Dieser Artikel wurde im Rahmen der Data Science Blogathon
Imputation ist eine Technik, die verwendet wird, um fehlende Daten durch einen Ersatzwert zu ersetzen, um die meisten Daten zu behalten / Datensatzinformationen. Diese Techniken werden verwendet, weil es nicht möglich ist, jedes Mal die Daten aus dem Datensatz zu entfernen und die Größe des Datensatzes stark reduzieren kann., was nicht nur Bedenken hinsichtlich einer Verzerrung des Datensatzes aufwirft, es führt auch zu falschen Analysen.
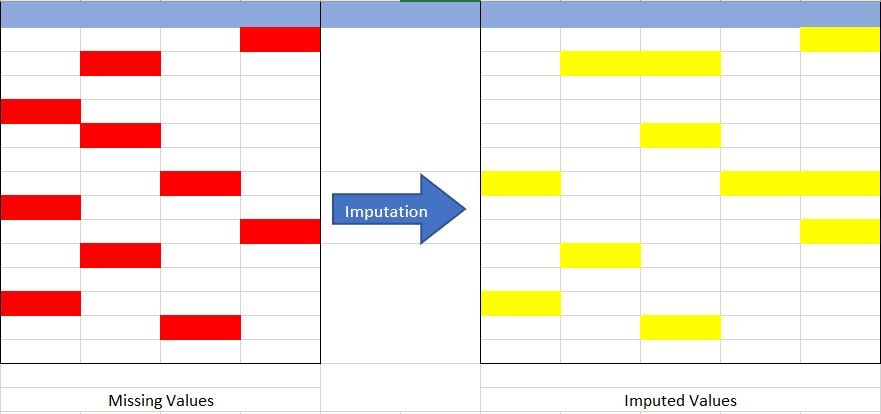
Quelle: erstellt vom Autor
Nicht sicher, welche Daten fehlen? Wie geht es? Und dein Typ? Schaut HIER vorbei um mehr darüber zu erfahren.
Lassen Sie uns das Konzept der Imputation aus Abb. verstehen {Feige 1} anterior. Im Bild oben, Ich habe versucht, die fehlenden Daten in der Tabelle links darzustellen (rot markiert) und mit Imputationstechniken haben wir den fehlenden Datensatz in der Tabelle rechts vervollständigt (gelb markiert), ohne die tatsächliche Größe des Datensatzes zu reduzieren. Wenn wir hier erkennen, wir haben die spalte vergrößert, was ist in der anrechnung möglich (Hinzufügen der Kategorie Imputation “Mangel”).
Warum ist Imputation wichtig?
Dann, nach Kenntnis der Definition von Imputation, Die nächste Frage ist, warum sollten wir es verwenden und was würde passieren, wenn ich es nicht benutze??
Hier gehen wir mit den Antworten auf die vorherigen Fragen.
Wir verwenden Imputation, da fehlende Daten zu folgenden Problemen führen können: –
- Inkompatibel mit den meisten Python-Bibliotheken, die in Machine Learning verwendet werden: – Jawohl, du liest gut. Bei Verwendung der Bibliotheken für ML (am häufigsten ist skLearn), haben keine Vorkehrungen, diese fehlenden Daten automatisch zu verarbeiten und können Fehler generieren.
- Verzerrung im Datensatz: – Eine große Menge fehlender Daten kann zu Verzerrungen in der Verteilung der Variablen führen, nämlich, kann den Wert einer bestimmten Kategorie im Datensatz erhöhen oder verringern.
- Beeinflusst das endgültige Modell: – fehlende Daten können Verzerrungen im Datensatz verursachen und zu einer fehlerhaften Analyse durch das Modell führen.
Ein weiterer und wichtigster Grund ist “Wir wollen den kompletten Datensatz wiederherstellen”. Dies geschieht hauptsächlich in dem Fall, in dem wir nicht verlieren möchten (Plus) Daten aus unserem Datensatz, da alle wichtig sind und, Zweitens, die Größe des Datensatzes ist nicht sehr groß und das Entfernen eines Teils davon kann erhebliche Auswirkungen haben. im fertigen Modell.
Exzellent..!! Wir haben einige Grundlagen zu fehlenden Daten und Imputationen erhalten. Jetzt, Schauen wir uns die verschiedenen Imputationstechniken an und vergleichen sie. Aber bevor ich mich darauf einlasse, wir müssen die Datentypen in unserem Datensatz kennen.
Es klingt seltsam..!!! Keine Sorge ... Die meisten Daten stammen von 4 Typen: – Numerisch, Kategorisch, Datum-Uhrzeit und gemischt. Diese Namen sind selbsterklärend, also vertiefen sie nicht viel oder beschreiben sie.
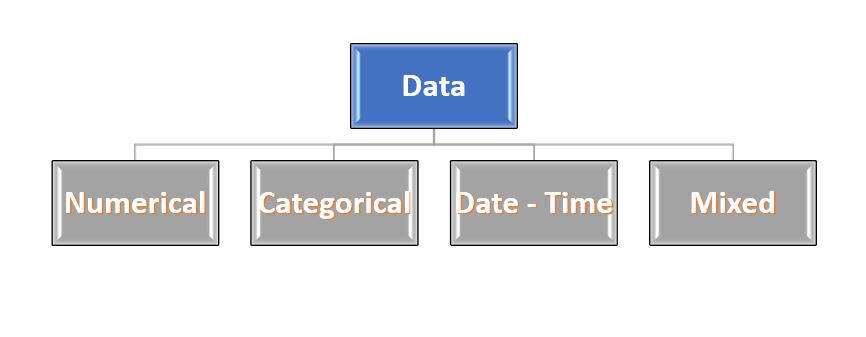
Feige 2: – Art der Daten
Quelle: erstellt vom Autor
Imputationstechniken
Weiter zu den Highlights dieses Artikels … Techniken der Imputation …
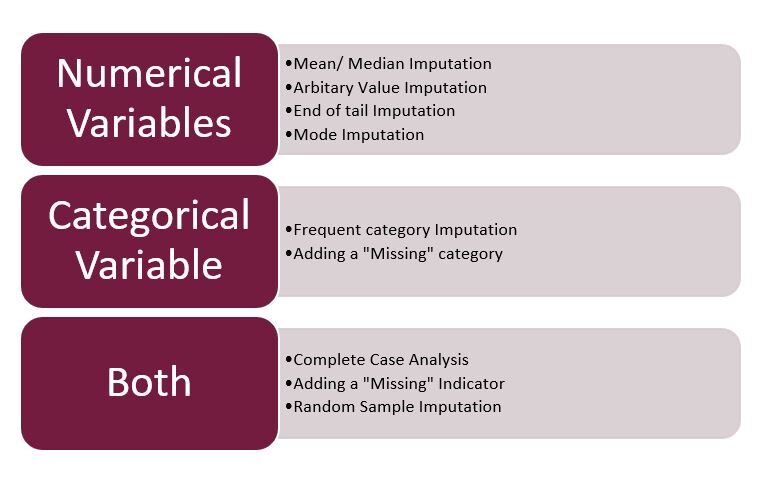
Feige 3: – Imputationstechniken
Quelle: erstellt vom Autor
Notiz: – Hier konzentriere ich mich ausschließlich auf die gemischte Imputation, numerisch und kategorisch. Das Datum und die Uhrzeit werden Teil des nächsten Artikels sein.
1. Vollständige Fallanalyse (CCA): –
Dies ist eine ziemlich einfache Methode, um mit fehlenden Daten umzugehen, wodurch die Zeilen mit fehlenden Daten direkt entfernt werden, nämlich, wir betrachten nur die Zeilen, in denen wir vollständige Daten haben, nämlich, keine fehlenden Daten. Diese Methode ist im Volksmund auch bekannt als “nach Liste löschen”.
- Annahmen: –
- Zufallsdaten fehlen (BESCHÄDIGEN).
- Fehlende Daten werden komplett aus der Tabelle entfernt.
- Vorteil: –
- Einfach zu implementieren.
- Keine Datenmanipulation erforderlich.
- Einschränkungen: –
- Gelöschte Daten können informativ sein.
- Es kann zur Löschung vieler Daten führen.
- Sie können einen Bias im Dataset erstellen, wenn eine große Menge eines bestimmten Variablentyps entfernt wird.
- Das Produktionsmodell wird mit den fehlenden Daten nichts anfangen können.
- Wann verwenden:-
- Die Daten sind MAR (Fehlt zufällig).
- Gut für gemischte Daten, numerisch und kategorisch.
- Die fehlenden Daten sind nicht mehr als 5% bis 6% des Datensatzes.
- Die Daten enthalten nicht viele Informationen und verzerren den Datensatz nicht.
- Code:-
## So überprüfen Sie die Form des ursprünglichen Datensatzes
train_df.shape
## Ausgabe (614 Reihen & 13 Säulen) (614,13)
## Suchen der Spalten mit Nullwerten(Fehlende Daten) ## Wir verwenden eine for-Schleife für alle im Datensatz vorhandenen Spalten mit durchschnittlichen Nullwerten größer als 0
na_variable = [ var für var in train_df.columns wenn train_df[wo].ist Null().bedeuten() > 0 ]
## Ausgabe von Spaltennamen mit Nullwerten ['Geschlecht','Verheiratet','Abhängige','Selbstständiger','Darlehensbetrag','Loan_Amount_Term','Kredit Geschichte']
## Wir können auch die mittleren Nullwerte in diesen Spalten sehen {Im Bild unten gezeigt}
data_na = trainf_df[na_variables].ist Null (). bedeuten ()
## Implementieren der CCA-Techniken zum Entfernen fehlender Daten data_cca = train_df(Achse=0) ### Achse=0 wird zur Angabe von Zeilen verwendet
## Überprüfen der endgültigen Form des verbleibenden Datensatzes data_cca.shape
## Ausgabe (480 Reihen & 13 Säulen) (480,13)
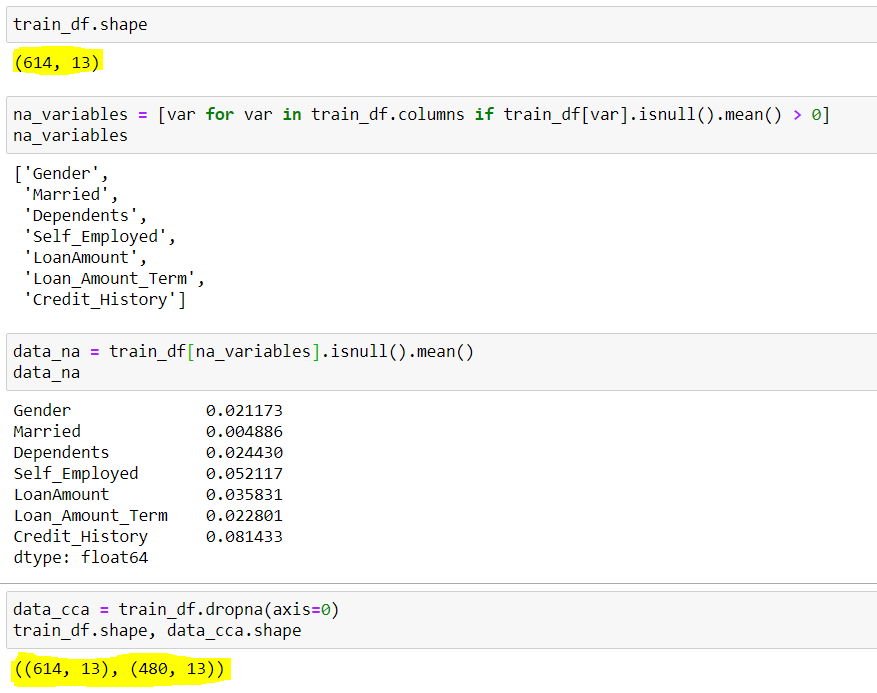
Abbildung 3: – CCA
Quelle: Erstellt vom Autor
Hier können wir sehen, der Datensatz hatte anfangs 614 Reihen und 13 Säulen, von welchem 7 Zeilen hatten fehlende Daten(Variablen_Variablen), seine fehlenden mittleren Reihen werden durch angezeigt data_na. Das haben wir beobachtet, abgesehen von und , alle haben einen durchschnittlichen niedrigeren als 5%. Dann, nach CCA, Wir entfernen die Zeilen mit fehlenden Daten, was zu einem Datensatz mit nur 480 Reihen. Hier können Sie sich um die 20% der Datenreduktion, was in Zukunft viele Probleme bereiten kann.
2. Willkürliche Wertanrechnung
Dies ist eine wichtige Technik, die bei der Imputation verwendet wird, da es sowohl numerische als auch kategoriale Variablen verarbeiten kann. Diese Technik besagt, dass wir die fehlenden Werte in einer Spalte gruppieren und sie einem neuen Wert zuweisen, der weit außerhalb des Bereichs dieser Spalte liegt. Allgemein, wir verwenden Werte wie 99999999 Ö -9999999 Ö “Mangel” Ö “Nicht definiert” für numerische und kategoriale Variablen.
- Annahmen: –
- Daten fehlen nicht zufällig.
- Fehlende Daten werden mit einem willkürlichen Wert imputiert, der nicht Teil des Datensatzes oder des Mittelwerts ist / Median / Daten Mode.
- Vorteil: –
- Einfach zu implementieren.
- Wir können es in der Produktion verwenden.
- Bewahrt die Bedeutung von “fehlende Werte” wenn es existiert.
- Nachteile: –
- Sie können die Verteilung der ursprünglichen Variablen verzerren.
- Beliebige Werte können Ausreißer erzeugen.
- Bei der Auswahl des willkürlichen Wertes ist besondere Vorsicht geboten.
- Wann verwenden:-
- Wenn die Daten nicht MAR . sind (Fehlt zufällig).
- fit für alle.
- Code:-
## Suchen der Spalten mit Nullwerten(Fehlende Daten) ## Wir verwenden eine for-Schleife für alle im Datensatz vorhandenen Spalten mit durchschnittlichen Nullwerten größer als 0
na_variable = [ var für var in train_df.columns wenn train_df[wo].ist Null().bedeuten() > 0 ]
## Ausgabe von Spaltennamen mit Nullwerten ['Geschlecht','Verheiratet','Abhängige','Selbstständiger','Darlehensbetrag','Loan_Amount_Term','Kredit Geschichte']
## Verwenden Sie die Spalte Geschlecht, um die eindeutigen Werte in der Spalte zu finden train_df['Geschlecht'].einzigartig()
## Ausgabe Array(['Männlich','Weiblich',in])
## Hier steht nan für fehlende Daten
## Verwendung der willkürlichen Imputationstechnik, wir werden fehlendes Geschlecht unterschreiben mit "Fehlen" {Sie können auch jeden anderen Wert verwenden}
arb_impute = train_df['Geschlecht'].Fillna('Fehlen')
einzigartige impute.arb()
## Ausgabe Array(['Männlich','Weiblich','Fehlen'])
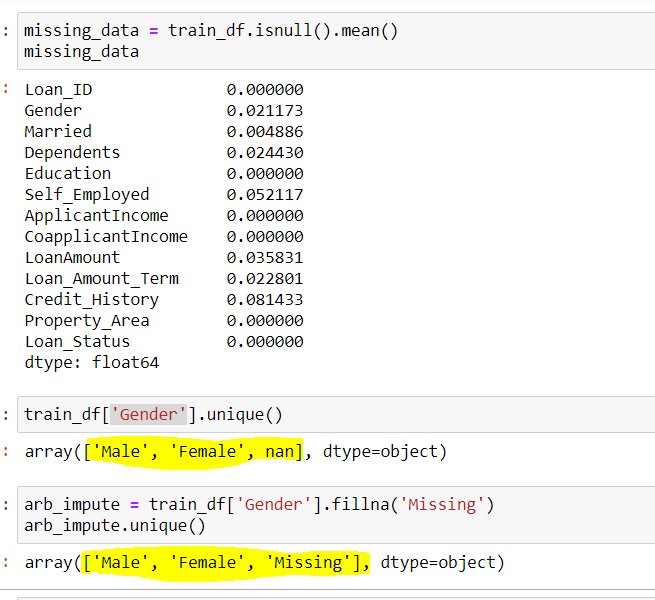
Feige 4: – Willkürliche Anrechnung
Quelle: erstellt vom Autor
Wir können hier die Spalte sehen Geschlecht ich hatte 2 einzigartige Werte {'Männlich Weiblich'} und wenige fehlende Werte {in}. Bei willkürlicher Imputation, wir füllen die werte von {in} in dieser Spalte mit {fehlen}, für das was du bekommst 3 eindeutige Werte für die Variable ‚Geschlecht‘.
3. Häufige Kategoriezuschreibung
Diese Technik sagt, den fehlenden Wert durch die Variable mit der höchsten Häufigkeit zu ersetzen oder in einfachen Worten durch Ersetzen der Werte durch den Modus dieser Spalte. Diese Technik ist auch bekannt als Modus-Imputation.
- Annahmen: –
- Zufallsdaten fehlen.
- Es besteht eine hohe Wahrscheinlichkeit, dass die fehlenden Daten wie die meisten Daten aussehen.
- Vorteil: –
- Die Umsetzung ist einfach.
- Wir können in kürzester Zeit einen vollständigen Datensatz erhalten.
- Wir können diese Technik im Produktionsmodell verwenden.
- Nachteile: –
- Je höher der Prozentsatz fehlender Werte, desto größer die Verzerrung.
- Kann zu einer Überrepräsentation einer bestimmten Kategorie führen.
- Sie können die Verteilung der ursprünglichen Variablen verzerren.
- Wann verwenden:-
- Zufallsdaten fehlen (BESCHÄDIGEN)
- Die fehlenden Daten sind nicht mehr als 5% bis 6% des Datensatzes.
- Code:-
## Ermitteln der Anzahl eindeutiger Werte in Gender train_df['Geschlecht'].gruppiere nach(train_df['Geschlecht']).zählen()
## Ausgabe (489 Männlich & 112 Weiblich) Männlich 489 Weiblich 112
## Männlich hat die höchste Frequenz. Wir können es auch tun, indem wir den Modus überprüfen train_df['Geschlecht'].Modus()
## Ausgabe Männlich
## Verwenden des Imputers für häufige Kategorien
frq_impute = train_df['Geschlecht'].Fillna('Männlich')
frq_impute.unique()
## Ausgabe Array(['Männlich','Weiblich'])
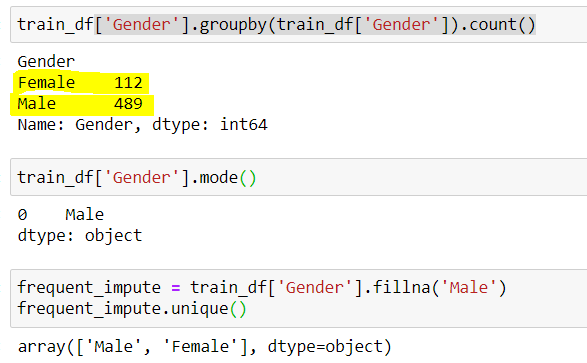
Feige 4: – Häufige Kategoriezuschreibung
Quelle: erstellt vom Autor
Hier merken wir das “Männlich” war die häufigste Kategorie, Also verwenden wir es, um die fehlenden Daten zu ersetzen. Jetzt sind wir allein gelassen 2 Kategorien, nämlich, männlich und weiblich.
Deswegen, Wir sehen, dass jede Technik ihre Vor- und Nachteile hat, und es hängt vom Datensatz und der Situation ab, für die die verschiedenen Techniken, die wir verwenden werden.
Das ist alles von hier …
Bis dann, este es Shashank Singhal, ein Big Data- und Data Science-Enthusiast.
Viel Spaß beim Lernen...
Wenn dir mein Artikel gefallen hat, kannst du mir folgen HIER
LinkedIn Profil:- www.linkedin.com/in/shashank-singhal-1806
Notiz: – Alle oben verwendeten Bilder wurden von mir erstellt (Autor).
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von DataPeaker und werden nach Ermessen des Autors verwendet.





