Einführung
Hatten Sie jemals Mühe, Ihren Rang bei einem Hackathon für maschinelles Lernen in . zu verbessern? DataHack o Kaggle? Du hast alle deine Lieblingstricks und -techniken ausprobiert, aber deine Punktzahl lässt sich nicht ändern. Ich war dort und es ist eine ziemlich frustrierende Erfahrung!
Dies ist besonders während Ihrer ersten Tage in diesem Bereich relevant.. Wir neigen dazu, vertraute Techniken zu verwenden, die wir gelernt haben, wie lineare Regression, logistische Regression, etc. (je nach Problemstellung).
Und dann kommt Bootstrap Sampling. Es ist ein starkes Konzept, das meinen Rang in die oberen Ränge dieser Hackathon-Bestenlisten befördert hat.. Und es war eine ziemliche Lernerfahrung!!

Bootstrap-Sampling ist eine Technik, die mir wie jedem Datenwissenschaftler vorkommt, anstrebend oder etabliert, Du musst lernen.
Dann, In diesem Artikel, wir erfahren alles, was Sie über Boot-Sampling wissen müssen. Was ist es, weil es notwendig ist, wie es funktioniert und wo es in das Bild des maschinellen Lernens passt. Wir werden auch Bootstrap-Sampling in Python implementieren.
Was ist Bootstrap-Sampling??
Hier ist eine formale Definition von Bootstrap Sampling:
In der Statistik, Bootstrap Sampling ist eine Methode, bei der Stichprobendaten wiederholt extrahiert werden, wobei eine Datenquelle ersetzt wird, um einen Populationsparameter zu schätzen.
Warten, das ist zu komplex. Lassen Sie uns die Schlüsselbegriffe analysieren und verstehen:
- Probenahme: Bezüglich Statistik, Sampling ist der Prozess der Auswahl einer Teilmenge von Elementen aus einer breiten Sammlung von Elementen (Population) ein bestimmtes Merkmal der Gesamtbevölkerung schätzen.
- Probenahme mit Ersatz: Das bedeutet, dass ein Datenpunkt in einer gezogenen Stichprobe auch in zukünftigen gezogenen Stichproben wieder auftauchen kann.
- Parameter Schätzung: Es ist eine Methode zur Schätzung von Parametern für die Grundgesamtheit unter Verwendung von Stichproben. Ein Parameter ist ein messbares Merkmal, das einer Population zugeordnet ist. Zum Beispiel, die durchschnittliche Körpergröße der Einwohner einer Stadt, Anzahl der roten Blutkörperchen, etc.
Mit diesem Wissen, fahren Sie fort und lesen Sie die obige Definition noch einmal durch. Es wird jetzt viel mehr Sinn machen!
Warum brauchen wir Bootstrap-Sampling??
Dies ist eine grundlegende Frage, mit der sich Enthusiasten des maschinellen Lernens auseinandersetzen müssen.. Was ist der Sinn von Bootstrap Sampling? Wo kann man es verwenden? Lassen Sie mich ein Beispiel nehmen, um dies zu erklären.
Nehmen wir an, wir wollen die durchschnittliche Körpergröße aller Schüler einer Schule ermitteln (mit einer Gesamtbevölkerung von 1000). Dann, Wie können wir diese Aufgabe erfüllen?
Eine Methode besteht darin, die Körpergröße aller Schüler zu messen und dann die durchschnittliche Körpergröße zu berechnen. Ich habe diesen Prozess unten dargestellt:
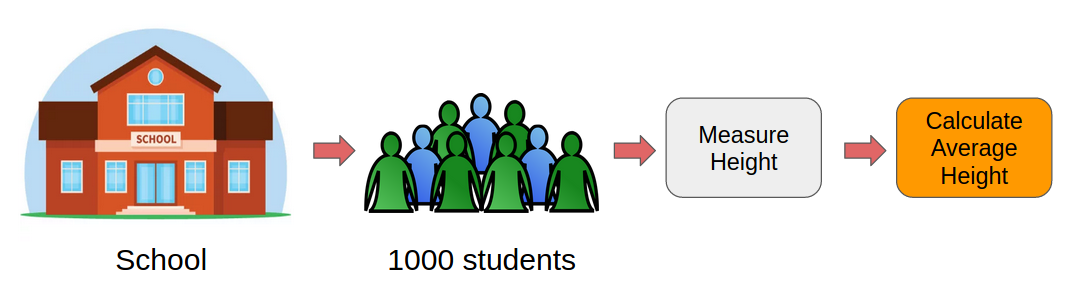
Aber trotzdem, das wäre eine mühsame aufgabe. Denk einfach drüber nach, wir müssten die höhen von einzeln messen 1,000 Schüler und berechne dann die mittlere Körpergröße. Es wird Tage dauern! Hier brauchen wir einen klügeren Ansatz.
Hier kommt Bootstrap Sampling ins Spiel..
Anstatt die Körpergröße aller Schüler zu messen, wir können eine zufällige Stichprobe ziehen von 5 Schüler und messen ihre Körpergröße. Wir würden diesen Vorgang wiederholen 20 mal und dann würden wir die gesammelten Höhendaten mitteln 100 Studenten (5 x 20). Diese Durchschnittsgröße wäre eine Schätzung der Durchschnittsgröße aller Schüler in der Schule.
Ziemlich einfach, Wahrheit? Das ist die Grundidee von Bootstrap Sampling.
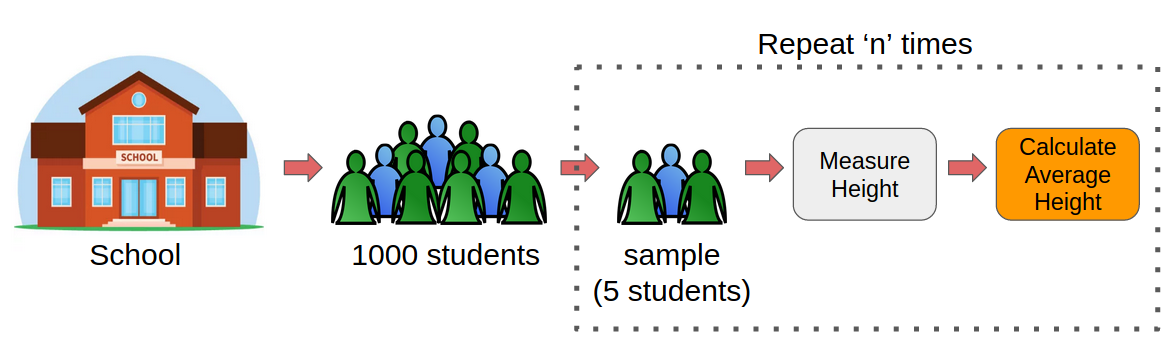
Deswegen, wenn wir einen Parameter einer großen Population schätzen müssen, wir können die Hilfe von Bootstrap Sampling nehmen.
Muestreo Bootstrap und Machine Learning
Bootstrap-Sampling wird in einem Ensemble-Algorithmus für maschinelles Lernen verwendet, der Bootstrap-Aggregation genannt wird (auch Verpackung genannt). Hilft Überanpassung zu vermeiden und verbessert die Stabilität von Algorithmen für maschinelles Lernen.
In der Tüte, eine bestimmte Anzahl gleich großer Teilmengen wird aus einem Datensatz mit Ersetzung extrahiert. Später, Auf jede dieser Teilmengen wird ein maschineller Lernalgorithmus angewendet und die Ausgaben werden wie unten dargestellt zusammengestellt:
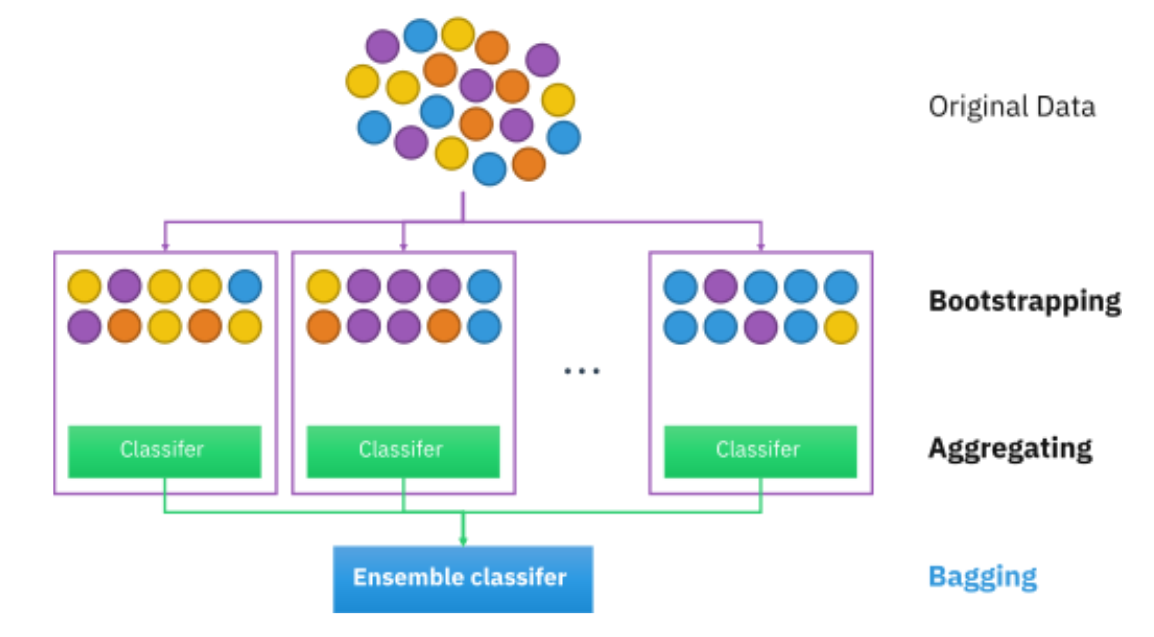
Hier können Sie mehr über Co-Learning lesen und erfahren:
Implementieren von Bootstrap-Sampling in Python
Zeit, unser Gelerntes auf die Probe zu stellen und das Bootstrap-Sampling-Konzept in Python zu implementieren.
In diesem Abschnitt, Wir werden versuchen, den Bevölkerungsdurchschnitt mit Hilfe von Bootstrap-Sampling zu schätzen. Lassen Sie uns die erforderlichen Bibliotheken importieren:
Dann, wir werden eine Verteilung erstellen (Population) Gaussiana de 10,000 Elemente mit dem Bevölkerungsmittelwert von 500:
Produktion: 500.00889503613934
Jetzt, wir werden extrahieren 40 Größenmuster 5 der Verteilung (Population) und wir berechnen den Mittelwert für jede Probe:
Lassen Sie uns den Durchschnitt der Mittelwerte der überprüfen 40 Proben:
np.mean(sample_mean)
Produktion: 500.024133172629
Es stellt sich heraus, dass es ziemlich nahe am Bevölkerungsdurchschnitt liegt!! Aus diesem Grund ist Bootstrap Sampling eine so nützliche Technik in der Statistik und beim maschinellen Lernen..
Wir fassen zusammen, was wir gelernt haben
In diesem Artikel, wir haben die Nützlichkeit von Bootstrap Sampling für Statistik und maschinelles Lernen kennengelernt. Wir implementieren es auch in Python und überprüfen seine Wirksamkeit.
Hier sind einige der wichtigsten Vorteile von Bootstrapping:
- Der durch Bootstrap-Sampling geschätzte Parameter ist mit dem realen Populationsparameter vergleichbar
- Da wir nur einige Samples zum Startup brauchen, Rechenaufwand ist viel geringer
- Ein zufälliger Wald, die Bootstrap-Stichprobengröße sogar der 20% liefert eine ziemlich gute Leistung, wie unten gezeigt:
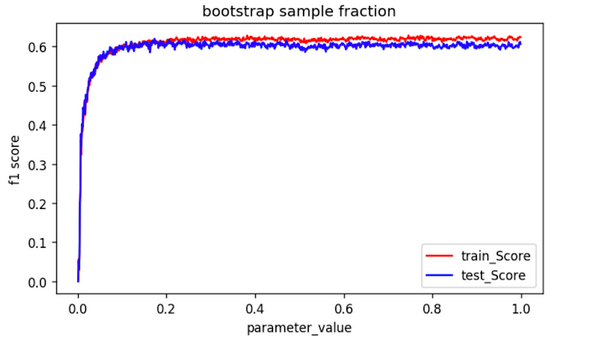
Modellleistungsspitzen, wenn die bereitgestellten Daten weniger als . betragen 0,2 Bruchteil des ursprünglichen Datensatzes.





