Einführung:
In diesem Artikel, wir lernen alle wichtigen statistischen Konzepte kennen, die für Data-Science-Rollen erforderlich sind.
Inhaltsverzeichnis:
- Unterschied zwischen Parameter und Statistik
- Statistiken und ihre Typen
- Datentypen und Messebenen
- Momente der Geschäftsentscheidung
- Zentraler Grenzwertsatz (CLT)
- Wahrscheinlichkeitsverteilungen
- Grafische Darstellungen
- Hypothesentest
1. Unterschied zwischen Parameter und Statistik
In unserem Alltag sprechen wir weiter über Bevölkerung und Shows. Dann, Es ist sehr wichtig, die Terminologie zu kennen, um die Grundgesamtheit und die Stichprobe darzustellen.
Ein Parameter ist eine Zahl, die die Bevölkerungsdaten beschreibt. Und eine Statistik ist eine Zahl, die die Daten in einer Stichprobe beschreibt.
2. Statistiken und ihre Typen
Die Wikipedia-Definition von Statistik besagt, dass “ist eine Disziplin, die sich mit der Zusammenstellung beschäftigt, Organisation, Analyse, Interpretation und Präsentation von Daten”.
Bedeutet, dass, im Rahmen der statistischen Analyse, wir sammeln, Organisieren und extrahieren Sie aussagekräftige Informationen aus Daten, entweder durch Visualisierungen oder mathematische Erklärungen.
Statistiken werden grob in zwei Typen eingeteilt:
- Beschreibende Statistik
- Inferenzstatistik
Beschreibende Statistik:
Wie der Name in der Deskriptiven Statistik vermuten lässt, Wir beschreiben die Daten mit den Mittelwertverteilungen, Standardabweichung, Grafiken oder Wahrscheinlichkeit.
Grundsätzlich, im Rahmen der deskriptiven Statistik, wir messen folgendes:
- Frequenz: Nein. wie oft ein Datenpunkt auftritt
- Zentraler Trend: die Zentralität von Daten: Medien, mittel und modus.
- Dispersion: der Umfang der Daten: Rang, Varianz und Standardabweichung
- Das Maß der Position: Perzentile und Quantilbereiche
Inferenzstatistik:
In Inferenzstatistik, wir schätzen die Populationsparameter. Oder wir führen Hypothesentests durch, um die Annahmen über die Populationsparameter zu bewerten..
In einfachen Worten, wir interpretieren die Bedeutung deskriptiver Statistiken, indem wir sie auf die Bevölkerung ableiten.
Zum Beispiel, wir führen eine Umfrage zur Anzahl der Zweiräder in einer Stadt durch. Angenommen, die Stadt hat eine Gesamtbevölkerung von 5 Litern. Deswegen, Wir haben eine Probe von genommen 1000 Menschen, da eine Analyse der gesamten Bevölkerungsdaten nicht möglich ist.
Aus der durchgeführten Umfrage, es wird festgestellt, dass 800 Menschen von 1000 (800 von 1000 es ist 80%) sie sind zweiräder. Dann, wir können diese Ergebnisse auf die Bevölkerung ableiten und schlussfolgern, dass die 4L-Leute aus der 5L-Population Zweiräder sind.
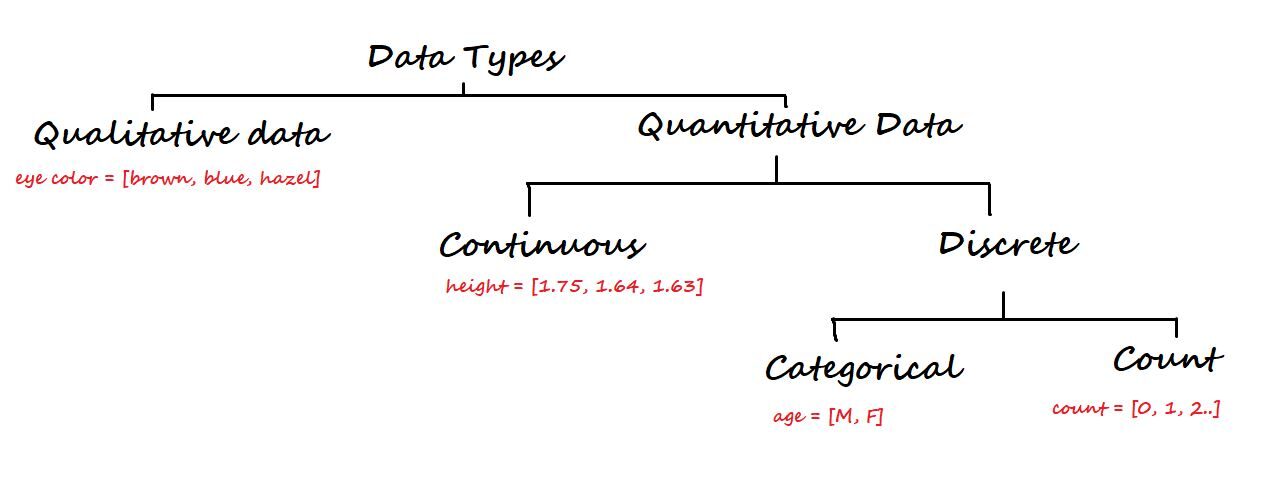
3. Datentypen und Messebene
Auf einem höheren Niveau, Daten werden in zwei Arten eingeteilt: Qualitativ Ja Quantitativ.
Qualitative Daten sind nicht numerisch. Einige der Beispiele sind Augenfarbe, Automarke, die Stadt, etc.
Zweitens, quantitative Daten sind numerisch und wiederum unterteilt in kontinuierliche und diskrete Daten.
Kontinuierliche Daten: Kann im Dezimalformat dargestellt werden. Einige Beispiele sind Höhe, Last, Wetter, Distanz, etc.
Diskrete Daten: Kann nicht im Dezimalformat dargestellt werden. Einige Beispiele sind die Anzahl der Laptops, die Anzahl der Schüler in einer Klasse.
Diskrete Daten werden wieder in kategoriale und Zähldaten aufgeteilt.
Kategoriale Daten: repräsentieren die Art von Daten, die in Gruppen unterteilt werden können. Einige Beispiele sind das Alter, Sex, etc.
Zähldaten: Diese Daten enthalten nicht negative ganze Zahlen. Beispiel: Anzahl der Kinder, die ein Partner hat.
Messebene
In der Statistik, das Messniveau ist eine Klassifikation, die die Beziehung zwischen den Werten einer Variablen beschreibt.
Wir haben vier grundlegende Messebenen. Sohn:
- Nominalskala
- Ordinalskala
- Intervall-Skala
- Anteilsskala
1. Nominalskala: Diese Skala enthält die wenigsten Informationen, da die Daten nur Namen haben / Etiketten. Kann zur Klassifizierung verwendet werden. Wir können keine mathematischen Operationen mit Nominaldaten durchführen, da es keinen numerischen Wert für die Optionen gibt (die mit den Namen verknüpften Zahlen können nur als Label verwendet werden).
Beispiel: Zu welchem Land gehörst du? Indien, Japan, Korea.
2. Ordinalskala: Im Vergleich zur Nennskala, die Ordinalskala hat mehr Informationen, denn zusammen mit den Labels, hat ordnung / die Anschrift.
Beispiel: Einkommensniveau: hohes Einkommen, durchschnittliches Einkommen, niedrige Einkommen.
3. Intervall-Skala: Es ist eine Zahlenskala. Die Intervallskala hat mehr Informationen als die nominalen Ordinalskalen. Zusammen mit der Bestellung, wir kennen den Unterschied zwischen den beiden Variablen (das Intervall gibt den Abstand zwischen zwei Entitäten an).
Der Durchschnitt kann verwendet werden, Median und Modus zur Beschreibung der Daten.
Beispiel: Temperatur, Einkommen, etc.
4. Verhältnisskala: Die Verhältnisskala enthält die meisten Informationen über die Daten. Im Gegensatz zu den anderen drei Skalen, die Verhältnisskala kann einen echten Nullpunkt aufnehmen. Es wird einfach gesagt, dass die Verhältnisskala die Kombination der Skalen Nominal . ist, Ordinal e Interkal.
Beispiel: tatsächliches Gewicht, Höhe, etc.
4. Momente der Geschäftsentscheidung
Wir haben vier Geschäftsentscheidungsmomente, die uns helfen, die Daten zu verstehen.
4.1. Maße der zentralen Tendenz
(In erster Linie auch als Geschäftsentscheidung bekannt)
Sprechen Sie über die Zentralität von Daten. um es zu vereinfachen, ist Teil der deskriptiven statistischen Analyse, bei der ein einzelner Wert in der Mitte den gesamten Datensatz repräsentiert.
Die zentrale Tendenz eines Datensatzes kann gemessen werden durch:
Meinen: Es ist die Summe aller Datenpunkte geteilt durch die Gesamtzahl der Werte im Datensatz. Dem Mittelwert kann man nicht immer vertrauen, da er von Ausreißern beeinflusst wird.
Median: Es ist der Zwischenwert eines geordneten Datensatzes / ordentlich. Wenn die Größe des Datensatzes gerade ist, der Median wird aus dem Durchschnitt der beiden Mittelwerte berechnet.
Weg: Es ist der am häufigsten wiederholte Wert im Datensatz. Daten mit nur einem Modus werden als unimodal bezeichnet, Daten mit zwei Modi werden als bimodal bezeichnet und Daten mit mehr als zwei Modi werden als multimodal bezeichnet.
4.2. Ausbreitungsmaße
(Auch als zweite Geschäftsentscheidung bekannt)
Sprechen Sie über die Verbreitung von Daten aus Ihrem Zentrum.
Dispersion kann gemessen werden mit:
Unterschied: Es ist der durchschnittliche quadrierte Abstand aller Datenpunkte von seinem Mittelwert. Das Problem mit der Varianz ist, dass die Einheiten auch quadrieren.
Standardabweichung: Es ist die Quadratwurzel der Varianz. Hilft bei der Wiederherstellung von Originallaufwerken.
Distanz: Es ist die Differenz zwischen den maximalen und minimalen Werten eines Datensatzes.
Messen |
Bevölkerung |
Zeigt an |
| Meinen | µ = (Xich)/NORDEN | x̄ = (xich)/Norden |
| Median | Der Mittelwert der Daten | Der Mittelwert der Daten |
| Weg | Meist aufgetretener Wert | Meist aufgetretener Wert |
| Unterschied | σ2 = (Xich – µ)2/NORDEN | S2 = (xich – x )2/ (n-1) |
| Standardabweichung | σ = Quadratwurzel ((Xich – µ)2/NORDEN) | s = Quadratwurzel ((xich – x )2/ (n-1)) |
| Distanz | Maximum Minimum | Maximum Minimum |
4.3. Schiefe
(Es ist auch als Geschäftsentscheidung im dritten Moment bekannt)
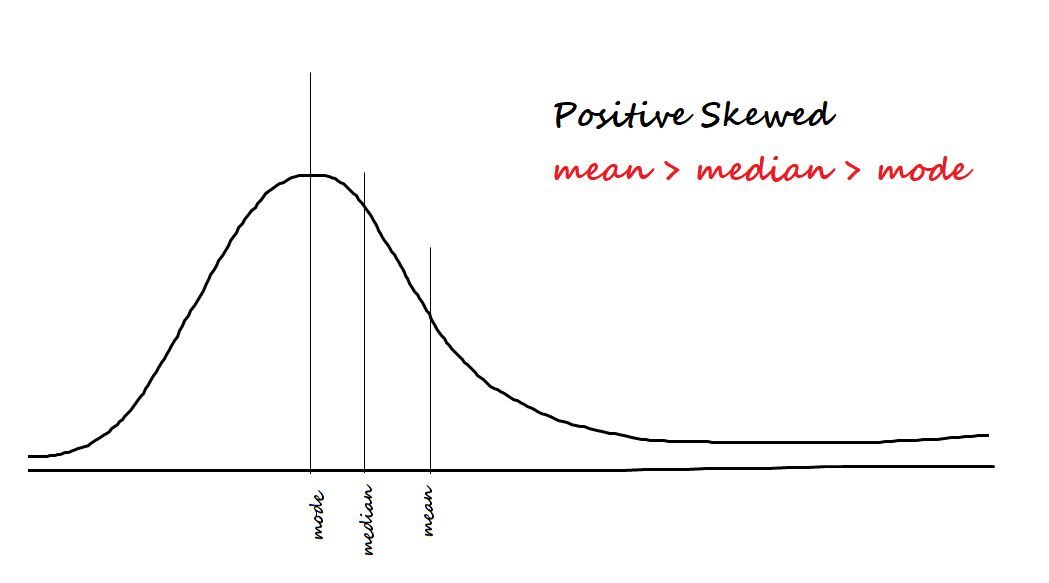
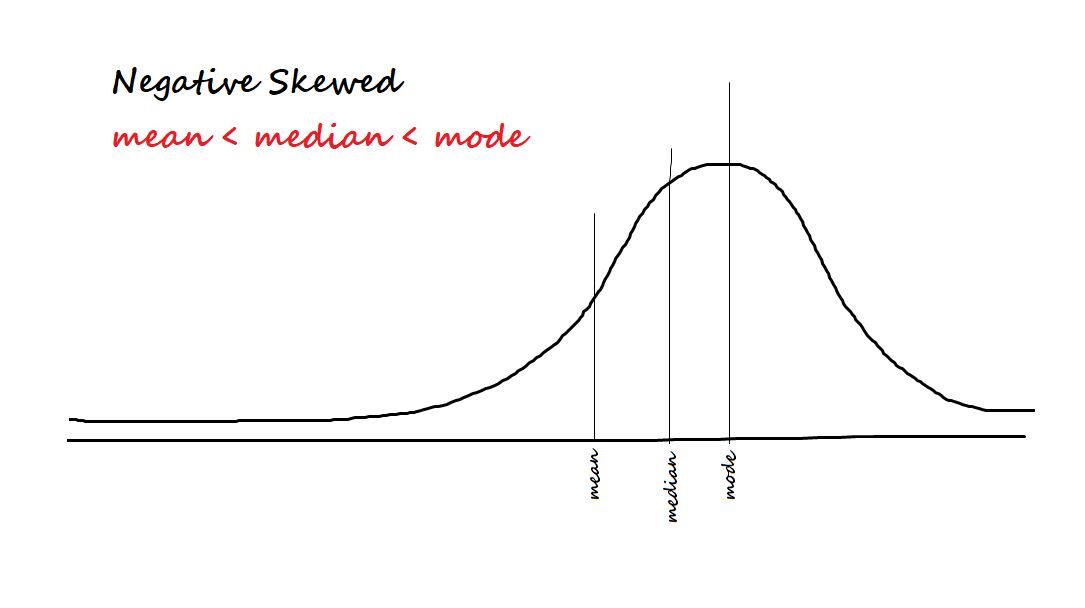
Schiefe in Daten messen. Die beiden Arten der Asymmetrie sind:
Positiv / nach rechts schief: Die Daten werden als positiv verzerrt bezeichnet, wenn die meisten Daten auf der linken Seite konzentriert sind und einen Schwanz nach rechts haben.
Negativ / nach links schief: Die Daten werden als negativ verzerrt bezeichnet, wenn die meisten Daten auf der rechten Seite konzentriert sind und einen Schwanz nach links haben.
Die Asymmetrieformel lautet mich [(X - µ)/ σ ]) 3 = Z3
4.4. Curtosis
(Auch bekannt als Geschäftsentscheidung im vierten Moment)
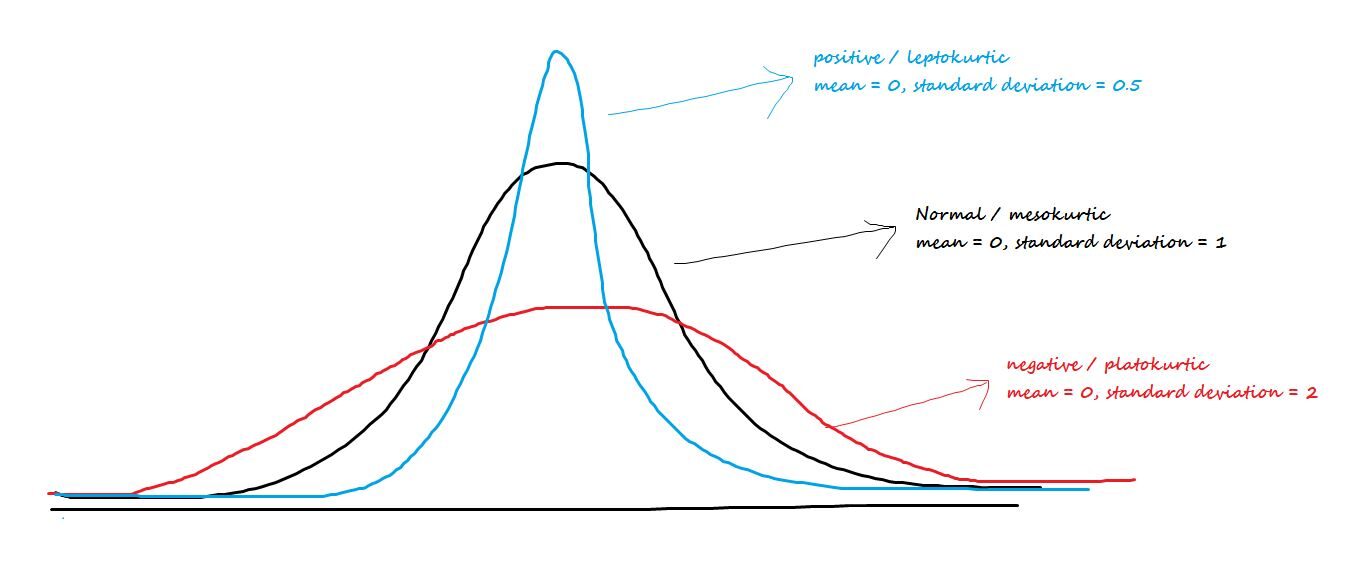
Sprechen Sie über die zentrale Spitze oder die Fülle der Schwänze. Die drei Arten von Kurtosis sind:
Positiv / leptokurtisch: Hat scharfe Schnäbel und leichtere Schwänze.
Negativ / Platokúrtico: Hat breite Schnäbel und dickere Schwänze.
mesokurtisch: Normalverteilung
Die Kurtosis-Formel lautet mich [(X - µ)/ σ ]) 4-3 = Z4– 3
Zusammen, Schiefe und Kurtosis werden als Formstatistiken bezeichnet.
5. Zentraler Grenzwertsatz (CLT)
Anstatt die Daten der gesamten Bevölkerung zu analysieren, wir nehmen immer eine Probe zur Analyse. Das Problem bei der Stichprobenziehung besteht darin, dass „der Stichprobenmittelwert eine Zufallsvariable ist“, variiert für verschiedene Proben". Und die von uns gezogene Zufallsstichprobe kann niemals eine exakte Darstellung der Bevölkerung sein. Dieses Phänomen wird als Stichprobenvariation bezeichnet.
So brechen Sie die Probenvariation ab, wir verwenden den zentralen Grenzwertsatz. Und nach dem zentralen Grenzwertsatz:
1. Die Verteilung der Stichprobenmittelwerte folgt einer Normalverteilung, wenn die Grundgesamtheit normal ist.
2. die Verteilung der Stichprobenmittelwerte folgt einer Normalverteilung, obwohl die Grundgesamtheit nicht normal ist. Aber die Stichprobengröße sollte groß genug sein.
3. Der große Durchschnitt aller Stichprobenmittelwerte gibt uns den Mittelwert der Grundgesamtheit.
4. Theoretisch, die Stichprobengröße sollte sein 30. Und praktisch, die Bedingung über die Stichprobengröße (n) es ist:
n> 10 (k3)2, wo k3 ist die Asymmetrie der Probe.
n> 10 (k4), wo K4 ist die Kurtosis-Probe.
6. Wahrscheinlichkeitsverteilungen
Statistisch gesehen, eine Verteilungsfunktion ist ein mathematischer Ausdruck, der die Wahrscheinlichkeit verschiedener möglicher Ergebnisse für ein Experiment beschreibt.
Bitte, Lesen Sie diesen Artikel von mir über die verschiedenen Arten von Wahrscheinlichkeitsverteilungen.
7. Grafische Darstellungen
Grafische Darstellung bezieht sich auf die Verwendung von Tabellen oder Grafiken zur Visualisierung, numerische Daten analysieren und interpretieren.
Für eine einzelne Variable (univariate Analyse), Wir haben ein Balkendiagramm, ein Liniendiagramm, ein Frequenzdiagramm, ein Punktplot, ein Boxplot und der normale QQ-Plot.
Wir besprechen den Boxplot und den normalen QQ-Plot.
7.1. Box-Plot
Ein Boxplot ist eine Möglichkeit, die Verteilung von Daten basierend auf einer Fünf-Zahlen-Zusammenfassung zu visualisieren. Wird verwendet, um Ausreißer in den Daten zu identifizieren.
Die fünf Zahlen sind das Minimum, erstes Quartil (Q1), Median (Q2), drittes Quartil (Q3) und maximal.
Die Box-Region enthält die 50% der Daten. Das 25% Der untere Teil des Datenbereichs wird als Bottom Whisker bezeichnet und der untere 25% Spitze der Datenregion heißt Top Whisker.
Die Interquartilsregion (IQR) ist die Differenz zwischen dem dritten und dem ersten Quartil. IQR = Q3 – Q1.
Ausreißer sind die Datenpunkte unterhalb des unteren Whiskers und jenseits des oberen Whiskers.
Die Formel zum Auffinden der Ausreißer lautet Ausreißer = Q ± 1,5 * (IQR)
Ausreißer unterhalb des unteren Whiskers werden als Q1 – 1,5 * (IQR)
Ausreißer jenseits des oberen Whiskers werden als Q3 + 1.5 * (IQR)
Siehe meinen Artikel zum Erkennen von Ausreißern mithilfe eines Boxplots.
7.2. Normales QQ-Diagramm
Ein normales QQ-Diagramm ist eine Art Streudiagramm, das durch Erstellen von zwei Sätzen von Quantilen erstellt wird.. Es wird verwendet, um zu überprüfen, ob die Daten normal sind oder nicht.
Auf der x-Achse haben wir die Z-Scores und auf der y-Achse haben wir die tatsächlichen Stichprobenquantile. Wenn das Streudiagramm eine gerade Linie bildet, die daten sollen normal sein.
8. Hypothesentest
Das Testen von Hypothesen in der Statistik ist eine Möglichkeit, Annahmen über Populationsparameter zu testen.
Siehe meinen Artikel über Hypothesentests, um ihn im Detail zu lesen.
Abschließende Anmerkungen:
Danke fürs Lesen bis zum Schluss. Am Ende dieses Artikels, wir kennen wichtige statistische Konzepte.
Ich hoffe dieser Artikel ist informativ. Teilen Sie es gerne mit Ihren Kommilitonen.
Andere Blogbeiträge von mir
Schauen Sie sich gerne auch meine anderen Blog-Beiträge von meinem DataPeaker-Profil an.
Du findest mich in LinkedIn, Twitter falls du dich verbinden möchtest. Ich würde mich gerne mit dir verbinden.
Für einen sofortigen Gedankenaustausch, schreibe mir [E-Mail geschützt].
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von DataPeaker und werden nach Ermessen des Autors verwendet.





