In meinem vorherigen Artikel, „Kombinieren von Datensätzen in SAS – Vereinfacht“, wir analysieren drei Methoden, um Datensätze zu kombinieren: anfügen, verketten und zusammenführen. In diesem Artikel, Wir werden die gebräuchlichste und am häufigsten verwendete Methode zum Kombinieren von Datensätzen sehen: FUSION oder UNION.
Die Notwendigkeit, sich zu vereinen / Datensätze zusammenführen:
Bevor Sie ins Detail gehen, Lass uns verstehen, warum wir wirklich zusammenkommen müssen / verschmelzen. Wann immer wir Informationen haben, die in zwei oder mehr Datensätze aufgeteilt und verfügbar sind und wir sie in einem einzigen Datensatz kombinieren möchten, wir müssen fusionieren / schließe dich diesen Tabellen an. Eines der wichtigsten Dinge, die Sie beachten sollten, ist, dass die Zusammenführung auf gemeinsamen Kriterien oder Feldern basieren sollte. Zum Beispiel, in einem Einzelhandelsunternehmen, Wir haben eine Tabelle der täglichen Transaktionen (Tabelle enthält Produktdetails, Verkaufsdetails und Kundendetails) und eine Inventartabelle (mit Produktdetails und verfügbarer Menge). jedoch, um Informationen über den Lagerbestand oder die Verfügbarkeit eines Produkts zu erhalten, Was sollen wir machen? Combine la tabla TransaktionDas "Transaktion" bezieht sich auf den Prozess, durch den ein Austausch von Waren stattfindet, Dienstleistungen oder Geld zwischen zwei oder mehr Parteien. Dieses Konzept ist im wirtschaftlichen und rechtlichen Bereich von grundlegender Bedeutung, da es sich um eine gegenseitige Vereinbarung und die Berücksichtigung spezifischer Bedingungen handelt. Transaktionen können formell sein, als Verträge, oder informell, und sind für das Funktionieren der Märkte und Unternehmen von wesentlicher Bedeutung.... con la tabla Inventario basada en Product_Code y reste la cantidad vendida de la cantidad disponible.
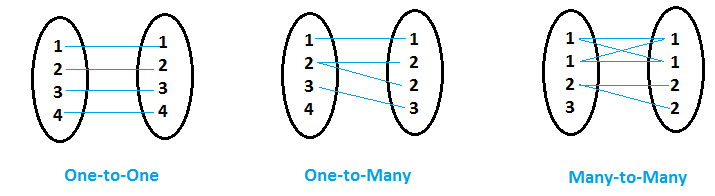
Die Fusion / union kann verschiedene Typen haben und hängt von den Geschäftsanforderungen und der Beziehung zwischen den Datensätzen ab. Zuerst, Sehen wir uns verschiedene Arten von Beziehungen an, die Datensätze haben können.
- Cuando para cada valor de VariableIn Statistik und Mathematik, ein "Variable" ist ein Symbol, das einen Wert darstellt, der sich ändern oder variieren kann. Es gibt verschiedene Arten von Variablen, und qualitativ, die nicht-numerische Eigenschaften beschreiben, und quantitative, numerische Größen darstellen. Variablen sind grundlegend in Experimenten und Studien, da sie die Analyse von Beziehungen und Mustern zwischen verschiedenen Elementen ermöglichen, das Verständnis komplexer Phänomene zu erleichtern.... gemeinsames (digamos Variable ‚x‘) im ersten Datensatz, el segundo conjunto de datos tiene solo un valor coincidente para esa variable común ‚x‘, dann heißt es Zwölf neunundfünfzig Beziehung.
- Wann für die Werte der gemeinsamen Variablen (digamos variable ‚Ja‘) im ersten Datensatz, otros conjuntos de datos tienen más de un valor coincidente para esa variable común ‚Ja‘, dann heißt es Einer zu vielen Beziehung.
- Wenn beide Datensätze mehrere Einträge für denselben gemeinsamen Variablenwert haben, dann heißt es Viel zu viel Beziehung.
Und SAS, Wir können Gewerkschaften gründen / Fusionen in verschiedenen Formen, hier werden wir die gängigsten Wege besprechen: Datenschritt y PROC SQL. Im Datenschritt, Wir verwenden die Merge-Anweisung, um Joins durchzuführen, während in PROC SQL, wir schreiben eine SQL-Abfrage. Lassen Sie uns zuerst den Datenpass analysieren:
DATENSCHRITTE
Syntax:- Datendatensatz; Zusammenführen Datensatz1 Datensatz2 Datensatz3 ...Datensatzn; Von CommonVariable1 CommonVariable2......CommonVariablen; Lauf;
Notiz: – Datensätze müssen nach Variablen sortiert werden (S) gebräuchlich und name, Typ und Länge der gemeinsamen Variablen müssen für alle Eingabedatensätze gleich sein.
Sehen wir uns einige Szenarien für jede der Beziehungen zwischen Eingabedatensätzen an.
EINS-zu-EINS-Beziehung
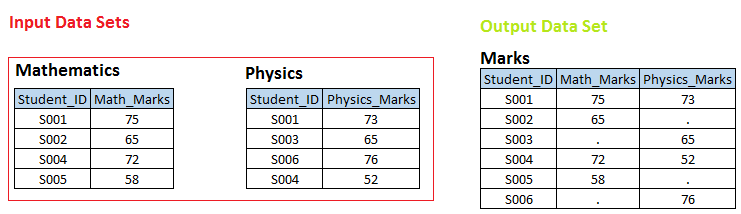
Bühne 1 In den folgenden Eingabedatensätzen, Sie können sehen, dass zwischen diesen beiden Tabellen eine Eins-zu-Eins-Beziehung besteht in Studenten ID. Jetzt wollen wir einen Datensatz erstellen. MARKEN, wo wir all die einzigartigen student_ids mit den jeweiligen Mathe- und Physiknoten haben. Wenn student_id in der Math-Tabelle nicht verfügbar ist, also sollte math_marks einen fehlenden Wert haben und umgekehrt.
Lösung mit Datenschritten: –
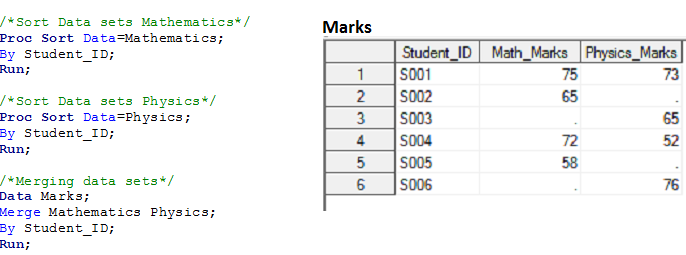
Wie funktioniert es:-
- SAS vergleicht beide Datensätze und erstellt einen POS (Programmdatenvektor) für alle eindeutigen Variablen und initialisiert sie mit fehlenden Werten (der Programmdatenvektor ist ein Vermittler zwischen den Eingabe- und Ausgabedatensätzen). Im aktuellen Beispiel, Ich würde so einen POV erstellen:

- Lesen Sie die erste Beobachtung aus den Eingabedatensätzen und vergleichen Sie die Werte der BY-Variablen in beiden Datensätzen:
- wenn die Werte gleich sind, es wird mit dem Wert der BY-Variablen in POS verglichen.
- wenn nicht gleich, die POV-Variablen werden mit den fehlenden Werten zurückgesetzt und der aktuelle Beobachtungswert wird in den POV kopiert, während die andere Beobachtung verloren bleibt
- Wenn es das gleiche ist, POS-Variablen werden nicht neu initialisiert. Der verfügbare Wert der aktuellen Beobachtung wird im POS aktualisiert
- Danach, der Datensatzzeiger bewegt sich in beiden Datensätzen zur nächsten Beobachtung und, während der RUN-Befehl ausgeführt wird, PDV-Werte werden an den Ausgangsdatensatz übergeben.
- Wenn der Wert der Variablen By nicht übereinstimmt, die Beobachtung des Datensatzes mit dem niedrigsten Wert wird nach POS . kopiert. Der Datensatzzeiger des Datensatzes mit einem niedrigeren BY-Variablenwert wird zur nächsten Beobachtung und zum nächsten Schritt verschoben 2 (ein) wiederholt sich noch einmal.
- wenn die Werte gleich sind, es wird mit dem Wert der BY-Variablen in POS verglichen.
- Die obigen Schritte werden wiederholt, bis der EOF beider Datensätze erreicht ist.
Sie können einen Versuch durchführen, um den Ergebnisdatensatz auszuwerten.
Bühne 2: – Basierend auf den Eingabedatensätzen des Szenarios 1, wir wollen die folgenden Ausgabedatensätze erstellen.
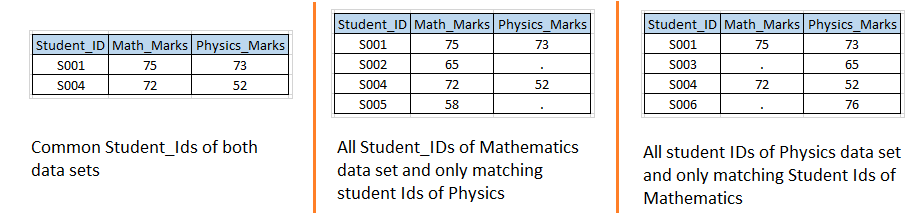
Lösung mit Datenschritten: – Schreiben wir einen Code ähnlich dem Szenario 1 mit der IN-Option. 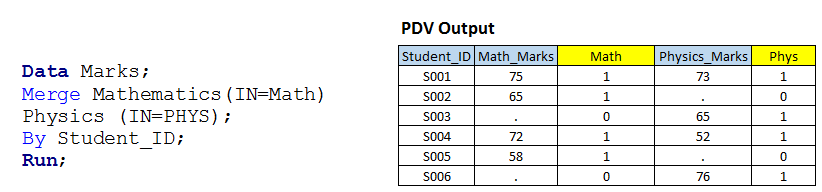 Über, Sie können sehen, dass wir die Option IN bei beiden Eingabedatensätzen verwendet und diesen den temporären Variablen MATH und PHYS Werte zugewiesen haben, da es sich um temporäre Variablen handelt, Daher können wir sie im Ausgabe-Dataset nicht sehen.
Über, Sie können sehen, dass wir die Option IN bei beiden Eingabedatensätzen verwendet und diesen den temporären Variablen MATH und PHYS Werte zugewiesen haben, da es sich um temporäre Variablen handelt, Daher können wir sie im Ausgabe-Dataset nicht sehen.
Ich habe dir die Tabelle gezeigt (PDV-Daten) die einen Variablenwert für alle Beobachtungen hat, zusammen mit den temporären Variablen. Jetzt, basierend auf dem Wert dieser Variablen, podemos escribir un código para las operaciones de subconfiguración y BEITRETEN"BEITRETEN" ist ein grundlegender Vorgang in Datenbanken, der es Ihnen ermöglicht, Datensätze aus zwei oder mehr Tabellen basierend auf einer logischen Beziehung zwischen ihnen zu kombinieren. Es gibt verschiedene Arten von JOIN, als INNER JOIN, LINKER JOIN und RECHTER JOIN, Jede mit ihren eigenen Eigenschaften und Verwendungsmöglichkeiten. Diese Technik ist unerlässlich für komplexe Abfragen und relevantere und detailliertere Informationen aus mehreren Datenquellen.... según lo necesitemos:
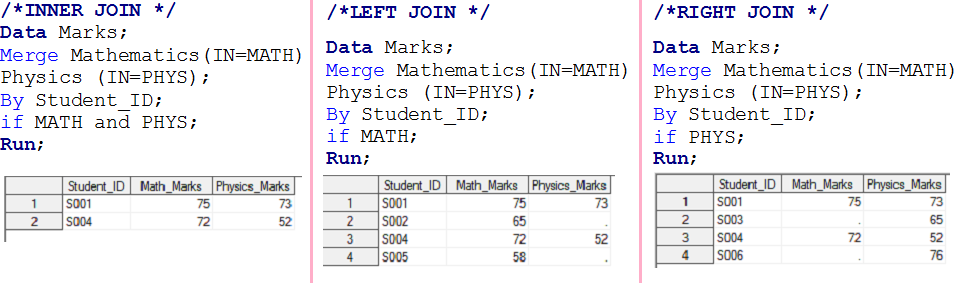
- Wenn MATH und PHYS einen Wert haben 1, creará el primer conjunto de datos de salida y se llamará INNERE VERKNÜPFUNGein "Innere Verknüpfung" ist ein Vorgang in Datenbanken, der es Ihnen ermöglicht, Zeilen mit zwei oder mehr Tabellen zu kombinieren., basierend auf einer bestimmten Übereinstimmungsbedingung. Diese Art der Verknüpfung gibt nur Zeilen zurück, die Entsprechungen in beiden Tabellen aufweisen, Dies führt zu einem Resultset, das nur die zugehörigen Daten widerspiegelt. Bei SQL-Abfragen ist es von entscheidender Bedeutung, zusammenhängende und genaue Informationen aus mehreren Datenquellen zu erhalten.....
- Wenn MATH hat 1, creará un segundo conjunto de datos de salida y se llamará LINKER JOINDas "LINKER JOIN" ist eine Operation in SQL, die es Ihnen ermöglicht, Zeilen aus zwei Tabellen zu kombinieren, Anzeige aller Zeilen in der linken Tabelle und Übereinstimmungen in der rechten Tabelle. Wenn es keine Übereinstimmungen gibt, werden mit NULL-Werten gefüllt. Dieses Tool ist nützlich, um vollständige Informationen zu erhalten, Auch wenn einige Beziehungen optional sind, So wird die Datenanalyse auf effiziente und konsistente Weise erleichtert.....
- Wenn PHYS hat 1, creará un tercer conjunto de datos de salida y se llamará como RECHTS BEITRETENDas "RECHTS BEITRETEN" ist ein Vorgang in Datenbanken, der es Ihnen ermöglicht, Zeilen aus zwei Tabellen zu kombinieren, Sicherstellen, dass alle Zeilen in der Tabelle auf der rechten Seite in das Ergebnis einbezogen werden, Auch wenn in der Tabelle links keine Treffer vorhanden sind. Dieser Verknüpfungstyp ist nützlich, um Informationen aus der sekundären Tabelle beizubehalten, was es einfach macht, vollständige Daten in SQL-Abfragen zu analysieren und zu erhalten....
- Wenn MATH und PHYS haben 1, funcionará como VOLLSTÄNDIGER BEITRITTDas "VOLLSTÄNDIGER BEITRITT" ist ein Datenbankvorgang, der die Ergebnisse von zwei Tabellen kombiniert, Anzeige aller Datensätze für beide. Wenn es Zufälle gibt, Daten werden kombiniert, Es werden aber auch Datensätze berücksichtigt, die keine Entsprechung in der anderen Tabelle haben, Abschließen mit NULL-Werten. Diese Technik ist nützlich, um einen vollständigen Überblick über die Informationen zu erhalten, Dies ermöglicht eine umfassendere Analyse der Daten in Bezug auf...., wurde auch auf Stufe 1 gelöst.
EINS-zu-viele-Beziehung
Bühne – 3 Hier haben wir zwei Datensätze, Student Ja Prüfung und wir wollen einen Satz von Ausgabedaten erstellen Warenzeichen.
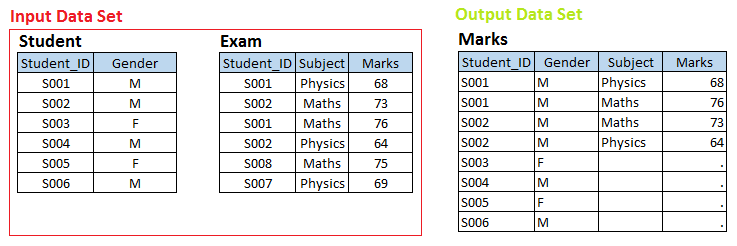
Zusätzlich zu den Eingabedatensätzen, Es besteht eine Eins-zu-Viele-Beziehung zwischen dem Studenten und der Prüfung. Jetzt, wenn Sie Ausgabedatensatznoten mit individueller Beobachtung für jede Schülerprüfung erstellen möchten, diese gehören zum STUDENT-Datensatz, nämlich, Union links.
Lösung mit Datenschritten: –
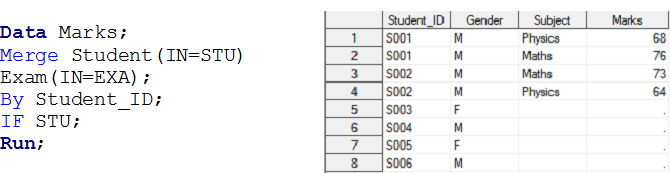
Ähnlich, wir können Operationen für Inner Join durchführen, richtig und vollständig für eine 1:n-Beziehung mit dem IN-Operator.
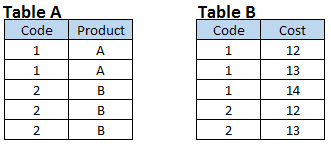
Verhältnis VIELE zu VIELE
Bühne 4: Erstellen Sie Ausgabedatensätze, die alle Joins basierend auf einem gemeinsamen Feld enthalten. Sie können auch sehen, dass beide Eingabedatensätze eine Viele-zu-Viele-Beziehung aufweisen.
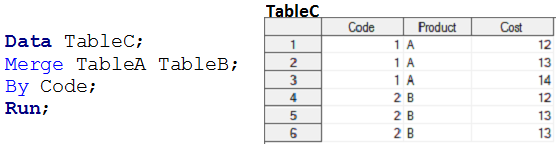
Datenschritte bilden keine VIELE-zu-MANY-Beziehung, weil sie keine Ausgabe als kartesisches Produkt liefern. Wenn wir Tabelle A und Tabelle B mithilfe von Datenschritten zusammenführen, die Ausgabe ähnelt dem folgenden Schnappschuss.
 Wir haben schon gesehen, Wie können wir Datenschritte verwenden, um zwei oder mehr Datensätze zusammenzuführen, die eine der Beziehungen aufweisen?, außer VIELE bis VIELE? Jetzt werden wir die PROC SQL-Methoden sehen, um eine Lösung für ähnliche Anforderungen zu haben.
Wir haben schon gesehen, Wie können wir Datenschritte verwenden, um zwei oder mehr Datensätze zusammenzuführen, die eine der Beziehungen aufweisen?, außer VIELE bis VIELE? Jetzt werden wir die PROC SQL-Methoden sehen, um eine Lösung für ähnliche Anforderungen zu haben.
PROC-SQL
Verstehen der Join-Methodik in SQL, wir müssen zuerst das kartesische Produkt verstehen. Das kartesische Produkt ist eine Abfrage, die mehrere Tabellen in der from-Klausel enthält und alle möglichen Kombinationen von Zeilen aus den Eingabetabellen erzeugt. Wenn wir zwei Tische haben mit 2 Ja 4 Datensätze bzw, mit dem kartesischen Produkt, wir haben einen tisch mit 2 x 4 = 8 Aufzeichnungen.
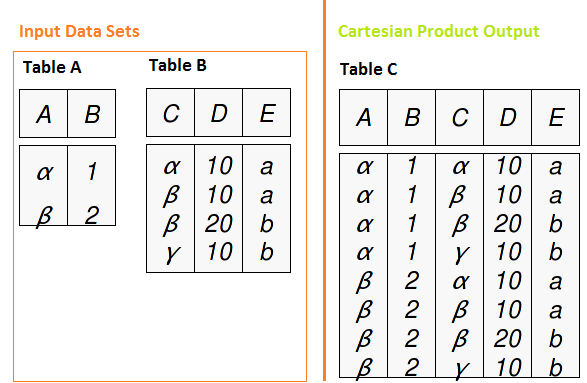
SQL-Joins funktionieren für jede der Beziehungen zwischen Datensätzen (Einer nach dem anderen, eins zu vielen und viele zu vielen). Mal sehen, wie es mit Join-Typen funktioniert.
Syntax:-
Bitte auswählen Spalte-1, Spalte-2,… Spalte-n von Tabelle1 INNENVERBINDUNG / LINKS / RECHTS / KOMPLETTcapaz2 AUF Join-Bedingung ;
Notiz:-
- Tabellen können nach allgemeinen Variablen geordnet sein oder nicht.
- Der Name der gemeinsamen Variablen darf nicht ähnlich sein, aber es muss in Länge und Art ähnlich sein.
- Funktioniert mit maximal zwei Tabellen.
Lassen Sie uns die obigen Anforderungen mit PROC SQL lösen.
Bühne 1 :- Dies war ein Beispiel für FULL Join, wobei alle Student_IDs im Ausgabedatensatz mit den entsprechenden MATH- und PHYSICS-Flags erforderlich waren.

Oben im Ausgabedatensatz, Sie können sehen, dass die Student_ID für diejenigen Studenten fehlt, die nur zur Physikprüfung erschienen sind. Um es zu lösen, verwenden wir eine COALESCE-Funktion. Gibt den Wert des ersten Arguments zurück, das in den angegebenen Variablen nicht fehlt.
Syntax:-
VERSCHMELZEN (Argument-1, Argument-2,… ..Argument-n)
Lassen Sie uns den obigen Code ändern: –
Bühne 2: – Dies war ein Beispiel für INNER, Links und Rechts Join. Hier lösen wir für Inner Join. Auf die gleiche Weise, Wir können für die linke und rechte Kreuzung tun.
Auf die gleiche Weise, Wir können für die linke und rechte Kreuzung tun.
Bühne -3 Dies war ein Link-Join-Problem für eine ONE-to-MANY-Beziehung.
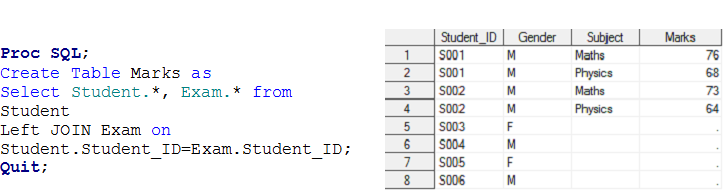
Bühne -4 Das war ein Viele-zu-Viele-Beziehungsproblem. Wir haben bereits besprochen, dass SQL ein kartesisches Produkt erzeugen kann, das alle Kombinationen von Datensätzen zwischen zwei Tabellen enthält.

Oben haben wir gesehen, wie Proc SQL beitritt / Datensätze zusammenführen.
Schlussbemerkung: –
In dieser Artikelserie zum Kombinieren von Datensätzen in SAS, Wir analysieren verschiedene Methoden, um Datensätze zu kombinieren, wie z. B. das Addieren, verketten, verschmelzen, Sicherung. Besonders in diesem Artikel, wir diskutieren das in Abhängigkeit von der Beziehung zwischen den Datensätzen, verschiedene Arten von Joins und wie wir sie basierend auf verschiedenen Szenarien lösen können. Wir haben zwei Methoden verwendet (Datenschritte y PROC SQL) Ergebnisse erzielen. Die Effizienz dieser Methoden werden wir in einem der zukünftigen Artikel sehen..
Hat dir diese Serie geholfen? Wir haben ein komplexes Thema wie das Kombinieren von Datensätzen vereinfacht und versucht, es verständlich darzustellen. Wenn Sie weitere Hilfe beim Kombinieren von Datensätzen benötigen, Fühlen Sie sich frei, Ihre Fragen in den Kommentaren unten zu stellen.
PS Bist du beigetreten? Analytische Vidhya-Diskussion noch? Wenn dies nicht der Fall ist, Viele Data-Science-Debatten gehen verloren. Dies sind einige der Diskussionen, die in SAS . stattfinden:
1. Wählen Sie Variablen aus und übertragen Sie sie in einen neuen Datensatz in SAS
2. Importieren Sie die erste 20 Datensätze von Excel zu SAS
3. Wenn die Anweisung in SAS nicht funktioniert





