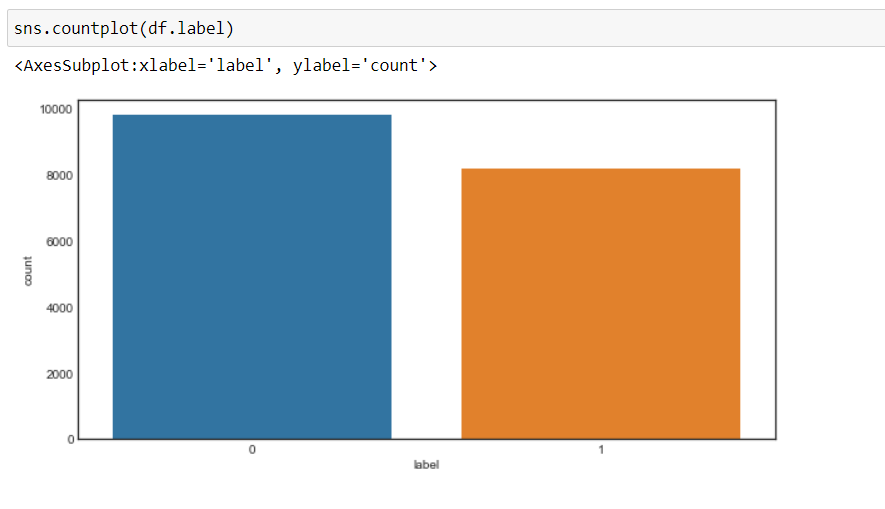
Jetzt, Wir können sehen, dass sich unser Ziel geändert hat zu 0 Ja 1, nämlich, 0 für negativ und 1 für positiv, und die Daten sind mehr oder weniger in einem ausgeglichenen Zustand.
Datenvorverarbeitung
Jetzt, Wir werden die Daten vorverarbeiten, bevor wir sie in Vektoren konvertieren und an das Modell für maschinelles Lernen übergeben.
Wir werden eine Funktion zur Datenvorverarbeitung erstellen.
1. Zuerst, wir durchlaufen jeden Datensatz und verwenden a regulärer Satz, Wir werden alle Zeichen außer den Alphabeten entfernen.
2. Später, Wir konvertieren die Zeichenfolge in Kleinbuchstaben Was, das Wort “Gut” ist anders als das Wort “gut”.
Warum, nicht in Kleinbuchstaben umgewandelt, wird ein Problem verursachen, wenn wir Vektoren dieser Wörter erstellen, da für dasselbe Wort zwei verschiedene Vektoren erstellt werden, die wir nicht wollen.
3. Später, wir suchen nach Stoppwörtern in den Daten und entfernen sie. Für Worte sind häufig verwendete Wörter in einem Satz wie “das”, “ein”, “ein”, etc. das bringt nicht viel.
4. Später, wir werden durchführen lematización in jedem Wort, nämlich, wandeln Sie die verschiedenen Formen eines Wortes in ein einziges Element um, das als Slogan bezeichnet wird.
EIN Motto ist eine Grundform eines Wortes. Zum Beispiel, “Lauf”, “laufen” Ja “Lauf” sie sind alle Formen desselben Lexems, wo “Lauf” ist das Motto. Deswegen, wir konvertieren alle Vorkommen des gleichen Lexems in ihr jeweiliges Motto.
5. Und dann einen Korpus verarbeiteter Daten zurückgeben.
Aber zuerst erstellen wir ein WordNetLemmatizer-Objekt und dann machen wir die Transformation.
#Objekt von WordNetLemmatizer lm = WordNetLemmatizer()
def text_transformation(df_col):
Korpus = []
für Artikel in df_col:
new_item = re.sub('[^ a-zA-Z]',' ',str(Artikel))
new_item = new_item.lower()
new_item = new_item.split()
neues_element = [lm.lemmatisieren(Wort) für Wort in neues_Element, wenn Wort nicht im Satz(Stoppwörter.Wörter('Englisch'))]
korpus.anhängen(' '.beitreten(str(x) für x in new_item))
Korpus zurückgeben
Korpus = text_transformation(df['Text'])
Jetzt erstellen wir a Wortwolke. Es ist eine Datenvisualisierungstechnik, die verwendet wird, um Text so darzustellen, dass die häufigsten Wörter im Vergleich zu den weniger häufigen Wörtern vergrößert erscheinen. Dies gibt uns eine kleine Vorstellung davon, wie die Daten nach der Verarbeitung durch alle bisherigen Schritte aussehen.
rcParams['figur.feigengröße'] = 20,8
word_cloud = ""
für Zeile im Korpus:
für Wort in Zeile:
word_cloud+=" ".beitreten(Wort)
Wortwolke = Wortwolke(Breite = 1000, Höhe = 500,background_color="Weiß",min_font_size = 10).generieren(Wortwolke)
plt.imshow(Wortwolke)
Produktion:
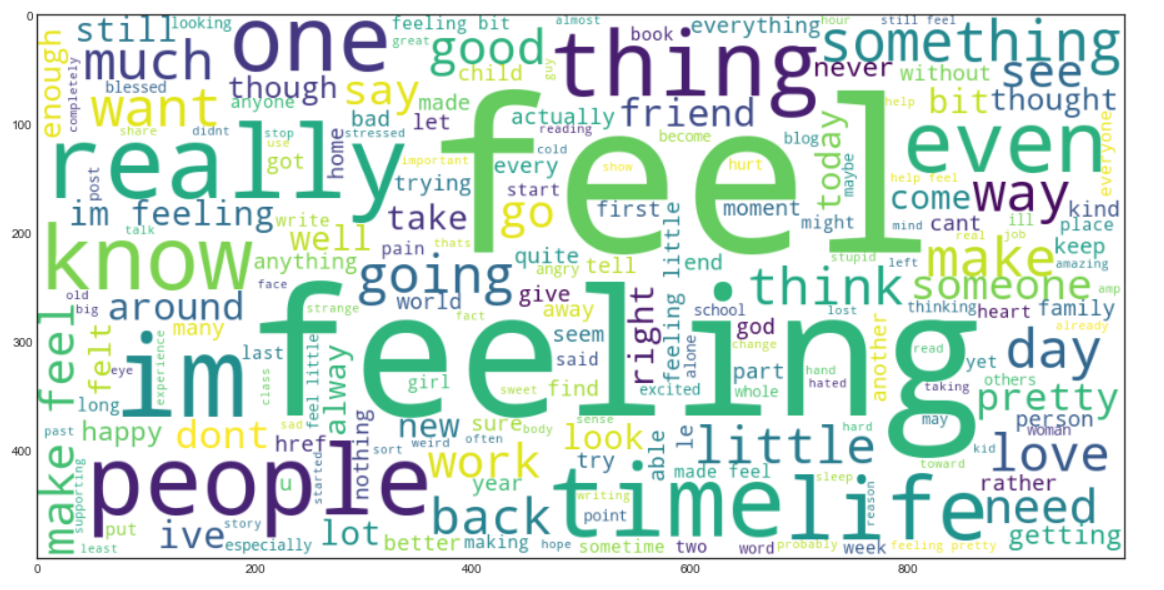
Beutel voller Worte
Jetzt, Wir werden das Bag of Words-Modell verwenden (SICH BEUGEN), die verwendet wird, um den Text in Form einer Tüte mit Wörtern darzustellen, nämlich, Grammatik und Wortstellung in einem Satz wird keine Bedeutung beigemessen, jedoch, die Vielfalt , nämlich (die Häufigkeit, mit der ein Wort in einem Dokument vorkommt) ist der Hauptgrund zur Sorge.
Grundsätzlich, beschreibt das Gesamtvorkommen von Wörtern innerhalb eines Dokuments.
Scikit-Lernen bietet eine saubere Möglichkeit, die Bag-of-Words-Technik mit auszuführen CountVectorizer.
Jetzt, wir werden die Textdaten in Vektoren umwandeln, Anpassung und Transformation des von uns erstellten Korpus.
cv = CountVectorizer(ngram_range=(1,2)) traindata = cv.fit_transform(Korpus) X = Zugdaten y = df.label
Wir werden es nehmen ngram_range Was (1,2) Was bedeutet ein Bigrama?.
Ngram ist eine Folge von 'n’ Wörter in einer Reihe oder einem Satz. ‘ngram_range’ ist ein Parameter, die wir verwenden, um der Kombination von Wörtern Bedeutung zu verleihen, Was “sozialen Medien” hat eine andere Bedeutung als “Sozial” Ja “Medien” separat.
Wir können mit dem Wert von experimentieren ngram_range Parameter und wählen Sie die Option, die die besten Ergebnisse liefert.
Jetzt kommt der Teil der Modellerstellung für maschinelles Lernen und in diesem Projekt, ich werde tragen Zufälliger Waldklassifizierer, und wir werden die Hyperparameter mit GridSearchCV anpassen.
GridSearchCV() nimmt die folgenden Parameter an,
1. Schätzen Sie das Modell – RandomForestClassifier in unserem Fall
2. Parameter: Wörterbuch der Hyperparameternamen und ihrer Werte
3. Lebenslauf: bedeutet Kreuzvalidierung Falten
4. return_train_score: gibt die Trainingsergebnisse der verschiedenen Modelle zurück
5. n_jobs – Nein. Jobs parallel laufen (“-1” bedeutet, dass alle CPU-Kerne verwendet werden, was die Trainingszeit drastisch verkürzt)
Zuerst, Wir werden ein Wörterbuch erstellen, “Parameter” die die Werte verschiedener Hyperparameter enthalten wird.
Wir werden dies als Parameter an GridSearchCV übergeben, um unser Random-Forest-Klassifikatormodell unter Verwendung aller möglichen Kombinationen dieser Parameter zu trainieren, um das beste Modell zu finden.
Parameter = {'max_features': ('Auto','sqrt'),
'n_Schätzer': [500, 1000, 1500],
'maximale Tiefe': [5, 10, Keiner],
'min_samples_split': [5, 10, 15],
'min_samples_leaf': [1, 2, 5, 10],
'Bootstrap': [Wahr, Falsch]}
Jetzt, Wir passen die Daten in der Rastersuche an und sehen den besten Parameter mit dem Attribut “beste_parameter_” von GridSearchCV.
grid_search = GridSearchCV(RandomForestClassifier(),Parameter,cv=5,return_train_score=Wahr,n_jobs=-1) grid_search.fit(x,Ja) grid_search.best_params_
Produktion:

Und später, wir können alle Modelle und ihre jeweiligen Parameter sehen, die durchschnittliche Testnote und das Ranking, da GridSearchCV alle Ergebnisse im . speichert cv_results_ Attribut.
für mich in Reichweite(432):
drucken('Parameter: ',grid_search.cv_results_['Parameter'][ich])
drucken('Durchschnittliches Testergebnis: ',grid_search.cv_results_['mean_test_score'][ich])
drucken('Rang: ',grid_search.cv_results_['rank_test_score'][ich])
Abfahrt: (ein Beispiel der Ausgabe)

Jetzt, Wir werden die besten Parameter aus GridSearchCV auswählen und ein endgültiges Zufallswald-Klassifikatormodell erstellen und dann unser neues Modell trainieren.
rfc = RandomForestClassifier(max_features=grid_search.best_params_['max_features'],
max_depth=grid_search.best_params_['maximale Tiefe'],
n_estimators=grid_search.best_params_['n_Schätzer'],
min_samples_split=grid_search.best_params_['min_samples_split'],
min_samples_leaf=grid_search.best_params_['min_samples_leaf'],
bootstrap=grid_search.best_params_['Bootstrap'])
rfc.fit(x,Ja)
Datentransformation testen
Jetzt, Wir werden die Testdaten lesen und die gleichen Transformationen wie bei den Trainingsdaten durchführen und schließlich das Modell anhand seiner Vorhersagen auswerten.
test_df = pd.read_csv('test.txt',Trennzeichen=";",Namen=['Text','Etikett'])
X_test,y_test = test_df.text,test_df.label #kodieren Sie die Labels in zwei Klassen , 0 und 1 test_df = custom_encoder(y_test) #Textvorverarbeitung test_corpus = text_transformation(X_test) #Textdaten in Vektoren umwandeln Testdaten = cv.transform(test_korpus) #das Ziel vorhersagen Vorhersagen = rfc.predict(Testdaten)
Modellbewertung
Wir werden unser Modell anhand verschiedener Metriken wie dem Accuracy Score evaluieren, Präzisionspunktzahl, Rückrufergebnis, Confusion Matrix und wir erstellen eine roc-Kurve, um die Leistung unseres Modells zu visualisieren.
rcParams['figur.feigengröße'] = 10,5
plot_confusion_matrix(y_test,Vorhersagen)
acc_score = Genauigkeit_score(y_test,Vorhersagen)
pre_score = Precision_score(y_test,Vorhersagen)
rec_score = recall_score(y_test,Vorhersagen)
drucken('Genauigkeitspunktzahl: ',acc_score)
drucken('Präzisionspunktzahl: ',pre_score)
drucken('Recall_score: ',rec_score)
drucken("-"*50)
cr = Klassifizierung_Bericht(y_test,Vorhersagen)
drucken(cr)
Produktion:
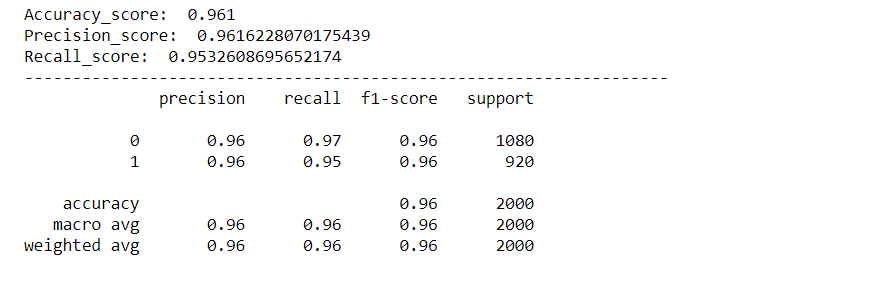
Verwirrung Matrix:
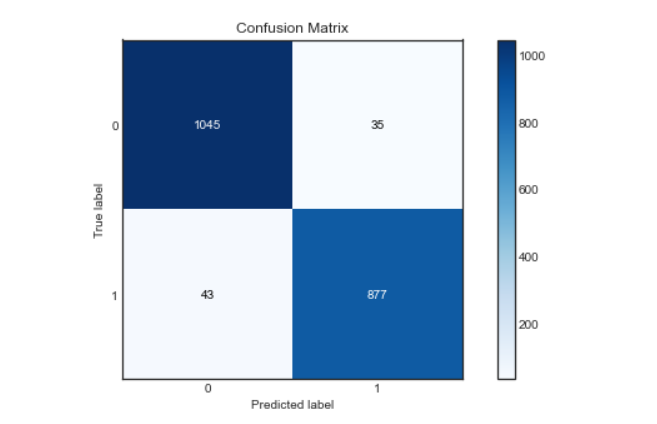
Roc-Kurve:
Wir finden die Wahrscheinlichkeit der Klasse mit der Methode predict_proba () von Random Forest Classifier und dann zeichnen wir die Kurve roc.
Predicts_probability = rfc.predict_proba(Testdaten)
fpr,tpr,Schwellen = roc_curve(y_test,Vorhersagen_Wahrscheinlichkeit[:,1])
plt.plot(fpr,tpr)
plt.plot([0,1])
plt.titel('ROC-Kurve')
plt.xlabel('Falsch-Positiv-Rate')
plt.ylabel('Echte positive Rate')
plt.zeigen()
Wie wir sehen können, unser Modell funktionierte sehr gut bei der Klassifizierung von Gefühlen, mit einer Präzisionsnote, Genauigkeit und Wiederfindung von ca. 96%. Und auch die Roc-Kurve und die Konfusionsmatrix sind hervorragend, was bedeutet, dass unser Modell die Etiketten genau klassifizieren kann, mit geringerer Fehlerwahrscheinlichkeit.
Jetzt, Wir werden auch die benutzerdefinierten Eingaben überprüfen und unser Modell die Stimmung der Eingabeanweisung identifizieren lassen.
Vorhersage für benutzerdefinierte Eingaben:
def expression_check(Vorhersage_Eingabe):
wenn vorhersage_eingabe == 0:
drucken("Die Eingabeanweisung hat eine negative Stimmung.")
Elif-Vorhersage_Eingabe == 1:
drucken("Die Eingabeanweisung hat eine positive Stimmung.")
anders:
drucken("Ungültige Anweisung.")
# Funktion, um die Eingabeanweisung zu nehmen und die gleichen Transformationen wie zuvor durchzuführen
def sentiment_predictor(Eingang):
input = text_transformation(Eingang)
transformierter_input = cv.transform(Eingang)
Vorhersage = rfc.predict(transformierte_eingabe)
expression_check(Vorhersage)
Eingang1 = ["Manchmal möchte ich einfach jemandem ins Gesicht schlagen."] Eingang2 = ["Ich habe ein neues Handy gekauft und es ist so gut."]
sentiment_predictor(Eingang1) sentiment_predictor(Eingang2)
Produktion:
Hurra, da wir sehen können, dass unser Modell die Gefühle hinter den beiden Sätzen richtig klassifiziert hat.
Wenn dir dieser Artikel gefällt, folge mir rein LinkedIn.
Und Sie können den vollständigen Code und die Ausgabe erhalten von hier.
Ausgabebilder bleiben erhalten hier als Referenz.
Das Ende?
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von Analytics Vidhya und werden nach Ermessen des Autors verwendet.





