De Maschinelles Lernen, Wir verwenden verschiedene Arten von Algorithmen, damit Maschinen die Beziehungen innerhalb der bereitgestellten Daten lernen und Vorhersagen basierend auf Mustern oder Regeln treffen können, die im Datensatz identifiziert wurden. Dann, Regression ist eine Technik des maschinellen Lernens, bei der das Modell die Ausgabe als fortlaufenden numerischen Wert vorhersagt.
Quelle: https://www.hindish.com
Regressionsanalyse wird häufig im Finanzwesen verwendet, Investitionen und andere, und entdecken Sie die Beziehung zwischen einer einzelnen abhängigen Variablen (Zielvariable) das hängt von mehreren unabhängigen. Zum Beispiel, Hauspreise vorhersagen, die Börse oder das Gehalt eines Mitarbeiters, usw. sind die häufigsten
Regressionsprobleme.
Die Algorithmen, die wir behandeln werden, sind:
1. Lineare Regression
2. Entscheidungsbaum
3. Vektorregression unterstützen
4. Schleifenregression
5. Zufälliger Wald
1. Lineare Regression
Lineare Regression ist ein maschineller Lernalgorithmus, der für überwachtes Lernen verwendet wird. Die lineare Regression übernimmt die Aufgabe, eine abhängige Variable vorherzusagen (Zielsetzung) als Funktion der gegebenen unabhängigen Variablen. Dann, Diese Regressionstechnik findet eine lineare Beziehung zwischen einer abhängigen Variablen und den anderen gegebenen unabhängigen Variablen. Deswegen, der Name dieses Algorithmus ist Lineare Regression.
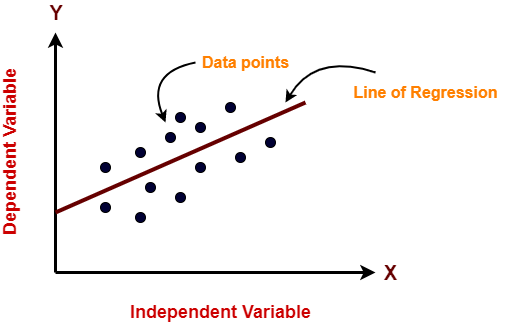
In der Abbildung oben, auf der X-Achse ist die unabhängige Variable und auf der Y-Achse ist die Ausgabe. Die Regressionsgerade ist die Linie, die am besten zu einem Modell passt. Und unser Hauptziel bei diesem Algorithmus ist es, die Linie zu finden, die am besten passt.
Vorteile:
- Lineare Regression ist einfach zu implementieren.
- Geringere Komplexität im Vergleich zu anderen Algorithmen.
- Lineare Regression kann zu Überanpassung führen, aber es kann vermieden werden, indem einige Dimensionsreduktionstechniken verwendet werden, Regularisierungs- und Kreuzvalidierungstechniken.
Nachteile:
- Ausreißer beeinträchtigen diesen Algorithmus stark.
- Es vereinfacht reale Probleme zu stark, indem es eine lineare Beziehung zwischen Variablen annimmt, daher nicht für praktische Anwendungsfälle empfohlen.
Implementierung
numpy als np importieren aus sklearn.linear_model import LinearRegression X = np.array([[2, 1], [3, 2], [4, 2], [5, 3]]) # y = 1 * x_0 + 2 * x_1 + 3 y = np.dot(x, np.array([1, 2])) + 3 lr = LinearRegression().fit(x, Ja) lr.vorhersagen(np.array([[1, 5]])) Ausgabe Array([14.])
2. Entscheidungsbaum
Entscheidungsbaummodelle können auf alle Daten angewendet werden, die numerische Merkmale und kategoriale Merkmale enthalten. Entscheidungsbäume sind gut darin, die nichtlineare Interaktion zwischen den Merkmalen und der Zielvariablen zu erfassen.. Entscheidungsbäume stimmen in gewisser Weise mit dem Denken auf menschlicher Ebene überein, daher ist es sehr intuitiv, die Daten zu verstehen.
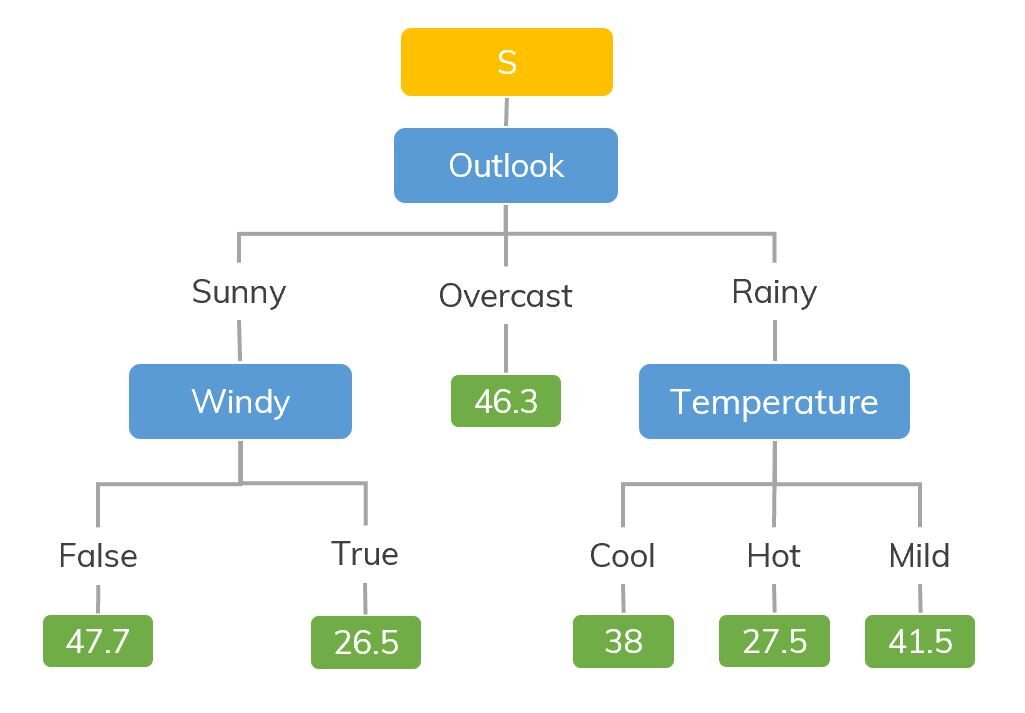
Quelle: https://dinhanhthi.com
Zum Beispiel, wenn wir klassifizieren, wie viele Stunden ein Kind in einem bestimmten Klima spielt, der Entscheidungsbaum sieht auf dem Bild ein bisschen so aus.
Dann, Zusammenfassend, Ein Entscheidungsbaum ist ein Baum, in dem jeder Knoten ein Merkmal darstellt, jeder Zweig steht für eine Entscheidung und jedes Blatt steht für ein Ergebnis (Zahlenwert für Regression).
Vorteile:
- Leicht zu verstehen und zu interpretieren, optisch intuitiv.
- Kann mit numerischen und kategorialen Merkmalen arbeiten.
- Benötigt wenig Datenvorverarbeitung: keine One-Hot-Codierung erforderlich, Dummy-Variablen, etc.
Nachteile:
- Neigt zur Überanpassung.
- Eine kleine Änderung der Daten bewirkt in der Regel einen großen Unterschied in der Baumstruktur, was verursacht instabilität.
Implementierung
numpy als np importieren aus sklearn.tree import DecisionTreeRegressor rng = np.random.RandomState(1) X = np.sort(5 * rng.rand(80, 1), Achse=0) y = np.sin(x).ravel() Ja[::5] += 3 * (0.5 - rng.rand(16)) # Regressionsmodell anpassen regr = EntscheidungsbaumRegressor(max_depth=2) regr.fit(x, Ja) # Vorhersagen X_test = np.arange(0.0, 5.0, 1)[:, z.B. newaxis] result = regr.vorhersage(X_test) drucken(Ergebnis) Ausgabe: [ 0.05236068 0.71382568 0.71382568 0.71382568 -0.86864256]
3. Vektorregression unterstützen
Sie müssen von SVM gehört haben, nämlich, Support-Vektor-Maschine. SVR verwendet auch die gleiche Idee von SVM, aber hier versucht es, die tatsächlichen Werte vorherzusagen. Dieser Algorithmus verwendet Hyperebenen, um die Daten zu trennen. Falls diese Trennung nicht möglich ist, Verwenden Sie also den Kernel-Trick, bei dem die Dimension zunimmt und die Datenpunkte durch die Hyperebene trennbar werden.
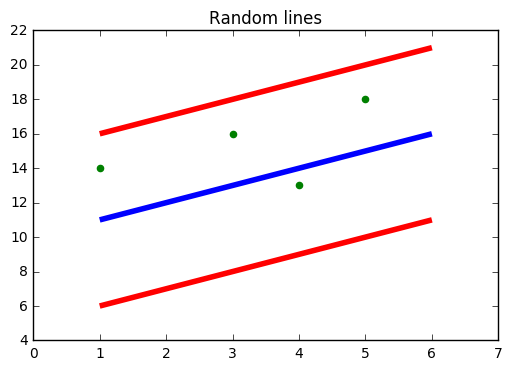
Quelle: https://www.medium.com
In der Abbildung oben, die blaue Linie ist die Hyperebene; Die rote Linie ist die Grenzlinie
Alle Datenpunkte liegen innerhalb der Grenzlinie (rote Linie). Das Hauptziel von SVR besteht im Wesentlichen darin, die Punkte zu berücksichtigen, die innerhalb der Grenzlinie liegen.
Vorteile:
- Robust gegenüber Ausreißern.
- Ausgezeichnete Generalisierbarkeit
- Hohe Vorhersagegenauigkeit.
Nachteile:
- Nicht geeignet für große Datensätze.
- Sie funktionieren nicht sehr gut, wenn der Datensatz mehr Rauschen enthält.
Implementierung
von sklearn.svm importieren SVR numpy als np importieren rng = np.random.RandomState(1) X = np.sort(5 * rng.rand(80, 1), Achse=0) y = np.sin(x).ravel() Ja[::5] += 3 * (0.5 - rng.rand(16)) # Regressionsmodell anpassen svr = SVR().fit(x, Ja) # Vorhersagen X_test = np.arange(0.0, 5.0, 1)[:, z.B. newaxis] svr.predict(X_test)
Ausgabe: Array([-0.07840308, 0.78077042, 0.81326895, 0.08638149, -0.6928019 ])
4. Schleifenregression
- LASSO steht für Absolute Minimum Selection Shrinkage Operator. Schrumpfung wird grundsätzlich als Attribut- oder Parametereinschränkung definiert.
- Der Algorithmus arbeitet, indem er eine Einschränkung auf die Attribute des Modells findet und anwendet, die dazu führt, dass die Regressionskoeffizienten einiger Variablen auf Null reduziert werden..
- Variablen mit einem Regressionskoeffizienten von Null werden aus dem Modell ausgeschlossen.
- Deswegen, Die Schleifenregressionsanalyse ist im Grunde eine Methode der Variablenauswahl und -kontraktion und hilft zu bestimmen, welche der Prädiktoren am wichtigsten sind.
Vorteile:
Nachteile:
- LASSO wählt nur ein Feature aus einer Gruppe korrelierter Features aus
- Ausgewählte Funktionen können stark verzerrt sein.
Implementierung
aus sklearn import linear_model numpy als np importieren rng = np.random.RandomState(1) X = np.sort(5 * rng.rand(80, 1), Achse=0) y = np.sin(x).ravel() Ja[::5] += 3 * (0.5 - rng.rand(16)) # Regressionsmodell anpassen lassoReg = linear_model.Lasso(alpha=0,1) lassoReg.fit(x,Ja) # Vorhersagen X_test = np.arange(0.0, 5.0, 1)[:, z.B. newaxis] lassoReg.predict(X_test)
Ausgabe: Array([ 0.78305084, 0.49957596, 0.21610108, -0.0673738 , -0.35084868])
5. Zufälliger Waldrückkehrer
Zufällige Wälder sind ein Set (Kombination) Entscheidungsbäume. Es handelt sich um einen überwachten Lernalgorithmus, der zur Klassifizierung und Regression verwendet wird. Eingabedaten werden durch mehrere Entscheidungsbäume geleitet. Es wird ausgeführt, indem zum Zeitpunkt des Trainings eine unterschiedliche Anzahl von Entscheidungsbäumen erstellt und die Klasse generiert wird, die der Modus der Klassen ist (zur Klassifizierung) oder mittlere Vorhersage (für Regression) einzelner Bäume.
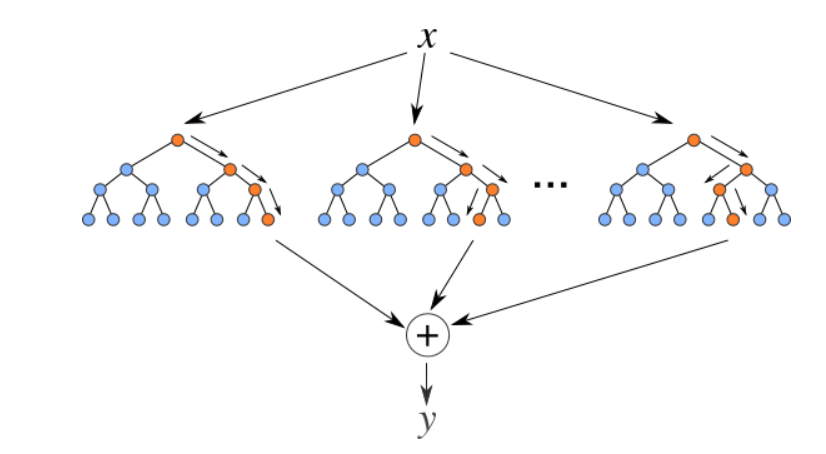
Quelle: https://levelup.gitconnected.com
Vorteile:
- Gut zum Erlernen komplexer und nichtlinearer Zusammenhänge
- Sehr leicht zu interpretieren und zu verstehen.
Nachteile:
- Sie neigen zu Überanpassungen
- Die Verwendung größerer Random Forest-Pools für eine höhere Leistung verlangsamt ihre Geschwindigkeit und benötigt dann auch mehr Speicher.
Implementierung
aus sklearn.ensemble importieren RandomForestRegressor aus sklearn.datasets import make_regression x, y = make_regression(n_features=4, n_informativ=2, random_state=0, shuffle=Falsch) rfr = RandomForestRegressor(max_depth=3) rfr.fit(x, Ja) drucken(rfr.vorhersage([[0, 1, 0, 1]])) Ausgabe: [33.2470716]
Abschließende Anmerkungen
Dies sind einige beliebte Regressionsalgorithmen, es gibt noch viel mehr und auch fortgeschrittene Algorithmen. Entdecke sie auch. Sie können diesen Klassifizierungsalgorithmen auch folgen, um Ihr Wissen über maschinelles Lernen zu erweitern.
Danke fürs Lesen, wenn du hier bist 🙂
Lass uns verbinden LinkedIn
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von Analytics Vidhya und werden nach Ermessen des Autors verwendet.





