Einführung
Künstliche Intelligenz und maschinelles Lernen werden unser größter Helfer im nächsten Jahrzehnt sein!!
Heute Morgen, Ich habe einen Artikel gelesen, in dem berichtet wurde, dass ein System der künstlichen Intelligenz gegen . gewonnen hat 20 Anwälte und Anwälte waren sehr froh, dass künstliche Intelligenz einen sich wiederholenden Teil ihrer Rollen übernehmen und ihnen helfen kann, an komplexen Themen zu arbeiten. Diese Anwälte waren erfreut, dass sie mit künstlicher Intelligenz zufriedenstellendere Funktionen ausführen können.
Heute, Ich werde ein ähnliches Beispiel teilen: wie man die Anzahl der Personen in einer Menschenmenge mit zählt Tiefes LernenTiefes Lernen, Eine Teildisziplin der Künstlichen Intelligenz, verlässt sich auf künstliche neuronale Netze, um große Datenmengen zu analysieren und zu verarbeiten. Diese Technik ermöglicht es Maschinen, Muster zu lernen und komplexe Aufgaben auszuführen, wie Spracherkennung und Computer Vision. Seine Fähigkeit, sich kontinuierlich zu verbessern, wenn mehr Daten zur Verfügung gestellt werden, macht es zu einem wichtigen Werkzeug in verschiedenen Branchen, von Gesundheit... y visión artificial? Aber, bevor du das tust, Lassen Sie uns ein Gefühl dafür entwickeln, wie einfach das Leben für einen Wissenschaftler ist, der die Menge zählt.
Benehmen Sie sich wie ein Wissenschaftler, der die Menge zählt
Lasst uns beginnen!
Kannst du mir beim Zählen helfen? / Schätzen Sie die Anzahl der Personen in diesem Bild, die an dieser Veranstaltung teilnehmen werden?

Okay, was ist mit diesem?

Quelle: ShanghaiTech-Datensatz
Du hast den Dreh raus. Am Ende dieses Tutorials, Wir werden einen Algorithmus für das Zählen von Menschenmengen mit erstaunlicher Präzision erstellen (im Vergleich zu Menschen wie dir und mir). Werden Sie einen solchen Assistenten verwenden??
PD In diesem Artikel wird davon ausgegangen, dass Sie über ein grundlegendes Verständnis der Funktionsweise von Convolutional Neural Networks verfügen. (CNN). Weitere Informationen zu diesem Thema finden Sie im folgenden Beitrag, bevor Sie fortfahren.:
Inhaltsverzeichnis
- Was ist Crowd-Counting??
- Warum ist Crowd-Counting erforderlich??
- Verständnis verschiedener Computer-Vision-Techniken zum Zählen von Menschenmengen
- CSRNet-Architektur und Trainingsmethoden
- Erstellen Sie Ihr eigenes Crowd-Counting-Modell in Python
Dieser Artikel ist sehr inspiriert von dem Artikel: CSRNet: Dilatierte neuronale Faltungsnetze zum Verständnis stark überlasteter Szenen.
Was ist Crowd-Counting??
Crowd Counting ist eine Technik zum Zählen oder Schätzen der Anzahl der Personen in einem Bild. Nehmen Sie sich einen Moment Zeit, um das folgende Bild zu analysieren:
Quelle: ShanghaiTech-Datensatz
Können Sie mir ungefähr sagen, wie viele Personen sich in der Box befinden?? Jawohl, einschließlich der im Hintergrund anwesenden. Die direkteste Methode besteht darin, jede Person manuell zu zählen, aber macht das praktisch sinn? Es ist fast unmöglich, wenn der Andrang so groß ist!
Die Crowd Scientists (Jawohl, Das ist eine echte Berufsbezeichnung!) Sie zählen die Anzahl der Personen in bestimmten Teilen eines Bildes und extrapolieren dann, um eine Schätzung zu erhalten. Häufiger, Wir mussten uns seit Jahrzehnten auf Rohmetriken verlassen, um diese Zahl zu schätzen.
Sicherlich muss es einen besseren und genaueren Ansatz geben.
Ja gibt es!
Obwohl wir immer noch keine Algorithmen haben, die uns die GENAUE Zahl liefern können, die Mehrheit Computer Vision Techniken können beeindruckend genaue Schätzungen erzeugen. Lassen Sie uns zuerst verstehen, warum das Zählen von Menschenmengen wichtig ist, bevor wir in den Algorithmus dahinter eintauchen..
Warum ist Crowd-Counting sinnvoll??
Lassen Sie uns die Nützlichkeit von Crowd-Counting anhand eines Beispiels verstehen. Stell dir das vor: Ihr Unternehmen hat gerade eine Big Data Science-Konferenz veranstaltet. Während der Veranstaltung wurden viele verschiedene Sitzungen abgehalten.
Se le pide que analice y estime el número de personas que asistieron a cada SitzungDas "Sitzung" Es ist ein Schlüsselbegriff im Bereich der Psychologie und Therapie. Bezieht sich auf ein geplantes Treffen zwischen einem Therapeuten und einem Klienten, wo Gedanken erforscht werden, Emotionen und Verhaltensweisen. Diese Sitzungen können in Länge und Häufigkeit variieren, und ihr Hauptzweck ist es, persönliches Wachstum und Problemlösung zu erleichtern. Die Wirksamkeit der Sitzungen hängt von der Beziehung zwischen dem Therapeuten und dem Therapeuten ab... Dies wird Ihrem Team helfen zu verstehen, welche Arten von Sitzungen die meisten Menschen angezogen haben. (und welche sind in diesem Sinne gescheitert). Das wird die Konferenz im nächsten Jahr prägen, Es ist also eine wichtige Aufgabe!

Es waren Hunderte von Menschen bei der Veranstaltung, Das manuelle Zählen dauert Tage! Hier kommen Ihre Fähigkeiten als Data Scientist ins Spiel.. Er schaffte es, bei jedem Shooting Fotos von der Menge zu machen und ein Computer-Vision-Modell zu erstellen, um den Rest zu erledigen!!
Es gibt viele andere Szenarien, in denen Crowd-Counting-Algorithmen die Arbeitsweise von Branchen verändern.:
- Zählen der Personen, die an einer Sportveranstaltung teilnehmen
- Schätzen Sie, wie viele Personen an einer Einweihung oder einem Marsch teilgenommen haben (politische Demonstrationen, womöglich)
- Überwachung von stark frequentierten Bereichen
- Unterstützung bei der Personal- und Ressourcenzuweisung.
Können Sie sich andere Anwendungsfälle vorstellen?? Lass es mich im Kommentarbereich unten wissen!! Wir können uns verbinden und versuchen herauszufinden, wie wir Crowd-Counting-Techniken auf Ihrer Bühne einsetzen können..
Verständnis verschiedener Computer-Vision-Techniken zum Zählen von Menschenmengen
Allgemein gesagt, Es gibt derzeit vier Methoden, mit denen wir die Anzahl der Personen in einer Menschenmenge zählen können:
1. Erkennungsbasierte Methoden
Hier, Wir verwenden einen sich bewegenden fensterartigen Detektor, um Personen in einem Bild zu identifizieren und zu zählen, wie viele es sind. Die zur Detektion verwendeten Methoden erfordern gut trainierte Klassifikatoren, die Low-Level-Merkmale extrahieren können. Obwohl diese Methoden gut funktionieren, um Gesichter zu erkennen, funktionieren nicht gut in überfüllten Bildern, da die meisten Zielobjekte nicht deutlich sichtbar sind.
2. Regressionsbasierte Methoden
Mit dem obigen Ansatz konnten wir keine Low-Level-Features extrahieren. Regressionsbasierte Methoden triumphieren hier. Zuerst schneiden wir die Patches aus dem Bild aus und dann, für jeden Patch, Wir extrahieren die Low-Level-Eigenschaften.
3. Methoden basierend auf Dichteschätzung
Zuerst erstellen wir eine Dichtekarte für die Objekte. Später, der Algorithmus lernt eine lineare Abbildung zwischen den extrahierten Merkmalen und ihren Objektdichtekarten. Wir können auch die Random-Forest-Regression verwenden, um nichtlineare Kartierungen zu lernen.
4. CNN-basierte Methoden
Ah, gute und zuverlässige neuronale Faltungsnetze (CNN). Anstatt sich die Flecken eines Bildes anzusehen, Wir erstellen eine End-to-End-Regressionsmethode mit CNN. Dies nimmt das gesamte Bild als Eingabe und gibt direkt die Personenzahl aus. CNNs eignen sich hervorragend für Regressions- oder Klassifizierungsaufgaben, und sie haben sich auch bei der Erstellung von Dichtekarten bewährt.
CSRNet, eine Technik, die wir in diesem Artikel implementieren werden, implementiert tieferes CNN, um High-Level-Features zu erfassen und hochwertige Dichtekarten zu generieren, ohne die Netzwerkkomplexität zu erhöhen. Lassen Sie uns verstehen, was CSRNet ist, bevor wir zum Abschnitt zur Codierung übergehen.
Verständnis der CSRNet-Architektur und Trainingsmethode
CSRNet verwendet VGG-16 als Schnittstelle aufgrund seiner hohen Transfer-Lernfähigkeiten. Die VGG-Ausgabegröße beträgt ein Fünftel der ursprünglichen Eingabegröße. CSRNet verwendet auch erweiterte Faltungsschichten auf der Rückseite.
Aber, Was zum Teufel sind erweiterte Windungen? Es ist eine berechtigte Frage. Betrachten Sie das folgende Bild:
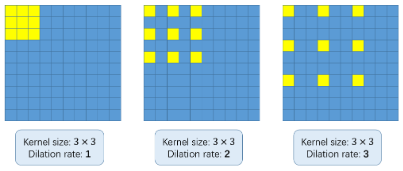
El concepto básico de usar convoluciones dilatadas es agrandar el kernel sin aumentar los ParameterDas "Parameter" sind Variablen oder Kriterien, die zur Definition von, ein Phänomen oder System zu messen oder zu bewerten. In verschiedenen Bereichen wie z.B. Statistik, Informatik und naturwissenschaftliche Forschung, Parameter sind entscheidend für die Etablierung von Normen und Standards, die die Datenanalyse und -interpretation leiten. Ihre richtige Auswahl und Handhabung sind entscheidend, um genaue und relevante Ergebnisse in jeder Studie oder jedem Projekt zu erhalten..... Dann, wenn die Dilatationsrate 1, wir nehmen den Kernel und wandeln ihn in das ganze Image um. Während, wenn wir die Dilatationsrate auf erhöhen 2, der Kern erstreckt sich wie im Bild oben gezeigt (Folgen Sie den Etiketten unter jedem Bild). Kann eine Alternative zur Ebenengruppierung sein.
Grundlegende Mathematik (empfohlen, aber optional)
Ich werde mir einen Moment Zeit nehmen, um zu erklären, wie Mathematik funktioniert. Beachten Sie, dass dies nicht zwingend erforderlich ist, um den Algorithmus in Python zu implementieren, aber ich empfehle dir, die zugrunde liegende Idee zu lernen. Dies ist praktisch, wenn Sie Ihr Modell anpassen oder ändern müssen..
Angenommen, wir haben eine Eingabe x (m, n), ein Filter w (ich, J) und die Dilatationsrate r. Die Ausgabe und (m, n) es wird sein:
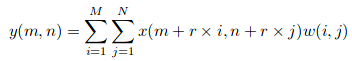
Wir können diese Gleichung mit einem Kernel verallgemeinern (k * k) mit einer Dilatationsrate r. Der Kern vergrößert sich zu:
([k + (k-1)*(r-1)] * [k + (k-1)*(r-1)])
So wurde die grundlegende Wahrheit für jedes Bild generiert. Der Kopf jeder Person in einem bestimmten Bild wird mit einem Gaußschen Kernel verwischt. Alle Bilder sind beschnitten bei 9 Patches und die Größe jedes Patches beträgt ein Viertel der ursprünglichen Bildgröße. Bis jetzt bei mir?
Der erste 4 Patches sind unterteilt in 4 Zimmer und die anderen 5 Patches werden zufällig ausgeschnitten. Schließlich, se toma el espejo de cada parche para duplicar el conjunto de AusbildungTraining ist ein systematischer Prozess zur Verbesserung der Fähigkeiten, körperliche Kenntnisse oder Fähigkeiten. Es wird in verschiedenen Bereichen angewendet, wie Sport, Aus- und Weiterbildung. Zu einem effektiven Trainingsprogramm gehört auch die Zielplanung, Regelmäßiges Üben und Bewerten der Fortschritte. Anpassung an individuelle Bedürfnisse und Motivation sind Schlüsselfaktoren, um in jeder Disziplin erfolgreiche und nachhaltige Ergebnisse zu erzielen.....
Dass, in einer Nussschale, sind die Details der Architektur hinter CSRNet. Dann, wir sehen deine Trainingsdetails, einschließlich verwendeter Bewertungsmetrik.
El descenso de SteigungGradient ist ein Begriff, der in verschiedenen Bereichen verwendet wird, wie Mathematik und Informatik, um eine kontinuierliche Variation von Werten zu beschreiben. In Mathematik, bezieht sich auf die Änderungsrate einer Funktion, während des Studiums im Grafikdesign, Gilt für den Farbübergang. Dieses Konzept ist unerlässlich, um Phänomene wie die Optimierung von Algorithmen und die visuelle Darstellung von Daten zu verstehen, ermöglicht eine bessere Interpretation und Analyse in... estocástico se utiliza para entrenar CSRNet como una estructura de extremo a extremo. Während der Ausbildung, die feste Lernrate ist eingestellt auf 1e-6. Das Verlust-FunktionDie Verlustfunktion ist ein grundlegendes Werkzeug des maschinellen Lernens, das die Diskrepanz zwischen Modellvorhersagen und tatsächlichen Werten quantifiziert. Ziel ist es, den Trainingsprozess zu steuern, indem dieser Unterschied minimiert wird, Dadurch kann das Modell effektiver lernen. Es gibt verschiedene Arten von Verlustfunktionen, wie z. B. mittlerer quadratischer Fehler und Kreuzentropie, jeder für unterschiedliche Aufgaben geeignet und... se toma como la distancia euclidiana para medir la diferencia entre la verdad del terreno y el mapa de densidad estimado. Dies wird dargestellt als:
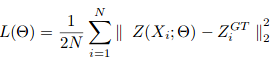
wobei N die Größe des Trainingsstapels ist. Die in CSRNet verwendete Bewertungsmetrik ist MAE und MSE, nämlich, mittlerer absoluter Fehler und mittlerer quadratischer Fehler. Diese werden gegeben von:
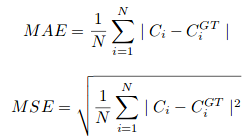
Hier, Ci ist die geschätzte Anzahl:
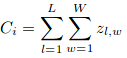
L und W sind die Breite der vorhergesagten Dichtekarte.
Unser Modell wird zuerst die Dichtekarte für ein gegebenes Bild vorhersagen. Der Pixelwert wird 0 wenn keine Person anwesend ist. Ein bestimmter voreingestellter Wert wird zugewiesen, wenn dieser Pixel einer Person entspricht. Dann, Wenn wir die Gesamtpixelwerte einer Person berechnen, erhalten wir die Anzahl der Personen in diesem Bild. Beeindruckend, Wahrheit?
Und nun, meine Damen und Herren, Es ist an der Zeit, endlich unser eigenes Crowd-Counting-Modell zu bauen!!
Erstellen Sie Ihr eigenes Crowd-Counting-Modell
Bereit mit eingeschaltetem Laptop?
Wir werden CSRNet im ShanghaiTech-Datensatz implementieren. Das beinhaltet 1198 kommentierte Bilder aus insgesamt 330,165 Menschen. Sie können den Datensatz herunterladen von hier.
Verwenden Sie den folgenden Codeblock, um das CSRNet-pytorch-Repository zu klonen. Enthält den gesamten Code zum Erstellen des Datensatzes, Trainieren Sie das Modell und validieren Sie die Ergebnisse:
Git-Klon https://github.com/leeyeehoo/CSRNet-pytorch.git
Bitte installiere WUNDER Ja PyTorch vor dem Fortfahren. Dies sind das Rückgrat hinter dem Code, den wir als nächstes verwenden werden.
Jetzt, Verschieben Sie das Dataset in das zuvor geklonte Repository und entpacken Sie es.. Später, wir müssen die grundlegenden Wahrheitswerte erstellen. das make_dataset.ipynb Datei ist unser Retter. Wir müssen nur geringfügige Änderungen an diesem Notebook vornehmen:
#setting the root to the Shanghai Datensatzein "Datensatz" oder Datensatz ist eine strukturierte Sammlung von Informationen, die für statistische Analysen verwendet werden können, Maschinelles Lernen oder Forschung. Datensätze können numerische Variablen enthalten, kategorisch oder textuell, und ihre Qualität ist entscheidend für zuverlässige Ergebnisse. Sein Einsatz erstreckt sich auf verschiedene Disziplinen, wie z.B. Medizin, Wirtschafts- und Sozialwissenschaften, Erleichterung einer fundierten Entscheidungsfindung und der Entwicklung von Vorhersagemodellen.... you have downloaded # Ändern Sie den Root-Pfad gemäß Ihrem Standort des Datensatzes Wurzel="/home/pulkit/CSRNet-pytorch/"
Jetzt, Lassen Sie uns die grundlegenden Realwerte für die Bilder in Teil_A und Teil_B generieren:
Das Generieren der Dichtekarte für jedes Bild ist ein Zeitschritt. Also mach dir eine Tasse Kaffee, während der Code läuft.
Bis jetzt, wir haben die grundlegenden Wahrheitswerte für die Bilder in Teil_A generiert. Das gleiche machen wir mit den Bildern part_B. Aber vorher, veamos una imagen de muestra y tracemos su Heatmapein "Heatmap" ist eine grafische Darstellung, die Farben verwendet, um die Dichte von Daten in einem bestimmten Bereich anzuzeigen. Häufig in der Datenanalyse verwendet, Marketing und Verhaltensstudien, Diese Art der Visualisierung ermöglicht es Ihnen, Muster und Trends schnell zu erkennen. Durch chromatische Variationen, Heatmaps erleichtern die Interpretation großer Informationsmengen, dabei helfen, fundierte Entscheidungen zu treffen.... de verdad del suelo:
plt.imshow(Bild.öffnen(img_paths[0]))
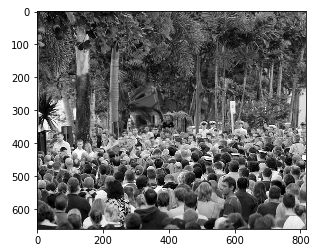
Es wird interessant!
gt_file = h5py.Datei(img_paths[0].ersetzen('.jpg','.h5').ersetzen('Bilder','Grundwahrheit'),'R')
Groundtruth = np.asarray(gt_datei['Dichte'])
plt.imshow(Bodenwahrheit,cmap=CM.jet)
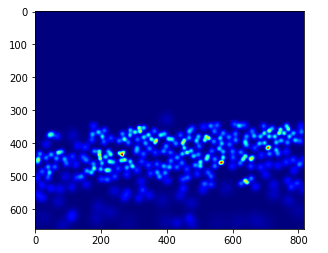
Zählen wir, wie viele Personen in diesem Bild vorhanden sind:
np.sum(Bodenwahrheit)
270.32568
Auf die gleiche Weise, wir generieren Werte für part_B:
Jetzt, wir haben die bilder, sowie ihre entsprechenden fundamentalen Wahrheitswerte. Zeit unser Modell zu trainieren!
Wir werden die .json-Dateien verwenden, die im geklonten Verzeichnis verfügbar sind. Solo tenemos que cambiar la ubicación de las imágenes en los archivos jsonJSON, o JavaScript-Objekt-Notation, Es handelt sich um ein leichtgewichtiges Datenaustauschformat, das für Menschen leicht zu lesen und zu schreiben ist, und für Maschinen einfach zu analysieren und zu generieren. Es wird häufig in Webanwendungen verwendet, um Informationen zwischen einem Server und einem Client zu senden und zu empfangen. Seine Struktur basiert auf Schlüssel-Wert-Paaren, Dadurch ist es vielseitig einsetzbar und in der Softwareentwicklung weit verbreitet... Um dies zu tun, öffne die .json-Datei und ersetze den aktuellen Speicherort durch den Speicherort, an dem sich deine Bilder befinden.
Bitte beachten Sie, dass der gesamte Code in Python geschrieben ist 2. Nehmen Sie die folgenden Änderungen vor, wenn Sie eine andere Version von Python verwenden:
- In model.py, Xrange auf der Linie ändern 18 eine Reihe
- Ändere die Zeile 19 in model.py mit: aufführen (self.frontend.state_dict (). Produkte ())[ich][1].Daten[:] = Liste (mod.state_dict (). Produkte ())[ich][1].Daten[:]
- In image.py, reemplace ground_truth con ground-truth
Hast du die Änderungen vorgenommen? Jetzt, Öffnen Sie ein neues Terminalfenster und geben Sie die folgenden Befehle ein:
cd CSRNet-pytorch python train.py part_A_train.json part_A_val.json 0 0
Nochmal, setz dich hin, denn das wird einige Zeit dauern. Sie können die Anzahl der Epochen im train.py Datei, um den Prozess zu beschleunigen. Eine gute Alternative ist das Herunterladen der vortrainierten Gewichte. von hier wenn du keine Lust hast zu warten.
Schließlich, Lassen Sie uns die Leistung unseres Modells mit unsichtbaren Daten überprüfen. Wir werden die verwenden val.ipynb Datei, um die Ergebnisse zu validieren. Denken Sie daran, den Pfad zu den zuvor trainierten Gewichten und Bildern zu ändern.
#den Bildpfad definieren
img_paths = []
für Pfad in path_sets:
für img_path in glob.glob(os.path.join(Weg, '*.jpg')):
img_paths.append(img_path)
Modell = CSRNet()
#das Modell definieren model = model.cuda()
#Laden der trainierten Gewichte
checkpoint = brenner.load('part_A/0model_best.pth.tar')
model.load_state_dict(Kontrollpunkt['state_dict'])
Überprüfen Sie die MAE (mittlerer absoluter Fehler) in den Testbildern zur Bewertung unseres Modells:
Wir haben einen MAE-Wert von 75,69, das ist ziemlich gut. Sehen wir uns nun die Vorhersagen in einem einzigen Bild an:
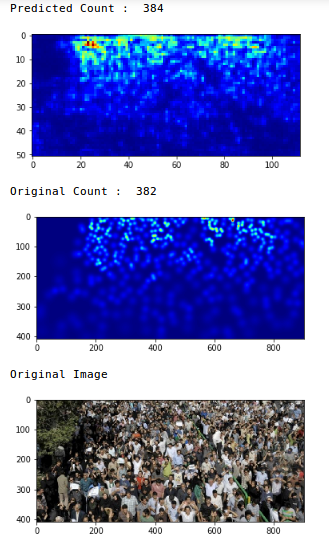 Beeindruckend, die ursprüngliche zählung war 382 und unser Modell schätzte, dass es 384 Leute auf dem Bild. Das ist eine sehr beeindruckende Leistung!!
Beeindruckend, die ursprüngliche zählung war 382 und unser Modell schätzte, dass es 384 Leute auf dem Bild. Das ist eine sehr beeindruckende Leistung!!
Herzlichen Glückwunsch zum Aufbau Ihres eigenen Crowd-Counting-Modells!!
Abschließende Anmerkungen
Ich ermutige Sie, diesen Ansatz an verschiedenen Bildern auszuprobieren und Ihre Ergebnisse im Kommentarbereich unten zu teilen.. Crowd Counting hat viele verschiedene Anwendungen und wird bereits von Organisationen und Regierungsbehörden übernommen..
Es ist eine nützliche Fähigkeit, die Sie Ihrem Portfolio hinzufügen können. Viele Branchen werden nach Data Scientists suchen, die mit Crowd-Counting-Algorithmen arbeiten können. Lernen, experimentiere damit und gib dir selbst das Geschenk von Deep Learning!
Fanden Sie diesen Artikel nützlich?? Fühlen Sie sich frei, mir Ihre Vorschläge und Kommentare unten zu hinterlassen, und ich kommuniziere gerne mit dir.
Sie sollten sich auch die folgenden Ressourcen ansehen, um die wunderbare Welt der Computer Vision kennenzulernen und zu erkunden.:





