Dieser Artikel wurde im Rahmen der Data Science Blogathon
Einführung
Dieser Artikel ist Teil einer fortlaufenden Blog-Serie zur Verarbeitung natürlicher Sprache (PNL). Im vorherigen Artikel, diskutieren wir eine Entitätsextraktionstechnik namens, zum Beispiel, Anerkennung benannter Entitäten. Es gibt auch eine andere Entitätsextraktionstechnik, die ebenfalls eine beliebte Technik namens . ist Themenmodellierung, die wir in späteren Artikeln unserer Blog-Reihe besprechen werden.
Dann, In diesem Artikel, wir vertiefen uns in die syntaktische Analyse, das ist eine der entscheidenden Ebenen von NLP.
Das ist das Teil 11 aus der Blog-Serie zur Schritt-für-Schritt-Anleitung zur Verarbeitung natürlicher Sprache.
Inhaltsverzeichnis
1. Was ist Parsen??
2. Was ist der Unterschied zwischen parsing und lexikalisch??
3. Was ist ein Analysator??
4. Welche verschiedenen Arten von Analysatoren gibt es??
5. Was ist Shunt und seine Typen?
6. Welche Arten der ableitungsbasierten Analyse gibt es??
7. Was ist ein Parse-Baum??
Was ist Parsen??
Syntaktische Analyse ist definiert als die Analyse, die uns die logische Bedeutung von mit Sicherheit gegebenen Sätzen oder Teilen dieser Sätze sagt. Wir müssen auch die Grammatikregeln berücksichtigen, um die logische Bedeutung und Richtigkeit von Sätzen zu definieren.
Ö, in einfachen Worten, Parsing ist der Prozess des Parsens natürlicher Sprache mit den Regeln der formalen Grammatik. Wir wenden Grammatikregeln nur auf Kategorien und Wortgruppen an, gilt nicht für einzelne Wörter.
Die syntaktische Analyse weist dem Text grundsätzlich eine semantische Struktur zu. Auch als Parsing oder Parsing bekannt. Das Wort ‚Syntaxanalyse‘ stammt vom lateinischen Wort ‚Nennwerte‘ was bedeutet es ‚Teil‘. Die syntaktische Analyse befasst sich mit der Syntax natürlicher Sprache. Grammatikregeln wurden in der syntaktischen Analyse verwendet.
Nehmen wir zum besseren Verständnis ein Beispiel:
Betrachten Sie den folgenden Satz:
Satz: Schule geh ein Junge
Der vorherige Satz gibt seine Bedeutung nicht logisch wieder und seine grammatikalische Struktur ist nicht korrekt. Dann, Die syntaktische Analyse sagt uns, ob ein bestimmter Satz seine logische Bedeutung vermittelt oder nicht und ob seine grammatikalische Struktur korrekt ist oder nicht.
Wie wir die Schritte oder die verschiedenen Ebenen von NLP besprechen, die dritte Ebene von NLP ist das Parsing oder das Parsing oder die Syntax. Das Hauptziel dieser Ebene ist es, die genaue Bedeutung zu extrahieren, oder in einfachen Worten, kann die Bedeutung von Wörterbüchern aus dem Text erkennen. Die Syntaxanalyse prüft die Bedeutung des Textes anhand der Regeln der formalen Grammatik.
Zum Beispiel, betrachte den folgenden Satz
Satz: “heißes Eis”
Der obige Satz würde vom semantischen Parser abgelehnt.
Jetzt, Lassen Sie uns das Parsen formal definieren,
Im obigen Sinne, Parsing oder Parsing kann als der Prozess des Parsens von Zeichenketten in natürlicher Sprache gemäß den Regeln der formalen Grammatik definiert werden.
Unterschied zwischen lexikalischer und syntaktischer Analyse
Das Ziel der lexikalischen Analyse ist die Datenbereinigung und Merkmalsextraktion mit Hilfe von Techniken wie
- Derivat,
- Lematización,
- Korrigiere falsch geschriebene Wörter, etc.
Auf der anderen Seite, beim Parsen ist unser Ziel:
- Finde die Rollen, die Wörter in einem Satz spielen,
- Interpretiere die Beziehung zwischen Wörtern,
- Interpretieren Sie die grammatikalische Struktur von Sätzen.
Betrachten wir das folgende Beispiel mit 2 Gebete:
Sätze: Patna ist die Hauptstadt von Bihar. Ist Patna die Hauptstadt von Bihar??
In beiden Sätzen, alle Wörter sind gleich, aber nur der erste Satz ist syntaktisch korrekt und leicht verständlich.
Aber wir können diese Unterscheidungen nicht mit grundlegenden lexikalischen Verarbeitungstechniken treffen.. Deswegen, wir brauchen ausgefeiltere Syntaxverarbeitungstechniken, um die Beziehung zwischen einzelnen Wörtern in einem Satz zu verstehen.
Die syntaktische Analyse berücksichtigt die folgenden Aspekte des Satzes, die das Lexikon nicht berücksichtigt::
Reihenfolge und Bedeutung der Wörter
Die syntaktische Analyse zielt darauf ab, die Abhängigkeit von Wörtern von anderen Wörtern im Dokument zu extrahieren. Wenn wir die Reihenfolge der Wörter ändern, es wird schwer den Satz zu verstehen.
Stoppen Sie die Wortspeicherung
Wenn wir die leeren Worte entfernen, kann die Bedeutung eines Satzes komplett verändern.
Wortmorphologie
Stemming und Stemming bringen die Wörter in ihre Grundform, dadurch die Grammatik des Satzes modifizieren.
Wortarten für Wörter in einem Satz
Es ist wichtig, den richtigen grammatikalischen Teil eines Wortes zu identifizieren.
Zum Beispiel, Betrachten Sie die folgenden Sätze:
„Schnitte an seiner Hand“ („Schnitt“ ist hier ein Substantiv) „er schneidet eine Ananas“ (Hier, 'schneiden' ist ein Verb)
Was ist ein Analysator??
Der Parser wird verwendet, um die Parsing-Aufgabe zu implementieren.
Jetzt, mal sehen was genau ein Parser ist.
Es ist definiert als die Softwarekomponente, die Eingabetextdaten entgegennimmt und nach Überprüfung der korrekten Syntax mit Hilfe der formalen Grammatik eine strukturelle Darstellung der Eingabe bereitstellt. Es erzeugt auch eine Datenstruktur im Allgemeinen in Form eines Parsebaums oder abstrakten Syntaxbaums oder einer anderen hierarchischen Struktur..
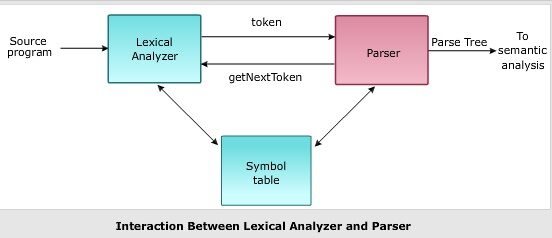
Bildquelle: Google Bilder
Anhand der folgenden Punkte können wir die Relevanz von Parsing im NLP verstehen:
- Der Parser kann verwendet werden, um Syntaxfehler zu melden.
- Hilft bei der Wiederherstellung von häufig auftretenden Fehlern, damit die Verarbeitung des Rests des Programms fortgesetzt werden kann.
- Ein Parse-Baum wird mit Hilfe eines Parsers erstellt.
- Der Parser wird verwendet, um eine Symboltabelle zu erstellen, die eine wichtige Rolle im NLP spielt.
- Ein Parser wird auch verwendet, um Zwischendarstellungen zu erzeugen (IR).
Verschiedene Arten von Analysatoren
Wie besprochen, Grundsätzlich, ein Parser ist eine prozedurale Interpretation der Grammatik. Versuchen Sie, einen optimalen Baum für einen bestimmten Satz zu finden, nachdem Sie den Raum nach einer Vielzahl von Bäumen durchsucht haben.
Werfen wir einen Blick auf einige der verfügbaren Analysatoren:
- Rekursiver Abstiegsanalysator
- Case-Reduction-Parser
- Grafikanalysator
- Parser für reguläre Ausdrücke
Rekursiver Abstiegsanalysator
Es ist eine der einfachsten Formen des Parsens. Einige wichtige Punkte über den rekursiven Abstiegs-Parser sind wie folgt:
- Folgen Sie einem Top-Down-Prozess.
- Versuchen Sie zu überprüfen, ob die Syntax des Eingabestreams korrekt ist oder nicht.
- Scannt den eingegebenen Text von links nach rechts.
- Die für diese Art von Parser erforderliche Operation besteht darin, Zeichen aus dem Eingabestrom zu scannen und sie mit Hilfe der Grammatik den Terminals zuzuordnen..
Case-Reduction-Parser
Einige der wichtigen Punkte über den Shift-Reduce-Parser sind wie folgt::
- Folgen Sie einem einfachen Prozess von unten nach oben.
- Ihr Ziel ist es, die Reihenfolge von Wörtern und Phrasen zu finden, die der rechten Seite einer Grammatikproduktion entspricht, und sie durch die linke Seite der Produktion zu ersetzen..
- Versuchen Sie, eine Wortfolge zu finden, die so lange andauert, bis der gesamte Satz gekürzt ist.
- In einfachen Worten, Dieser Parser beginnt mit dem Eingabesymbol und zielt darauf ab, den Parserbaum bis zum Startsymbol aufzubauen.
Grafikanalysator
Einige der wichtigen Punkte über den Chart-Analyzer sind wie folgt:
- Grundsätzlich, Dieser Parser ist nützlich für mehrdeutige Grammatiken, einschließlich natürlichsprachlicher Grammatiken.
- Wendet das Konzept der dynamischen Programmierung auf Analyseprobleme an.
- Durch dynamische Programmierung, speichert hypothetische Teilergebnisse in einer Struktur namens „Grafik“.
- Das ‚Grafik‘ kann auch in verschiedenen Szenarien wiederverwendet werden.
Parser für reguläre Ausdrücke
Es ist einer der am häufigsten verwendeten Parser. Einige der wichtigen Punkte über den Regexp-Analysator sind wie folgt::
- Verwendet einen regulären Ausdruck, der in Grammatikform am Anfang einer Zeichenfolge mit der Bezeichnung POS . definiert ist.
- Grundsätzlich, Verwenden Sie diese regulären Ausdrücke, um die Eingabesätze zu parsen und daraus einen Analysebaum zu erstellen.
Was ist Bypass?
Wir benötigen eine Folge von Produktionsregeln, um die Eingabezeichenfolge zu erhalten. Die Ableitung ist ein Satz von Produktionsregeln. Während der Analyse, wir müssen das Nicht-Terminal entscheiden, die zusammen mit der Produktionsregelentscheidung ersetzt wird, mit deren Hilfe das Nicht-Terminal ersetzt wird.
Bypass-Typen
In diesem Abschnitt, Wir werden die beiden Arten von Ableitungen diskutieren, die verwendet werden kann, um zu entscheiden, welches Nichtterminal durch die Produktionsregel ersetzt werden soll:
Am weitesten links umfahren
In der Umgehungsstraße ganz links, die eingegebene Ausspracheform wird gescannt und von links nach rechts ersetzt. In diesem Fall, die Satzform ist als linke Satzform bekannt.
Ganz rechts Bypass
In der Umgehungsstraße ganz links, Eingabesatzform wird gescannt und von rechts nach links ersetzt. In diesem Fall, die Form des Satzes heißt die Form des rechten Satzes.
Analysearten
Die Ableitung unterteilt das Parsing in die folgenden zwei Arten:
Bildquelle: Google Bilder
Top-down-Analyse
In der Top-Down-Analyse, der Parser beginnt, den Parse-Baum aus dem Startsymbol zu erzeugen und versucht dann, das Startsymbol in eine Eingabe umzuwandeln. Die gängigste Form der Top-Down-Analyse verwendet das rekursive Verfahren, um die Eingaben zu verarbeiten, aber sein Hauptnachteil ist zurück.
Bottom-up-Analyse
In der Bottom-up-Analyse, der Parser beginnt mit dem Eingabesymbol zu arbeiten und versucht den Parserbaum bis zum Startsymbol aufzubauen.
Was ist ein Parse-Baum??
Stellt die grafische Darstellung einer Ableitung dar. Das Startsymbol des Shunts wird als KnotenNodo ist eine digitale Plattform, die die Verbindung zwischen Fachleuten und Unternehmen auf der Suche nach Talenten erleichtert. Durch ein intuitives System, Ermöglicht Benutzern das Erstellen von Profilen, Erfahrungen austauschen und Zugang zu Stellenangeboten erhalten. Der Fokus auf Zusammenarbeit und Networking macht Nodo zu einem wertvollen Werkzeug für diejenigen, die ihr berufliches Netzwerk erweitern und Projekte finden möchten, die mit ihren Fähigkeiten und Zielen übereinstimmen.... Die Wurzel des Analysebaums und die Blattknoten sind Terminals, und die inneren Knoten sind nicht terminal..
Die nützlichste Eigenschaft des Parse-Baums ist, dass die Tour in Ordnung aus dem Baum erzeugt die ursprüngliche Eingabezeichenfolge.
Zum Beispiel, Betrachten Sie den folgenden Satz:
Satz: Der Hund hat einen Mann im Park gesehen
Nach der Analyse des Satzes, der generierte Parse-Baum ist unten gezeigt:
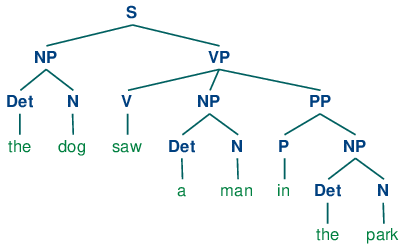
Bildquelle: Google Bilder
Damit endet unser Teil 11 aus der Blog-Reihe zur Verarbeitung natürlicher Sprache!
Andere Blogbeiträge von mir
Du kannst auch meine vorherigen Blogbeiträge lesen.
Frühere Data Science-Blog-Posts.
Hier ist es mein Linkedin-Profil falls du dich mit mir verbinden möchtest. Ich freue mich, mit Ihnen verbunden zu sein.
Für jede Anfrage, Sie können mir eine E-Mail senden an Google Mail.
Abschließende Anmerkungen
Danke fürs Lesen!
Ich hoffe der Artikel hat dir gefallen. Wenn du möchtest, teile es auch mit deinen Freunden. Alles was nicht erwähnt wurde oder du deine Gedanken teilen möchtest? Fühlen Sie sich frei, unten einen Kommentar zu hinterlassen und ich melde mich bei Ihnen. 😉
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von DataPeaker und werden nach Ermessen des Autors verwendet.





