Dieser Artikel wurde im Rahmen der Data Science Blogathon.
Was ist maschinelles Lernen??
Maschinelles Lernen: Maschinelles Lernen (ML) ist ein hoch iterativer Prozess und ML Modelle werden aus Erfahrungen der Vergangenheit gelernt und auch historische Daten zu analysieren. Was ist mehr, ML-Modelle können Muster erkennen, um Vorhersagen über die Zukunft des gegebenen Datensatzes zu treffen.

WWarum ist maschinelles Lernen wichtig?
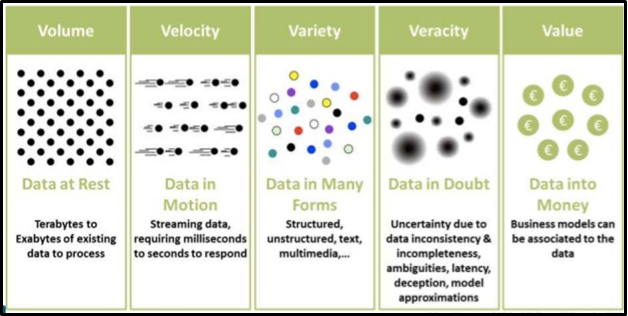
Da 5V die digitale Welt von heute dominiert (Volumen, Vielfalt, Varianz und Wertsichtbarkeit), die meisten Branchen entwickeln verschiedene Modelle, um ihre Präsenz und Chancen auf dem Markt zu analysieren, basierend auf diesem Ergebnis, Sie liefern die besten Produkte. Dienstleistungen für Ihre Kunden in großem Umfang.
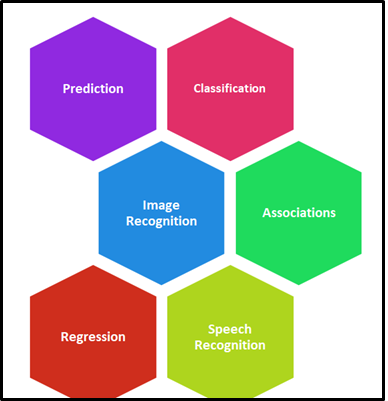
Was sind die wichtigsten Anwendungen für maschinelles Lernen??
Maschinelles Lernen (ML) ist in vielen Branchen breit anwendbar und die Implementierung und Verbesserung ihrer Prozesse. Heutzutage, ML wurde in vielen Bereichen und Branchen ohne Grenzen eingesetzt. Die folgende Abbildung stellt den Bereich dar, in dem ML eine entscheidende Rolle spielt.
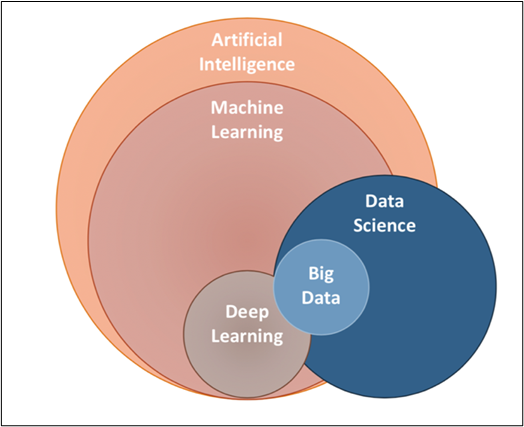
Wo ist maschinelles Lernen im KI-Raum?
Schaut euch einfach die Venn-Diagramm, wir könnten verstehen, wo ML im KI-Raum steht und wie es mit anderen KI-Komponenten zusammenhängt.
Woher kennen wir die Jargons, die um uns herum fliegen?, mal sehen, wovon genau jede Komponente spricht.
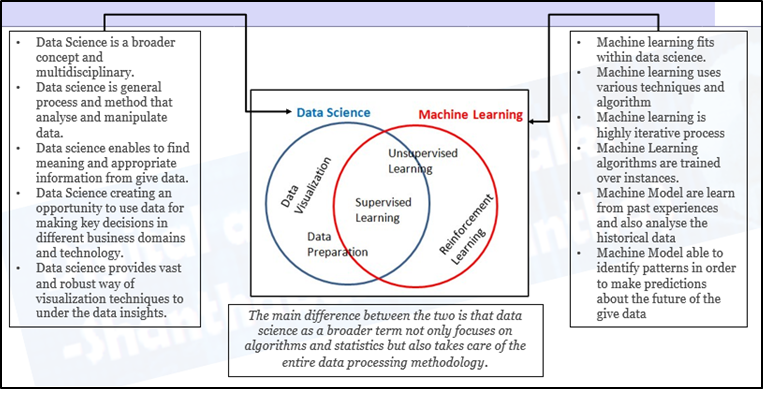
Wie hängen Data Science und maschinelles Lernen zusammen?
Maschineller Lernprozess, ist der erste Schritt im ML-Prozess, bei dem Daten aus mehreren Quellen entnommen und von einer fein abgestimmten Datenverarbeitung gefolgt werden, diese Daten wären die Quelle für die ML-Algorithmen basierend auf der Problemstellung, wie Vorhersagemodelle, Rankings und andere, die im ML-Weltraum verfügbar sind. Lassen Sie uns hier jeden Prozess einzeln besprechen.
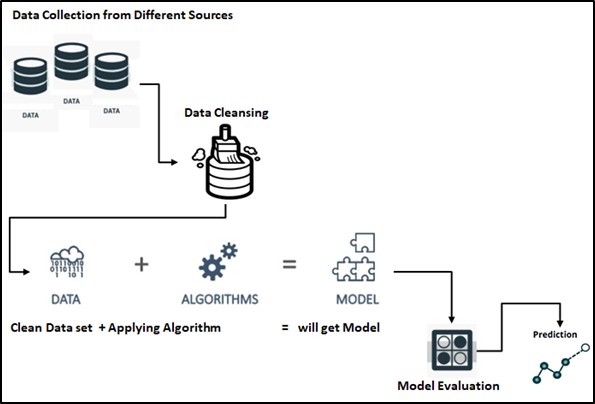
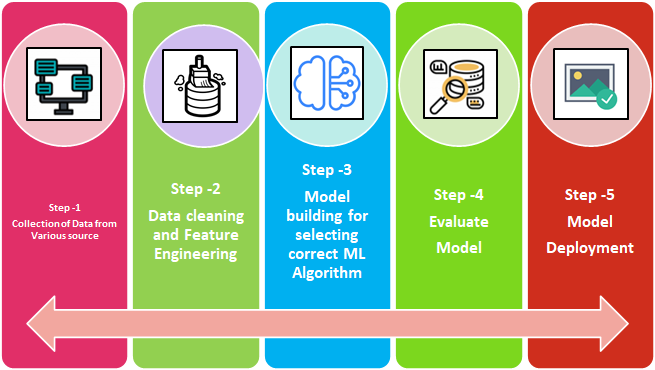
Maschinelles Lernen – Etapas: Wir können die Phasen des AA-Prozesses in 5 wie unten im Flussdiagramm erwähnt.
- Datensatz
- Datenverhandlung
- Bau des Modells
- Modellbewertung
- Modellbereitstellung
Identifizierung von Geschäftsproblemen, bevor Sie zu den vorherigen Phasen übergehen. Dann, Wir müssen uns über das Ziel des Zwecks der Umsetzung des ML klar sein. Finden Sie die Lösung für das gegebene Problem / identifiziert. wir müssen die Daten sammeln und die nächsten Schritte richtig überwachen.
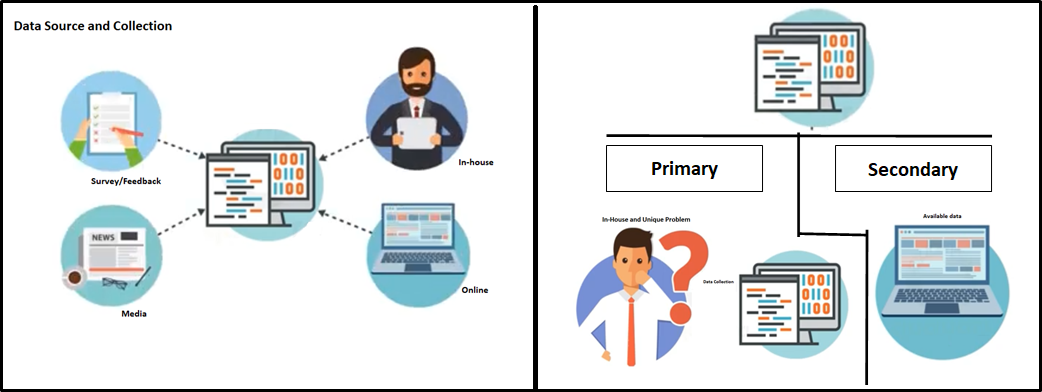
Datensatz
Die Erhebung von Daten aus verschiedenen Quellen kann intern und / oder extern, um Anforderungen zu erfüllen / geschäftliche Probleme. Daten können in jedem Format vorliegen. CSV, XML.JSON, etc., Hier spielt Big Data eine entscheidende Rolle, um sicherzustellen, dass die richtigen Daten im erwarteten Format und in der erwarteten Struktur vorliegen.
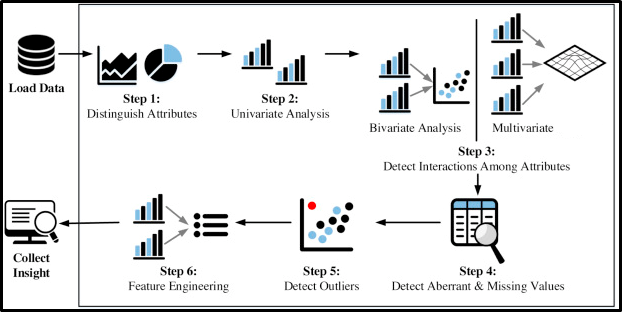
Datenverhandlung und Datenverarbeitung: Das Hauptziel dieser Phase und dieses Ansatzes sind die folgenden:.
Datenverarbeitung (EDA):
- Verstehen Sie den angegebenen Datensatz und helfen Sie beim Bereinigen des angegebenen Datensatzes.
- Gibt Ihnen ein besseres Verständnis der Eigenschaften und der Beziehungen zwischen ihnen
- Extrahieren Sie wesentliche Variablen und lassen Sie sie zurück / Entfernen Sie nicht-essentielle Variablen.
- Umgang mit fehlenden Werten oder menschlichen Fehlern.
- Identifizierung von Ausreißern.
- Der EDA-Prozess würde die Erkenntnisse aus einem Datensatz maximieren.
Funktionsengineering:
- Umgang mit fehlenden Werten in Variablen
- Konvertieren Sie kategorial in numerisch, da die meisten Algorithmen numerische Eigenschaften benötigen.
- Muss Nicht-Gaussian korrigieren (normal). Lineare Modelle gehen davon aus, dass die Variablen eine Gaußsche Verteilung haben.
- Finden Sie Ausreißer in den Daten, Daher kürzen wir die Daten über einem Schwellenwert oder transformieren die Daten, indem wir Datensätze transformieren.
- Skalierungsfunktionen. Dies ist notwendig, um allen Merkmalen die gleiche Bedeutung zu geben und nicht mehr dem, dessen Wert größer ist.
- Feature Engineering ist ein kostspieliger und zeitaufwändiger Prozess.
- Feature Engineering kann ein manueller Prozess sein, kann automatisiert werden
Schulung und Prüfung:
- Die Trainingsdaten werden verwendet, um sicherzustellen, dass die Maschine Muster in den Daten erkennt., Kreuzvalidierung der Daten wird verwendet, um eine bessere Genauigkeit zu gewährleisten und
die Effizienz des Algorithmus, der zum Trainieren der Maschine verwendet wird. - Die Testdaten werden verwendet, um zu sehen, wie gut das Gerät neue Reaktionen basierend auf Ihrem Training vorhersagen kann..
- Das Zugtestteilungsverfahren wird verwendet, um die ML-Leistung von Algorithmen zu schätzen, wenn sie verwendet werden, um Vorhersagen über Daten zu treffen, die nicht
zum Trainieren des Modells verwendet.
Ausbildung
- Trainingsdaten sind der Datensatz, auf dem das Modell trainiert.
- Trainieren Sie Daten, aus denen das Modell Erfahrungen gelernt hat.
- Trainingssets werden verwendet, um Ihre Modelle anzupassen und anzupassen.
Tests
- Die Testdaten sind die Daten, die verwendet werden, um zu überprüfen, ob das Modell
Sie haben aus den Erfahrungen, die Sie mit dem Zugdatensatz gemacht haben, gut genug gelernt. - Testsätze
sind Daten “unsichtbar” um Ihre Modelle zu bewerten.
Zugdaten: Trainieren Sie unseren Algorithmus für maschinelles Lernen
Testdaten: Nach dem Training des Modells, Testdaten werden verwendet, um Ihre Effizienz und Modellleistung zu testen.
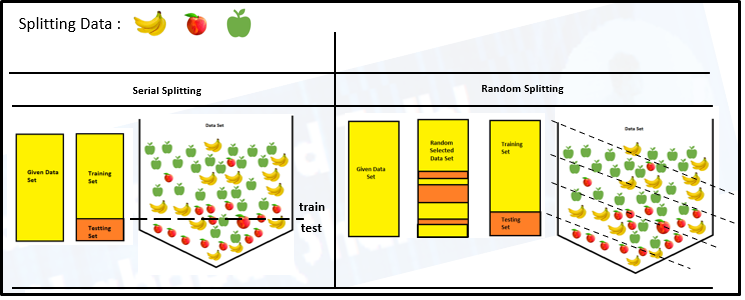
Der Zweck des Zufallszustandes in der Zugversuchsabteilung: zufälliger Zustand sorgt dafür, dass die Divisionen die Sie generieren, sind reproduzierbar. das zufälliger Zustand die Sie bereitstellen, wird als Saat für die zufällig Zahlengenerator. Dies stellt sicher, dass die zufällig die Zahlen werden in der gleichen Reihenfolge generiert.
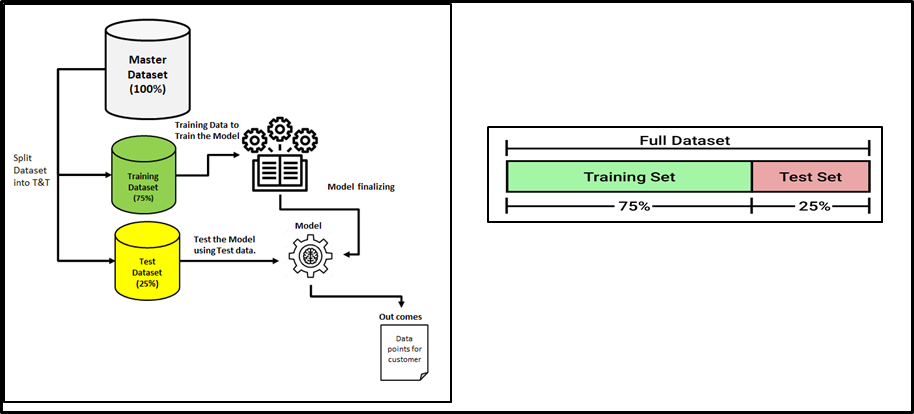
Daten aufgeteilt in Trainingssätze / nachweisen
- Früher haben wir einen Datensatz in Trainingsdaten und Testdaten im Bereich des maschinellen Lernens unterteilt.
- Der geteilte Bereich ist normalerweise 20% al 80% zwischen den Test- und Trainingsphasen des gegebenen Datensatzes.
- Es würde eine große Datenmenge ausgegeben, um Ihr Modell zu trainieren
- Den Rest können Sie für die Evaluierung Ihres Testmodells verwenden.
- Kann aber nicht mischen / Dieselben Daten für Trainings- und Testzwecke wiederverwenden
- Wenn Sie Ihr Modell mit denselben Daten auswerten, mit denen Sie es trainiert haben, dein Modell könnte sehr überstimmt sein. Dann stellt sich die Frage, ob die Modelle neue Daten vorhersagen können.
- Deswegen, Sie sollten separate Test- und Trainings-Subsets Ihres Datasets haben.
MODELLBEWERTUNG: Jedes Modell hat seine eigene Modellbewertungsmythologie, Einige der besten Bewertungen sind hier.
- Bewerten Rückschritt Modell.
- Summe des quadratischen Fehlers (SSE)
- Quadratischer Fehler (MSE)
- Quadratischer Fehler (RMSE)
- Mittlerer absoluter Fehler (VIEL)
- Bestimmungskoeffizient (R2)
- R2 angepasst
- Bewerten Einstufung Modell.
- Verwirrung Matrix.
- Genauigkeitsbewertung.
- AUC und ROC.
Einsatz von a ML-Modell bedeutet einfach, das fertige Modell in eine Produktionsumgebung zu integrieren und Ergebnisse zu erhalten, um Geschäftsentscheidungen zu treffen.
Deswegen, Ich hoffe, Sie können den End-to-End-Prozessablauf des maschinellen Lernens verstehen und ich denke, es wäre hilfreich für Sie. Vielen Dank für Ihre Zeit.





