Dieser Artikel wurde im Rahmen der Data Science Blogathon
Hallo Leute! In diesem Blog, Ich werde alles über die Bildklassifizierung besprechen.
In den vergangenen Jahren, Deep Learning hat sich aufgrund seiner Fähigkeit, große Datenmengen zu verarbeiten, als sehr leistungsfähiges Werkzeug erwiesen. Die Verwendung versteckter Schichten geht über traditionelle Techniken hinaus, speziell zur Mustererkennung. Eines der beliebtesten tiefen neuronalen Netze sind konvolutionelle neuronale Netze (CNN).
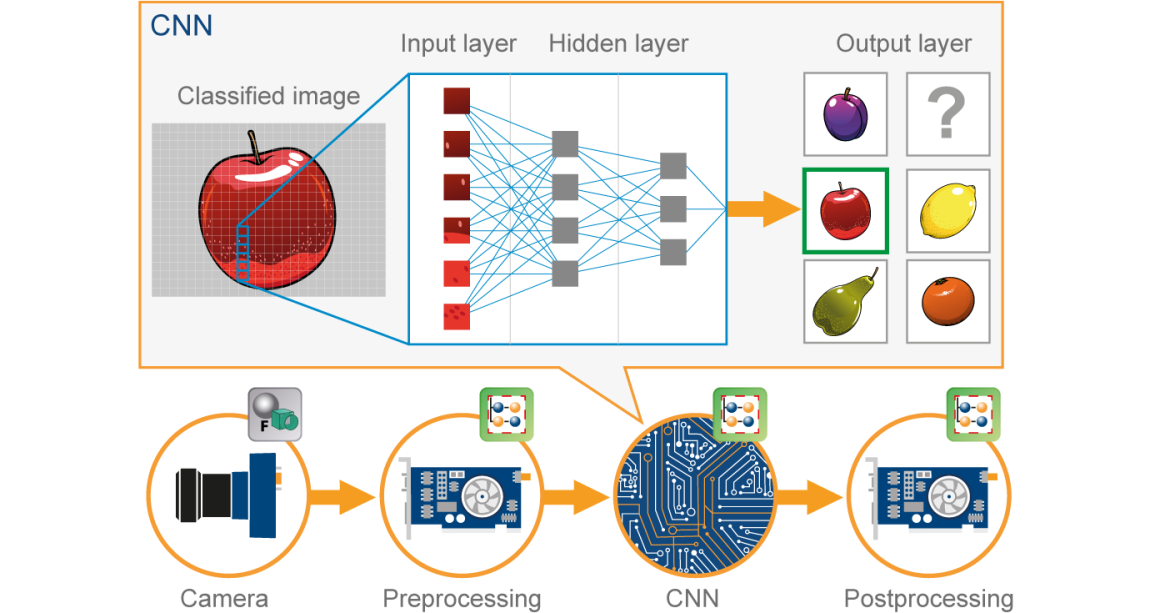
Ein konvolutionelles neuronales Netzwerk (CNN) es ist eine Art Rote neuronale künstliche (ANN) verwendet in der Bilderkennung und -verarbeitung, die speziell auf die Verarbeitung von Daten ausgelegt ist (Pixel).
Bildquelle: Google.com
Bevor es weitergeht, wir müssen verstehen, was das neuronale Netz ist. Lass uns gehen…
Rotes Neuron:
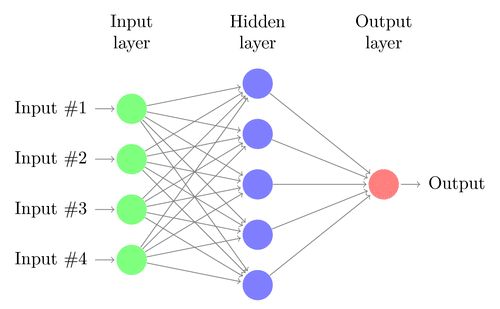
Ein neuronales Netz besteht aus mehreren miteinander verbundenen Knoten, genannt “Neuronen”. Neuronen sind angeordnet in Eingabeschicht, versteckte Schicht und Ausgabeschicht. Die Eingabeschicht entspricht unseren Prädiktoren / Eigenschaften und die Ausgabeschicht zu unseren Antwortvariablen.
Bildquelle: Google.com
Mehrschichtiges Perzeptron (MLP):
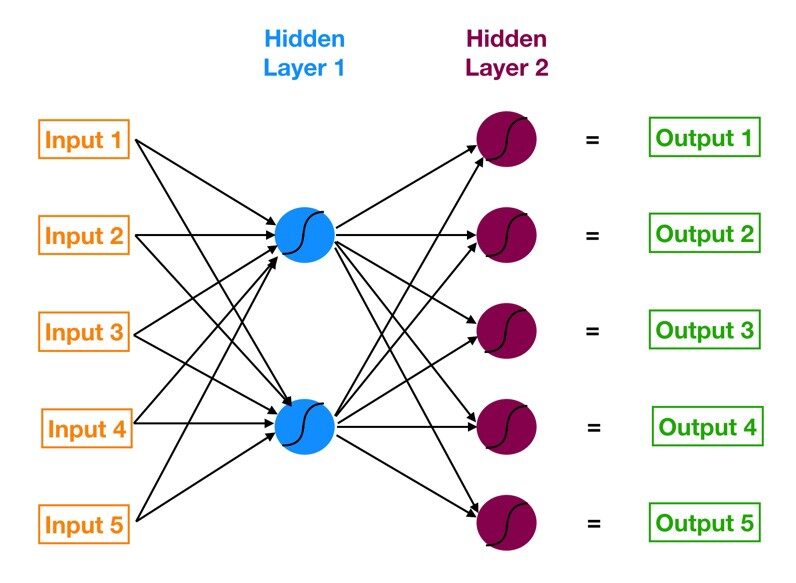
Das neuronale Netz mit einer Eingabeschicht, eine oder mehrere versteckte Schichten und eine Ausgabeschicht wird aufgerufen mehrschichtiges Perzeptron (MLP). MLP wird erfunden von Frank Rosenblatt Im Jahr von 1957. Das unten gezeigte MLP hat 5 Eingabeknoten, 5 Hidden Nodes mit zwei Hidden Layern und einem Exit Node
Bildquelle: Google.com
Wie funktioniert dieses neuronale Netz?
– Die Neuronen der Eingabeschicht erhalten eingehende Informationen aus den Daten, die sie verarbeiten und an die versteckte Schichten.
– Diese Informationen, zur selben Zeit, wird von versteckten Layern verarbeitet und an die Ausgabe übergeben. Neuronen.
– Die Informationen aus diesem künstlichen neuronalen Netz (ANN) wird im Sinne von a . verarbeitet Weckfunktion. Diese Funktion ahmt tatsächlich Neuronen im Gehirn nach.
– Jedes Neuron enthält einen Wert von Triggerfunktionen und ein Schwellwert.
– Das Schwellwert ist der Mindestwert, den der Eingang haben muss, damit er aktiviert wird.
– Die Aufgabe des Neurons besteht darin, eine gewichtete Summe aller Eingangssignale durchzuführen und die Aktivierungsfunktion auf die Summe anzuwenden, bevor sie an die nächste Schicht übergeben wird. (versteckt oder verlassen).
Lassen Sie uns verstehen, was die Gewichtungssumme ist.
Nehmen wir an, wir haben Werte 𝑎1, 𝑎2, 3, 𝑎4 für Eingabe und Gewichte als 𝑤1, 𝑤2, 3, 𝑤4 als Eingabe für eines der Neuronen der versteckten Schicht, sagen wir, dann wird die gewichtete Summe dargestellt als
𝑆𝑗 = σ 𝑖 = 1bis4 𝑤𝑖 * ai + 𝑏𝑗
wo: Verzerrung durch Knoten
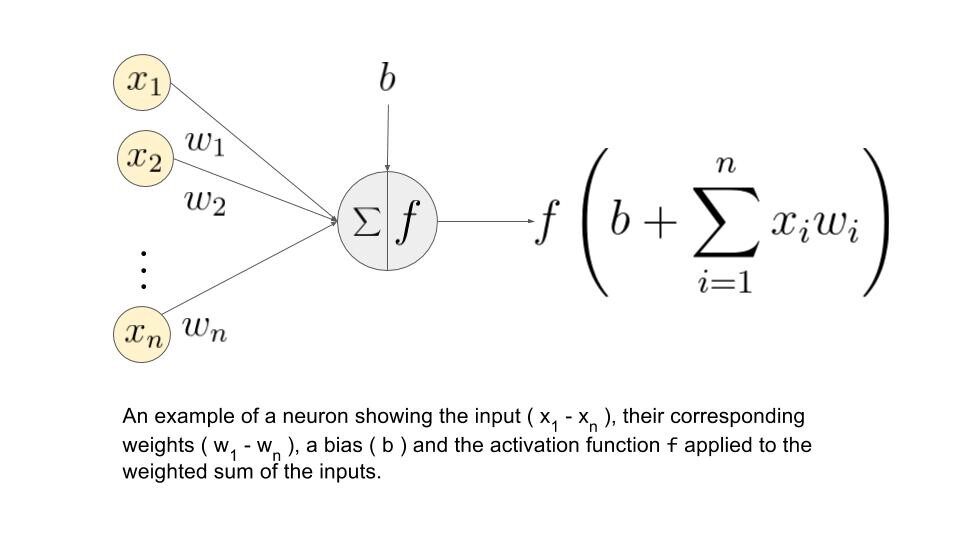
Bildquelle: Google.com
Was sind die Aktivierungsfunktionen?
Diese Funktionen sind notwendig, um eine Nichtlinearität in das Netzwerk einzuführen. Die Triggerfunktion wird angewendet und diese Ausgabe wird an die nächste Schicht übergeben.
* Mögliche Funktionen *
• Sigmoide: Sigmoidfunktion ist differenzierbar. Erzeugt eine Ausgabe zwischen 0 Ja 1.
• Hyperbolischer Tangens: Der hyperbolische Tangens ist auch differenzierbar. Dies erzeugt eine Ausgabe zwischen -1 Ja 1.
• ReLU: ReLU ist die beliebteste Funktion. ReLU wird häufig im Deep Learning verwendet.
• Softmax: Die Softmax-Funktion wird für Klassifikationsprobleme mit mehreren Klassen verwendet. Es ist eine Verallgemeinerung der Sigmoidfunktion. Es erzeugt auch eine Ausgabe zwischen 0 Ja 1
Jetzt, Los geht's mit unserem CNN-Thema …
CNN:
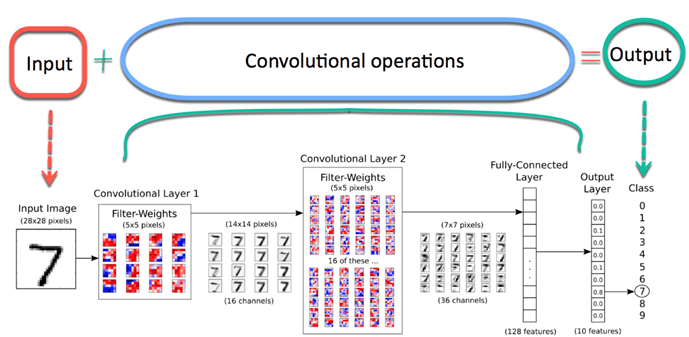
Stellen Sie sich nun vor, es gibt ein Bild von einem Vogel, und du willst es identifizieren, ob es wirklich ein Vogel oder etwas anderes ist. Als erstes müssen Sie die Bildpixel in Form von Arrays in die Eingabeschicht des neuronalen Netzes einspeisen (MLP-Netzwerke werden verwendet, um solche Dinge zu klassifizieren). Ausgeblendete Layer tragen Feature-Extraktion durch Ausführen verschiedener Berechnungen und Operationen. Es gibt mehrere versteckte Schichten wie Faltung, die ReLU und die Gruppierungsebene, die die Merkmalsextraktion aus Ihrem Bild durchführt. Dann, Schließlich, es gibt eine vollständig verbundene Ebene, die Sie sehen können, die das genaue Objekt im Bild identifiziert. Sie können sehr leicht aus der folgenden Abbildung verstehen:
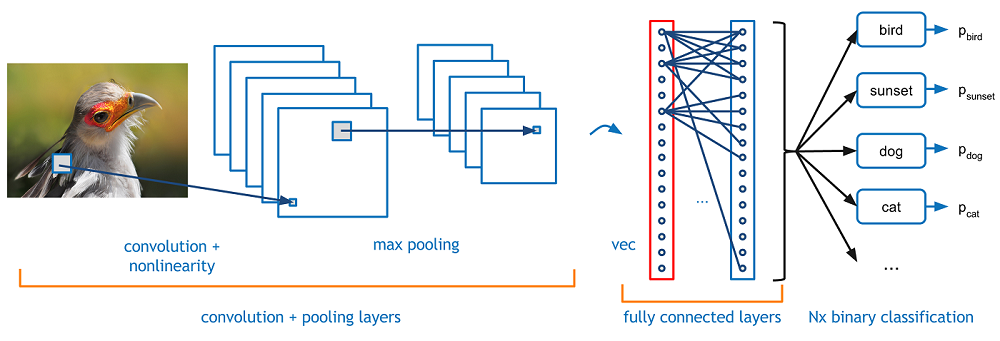
Bildquelle: Google.com
Faltung:-
Die Faltungsoperation beinhaltet Matrixarithmetikoperationen und jedes Bild wird als ein Array von Werten dargestellt (Pixel).
Lass uns das Beispiel verstehen:
a = [2,5,8,4,7,9]
b = [1,2,3]
In der Faltungsoperation, Matrizen werden eins zu eins in Bezug auf die Elemente multipliziert, und das Produkt wird gruppiert oder summiert, um eine neue Matrix zu erstellen, die darstellt ein * B.
Die ersten drei Elemente des Arrays ein jetzt mit den Elementen des Arrays multiplizieren B. Das Produkt wird addiert, um das Ergebnis zu erhalten und wird in einer neuen Matrix von gespeichert ein * B.
Dieser Vorgang bleibt kontinuierlich, bis der Vorgang abgeschlossen ist..
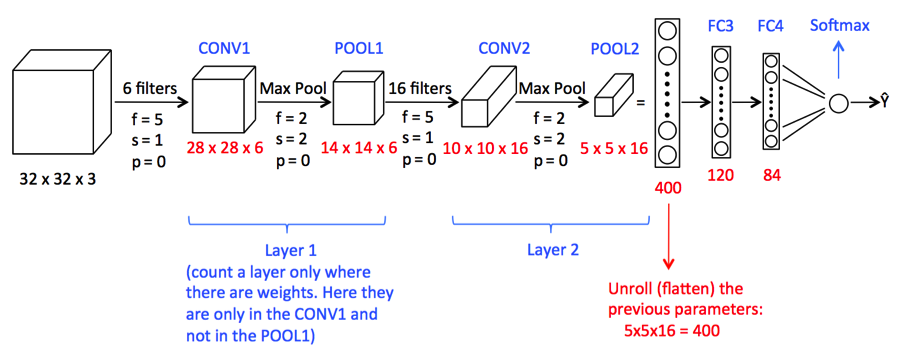
Bildquelle: Google.com
Gruppierung:
Nach der Faltung, es gibt eine andere Operation namens Gruppierung. Dann, In der Kette, Faltung und Gruppierung werden sequentiell auf die Daten angewendet, um einige Merkmale aus den Daten zu extrahieren. Nach sequentiellen Cluster- und Faltungsschichten, Daten werden abgeflacht
in einem rückgekoppelten neuronalen Netz, das auch als mehrschichtiges Perzeptron bezeichnet wird.
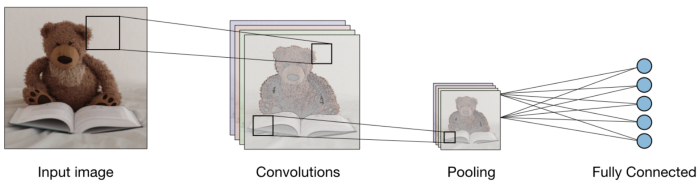
Bildquelle: Google.com
Bisher, Wir haben Konzepte gesehen, die für unser CNN-Gebäudemodell wichtig sind.
Jetzt werden wir weitermachen, um eine CNN-Fallstudie zu sehen.
1) Hier importieren wir die notwendigen Bibliotheken, die zum Ausführen von CNN-Aufgaben erforderlich sind..
import NumPy as np
%matplotlib inline
import matplotlib.image as mpimg
import matplotlib.pyplot as plt
import TensorFlow as tf
tf.compat.v1.set_random_seed(2019)
2) Hier benötigen wir den folgenden Code, um das CNN-Modell zu bilden
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(16,(3,3),Aktivierung = "Lebenslauf" , input_shape = (180,180,3)) ,
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(32,(3,3),Aktivierung = "Lebenslauf") ,
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(64,(3,3),Aktivierung = "Lebenslauf") ,
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(128,(3,3),Aktivierung = "Lebenslauf"),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Flatten(),
tf.harte.Schichten.Dense(550,Aktivierung="Lebenslauf"), #Adding the Hidden layer
tf.keras.layers.Dropout(0.1,Samen = 2019),
tf.harte.Schichten.Dense(400,Aktivierung ="Lebenslauf"),
tf.keras.layers.Dropout(0.3,Samen = 2019),
tf.harte.Schichten.Dense(300,Aktivierung="Lebenslauf"),
tf.keras.layers.Dropout(0.4,Samen = 2019),
tf.harte.Schichten.Dense(200,Aktivierung ="Lebenslauf"),
tf.keras.layers.Dropout(0.2,Samen = 2019),
tf.harte.Schichten.Dense(5,Aktivierung = "softmax") #Hinzufügen der Ausgabeebene
])
Ein verworrenes Bild kann zu groß sein und, Daher, Schrumpft ohne Verlust von Features oder Mustern, Die Gruppierung ist also erledigt.
Hier, Um ein neuronales Netzwerk zu erstellen, wird das Netzwerk mit dem sequenziellen Keras-Modell initialisiert.
Abflachen (): Durch das Reduzieren wird ein zweidimensionales Array von Features in einen Vektor von Features umgewandelt..
3) Schauen wir uns nun eine Zusammenfassung des CNN-Modells an
Modell.Zusammenfassung()
Sie drucken die folgende Ausgabe
Modell: "sequenziell" ________________________________________________________________________________ Schicht (Typ) Parameter der Ausgabeform # ================================================================= conv2d (Conv2D) (Keiner, 178, 178, 16) 448 _________________________________________________________________ max_pooling2d (MaxPooling2D) (Keiner, 89, 89, 16) 0 _________________________________________________________________ conv2d_1 (Conv2D) (Keiner, 87, 87, 32) 4640 _________________________________________________________________ max_pooling2d_1 (MaxPooling2 (Keiner, 43, 43, 32) 0 _________________________________________________________________ conv2d_2 (Conv2D) (Keiner, 41, 41, 64) 18496 _________________________________________________________________ max_pooling2d_2 (MaxPooling2 (Keiner, 20, 20, 64) 0 _________________________________________________________________ conv2d_3 (Conv2D) (Keiner, 18, 18, 128) 73856 _________________________________________________________________ max_pooling2d_3 (MaxPooling2 (Keiner, 9, 9, 128) 0 _________________________________________________________________ flatten (Ebnen) (Keiner, 10368) 0 _________________________________________________________________ dense (Dicht) (Keiner, 550) 5702950 _________________________________________________________________ dropout (Aussteigen) (Keiner, 550) 0 _________________________________________________________________ dense_1 (Dicht) (Keiner, 400) 220400 ________________________________________________________________________________ dropout_1 (Aussteigen) (Keiner, 400) 0 ________________________________________________________________________________ dicht_2 (Dicht) (Keiner, 300) 120300 _________________________________________________________________ dropout_2 (Aussteigen) (Keiner, 300) 0 ________________________________________________________________________________ dicht_3 (Dicht) (Keiner, 200) 60200 _________________________________________________________________ dropout_3 (Aussteigen) (Keiner, 200) 0 _________________________________________________________________ dense_4 (Dicht) (Keiner, 5) 1005 ================================================ =============== Gesamtparameter: 6,202,295 Trainierbare Parameter: 6,202,295 Nicht trainierbare Parameter: 0
4) Jetzt sind wir verpflichtet, Optimierer anzugeben.
Importieren Sie RMSprop von tensorflow.keras.optimizers,SGD,Adam
adam=Adam(lr=0,001)
model.compile(Optimierer="Adam", Verlust="kategoriale_Kreuzentropie", Metriken = ['bezüglich'])
Der Optimierer wird verwendet, um die berechneten Kosten pro Kreuzentropie zu reduzieren
Die Verlustfunktion wird verwendet, um den Fehler zu berechnen.
Der Begriff Metriken wird verwendet, um die Effizienz des Modells darzustellen.
5) In diesem Schritt, Wir werden sehen, wie Sie das Datenverzeichnis konfigurieren und Bilddaten generieren.
bs=30 #Setting batch size train_dir = "D:/Data Science/Bilddatensätze/FastFood/Zug/" #Setting training directory validation_dir = "D:/Data Science/Bilddatensätze/FastFood/Test/" #Setting testing directory from tensorflow.keras.preprocessing.image import ImageDataGenerator # Alle Bilder werden neu skaliert von 1./255. train_datagen = ImageDataGenerator( neu skalieren = 1.0/255. ) test_datagen = ImageDataGenerator( neu skalieren = 1.0/255. ) # Flow-Trainingsbilder in Stapeln von 20 using train_datagen generator #Flow_from_directory function lets the classifier directly identify the labels from the name of the directories the image lies in train_generator=train_datagen.flow_from_directory(train_dir,batch_size=bs,class_mode="kategorisch",target_size=(180,180)) # Flow-Validierungsbilder in Stapeln von 20 using test_datagen generator validation_generator = test_datagen.flow_from_directory(validation_dir, batch_size=bs, class_mode="kategorisch", target_size=(180,180))
La salida será:
Gefunden 1465 Bilder, die zu 5 Klassen. Gefunden 893 Bilder, die zu 5 Klassen.
6) Paso final del modelo de ajuste.
Geschichte = model.fit(train_generator,
validation_data=validation_generator,
steps_per_epoch=150 // Bs,
Epochen=30,
validation_steps=50 // Bs,
ausführlich=2)
La salida será:
Epoche 1/30 5/5 - 4S - Verlust: 0.8625 - acc: 0.6933 - Wertverlust: 1.1741 - val_acc: 0.5000 Epoche 2/30 5/5 - 3S - Verlust: 0.7539 - acc: 0.7467 - Wertverlust: 1.2036 - val_acc: 0.5333 Epoche 3/30 5/5 - 3S - Verlust: 0.7829 - acc: 0.7400 - Wertverlust: 1.2483 - val_acc: 0.5667 Epoche 4/30 5/5 - 3S - Verlust: 0.6823 - acc: 0.7867 - Wertverlust: 1.3290 - val_acc: 0.4333 Epoche 5/30 5/5 - 3S - Verlust: 0.6892 - acc: 0.7800 - Wertverlust: 1.6482 - val_acc: 0.4333 Epoche 6/30 5/5 - 3S - Verlust: 0.7903 - acc: 0.7467 - Wertverlust: 1.0440 - val_acc: 0.6333 Epoche 7/30 5/5 - 3S - Verlust: 0.5731 - acc: 0.8267 - Wertverlust: 1.5226 - val_acc: 0.5000 Epoche 8/30 5/5 - 3S - Verlust: 0.5949 - acc: 0.8333 - Wertverlust: 0.9984 - val_acc: 0.6667 Epoche 9/30 5/5 - 3S - Verlust: 0.6162 - acc: 0.8069 - Wertverlust: 1.1490 - val_acc: 0.5667 Epoche 10/30 5/5 - 3S - Verlust: 0.7509 - acc: 0.7600 - Wertverlust: 1.3168 - val_acc: 0.5000 Epoche 11/30 5/5 - 4S - Verlust: 0.6180 - acc: 0.7862 - Wertverlust: 1.1918 - val_acc: 0.7000 Epoche 12/30 5/5 - 3S - Verlust: 0.4936 - acc: 0.8467 - Wertverlust: 1.0488 - val_acc: 0.6333 Epoche 13/30 5/5 - 3S - Verlust: 0.4290 - acc: 0.8400 - Wertverlust: 0.9400 - val_acc: 0.6667 Epoche 14/30 5/5 - 3S - Verlust: 0.4205 - acc: 0.8533 - Wertverlust: 1.0716 - val_acc: 0.7000 Epoche 15/30 5/5 - 4S - Verlust: 0.5750 - acc: 0.8067 - Wertverlust: 1.2055 - val_acc: 0.6000 Epoche 16/30 5/5 - 4S - Verlust: 0.4080 - acc: 0.8533 - Wertverlust: 1.5014 - val_acc: 0.6667 Epoche 17/30 5/5 - 3S - Verlust: 0.3686 - acc: 0.8467 - Wertverlust: 1.0441 - val_acc: 0.5667 Epoche 18/30 5/5 - 3S - Verlust: 0.5474 - acc: 0.8067 - Wertverlust: 0.9662 - val_acc: 0.7333 Epoche 19/30 5/5 - 3S - Verlust: 0.5646 - acc: 0.8138 - Wertverlust: 0.9151 - val_acc: 0.7000 Epoche 20/30 5/5 - 4S - Verlust: 0.3579 - acc: 0.8800 - Wertverlust: 1.4184 - val_acc: 0.5667 Epoche 21/30 5/5 - 3S - Verlust: 0.3714 - acc: 0.8800 - Wertverlust: 2.0762 - val_acc: 0.6333 Epoche 22/30 5/5 - 3S - Verlust: 0.3654 - acc: 0.8933 - Wertverlust: 1.8273 - val_acc: 0.5667 Epoche 23/30 5/5 - 3S - Verlust: 0.3845 - acc: 0.8933 - Wertverlust: 1.0199 - val_acc: 0.7333 Epoche 24/30 5/5 - 3S - Verlust: 0.3356 - acc: 0.9000 - Wertverlust: 0.5168 - val_acc: 0.8333 Epoche 25/30 5/5 - 3S - Verlust: 0.3612 - acc: 0.8667 - Wertverlust: 1.7924 - val_acc: 0.5667 Epoche 26/30 5/5 - 3S - Verlust: 0.3075 - acc: 0.8867 - Wertverlust: 1.0720 - val_acc: 0.6667 Epoche 27/30 5/5 - 3S - Verlust: 0.2820 - acc: 0.9400 - Wertverlust: 2.2798 - val_acc: 0.5667 Epoche 28/30 5/5 - 3S - Verlust: 0.3606 - acc: 0.8621 - Wertverlust: 1.2423 - val_acc: 0.8000 Epoche 29/30 5/5 - 3S - Verlust: 0.2630 - acc: 0.9000 - Wertverlust: 1.4235 - val_acc: 0.6333 Epoche 30/30 5/5 - 3S - Verlust: 0.3790 - acc: 0.9000 - Wertverlust: 0.6173 - val_acc: 0.8000
La función anterior entrena la red neuronal utilizando el conjunto de entrenamiento y evalúa su rendimiento en el conjunto de prueba. Las funciones devuelven dos métricas para cada época 'acc’ y 'val_acc’ das sind die Genauigkeit der im Trainingssatz erhaltenen Vorhersagen und die im Testsatz erreichte Genauigkeit, beziehungsweise.
Fazit:
Deswegen, wir sehen, dass es mit ausreichender Genauigkeit getroffen wurde. Aber trotzdem, Jeder kann dieses Modell ausführen, indem er die Anzahl der Epochen oder einen anderen Parameter erhöht.
Ich hoffe dir hat mein Artikel gefallen. Teile mit deinen Freunden, Kollegen.
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von DataPeaker und werden nach Ermessen des Autors verwendet.





