Entscheidungsbaumklassifizierung | Leitfaden zur Klassifizierung von Entscheidungsbäumen
Inhalt
Überblick
Was ist der Entscheidungsklassifikationsbaum-Algorithmus??
So erstellen Sie einen Entscheidungsbaum von Grund auf neu
Terminologien des Entscheidungsbaums
Unterschied zwischen Random Forest und Entscheidungsbaum
Python-Code-Implementierung von Entscheidungsbäumen
Es gibt mehrere Algorithmen im maschinellen Lernen für Regressions- und Klassifikationsprobleme, aber entscheide dich für Der beste und effizienteste Algorithmus für den gegebenen Datensatz ist der wichtigste Punkt bei der Entwicklung eines guten Modells für maschinelles Lernen..
Einer dieser Algorithmen ist gut für Klassifikationsprobleme / kategorial und Regression ist der Entscheidungsbaum
Entscheidungsbäume implementieren in der Regel genau das menschliche Denkvermögen bei der Entscheidungsfindung, so ist es leicht zu verstehen.
Die Logik hinter dem Entscheidungsbaum ist leicht zu verstehen, da er eine Flussdiagrammstruktur zeigt / baumartige Struktur, die es einfach macht, Informationen aus dem Hintergrundprozess anzuzeigen und zu extrahieren.
Inhaltsverzeichnis
Was ist ein Entscheidungsbaum?
Elemente des Entscheidungsbaums
Wie Sie eine Entscheidung von Grund auf treffen
Wie funktioniert der Entscheidungsbaum-Algorithmus?
EDA-Kenntnisse (explorative Datenanalyse)
Entscheidungsbäume und Random Forests
Vorteile des Entscheidungswaldes
Nachteile von Decision Forest
Python-Codeimplementierung
1. Was ist ein Entscheidungsbaum?
Ein Entscheidungsbaum ist ein überwachter maschineller Lernalgorithmus. Wird sowohl in Klassifikations- als auch in Regressionsalgorithmen verwendet.. Der Entscheidungsbaum ist wie ein Baum mit Knoten. Die Filialen hängen von mehreren Faktoren ab. Teilt die Daten in solche Zweige auf, bis sie einen Schwellenwert erreichen. Ein Entscheidungsbaum besteht aus den Wurzelknoten, untergeordnete Knoten und Blattknoten.
Lassen Sie uns die Entscheidungsbaummethoden anhand eines realen Szenarios verstehen
Stell dir vor, du spielst jeden Sonntag Fußball und lädst immer deinen Freund ein, mit dir zu spielen. Manchmal, dein Freund kommt und andere nicht.
Der Faktor, ob man kommt oder nicht, hängt von vielen Dingen ab, wie das Wetter, die Temperatur, Wind und Müdigkeit. Wir haben begonnen, all diese Funktionen in Betracht zu ziehen und sie zusammen mit der Entscheidung Ihres Freundes zu verfolgen, ob er zum Spielen kommt oder nicht..
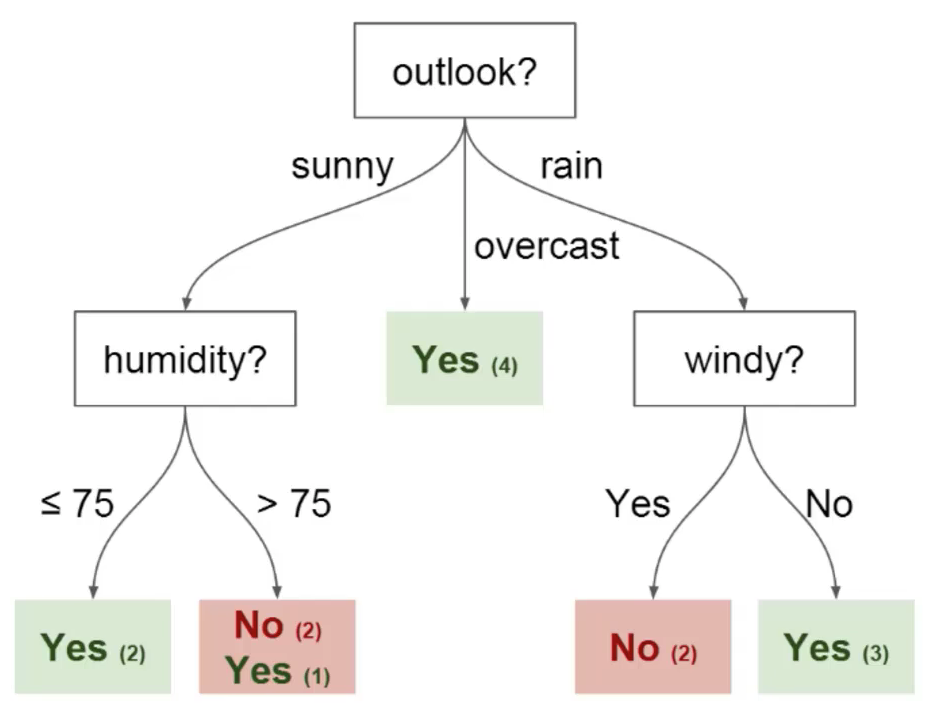
Sie können diese Daten verwenden, um vorherzusagen, ob Ihr Freund zum Fußballspielen kommt oder nicht. Die Technik, die Sie verwenden könnten, ist ein Entscheidungsbaum. So würde der Entscheidungsbaum nach der Bereitstellung aussehen:
2. Elemente eines Entscheidungsbaums
Jeder Entscheidungsbaum besteht aus der folgenden Liste von Elementen:
ein Knoten
b Kanten
c Wurzel
d Blätter
ein) Knoten: Es ist der Punkt, an dem der Baum nach dem Wert eines Attributs unterteilt wird / Datensatzmerkmal.
B) Kanten: Leitet das Ergebnis einer Division an den nächsten Knoten, den wir in der vorherigen Abbildung sehen können, dass Knoten für Features wie Perspektive vorhanden sind, Feuchtigkeit und Wind. Es gibt einen Vorteil für jeden potenziellen Wert jedes dieser Attribute / Merkmale.
C) Wurzel: Dies ist der Knoten, an dem die erste Teilung stattfindet.
D) Laub: Dies sind die Endknoten, die das Ergebnis des Entscheidungsbaums vorhersagen.
3. Wie man Entscheidungsbäume von Grund auf neu erstellt?
Beim Erstellen eines Entscheidungsbaums, die Hauptsache ist, das beste Attribut aus der Liste der Gesamtmerkmale des Datensatzes für den Wurzelknoten und für die Unterknoten auszuwählen. Die Auswahl der besten Attribute erfolgt mit Hilfe einer Technik, die als Attributauswahlmaß bekannt ist. (ASM).
Mit Hilfe von ASM, wir können einfach die besten Eigenschaften für die jeweiligen Entscheidungsbaumknoten auswählen.
Es gibt zwei Techniken für ASM:
ein) Informationsgewinn
B) Gini-Index
ein) Informationsgewinn:
1Informationsgewinn ist die Messung von Änderungen des Entropiewerts nach der Division / Datensatzsegmentierung basierend auf einem Attribut.
2 Gibt an, wie viele Informationen uns eine Funktion liefert / Attribut.
3 Dem Wert des Informationsgewinns folgen, Knotenaufteilung und Aufbau des Entscheidungsbaums sind im Gange.
Der Entscheidungsbaum 4 versucht immer den Wert des Informationsgewinns zu maximieren, und ein Knoten / Attribut mit dem höchsten Wert des Informationsgewinns wird zuerst geteilt. Der Informationsgewinn kann mit der folgenden Formel berechnet werden:
Informationsgewinn = Entropie (S) – [(Gewichteter Durchschnitt) *Entropie(jede Funktion)
Entropie: Entropie bezeichnet die Zufälligkeit im Datensatz. Es wird als Metrik zur Messung von Verunreinigung definiert. Entropie kann berechnet werden als:
Der Gini-Index wird auch als Maß für die Verunreinigung/Reinheit definiert, das beim Erstellen eines Entscheidungsbaums im CART verwendet wird(bekannt als Klassifikations- und Regressionsbaum) Algorithmus.
Ein Attribut mit einem niedrigen Gini-Indexwert sollte gegenüber dem hohen Gini-Indexwert bevorzugt werden.
Es erstellt nur binäre Splits, und der CART-Algorithmus verwendet den Gini-Index, um binäre Splits zu erstellen.
Der Gini-Index kann mit der folgenden Formel berechnet werden:
Gini-Index= 1- ΣJPJ2
Wobei pj für die Wahrscheinlichkeit steht
4. Wie funktioniert der Entscheidungsbaum-Algorithmus?
Die Grundidee jedes Entscheidungsbaumalgorithmus ist wie folgt:
1. Wählen Sie das beste Feature mithilfe von Attributauswahlmaßen(ASM) um die Aufzeichnungen zu teilen.
2. Machen Sie dieses Attribut/Feature zu einem Entscheidungsknoten und teilen Sie den Datensatz in kleinere Teilmengen auf.
3 Starten Sie den Baumbildungsprozess, indem Sie diesen Prozess für jedes Kind rekursiv wiederholen, bis eine der folgenden Bedingungen erreicht ist :
ein) Alle Tupel, die zum gleichen Attributwert gehören.
B) Es sind keine Attribute mehr übrig.
C ) Es sind keine Instanzen mehr übrig.
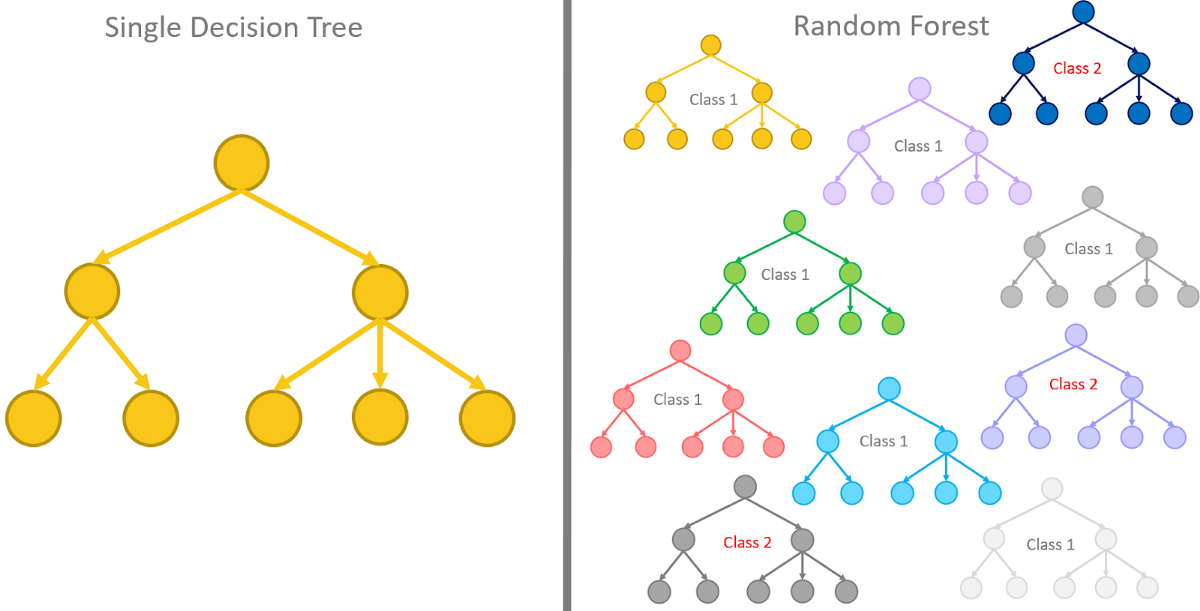
5. Entscheidungsbäume und Random Forests
Entscheidungsbäume und Random Forest sind beides die Baummethoden, die im maschinellen Lernen verwendet werden.
Entscheidungsbäume sind die Machine-Learning-Modelle, die verwendet werden, um Vorhersagen zu treffen, indem jedes einzelne Merkmal im Datensatz durchgegangen wird., Einer nach dem anderen.
Random Forests hingegen sind eine Sammlung von Entscheidungsbäumen, die zusammen gruppiert und trainiert werden und die zufällige Reihenfolgen der Features in den gegebenen Datensätzen verwenden.
Anstatt sich auf nur einen Entscheidungsbaum zu verlassen, der Random Forest übernimmt die Vorhersage von jedem einzelnen Baum und basiert auf der Mehrheit der Vorhersagen, und es gibt die endgültige Ausgabe. Mit anderen Worten, Der Random Forest kann als eine Sammlung mehrerer Entscheidungsbäume definiert werden.
6. Vorteile des Entscheidungsbaums
1 Es ist einfach zu implementieren und folgt einer Flussdiagrammstruktur, die einer menschenähnlichen Entscheidungsfindung ähnelt.
2 Es erweist sich als sehr nützlich bei entscheidungsbezogenen Problemen.
3 Es hilft, alle möglichen Ergebnisse für ein bestimmtes Problem zu finden.
4 Im Vergleich zu anderen Algorithmen des maschinellen Lernens ist die Datenbereinigung in Entscheidungsbäumen sehr gering.
5 Verarbeitet sowohl numerische als auch kategoriale Werte
7. Nachteile des Entscheidungsbaums
1 Zu viele Ebenen des Entscheidungsbaums machen es manchmal extrem komplex.
2 Dies kann zu einer Überanpassung führen ( die mit dem gelöst werden können Random Forest-Algorithmus)
3 Für die mehr Anzahl der Klassenlabels, die Rechenkomplexität des Entscheidungsbaums steigt.
8. Python-Code-Implementierung
#Numerische Computerbibliotheken
Pandas als pd importieren
numpy als np importieren
import matplotlib.pyplot als plt
Seegeboren als sns importieren
# Teilen Sie den Datensatz in Trainingsdaten und Testdaten auf
aus sklearn.model_selection import train_test_split
x = raw_data.drop('Kyphose', Achse = 1)
y = raw_data['Kyphose']
x_training_data, x_test_data, y_training_data, y_test_data = train_test_split(x, Ja, test_size = 0.3)
#Trainieren Sie das Entscheidungsbaummodell
aus sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier()
model.fit(x_training_data, y_training_data)
Vorhersagen = model.predict(x_test_data)
# Messen Sie die Leistung des Entscheidungsbaummodells
von sklearn.metrics import Klassifizierung_Bericht
von sklearn.metrics importieren Confusion_matrix
drucken(Klassifizierungsbericht(y_test_data, Vorhersagen))
drucken(Verwirrung Matrix(y_test_data, Vorhersagen))
Damit beende ich diesen Blog. Hallo allerseits, Namasté Ich heiße Pranshu Sharma Und ich bin ein Data Science-Enthusiast
Vielen Dank, dass Sie sich Ihre wertvolle Zeit genommen haben, um diesen Blog zu lesen.. Auf Fehler gerne hinweisen (schließlich, ich bin lehrling) und hinterlasse die entsprechenden Kommentare oder hinterlasse einen Kommentar.