- Zähle die Werte jeder Klasse.
brain_df['Maske'].value_counts()

- Zufällig ein MRT-Bild aus dem Datensatz anzeigen.
image = cv2.imread(brain_df.image_path[1301]) plt.imshow(Bild)
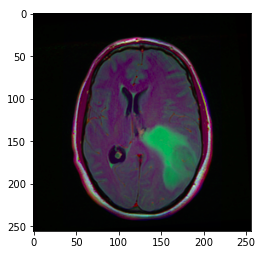
Image_path speichert den Pfad des Gehirn-MRT, damit wir das Bild mit Matplotlib anzeigen können.
Anregung: der grünliche Teil des obigen Bildes kann als Tumor angesehen werden.
- Was ist mehr, entsprechendes Maskenbild anzeigen.
image1 = cv2.imread(brain_df.mask_path[1301]) plt.imshow(Bild1)
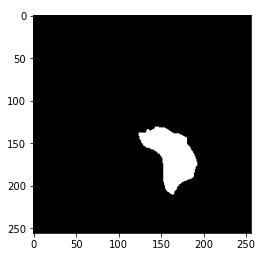
Jetzt, Sie haben vielleicht den Hinweis bekommen, was die Maske wirklich ist. Die Maske ist das Bild des von einem Tumor betroffenen Teils des Gehirns aus dem entsprechenden MRT-Bild. Hier, die Maske stammt aus dem oben gezeigten MRT des Gehirns.
- Analysieren Sie die Pixelwerte des Maskenbildes.
cv2.imread(brain_df.mask_path[1301]).max()
Abfahrt: 255
Der maximale Pixelwert im Maskenbild ist 255, was die weiße farbe anzeigt.
cv2.imread(brain_df.mask_path[1301]).Mindest()
Abfahrt: 0
Der minimale Pixelwert im Maskenbild ist 0, was die schwarze farbe anzeigt.
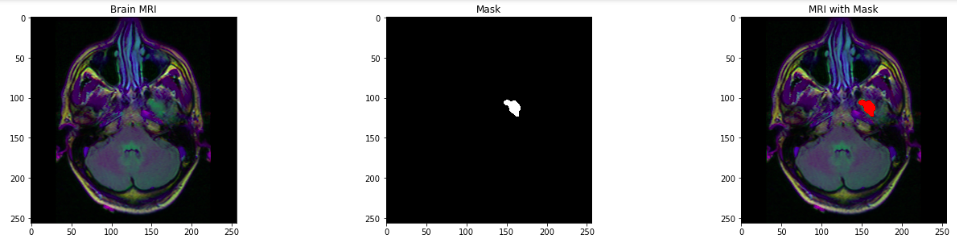
- Visualisierung der MRT des Gehirns, die entsprechende Maske und MRT mit der Maske.
zählen = 0
Feige, axs = plt.subplots(12, 3, Feigengröße = (20, 50))
für mich in Reichweite(len(brain_df)):
wenn brain_df['Maske'][ich] ==1 und zählen <5:
img = io.imread(brain_df.image_path[ich])
Achsen[zählen][0].title.set_text('Gehirn-MRT')
Achsen[zählen][0].imshow(img)
Maske = io.imread(brain_df.mask_path[ich])
Achsen[zählen][1].title.set_text('Maske')
Achsen[zählen][1].imshow(Maske, cmap = 'grau')
img[Maske == 255] = (255, 0, 0) #rote Farbe
Achsen[zählen][2].title.set_text('MRT mit Maske')
Achsen[zählen][2].imshow(img)
zählen+=1
fig.tight_layout()
- Identifikation entfernen, da für die Verarbeitung nicht erforderlich.
# Löschen Sie die Patienten-ID-Spalte brain_df_train = brain_df.drop(Spalten = ['Patienten ID']) brain_df_train.shape
Sie erhalten die Größe des Datenrahmens in der Ausgabe: (3929, 3)
- Konvertieren von Daten in der Maskenspalte vom Integer-Format in das String-Format, da wir die Daten im String-Format benötigen.
brain_df_train['Maske'] = brain_df_train['Maske'].anwenden(Lambda x: str(x)) brain_df_train.info()
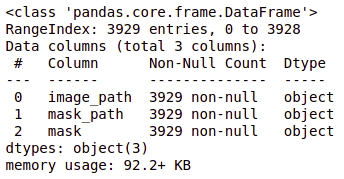
Wie du siehst, jetzt hat jedes Feature den Datentyp als Objekt.
- Teilen Sie die Daten in Test- und Train-Sets auf.
# Teilen Sie die Daten in Zug- und Testdaten auf aus sklearn.model_selection import train_test_split Bahn, test = train_test_split(brain_df_train, test_size = 0.15) |
- Erhöhen Sie mehr Daten mit ImageDataGenerator. ImageDataGenerator generiert Stapel von Spanner-Bilddaten mit Echtzeit-Datenerweiterung.
Verweisen hier für weitere Informationen zu ImageDataGenerator und Parametern im Detail.
Wir erstellen einen train_generator und einen validierungsgenerator aus den Zugdaten und einen test_generator aus den Testdaten.
# Erstellen Sie einen Bildgenerator from keras_preprocessing.image import ImageDataGenerator #Erstellen Sie einen Datengenerator, der die Daten aus skaliert 0 zu 1 und macht Validierungssplit von 0.15 datagen = ImageDataGenerator(neu skalieren=1./255., Validierung_split = 0.15) train_generator=datagen.flow_from_dataframe( Datenrahmen=Zug, Verzeichnis= './', x_col="Bildpfad", y_col ="Maske", Teilmenge="Ausbildung", batch_size=16, shuffle=Wahr, class_mode="kategorisch", target_size=(256,256)) valid_generator=datagen.flow_from_dataframe( Datenrahmen=Zug, Verzeichnis= './', x_col="Bildpfad", y_col ="Maske", Teilmenge="Validierung", batch_size=16, shuffle=Wahr, class_mode="kategorisch", target_size=(256,256)) # Erstellen Sie einen Datengenerator für Testbilder test_datagen=ImageDataGenerator(neu skalieren=1./255.) test_generator=test_datagen.flow_from_dataframe( dataframe=test, Verzeichnis= './', x_col="Bildpfad", y_col ="Maske", batch_size=16, shuffle=Falsch, class_mode="kategorisch", target_size=(256,256))





