Einführung
In den letzten Jahrzehnten, Deep Learning hat sich aufgrund seiner Fähigkeit, große Datenmengen zu verarbeiten, als sehr leistungsfähiges Werkzeug erwiesen. Das Interesse an der Verwendung versteckter Schichten hat traditionelle Techniken übertroffen, besonders bei der Mustererkennung. Eines der beliebtesten tiefen neuronalen Netze sind konvolutionelle neuronale Netze.
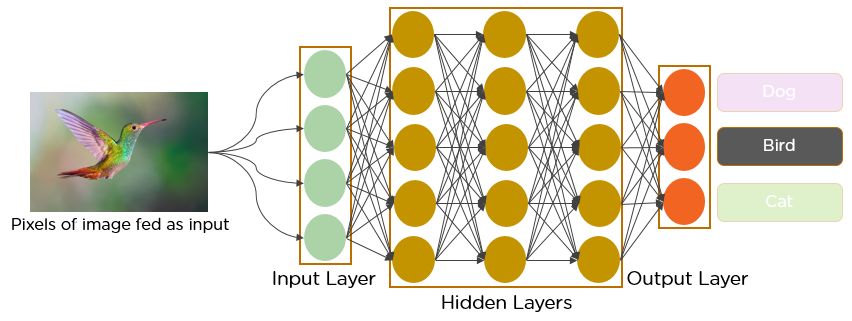
Seit dem Jahrzehnt 1950, die Anfänge von AI, Forscher haben sich schwer getan, ein System zu entwickeln, das visuelle Daten verstehen kann. In den folgenden Jahren, dieses Feld wurde als Computer Vision bekannt. In 2012, Computer Vision machte einen Quantensprung, als eine Gruppe von Forschern der University of Toronto ein Modell der künstlichen Intelligenz entwickelte, das die besten Bilderkennungsalgorithmen bei weitem übertraf.
Das künstliche Intelligenzsystem, die als AlexNet bekannt wurde (benannt nach seinem Hauptschöpfer, Alex Krizhevsky), gewann den ImageNet Computer Vision Contest von 2012 mit erstaunlicher Präzision von 85 Prozent. Der Zweitplatzierte verdiente sich ein bescheidenes 74 Prozent im Test.
Das Herzstück von AlexNet waren konvolutionelle neuronale Netze, eine spezielle Art von neuronalen Netzen, die das menschliche Sehvermögen in etwa nachahmen. Über die Jahre, CNNs sind zu einem sehr wichtigen Bestandteil vieler Computer-Vision-Anwendungen geworden und, Daher, in einem Teil von irgendwas Computer Vision Kurs online. Schauen wir uns also an, wie CNN funktioniert.
CNN-Hintergrund
CNNs wurden erstmals um das Jahrzehnt des entwickelt und verwendet 1980. Das Beste, was ein CNN zu dieser Zeit tun konnte, war, handgeschriebene Ziffern zu erkennen. Es wurde hauptsächlich im Postbereich zum Lesen von Postleitzahlen verwendet, PIN-Codes, etc. Bei jedem Deep-Learning-Modell ist zu beachten, dass für das Training viele Daten und auch viele Rechenressourcen erforderlich sind.. Dies war in dieser Zeit eine große Unannehmlichkeit für CNN und, Daher, CNNs waren nur auf den Postsektor beschränkt und konnten nicht in die Welt des maschinellen Lernens eintreten.
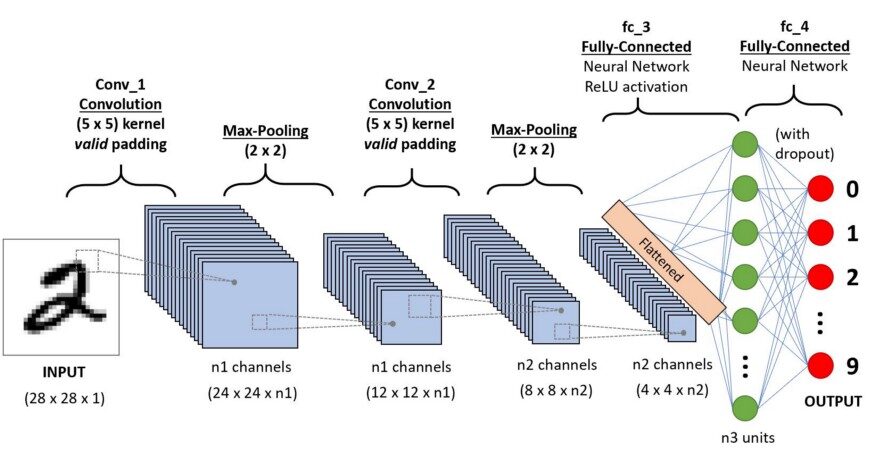
In 2012, Alex Krizhevsky erkannte, dass es an der Zeit war, den Zweig des Deep Learning zurückzuerobern, der mehrschichtige neuronale Netze verwendet. Die Verfügbarkeit großer Datensätze, um spezifischere ImageNet-Datensätze mit Millionen von markierten Bildern und einer Fülle von Computerressourcen zu sein, ermöglichte es Forschern, CNN . wiederzubeleben.
Was genau ist ein CNN??
In tiefes Lernen, ein rote neuronale Faltung (CNN / ConvNet) es ist eine Art tiefe neuronale Netze, am häufigsten verwendet, um visuelle Bilder zu analysieren. Jetzt, wenn wir an ein neuronales Netz denken, wir denken an Matrixmultiplikationen, aber das ist bei ConvNet nicht der Fall. Verwendet eine spezielle Technik namens Faltung. Jetzt in Mathe Faltung ist eine mathematische Operation an zwei Funktionen, die eine dritte Funktion erzeugt, die ausdrückt, wie die Form der einen durch die andere modifiziert wird.
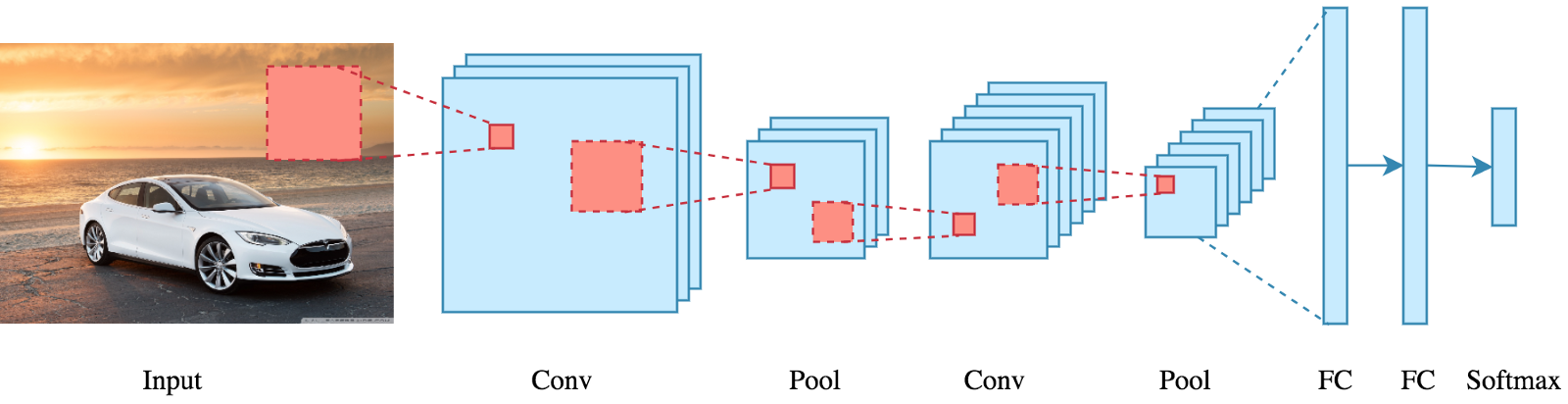
Aber wir müssen nicht wirklich über den mathematischen Teil hinausgehen, um zu verstehen, was ein CNN ist oder wie es funktioniert..
Unterm Strich ist die Rolle von ConvNet Bilder auf eine leichter zu verarbeitende Form reduzieren, ohne die für eine gute Vorhersage entscheidenden Eigenschaften zu verlieren.
Wie funktioniert es?
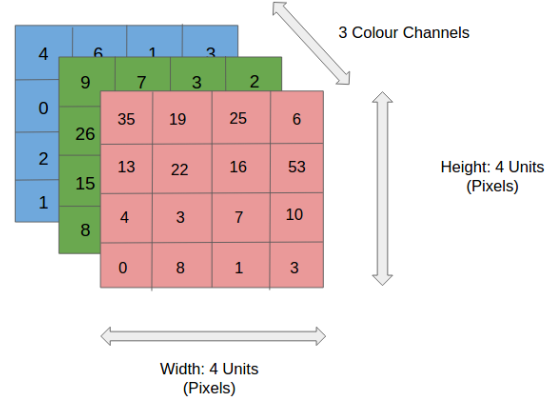
Bevor Sie zum CNN-Betrieb übergehen, lass uns die Grundlagen behandeln, wie was ist ein Bild und wie wird es dargestellt. Ein RGB-Bild ist nichts anderes als ein Array von Pixelwerten, das drei Ebenen hat, wohingegen ein Graustufenbild gleich ist, aber nur eine Ebene hat. Schauen Sie sich dieses Bild an, um mehr zu verstehen.
Vereinfachen, Lassen Sie uns mit Graustufenbildern weitermachen, während wir versuchen zu verstehen, wie CNN funktioniert.
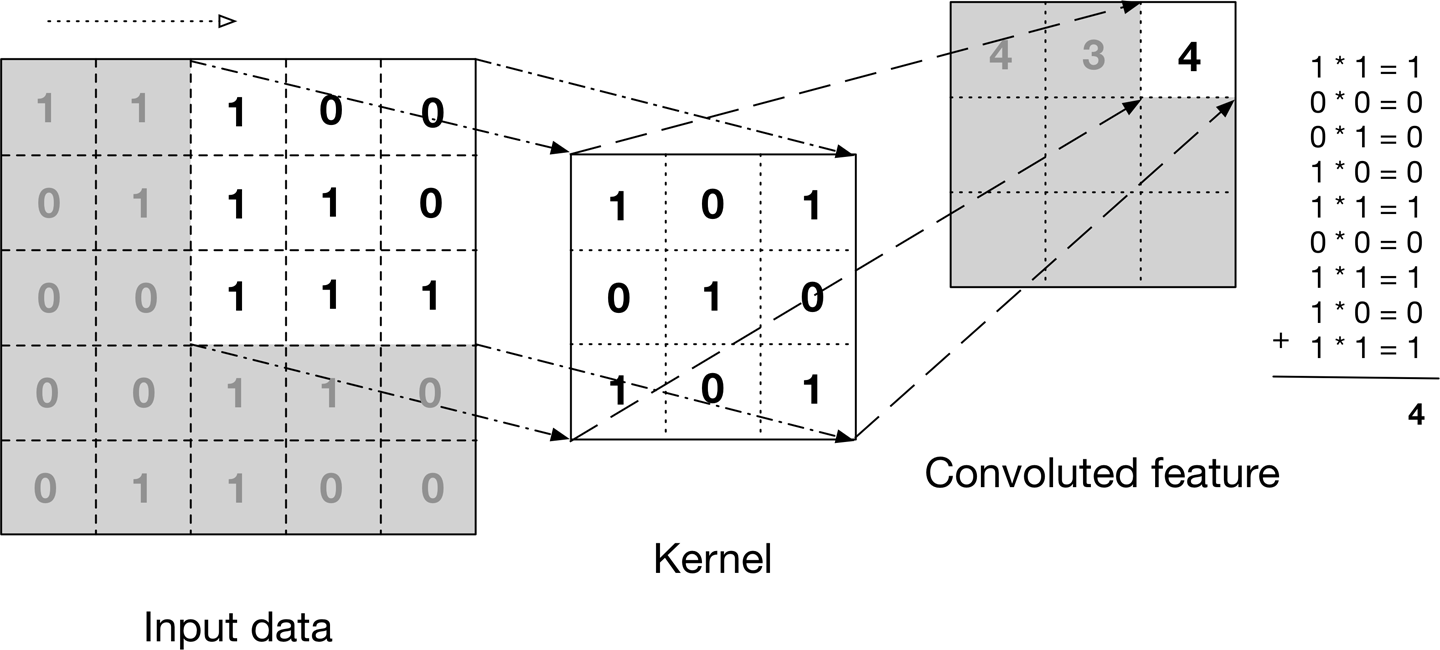
Das obige Bild zeigt, was eine Faltung ist. Wir nehmen einen Filter / Ader (Matrix von 3 × 3) und wir wenden es auf das Eingabebild an, um die gefaltete Funktion zu erhalten. Dieses gefaltete Feature wird an die nächste Schicht übergeben.
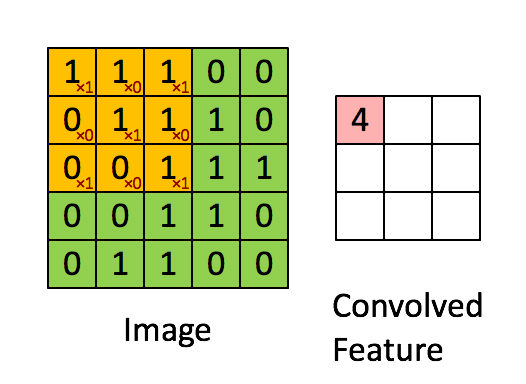
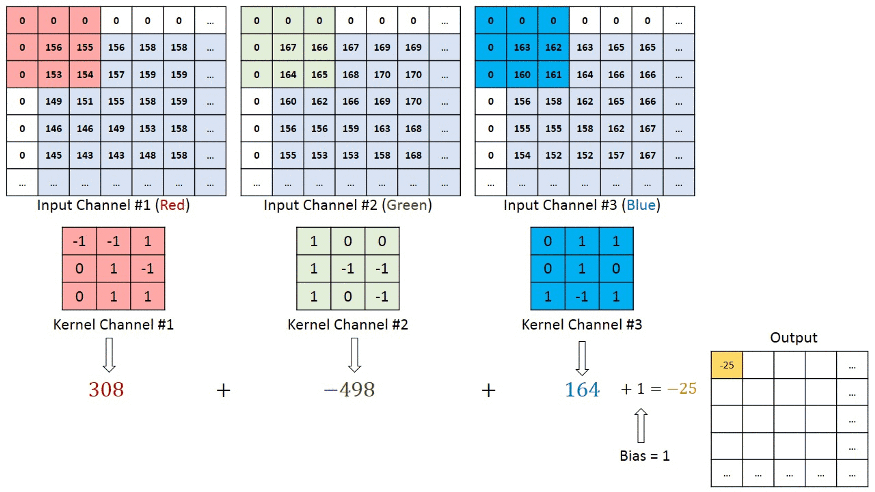
Bei RGB-Farbe, der Kanal sieh dir diese Animation an, um zu verstehen, wie es funktioniert.
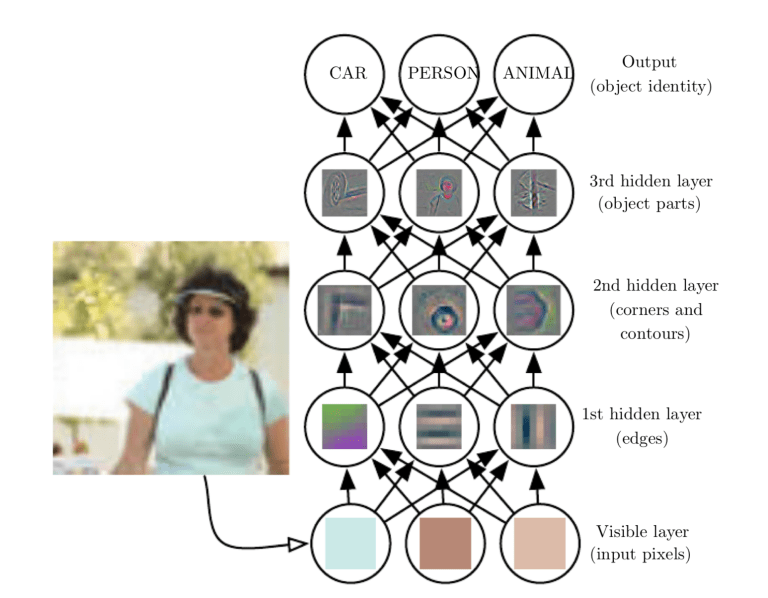
Convolutional Neural Networks bestehen aus mehreren Schichten künstlicher Neuronen. Künstliche Neuronen, eine grobe Nachahmung ihrer biologischen Artgenossen, sind mathematische Funktionen, die die gewichtete Summe mehrerer Ein- und Ausgänge eines Triggerwertes berechnen. Wenn Sie ein Bild in ein ConvNet eingeben, jede Schicht generiert mehrere Aktivierungsfunktionen, die an die nächste Schicht weitergegeben werden.
Die erste Ebene extrahiert normalerweise grundlegende Merkmale wie horizontale oder diagonale Kanten. Diese Ausgabe wird an die nächste Schicht übergeben, das erkennt komplexere Merkmale, als kombinatorische Ecken oder Kanten. Wenn wir das Web betreten, wir können noch komplexere Merkmale erkennen, als Objekte, Gesichter, etc.

Gemäß der Aktivierungskarte der letzten Faltungsschicht, die Klassifizierungsschicht generiert eine Reihe von Konfidenzbewertungen (Werte zwischen 0 Ja 1) die die Wahrscheinlichkeit angeben, dass das Bild zu a . gehört “Klasse”. Zum Beispiel, wenn Sie ein ConvNet haben, das Katzen erkennt, Hunde und Pferde, die Ausgabe der letzten Ebene ist die Möglichkeit, dass das Eingabebild eines dieser Tiere enthält.
Was ist eine Gruppierungsebene??
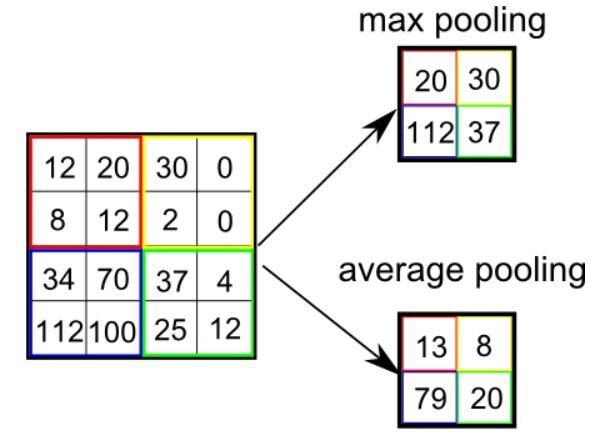
Ähnlich der Faltungsschicht, die Gruppierungsebene ist für die Verringerung der räumlichen Größe des gefalteten Elements verantwortlich. Das ist für Verringern Sie die Rechenleistung, die zum Verarbeiten von Daten erforderlich ist. Reduziermaße. Es gibt zwei Arten der Gruppierung durchschnittliche Gruppierung und maximale Gruppierung. Ich habe bisher nur Erfahrung mit Max Pooling gemacht und hatte keine Schwierigkeiten.
Dann, Was wir in Max Pooling tun, ist den maximalen Wert eines Pixels eines Teils des Bildes zu finden, der vom Kernel abgedeckt wird. Max Pooling funktioniert auch als Geräuschunterdrücker. Es schließt verrauschte Trigger vollständig aus und führt auch eine Rauschunterdrückung zusammen mit einer Dimensionsreduktion durch.
Außerdem, Durchschnittliche Gruppierung Gib die ... wieder Durchschnitt aller Werte des Teils des Bildes, der vom Kernel bedeckt ist. Die durchschnittliche Gruppierung führt lediglich eine Dimensionsreduzierung als Rauschunterdrückungsmechanismus durch. Deswegen, Wir können das sagen Der maximale Pool funktioniert viel besser als der durchschnittliche Pool.
Einschränkungen
Trotz der Leistungsfähigkeit und Komplexität der CNN-Ressourcen, liefern detaillierte Ergebnisse. An der Wurzel von allem, es geht nur darum, Muster und Details zu erkennen, die so winzig und unauffällig sind, dass sie vom menschlichen Auge nicht wahrgenommen werden. Aber wenn es darum geht Verstehen Bildinhalt schlägt fehl.
Schauen wir uns dieses Beispiel an. Wenn wir das Bild unten an ein CNN weitergeben, erkennt eine Person in der Nähe 30 Jahre und ein Kind wahrscheinlich in der Nähe 10 Jahre. Aber wenn wir das gleiche Bild betrachten, Wir haben angefangen, in mehreren verschiedenen Szenarien zu denken. Vielleicht ist es ein Vater-Sohn-Tag, ein Picknick oder vielleicht campen sie. Vielleicht ist es ein Schulgelände und der Junge hat ein Tor geschossen und sein Vater ist glücklich, also hebt er es auf.

Diese Einschränkungen sind in der praktischen Anwendung mehr als offensichtlich. Zum Beispiel, CNNs wurden häufig verwendet, um Inhalte in sozialen Medien zu moderieren. Aber trotz der riesigen Bild- und Videoressourcen, an denen sie geschult wurden, Sie können unangemessene Inhalte immer noch nicht vollständig blockieren und entfernen. Wie sich herausstellt hast du markiert eine Statue von 30.000 Jahre mit Nacktheit auf Facebook.
Mehrere Studien haben gezeigt, dass mit ImageNet trainierte CNNs und andere beliebte Datensätze keine Objekte erkennen, wenn sie unter anderen Lichtverhältnissen und aus neuen Blickwinkeln betrachtet werden..
Bedeutet dies, dass CNN nutzlos ist?? Aber trotzdem, trotz der Grenzen von Convolutional Neural Networks, Es ist nicht zu leugnen, dass sie eine Revolution in der künstlichen Intelligenz verursacht haben. Heute, CNNs werden in vielen verwendet Bildverarbeitungsanwendungen als Gesichtserkennung, Bilder suchen und bearbeiten, Augmented Reality und mehr. Wie Fortschritte bei konvolutionellen neuronalen Netzen zeigen, unsere Leistungen sind bemerkenswert und nützlich, aber wir sind noch weit davon entfernt replizieren Schlüsselkomponenten der menschlichen Intelligenz.

Danke fürs Lesen! Wenn Ihnen das Lesen dieses Artikels gefallen hat, bitte teilen, um anderen zu helfen, es zu finden! Hinterlasse gerne einen Kommentar 💬 unten. Du kannst dich mit mir verbinden unter GitHub, LinkedIn
Hast du Kommentare? Lass uns Freunde sein in Twitter.
Alles Gute und viel Spaß beim Codieren! 😀
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von Analytics Vidhya und werden nach Ermessen des Autors verwendet.





