Dieser Artikel wurde im Rahmen der Data Science Blogathon
Einführung:
Datenextraktion ist der Prozess des Extrahierens von Daten aus verschiedenen Quellen wie CSV-Dateien, Netz, PDF, etc. Obwohl in einigen Dateien, Daten können einfach wie in CSV extrahiert werden, während wir in Dateien wie unstrukturiertem PDF zusätzliche Aufgaben ausführen müssen, um Daten zu extrahieren.
Es gibt eine Reihe von Python-Bibliotheken, mit denen Sie Daten aus PDF-Dateien extrahieren können. Zum Beispiel, du kannst den ... benutzen PyPDF2 Bibliothek zum Extrahieren von Text aus PDF-Dateien, bei denen der Text sequentiell oder formatiert ist, nämlich, in Linien oder Formen. Sie können Tabellen auch über die Camelot Bücherei. In all diesen Fällen, Daten liegen in strukturierter Form vor, nämlich, sequentiell, Formulare oder Tabellen.
Aber trotzdem, In der echten Welt, die meisten Daten sind in keinem der Formulare vorhanden und es gibt keine Datenreihenfolge. Es liegt in einer unstrukturierten Form vor. In diesem Fall, Es ist nicht möglich, die oben genannten Python-Bibliotheken zu verwenden, da sie mehrdeutige Ergebnisse liefern. Um unstrukturierte Daten zu analysieren, wir müssen sie in eine strukturierte Form umwandeln.
Als solche, Es gibt keine spezielle Technik oder Prozedur, um Daten aus unstrukturierten PDF-Dateien zu extrahieren, da die Daten nach dem Zufallsprinzip gespeichert werden und dies von der Art der Daten abhängt, die Sie aus dem PDF extrahieren möchten.
Hier, Ich zeige Ihnen eine erfolgreichere Technik und Python-Bibliothek, mit der Sie Daten extrahieren können Begrenzungsrahmen in unstrukturierten PDF-Dateien und führen Sie dann den Datenbereinigungsvorgang an den extrahierten Daten durch und konvertieren Sie sie in ein strukturiertes Format.
PyMuPDF:
Ich habe die benutzt PyMuPDF Bibliothek zu diesem Zweck. Diese Bibliothek stellte viele Anwendungen bereit, So extrahieren Sie Bilder aus PDF, Texte auf unterschiedliche Weise extrahieren, Anmerkungen machen, Zeichnen Sie einen Begrenzungsrahmen um die Texte zusammen mit Bibliotheksfunktionen wie PyPDF2.
Jetzt, Ich zeige Ihnen, wie ich Daten aus Begrenzungsrahmen in einem PDF mit mehreren Seiten extrahiert habe.
Hier ist das PDF und die roten Begrenzungsrahmen, aus denen wir Daten extrahieren müssen.
Ich habe viele Python-Bibliotheken ausprobiert wie PyPDF2, PDFMiner, luciopdf, Camelot du tabellarisch. Aber trotzdem, keiner von ihnen hat funktioniert außer PyMuPDF.
Vor der Codeeingabe, Es ist wichtig, die Bedeutung von zu verstehen 2 wichtige Begriffe, die Ihnen helfen, den Code zu verstehen.
Wort: Zeichenfolge ohne Leerzeichen. Ex – Asche, 23, 2, 3.
Anmerkungen: eine Anmerkung verknüpft ein Objekt als Anmerkung, ein Bild oder ein Begrenzungsrahmen mit einer Position auf einer Seite eines PDF-Dokuments, oder bietet eine Möglichkeit, mit dem Benutzer über Maus und Tastatur zu interagieren. Objekte werden als Anmerkungen bezeichnet.
Beachten Sie, dass, in unserem Fall, Begrenzungsrahmen, Anmerkungen und Rechtecke sind gleich. Deswegen, diese Begriffe würden synonym verwendet.
Zuerst, Wir werden Text aus einem der Begrenzungsrahmen extrahieren. Dann werden wir das gleiche Verfahren verwenden, um Daten aus allen Bounding Boxes von PDF zu extrahieren.
Code:
fitz importieren
Pandas als pd importieren
doc = fitz.open('Mansfield--70-21009048 - ConvertToExcel.pdf ')
page1 = doc[0]
Wörter = page1.get_text("Wörter")
Zuerst, wir importieren die Fitz Modul der PyMuPDF Pandas Bibliothek und Bibliothek. Später, das PDF-Dateiobjekt wird erstellt und im Dokument gespeichert und die erste Seite des PDFs wird in der Seite gespeichert 1. page.get_text () extrahiere alle Wörter auf der Seite 1. Jedes Wort besteht aus einem Tupel mit 8 Elemente.
In variablen Worten, der erste 4 Elemente repräsentieren die Koordinaten des Wortes, das fünfte Element ist das Wort selbst, sechste, siebte, achte Elemente sind Blocknummern, Zeile und Wort, beziehungsweise.
PRODUKTION
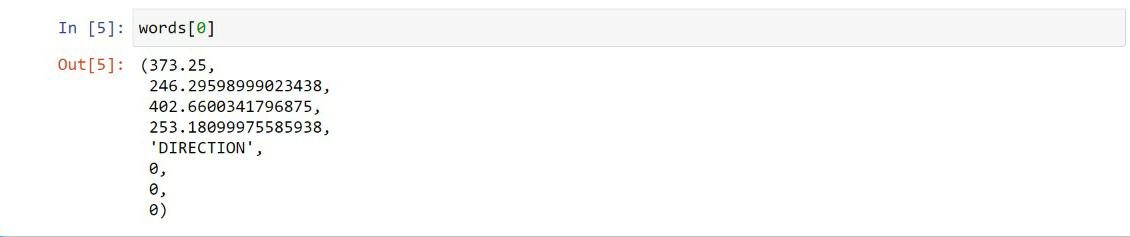
Extrahieren Sie die Koordinaten des ersten Objekts:
first_annots=[] rec=page1.first_annot.rect rec #Informationen zu Wörtern im ersten Objekt werden in mywords gespeichert mywords = [w für w in Worten wenn fitz.Rect(w[:4]) in rec] ann= make_text(meine Worte) first_annots.append(ann)
Diese Funktion wählt die Wörter aus, die in der Box enthalten sind, Sortiere die Wörter und kehre als String zurück:
def make_text(Wörter):
line_dict = {}
Wörter.sort(Schlüssel = Lambda w: w[0])
für w in Worten:
y1 = rund(w[3], 1)
Wort = w[4]
line = line_dict.get(y1, [])
line.append(Wort)
line_dict[y1] = Linie
Zeilen = Liste(line_dict.items())
Linien.sort()
Rückkehr "n".beitreten([" ".beitreten(Leitung[1]) für Zeile in Zeile])
PRODUKTION

page.first_annot () gibt die erste Anmerkung, nämlich, der Begrenzungsrahmen der Seite.
.rechts gibt die Koordinaten eines Rechtecks an.
Jetzt, wir haben die Koordinaten des Rechtecks und alle Wörter auf der Seite. Dann filtern wir die Wörter, die in unserer Bounding Box vorhanden sind, und speichern sie in meine Worte Variable.
Wir haben alle Wörter im Rechteck mit ihren Koordinaten. Aber trotzdem, diese Wörter sind in zufälliger Reihenfolge. Da wir den Text sequentiell brauchen und das nur Sinn macht, wir verwenden eine make_text-Funktion () die die Wörter zuerst von links nach rechts und dann von oben nach unten ordnet. Gibt den Text im String-Format zurück.
Hurra! Wir haben Daten aus einem Kommentar extrahiert. Unsere nächste Aufgabe besteht darin, Daten aus allen Anmerkungen im PDF zu extrahieren, was würde man mit dem gleichen ansatz machen.
Extrahieren jeder Seite des Dokuments und aller Anmerkungen / Rechtecke:
für Pageno in Reichweite(0,len(doc)-1):
Seite = Dokument[Seite Nummer]
Wörter = page.get_text("Wörter")
für annot in page.annots():
wenn annot!=Keine:
rec=annot.rect
mywords = [w für w in Worten wenn fitz.Rect(w[:4]) in rec]
ann= make_text(meine Worte)
all_annots.append(ann)
all_annots, eine Liste wird initialisiert, um den Text aller Anmerkungen im PDF zu speichern.
Die Funktion der äußeren Schleife im obigen Code besteht darin, jede Seite des PDFs zu durchlaufen, während die innere Schleife darin besteht, alle Anmerkungen auf der Seite zu überprüfen und die Aufgabe des Hinzufügens von Texten zur Liste all_annots wie oben beschrieben auszuführen.
Das Drucken von all_annots gibt uns den Text aller Anmerkungen des PDFs, die Sie unten sehen können.
PRODUKTION
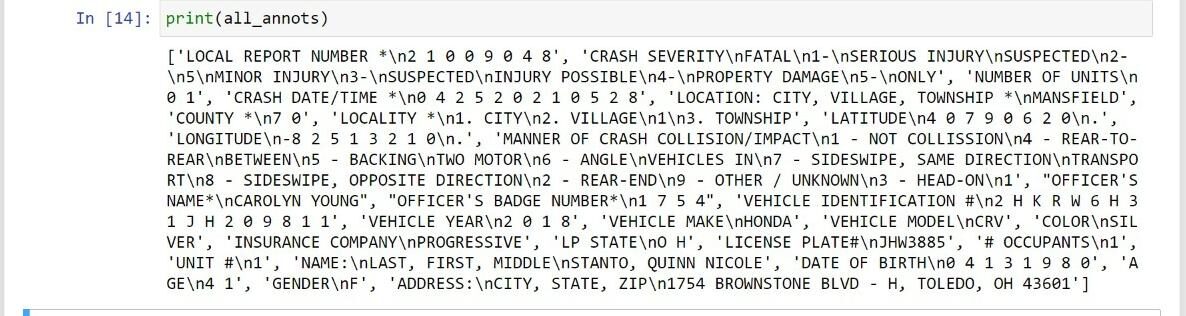
Schließlich, wir haben die Texte aller Anmerkungen extrahiert / Begrenzungsrahmen.
Es ist an der Zeit, die Daten zu bereinigen und auf verständliche Weise zu bringen.
Datenbereinigung und -verarbeitung
Dividieren, um den Spaltennamen und seine Werte zu bilden:
Fortsetzung =[]
für mich in Reichweite(0,len(all_annots)):
Fortsetzung anhängen(all_annots[ich].Teilt('n',1))
Entfernen Sie unnötige Symbole *, # ,:
liss=[]
für mich in Reichweite(0,len(Konto)):
lis=[]
für j in Fortsetzung[ich]:
j=j.ersetzen('*','')
j=j.ersetzen('#','')
j=j.ersetzen(':','')
j=j.streifen()
#drucken(J)
lis.anhängen(J)
liss.anhängen(lis)
In Schlüssel und Werte aufteilen und Leerzeichen in Werten entfernen, die nur Ziffern enthalten:
Schlüssel=[]
Werte=[]
für ich in liss:
Schlüssel.anhängen(ich[0])
Werte.anhängen(ich[1])
für mich in Reichweite(0, len(Werte)):
für j im Bereich(0,len(Werte[ich])):
wenn Werte[ich][J]>='A' und Werte[ich][J]<= 'Z':
brechen
wenn j==len(Werte[ich])-1:
Werte[ich]=Werte[ich].ersetzen(' ','')
Wir teilen jede Zeichenfolge basierend auf einem Zeilenumbruchzeichen (n) um den Spaltennamen von seinen Werten zu trennen. Durch Reinigung mehr, unnötige Symbole wie (*, #, 🙂. Leerzeichen zwischen den Ziffern werden entfernt.
Mit Schlüssel-Wert-Paaren, wir erstellen ein unten gezeigtes Wörterbuch:
Konvertierung in Wörterbuch:
berichten=diktieren(Postleitzahl(Schlüssel,Werte))
Prüfbericht['FAHRZEUG IDENTIFIKATION']= melden['FAHRZEUG IDENTIFIKATION'].ersetzen(‘ ‘,”)
dez =[Prüfbericht['LOKALITÄT'],Prüfbericht['ART DER ABSTURZKOLLISION/AUSWIRKUNG'],Prüfbericht['Crash-Schwere']]
l=0
val_after=[]
für lokal in dic:
li =[]
lii =[]
k=''
extrahieren=""
l=0
für mich in Reichweite(0,len(lokal)-1):
wenn lokal[ich+1]>='0' und lokal[ich+1]<='9':
li.anhängen(lokal[l:ich+1])
l = ich + 1
li.anhängen(lokal[l:])
drucken(Bei der)
für ich in li:
wenn ich[0] im lii:
k=i[0]
brechen
lii.anhängen(ich[0])
für ich in li:
wenn ich[0]==k:
extrahieren = ich
val_after.append(Extrakt) brechen Prüfbericht['LOKALITÄT']=val_after[0] Prüfbericht['ART DER ABSTURZKOLLISION/AUSWIRKUNG']=val_after[1] Prüfbericht['Crash-Schwere']=val_after[2]
PRODUKTION
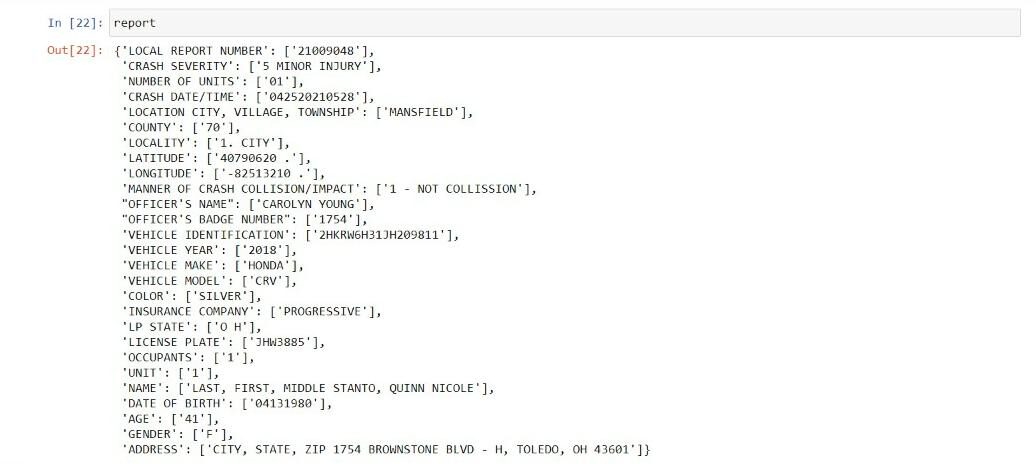
Schließlich, Wörterbuch wird mit Hilfe von Pandas in Datenrahmen umgewandelt.
In DataFrame konvertieren und in CSV exportieren:
data=pd.DataFrame.from_dict(Prüfbericht)
data.to_csv('final.csv',index=Falsch)
PRODUKTION
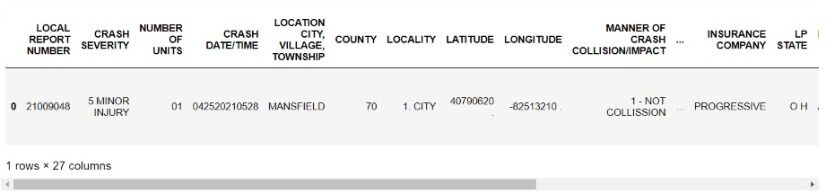
Jetzt, Wir können unsere strukturierten Daten analysieren oder nach Excel exportieren.
Ich wünsche Ihnen viel Spaß beim Lesen dieses Blogs und er gab Ihnen einen Einblick in den Umgang mit unstrukturierten Daten..
Verweise:
Empfohlene Bildquelle: Echtes Python https://realpython.com/python-data-engineer/
PyMuPDF-Dokumentation: https://pymupdf.readthedocs.io/en/latest/
Über den Autor:
Hi! Soja Ashish Choudhary. Ich studiere B.Tech an der JC Bose University of Science and Technology. Data Science ist meine Leidenschaft und ich bin stolz darauf, interessante Blogs zu diesem Thema zu schreiben. Zögern Sie nicht, mich über Linkedin zu kontaktieren linkedin.com/in/ashish-choudhary-7b6029166.
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von DataPeaker und werden nach Ermessen des Autors verwendet.





