Dieser Beitrag wurde im Rahmen der . veröffentlicht Data Science Blogathon.
Einführung
Unstrukturierte Daten enthalten eine große Menge an Informationen. Es ist wie Energie, wenn es genutzt wird, Schaffen Sie hohen Wert für Ihre Stakeholder. Mehrere Unternehmen arbeiten bereits intensiv in diesem Bereich. Es steht außer Frage, dass unstrukturierte Daten verrauscht sind und erhebliche Anstrengungen unternommen werden müssen, um sie zu bereinigen, analysieren Sie sie und machen Sie sie für Ihren Gebrauch sinnvoll. In diesem Beitrag geht es um einen Bereich, der bei der Analyse großer Datenmengen hilft, indem Inhalte zusammengefasst und interessante Themen identifiziert werden.: Keyword-Extraktion
Übersicht über die Keyword-Extraktion
Es ist eine Textanalysetechnik. Wir können uns in kurzer Zeit wichtiges Wissen zum Thema aneignen. Hilft, den Text zu prägnant und relevante Keywords zu erhalten. Sparen Sie sich die Zeit, das gesamte Dokument zu überprüfen. Beispielanwendungsfälle sind das Auffinden von interessanten Themen in einem Nachrichtenbeitrag und das Identifizieren von Problemen basierend auf Kundenfeedback, etc. Eine der Techniken zur Schlüsselwortextraktion ist TF-IDF (Terminierungsfrequenz – Belegfrequenz umkehren)
TF – IDF-Übersicht
Begriffshäufigkeit – Wie oft erscheint eine Definition in einem Text. Sie wird gemessen als die Häufigkeit, mit der eine Definition t im Text vorkommt / Gesamtzahl der Wörter im Dokument
Beleghäufigkeit umkehren – Wie relevant ist ein Wort in einem Dokument?. Als Log messen (Gesamtzahl der Sätze / Anzahl der Sätze mit Begriff t)
TF-IDF – Die Relevanz von Wörtern wird anhand dieser Punktzahl gemessen. Es wird als TF . gemessen * IDF
Wir werden das gleiche Konzept verwenden und versuchen, es Zeile für Zeile mit Python zu codieren. Wir werden einen kleineren Satz von Textdokumenten nehmen und alle oben genannten Schritte ausführen. Zwar gibt es bereits fortgeschrittenere Konzepte zur Keyword-Extraktion auf dem Markt, Dieser Beitrag zielt darauf ab, das grundlegende Konzept hinter der Identifizierung der Relevanz von Wörtern zu verstehen. Lass uns anfangen!
Implementierung
1. Pakete importieren
Wir müssen tokenisieren, um Wort-Token zu erstellen, itemgetter zum Sortieren des Wörterbuchs und Mathematik zum Ausführen der Log-Basis-e-Operation
von nltk import tokenize vom Operator import itemgetter Mathematik importieren
2. Variablen deklarieren
Wir werden eine String-Variable deklarieren. Es wird ein Platzhalter für das Beispieltextdokument sein.
doc="Ich bin Absolvent. Ich möchte Python lernen. Ich lerne gerne Python. Python ist einfach. Python ist interessant. Lernen fördert das Denken. Jeder sollte Zeit ins Lernen investieren"
3. Nimm die leeren Worte weg
Stoppwörter sind Wörter, die häufig vorkommen und für unsere Analyse möglicherweise nicht relevant sind.. Wir können die Verwendung der nltk-Bibliothek löschen
nltk importieren
aus nltk.corpus importieren Stoppwörter
aus nltk.tokenize import word_tokenize
stop_words = gesetzt(Stoppwörter.Wörter('Englisch'))
4. Finden Sie die Gesamtzahl der Wörter im Dokument.
Dies wird bei der Berechnung der Terminierungshäufigkeit benötigt
total_words = doc.split() total_word_length = len(total_words) drucken(total_word_length)
5. Berechnen Sie die Gesamtzahl der Sätze
Dies ist bei der Berechnung der inversen Häufigkeit des Dokuments erforderlich.
total_sentences = tokenize.sent_tokenize(doc) total_sent_len = len(total_sätze) drucken(total_sent_len)
6. Berechnen Sie TF für jedes Wort
Wir beginnen mit der Berechnung der Wortzahl für jedes Wort ohne anzuhalten und zum Schluss werden wir jedes Element durch das Ergebnis des Schrittes dividieren 4
tf_score = {}
für jedes_wort in total_words:
jedes_wort = jedes_wort.ersetzen('.','')
wenn jedes_wort nicht in stop_words ist:
wenn jedes_wort in tf_score:
tf_score[jedes Wort] += 1
anders:
tf_score[jedes Wort] = 1
# Dividieren durch total_word_length für jedes Wörterbuchelement
tf_score.update((x, j/int(total_word_length)) für x, y in tf_score.items())
drucken(tf_score)
7. Funktion, um zu überprüfen, ob das Wort in einer Liste von Phrasen vorhanden ist.
Diese Methode wird bei der Berechnung des IDF benötigt.
def check_sent(Wort, Sätze):
endgültig = [alle([w in x für w im Wort]) für x in Sätzen]
gesendet_len = [Sätze[ich] für mich in Reichweite(0, len(Finale)) wenn endgültig[ich]]
zurück int(len(gesendet_len))
8. Berechnen Sie die IDF für jedes Wort.
Wir verwenden die Funktion in Schritt 7 das Wort endlos zu wiederholen und das Ergebnis für die inverse Frequenz des Dokuments zu speichern.
idf_score = {}
für jedes_wort in total_words:
jedes_wort = jedes_wort.ersetzen('.','')
wenn jedes_wort nicht in stop_words ist:
if each_word in idf_score:
idf_score[jedes Wort] = check_sent(jedes Wort, total_sätze)
anders:
idf_score[jedes Wort] = 1
# Durchführen einer Protokollierung und Division
idf_score.update((x, math.log(int(total_sent_len)/
9. Kalkulatorischer TF * IDF
Da der Schlüssel beider Wörterbücher gleich ist, Wir können ein Wörterbuch iterieren, um die Schlüssel zu erhalten und die Werte von beiden zu multiplizieren
tf_idf_score = {Schlüssel: tf_score[Schlüssel] * idf_score.get(Schlüssel, 0) für Schlüssel in tf_score.keys()}
drucken(tf_idf_score)
10. Erstellen Sie eine Funktion, um N wichtige Wörter im Dokument zu erhalten
def get_top_n(dict_elem, n):
Ergebnis = dict(sortiert(dict_elem.items(), key = itemgetter(1), umgekehrt = wahr)[:n])
Ergebnis zurückgeben
11. Bekommen das 5 die wichtigsten worte
drucken(get_top_n(tf_idf_score, 5))
Fazit
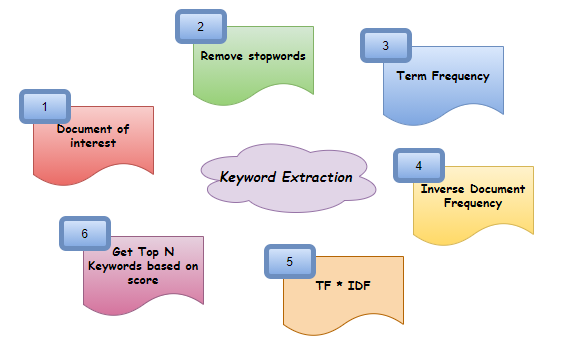
Dann, Dies ist eine der Möglichkeiten, wie Sie Ihren eigenen Keyword-Extraktor in Python erstellen können!! Die obigen Schritte lassen sich auf einfache Weise zusammenfassen als Dokument -> Stoppwörter löschen -> Termhäufigkeit suchen (TF) -> Finden Sie die Häufigkeit von Reverse-Dokumenten (IDF) -> Suche TF * IDF -> Top N Keywords abrufen. Teilen Sie Ihre Meinung mit, wenn dieser Beitrag interessant war oder Ihnen in irgendeiner Weise geholfen hat. Immer offen für Verbesserungen und Anregungen. Den Code findest du in GitHub





