Was ist logistische Regression??
In diesem Artikel wird davon ausgegangen, dass Sie über grundlegende Kenntnisse und Verständnis von Konzepten des maschinellen Lernens verfügen., als Zielvektor, die Matrix von Merkmalen und verwandten Begriffen.
Logistische Regression: wahrscheinlich einer der interessantesten überwachten maschinellen Lernalgorithmen im maschinellen Lernen. Obwohl “Rückschritt” in ihrem namen, Die logistische Regression ist eine weit verbreitete überwachte Methode. Einstufung Algorithmus. Logistische Regression, zusammen mit ihren verwandten Cousinen, nämlich.. Multinomiale logistische Regression, gibt uns die Möglichkeit, mit einem einfachen Ansatz vorherzusagen, ob eine Beobachtung zu einer bestimmten Klasse gehört, leicht verständlich und weiter.
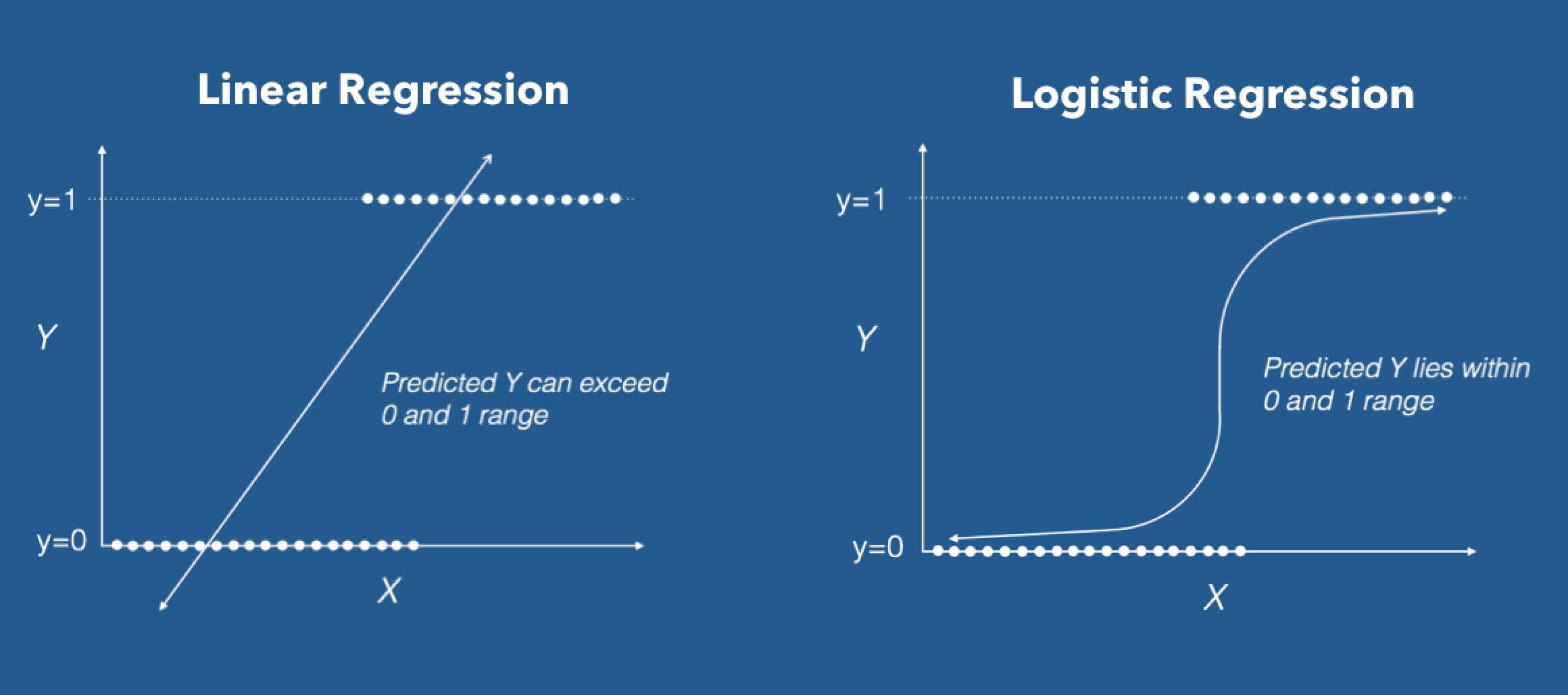
Quelle: DZone
Logistische Regression in ihrer Grundform (von Ursprünglich) es ist ein Binärer Klassifikator. Dies bedeutet, dass der Zielvektor nur die Form eines von zwei Werten annehmen kann. In der Formel des logistischen Regressionsalgorithmus, Wir haben ein lineares Modell, zum Beispiel, B0 + B1x, die in eine Logistikfunktion integriert ist (auch bekannt als Sigmoidfunktion). Die Formel des binären Klassifikators, die wir am Ende haben, ist die folgende:
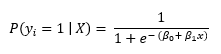
 Woher:
Woher:
- P (Jaich = 1 | x) ist die Wahrscheinlichkeit des iNS Beobachtungszielwert, Jaich der Klasse angehören 1.
- Β0 y β1 sind die zu erlernenden Parameter.
- mich repräsentiert die Eulersche Zahl.
Hauptziel der logistischen Regressionsformel.
Die logistische Regressionsformel zielt darauf ab, den linearen Output zu begrenzen oder zu beschränken und / das Sigmoid zwischen einem Wert von 0 Ja 1. Der Hauptgrund ist aus Gründen der Interpretierbarkeit, nämlich, wir können den Wert als einfache Wahrscheinlichkeit lesen; Das heißt, wenn der Wert größer ist als 0,5, Klasse eins würde vorhergesagt; andererseits, Klasse ist vorhergesagt 0.
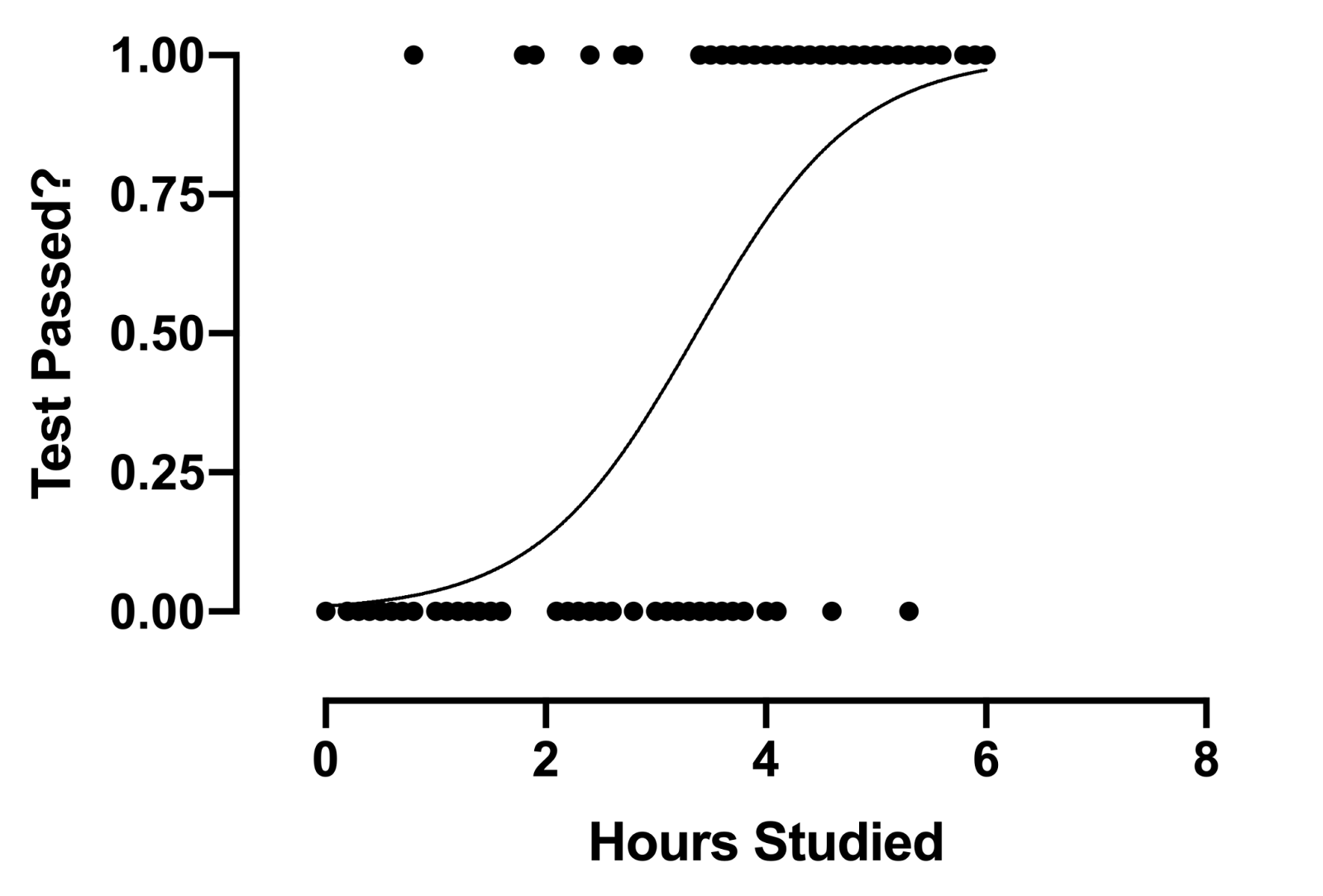
Quelle: GraphPad
Python-Implementierung.
Jetzt sehen wir die Implementierung der Programmiersprache Python. Für diese Übung, Wir verwenden den Ionosphären-Datensatz, der zum Download von der UCI-Repository für maschinelles Lernen.
# Wir beginnen mit dem Importieren der erforderlichen Pakete
# für das Problem des maschinellen Lernens verwendet werden
Pandas als pd importieren
numpy als np importieren
from sklearn.linear_model import LogisticRegression
aus sklearn.preprocessing importieren StandardScaler
# Wir lesen die Daten mit Pandas'
# 'read_csv'-Methode. Dies transformiert die .csv-Datei
# in ein Pandas DataFrame-Objekt.
Datenrahmen = pd.read_csv('ionosphäre.daten', header=Keine)
# Wir konfigurieren die Anzeigeeinstellungen des
# Pandas DataFrame.
pd.set_option('display.max_rows', 10000000000)
pd.set_option('display.max_columns', 10000000000)
pd.set_option('anzeige.breite', 95)
# Wir sehen die Form des Datenrahmens. Speziell
# die Anzahl der vorhandenen Zeilen und Spalten.
drucken('Dieser DataFrame hat %d Zeilen und %d Spalten'%(dataframe.shape))
Die Ausgabe des vorherigen Codes wäre die folgende (die Form des Datenrahmens):
![]()
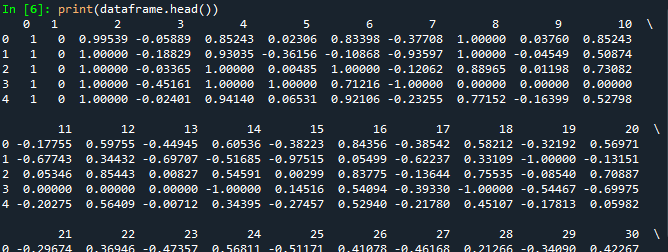
# Wir drucken die ersten fünf Zeilen unseres Datenrahmens. drucken(dataframe.head())
Die Ausgabe des obigen Codes sieht wie folgt aus (die folgende Ausgabe wird abgeschnitten):

# Wir isolieren die Feature-Matrix aus dem DataFrame.
features_matrix = dataframe.iloc[:, 0:34]
# Wir isolieren den Zielvektor aus dem DataFrame.
target_vector = dataframe.iloc[:, -1]
# Wir überprüfen die Form der Merkmalsmatrix, und Zielvektor.
drucken('Die Feature-Matrix hat %d Zeilen und %d Spalten(S)'%(features_matrix.shape))
drucken('Die Zielmatrix hat %d Zeilen und %d Spalten(S)'%(np.array(Zielvektor).umformen(-1, 1).Form))
Die Ausgabe für die Form unserer Feature-Matrix und des Zielvektors wäre wie folgt:
![]()

# Wir verwenden den StandardScaler von scikit-learn, um # Vorverarbeiten der Merkmalsmatrixdaten. Dieser Wille # Stellen Sie sicher, dass alle eingegebenen Werte auf dem gleichen Wert sind # Skala für den Algorithmus. features_matrix_standardized = StandardSkalierer().fit_transform(features_matrix)
# Wir erstellen eine Instanz des LogisticRegression Algorithm # Wir verwenden die Standardwerte für die Parameter und # Hyperparameter. Algorithmus = LogistischeRegression(Strafe='l2', dual=Falsch, Maut=1e-4, C=1,0, fit_intercept=Wahr, intercept_scaling=1, class_weight=Keine, random_state=Keine, Löser="lbfgs", max_iter=100, multi_class="Auto", ausführlich=0, warm_start=Falsch, n_jobs=Keine, l1_ratio=Keine) # Wir verwenden die 'Fit'-Methode, um die # Trainingsprozess zu unserer Merkmalsmatrix und unserem Zielvektor. Logistic_Regression_Model = algorithm.fit(features_matrix_standardized, Zielvektor)
# Wir schaffen eine Beobachtung mit Werten, in Ordnung # um die Vorhersagekraft unseres Modells zu testen. Beobachtung = [[1, 0, 0.99539, -0.05889, 0.8524299999999999, 0.02306, 0.8339799999999999, -0.37708, 1.0, 0.0376, 0.8524299999999999, -0.17755, 0.59755, -0.44945, 0.60536, -0.38223, 0.8435600000000001, -0.38542, 0.58212, -0.32192, 0.56971, -0.29674, 0.36946, -0.47357, 0.56811, -0.51171, 0.41078000000000003, -0.46168000000000003, 0.21266, -0.3409, 0.42267, -0.54487, 0.18641, -0.453]]
# Wir speichern den vorhergesagten Klassenwert in einer Variablen # "Vorhersagen" genannt. Vorhersagen = Logistic_Regression_Model.predict(Überwachung)
# Wir drucken die vorhergesagte Klasse des Modells für die Beobachtung.
drucken('Das Modell sagte voraus, dass die Beobachtung zur Klasse %s gehört'%(Vorhersagen))
Die Ausgabe zum vorherigen Codeblock sollte wie folgt aussehen::


# Wir sehen uns die spezifischen Klassen an, für die das Modell trainiert wurde, vorherzusagen.
drucken("Der Algorithmus wurde trainiert, um eine der beiden Klassen vorherzusagen": %S'%(algorithm.klassen_))
Die Ausgabe des vorherigen Codeblocks sieht wie folgt aus:


drucken("""Das Modell sagt, dass die Wahrscheinlichkeit der Beobachtung, die wir bestanden haben, zur Klasse gehört ['B'] Ist %s"""%(algorithm.predict_proba(Überwachung)[0][0]))
drucken()
drucken("""Das Modell sagt, dass die Wahrscheinlichkeit der Beobachtung, die wir bestanden haben, zur Klasse gehört ['g'] Ist %s"""%(algorithm.predict_proba(Überwachung)[0][1]))
Das erwartete Ergebnis wäre folgendes:

Fazit.
Damit ist mein Artikel abgeschlossen. Jetzt verstehen wir die Logik hinter diesem überwachten maschinellen Lernalgorithmus und wissen, wie wir ihn in ein binäres Klassifizierungsproblem implementieren können.
Vielen Dank für Ihre Zeit.
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von DataPeaker und werden nach Ermessen des Autors verwendet.





