_encoder_x.fit_transform(x[:, 0])
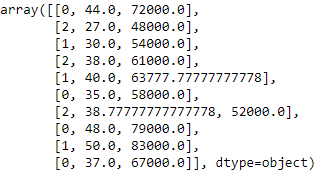
Dummy-Codierung
Diese Dummy-Variablen ersetzen kategoriale Daten wie 0 Ja 1 beim Fehlen oder Vorhandensein spezifischer kategorialer Daten.
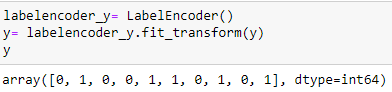
Codierung der gekauften Variablen
labelencoder_y= LabelEncoder() y= labelencoder_y.fit_transform(Ja)
Teilen Sie das Dataset in eine Gruppe von AusbildungTraining ist ein systematischer Prozess zur Verbesserung der Fähigkeiten, körperliche Kenntnisse oder Fähigkeiten. Es wird in verschiedenen Bereichen angewendet, wie Sport, Aus- und Weiterbildung. Zu einem effektiven Trainingsprogramm gehört auch die Zielplanung, Regelmäßiges Üben und Bewerten der Fortschritte. Anpassung an individuelle Bedürfnisse und Motivation sind Schlüsselfaktoren, um in jeder Disziplin erfolgreiche und nachhaltige Ergebnisse zu erzielen.... und testen:
aus sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split(x, Ja, test_size= 0.2, random_state=0)
Funktionsskala
aus sklearn.preprocessing importieren StandardScaler
st_x= StandardSkalierer() x_train= st_x.fit_transform(x_train)

x_test= st_x.transform(x_test)
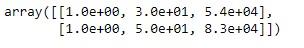
Fazit:
In diesem Artikel, Ich habe den wichtigsten Schritt beim maschinellen Lernen erklärt, die Datenvorverarbeitung. Ich hoffe, dieser Artikel hilft Ihnen, das Konzept besser zu verstehen.
Referenz:
https://www.javatpoint.com/data-preprocessing-machine-learning
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von DataPeaker und werden nach Ermessen des Autors verwendet.





