Einführung
Das tiefes LernenTiefes Lernen, Eine Teildisziplin der Künstlichen Intelligenz, verlässt sich auf künstliche neuronale Netze, um große Datenmengen zu analysieren und zu verarbeiten. Diese Technik ermöglicht es Maschinen, Muster zu lernen und komplexe Aufgaben auszuführen, wie Spracherkennung und Computer Vision. Seine Fähigkeit, sich kontinuierlich zu verbessern, wenn mehr Daten zur Verfügung gestellt werden, macht es zu einem wichtigen Werkzeug in verschiedenen Branchen, von Gesundheit... está ganando fuerza rápidamente a messenDas "messen" Es ist ein grundlegendes Konzept in verschiedenen Disziplinen, , die sich auf den Prozess der Quantifizierung von Eigenschaften oder Größen von Objekten bezieht, Phänomene oder Situationen. In Mathematik, Wird verwendet, um Längen zu bestimmen, Flächen und Volumina, In den Sozialwissenschaften kann es sich auf die Bewertung qualitativer und quantitativer Variablen beziehen. Die Messgenauigkeit ist entscheidend, um zuverlässige und valide Ergebnisse in der Forschung oder praktischen Anwendung zu erhalten.... que surgen más y más artículos de investigación de todo el mundo. Zweifellos, diese Dokumente enthalten viele Informationen, aber sie können oft schwer zu analysieren sein. Und um sie zu verstehen, Möglicherweise müssen Sie dieses Dokument mehrmals überprüfen (Und vielleicht noch andere abhängige Dokumente!).
Dies ist wirklich eine gewaltige Aufgabe für Nicht-Akademiker wie uns..

Persönlich, Ich finde die Aufgabe, einen Forschungsartikel zu rezensieren, interpretieren Sie die Crux dahinter und implementieren Sie den Code als eine wichtige Fähigkeit, die jeder Deep-Learning-Enthusiast und -Praktiker besitzen sollte. Die praktische Umsetzung von Forschungsideen bringt den Denkprozess des Autors zum Vorschein und hilft auch, diese Ideen in reale Industrieanwendungen zu überführen..
Dann, In diesem Artikel (und die folgende Artikelserie) mein grund zu schreiben ist zweierlei:
- Lassen Sie die Leser mit der neuesten Forschung Schritt halten, indem Sie Deep-Learning-Artikel in verständliche Konzepte aufteilen.
- Lerne, Forschungsideen für mich selbst zu programmieren und ermutige die Leute, dies gleichzeitig zu tun.
In diesem Artikel wird davon ausgegangen, dass Sie die Grundlagen von Deep Learning gut verstehen.. Falls du es nicht brauchst, oder brauche einfach eine Auffrischung, Überprüfen Sie zuerst die folgenden Punkte und kommen Sie dann bald wieder hierher:
Inhaltsverzeichnis
- Dokumentzusammenfassung „Tauchen Sie ein in Windungen“
- Ziel der Arbeit
- Vorgeschlagene architektonische Details
- Trainingsmethodik
- GoogLeNet-Implementierung in Keras
Dokumentzusammenfassung „Tauchen Sie ein in Windungen“
Dieser Artikel konzentriert sich auf Papier „Mit Windungen tiefer graben“ woher die unverwechselbare Idee des Homenet kam. Das Heimnetzwerk galt einst als Architektur (das Model) Deep Learning der nächsten Generation zur Lösung von Bilderkennungs- und Erkennungsproblemen.
Herausragende bahnbrechende Leistung bei der ImageNet Visual Recognition Challenge (In 2014), Dies ist eine renommierte Plattform für das Benchmarking von Bilderkennungs- und -erkennungsalgorithmen. zusammen mit, Es wurde viel geforscht, um neue Deep-Learning-Architekturen mit innovativen und wirkungsvollen Ideen zu schaffen.
Wir werden die wichtigsten Ideen und Vorschläge des oben genannten Dokuments überprüfen und versuchen, die darin enthaltenen Techniken zu verstehen. In den Worten des Autors:
„In diesem Artikel, nos centraremos en una arquitectura de rotes neuronalesNeuronale Netze sind Rechenmodelle, die von der Funktionsweise des menschlichen Gehirns inspiriert sind. Sie nutzen Strukturen, die als künstliche Neuronen bekannt sind, um Daten zu verarbeiten und daraus zu lernen. Diese Netze sind grundlegend im Bereich der künstlichen Intelligenz, Dies ermöglicht erhebliche Fortschritte bei Aufgaben wie der Bilderkennung, Verarbeitung natürlicher Sprache und Vorhersage von Zeitreihen, unter anderen. Ihre Fähigkeit, komplexe Muster zu erlernen, macht sie zu mächtigen Werkzeugen.. profunda eficiente para la visión por computadora, dessen Codename Inception ist, was seinen Namen ableitet (…) das berühmte Internet-Meme“ wir müssen tiefer gehen „.

Das klingt faszinierend, Nein? Gut, Dann lies weiter!
Ziel der Arbeit
Es gibt eine einfache, aber leistungsstarke Möglichkeit, bessere Deep-Learning-Modelle zu erstellen. Du kannst einfach ein größeres Modell machen, entweder in Bezug auf die Tiefe, nämlich, Anzahl der Schichten, oder die Anzahl der Neuronen in jeder Schicht. Aber wie kannst du dir das vorstellen, das kann oft zu komplikationen führen:
- Je größer das Modell, anfälliger für Überanpassung. Esto es particularmente notable cuando los datos de AusbildungTraining ist ein systematischer Prozess zur Verbesserung der Fähigkeiten, körperliche Kenntnisse oder Fähigkeiten. Es wird in verschiedenen Bereichen angewendet, wie Sport, Aus- und Weiterbildung. Zu einem effektiven Trainingsprogramm gehört auch die Zielplanung, Regelmäßiges Üben und Bewerten der Fortschritte. Anpassung an individuelle Bedürfnisse und Motivation sind Schlüsselfaktoren, um in jeder Disziplin erfolgreiche und nachhaltige Ergebnisse zu erzielen.... son pequeños.
- Aumentar la cantidad de ParameterDas "Parameter" sind Variablen oder Kriterien, die zur Definition von, ein Phänomen oder System zu messen oder zu bewerten. In verschiedenen Bereichen wie z.B. Statistik, Informatik und naturwissenschaftliche Forschung, Parameter sind entscheidend für die Etablierung von Normen und Standards, die die Datenanalyse und -interpretation leiten. Ihre richtige Auswahl und Handhabung sind entscheidend, um genaue und relevante Ergebnisse in jeder Studie oder jedem Projekt zu erhalten.... significa que necesita aumentar sus recursos computacionales existentes
Eine Lösung dafür, wie das Dokument vorschlägt, ist der Wechsel zu lose verbundenen Netzwerkarchitekturen, die vollständig verbundene Netzwerkarchitekturen ersetzen werden, insbesondere innerhalb von Faltungsschichten. Diese Idee kann in den folgenden Bildern konzeptualisiert werden:
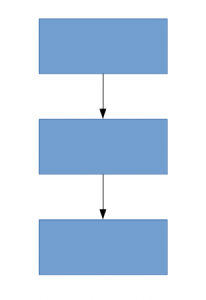
Dicht vernetzte Architektur
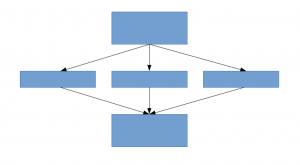
Schwach vernetzte Architektur
Dieser Artikel schlägt eine neue Idee zum Erstellen tiefer Architekturen vor. Dieser Ansatz ermöglicht es Ihnen, beizubehalten „Rechenbudget“, bei gleichzeitiger Erhöhung der Tiefe und Breite des Netzes. Klingt zu schön um wahr zu sein! So sieht die konzeptionierte Idee aus:
Schauen wir uns die vorgeschlagene Architektur etwas genauer an.
Vorgeschlagene architektonische Details
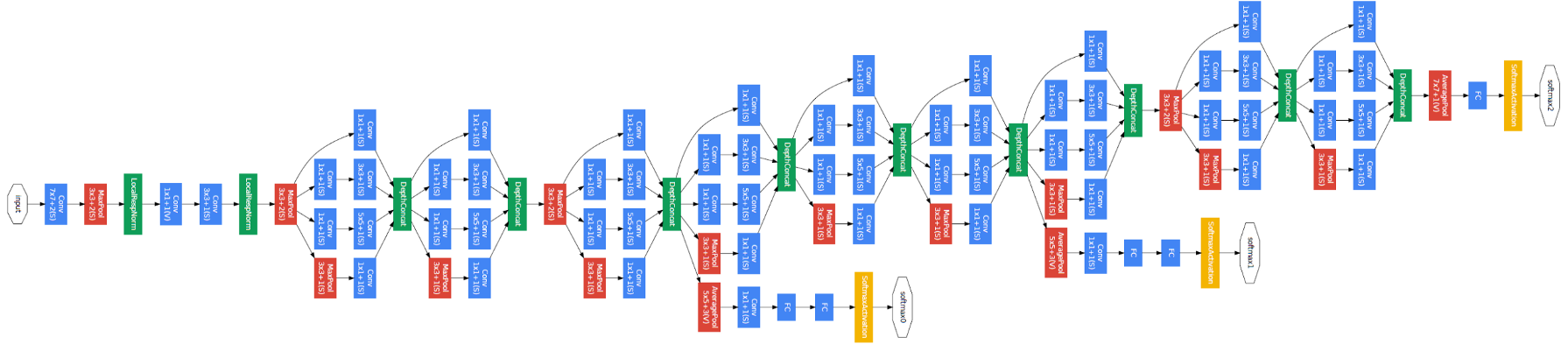
Das Dokument schlägt eine neue Art von Architektur vor: GoogLeNet oder Inception v1. Es básicamente una rote neuronale FaltungFaltungsneurale Netze (CNN) sind eine Art von neuronaler Netzwerkarchitektur, die speziell für die Datenverarbeitung mit einer Gitterstruktur entwickelt wurde, als Bilder. Sie verwenden Faltungsschichten, um hierarchische Merkmale zu extrahieren, Dies macht sie besonders effektiv bei Mustererkennungs- und Klassifizierungsaufgaben. Dank seiner Fähigkeit, aus großen Datenmengen zu lernen, CNNs haben Bereiche wie Computer Vision revolutioniert.. (CNN) Was stimmt damit nicht 27 Schichten tief.. Unten ist die Zusammenfassung des Modells:

Beachten Sie im obigen Bild, dass es eine Ebene gibt, die als Startebene bezeichnet wird. Dies ist eigentlich die Hauptidee hinter dem Fokus des Dokuments. Die erste Schicht ist das zentrale Konzept einer schlecht vernetzten Architektur.
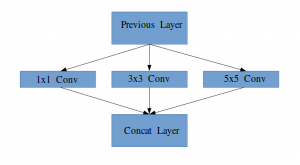
Idee eines Startermoduls
Lassen Sie mich etwas genauer erklären, worum es bei einer Startup-Schicht geht. Tomando un AuszugDer Extrakt ist eine Substanz, die durch Konzentration von Verbindungen pflanzlichen Ursprungs gewonnen wird, tierisch oder mineralisch. Einsatz in einer Vielzahl von Anwendungen, wie z.B. die Lebensmittelindustrie, Pharma & Kosmetik. Extrakte können in flüssiger Form präsentiert werden, in Pulverform oder als Tinktur, und seine Herstellung erfordert Techniken wie die Mazeration, Destillation oder Lösungsmittelextraktion. Seine Verwendung ermöglicht es, die vorteilhaften Eigenschaften der ursprünglichen Zutaten besser zu nutzen.. del artículo:
„(Ebene starten) es ist eine Kombination all dieser Schichten (nämlich, FaltdeckelDie Faltungsschicht, grundlegend in Convolutional Neural Networks (CNN), Es wird hauptsächlich für die Datenverarbeitung mit gitterartigen Strukturen verwendet, als Bilder. Dieser Layer wendet Filter an, die relevante Features extrahieren, wie Kanten und Texturen, Ermöglicht dem Modell, komplexe Muster zu erkennen. Seine Fähigkeit, die Dimensionalität von Daten zu reduzieren und wichtige Informationen zu speichern, macht es zu einem wichtigen Werkzeug für Computer-Vision-Aufgaben.. 1 × 1, Faltdeckel 3 × 3, Faltdeckel 5 × 5) mit ihren Ausgangsfilterbänken zu einem einzigen Ausgangsvektor verkettet, der die Eingabe des folgenden Szenarios bildet.“
Zusammen mit den oben genannten Schichten, Es gibt zwei Haupt-Plugins in der ursprünglichen Startebene:
- Faltdeckel 1 × 1 bevor Sie eine weitere Schicht auftragen, die hauptsächlich zur Dimensionsreduktion verwendet wird
- Eine parallele maximale Gruppierungsschicht, die eine weitere Option für die Startschicht bietet
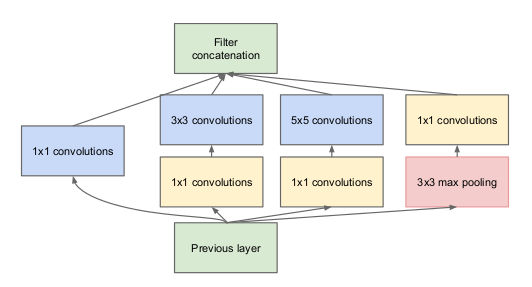
Ebene starten
Die Bedeutung der Struktur der Anfangsschicht verstehen, der Autor greift auf das hebbische Prinzip des menschlichen Lernens zurück. Das sagt das „Neuronen, die zusammen feuern, sie verbinden sich“. Der Autor schlägt vor, dass Beim Erstellen einer Beitragsebene in einem Deep-Learning-Modell, Es sollte auf die Erkenntnisse aus der vorherigen Schicht geachtet werden.
Vermuten, zum Beispiel, dass eine Schicht unseres Deep-Learning-Modells gelernt hat, sich auf einzelne Teile eines Gesichts zu konzentrieren. Die nächste Schicht des Netzwerks würde sich wahrscheinlich auf das allgemeine Gesicht des Bildes konzentrieren, um die verschiedenen dort vorhandenen Objekte zu identifizieren. Jetzt, um dies zu tun, der Layer muss die entsprechenden Filtergrößen haben, um verschiedene Objekte zu erkennen.
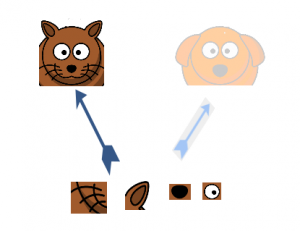
Hier kommt die erste Schicht in den Vordergrund. Ermöglicht den inneren Schichten die Auswahl der Filtergröße, die relevant ist, um die erforderlichen Informationen zu kennen. Dann, auch wenn die größe des gesichts auf dem bild unterschiedlich ist (wie auf den Bildern unten zu sehen), der Umhang funktioniert entsprechend, um das Gesicht zu erkennen. Für das erste Bild, du bräuchtest wahrscheinlich eine höhere Filtergröße, während ich für das zweite Bild ein niedrigeres nehmen würde.

Allgemeine Architektur, mit allen Spezifikationen, es sieht aus wie das:
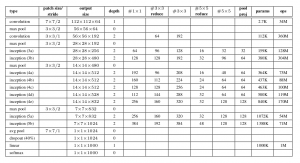
Trainingsmethodik
Beachten Sie, dass diese Architektur größtenteils darauf zurückzuführen ist, dass die Autoren an einer Herausforderung zur Bilderkennung und -erkennung teilgenommen haben.. Deswegen, Es gibt viele „Schnickschnack“ die sie im Dokument erklärt haben. Diese beinhalten:
- Die Hardware, mit der sie die Modelle trainiert haben.
- Die Datenerweiterungstechnik zum Erstellen des Trainingsdatensatzes.
- Die Hyperparameter des neuronalen Netzes, wie die Optimierungstechnik und das Lernratenprogramm.
- Zusatzausbildung zum Trainieren des Modells erforderlich.
- Montagetechniken, mit denen sie die Abschlusspräsentation erstellt haben.
Dazwischen, Die von den Autoren durchgeführte Hilfsausbildung ist von Natur aus sehr interessant und neu. Deshalb konzentrieren wir uns vorerst darauf.. Die Details der restlichen Techniken können dem Artikel selbst entnommen werden, oder in der Implementierung, die wir unten sehen werden.
Um zu verhindern, dass der mittlere Teil des Netzwerks "verschwindet", die Autoren führten zwei Hilfsklassifikatoren ein (die lila Quadrate im Bild). Grundsätzlich, legte Softmax auf die Ausgänge von zwei der Startermodule und berechnete einen Hilfsverlust auf den gleichen Labels. Das Verlust-FunktionDie Verlustfunktion ist ein grundlegendes Werkzeug des maschinellen Lernens, das die Diskrepanz zwischen Modellvorhersagen und tatsächlichen Werten quantifiziert. Ziel ist es, den Trainingsprozess zu steuern, indem dieser Unterschied minimiert wird, Dadurch kann das Modell effektiver lernen. Es gibt verschiedene Arten von Verlustfunktionen, wie z. B. mittlerer quadratischer Fehler und Kreuzentropie, jeder für unterschiedliche Aufgaben geeignet und... total es una suma ponderada de la pérdida auxiliar y la pérdida real. Der auf dem Papier verwendete Gewichtswert war 0,3 für jeden Hilfsverlust.
GoogLeNet-Implementierung in Keras
Jetzt haben Sie die GoogLeNet-Architektur und die Intuition dahinter verstanden, Es ist an der Zeit, Python zu starten und unsere Erkenntnisse mit Keras umzusetzen!! Dazu verwenden wir den CIFAR-10-Datensatz.

CIFAR-10 ist ein beliebter Datensatz zur Bildklassifizierung. Es besteht aus 60.000 Bilder von 10 Lektionen (jede Klasse wird im obigen Bild als Zeile dargestellt). Der Datensatz ist unterteilt in 50.000 Trainingsbilder und 10.000 Testbilder.
Denken Sie daran, dass Sie die erforderlichen Bibliotheken installiert haben müssen, um den Code zu implementieren, den wir in diesem Abschnitt sehen werden. Dazu gehören Keras und TensorFlow (als Backend für Keras). Sie können das überprüfen offizielle Installationsanleitung falls Sie Keras noch nicht auf Ihrem Computer installiert haben.
Jetzt haben wir uns um die Voraussetzungen gekümmert, wir können endlich damit beginnen, die Theorie zu codieren, die wir in den vorherigen Abschnitten behandelt haben. Als erstes müssen wir alle notwendigen Bibliotheken und Module importieren, die wir im gesamten Code verwenden werden.
importieren schwer
von harte.Schichten.Kern importieren Schicht
importieren keras.backend wie K
importieren Tensorfluss wie tf
von harte.datensätze importieren cifar10
von hart.models importieren Modell
von harte.schichten importieren Conv2D, MaxPool2D,
Aussteigen, Dicht, Eingang, verketten,
GlobalAveragePooling2D, DurchschnittPooling2D,
Ebnen
importieren cv2
importieren numpy wie z.B
von harte.datensätze importieren cifar10
von schwer importieren Backend wie K
von hard.utils importieren np_utils
importieren Mathematik
von harte.optimierer importieren SGD
von laute.rückrufe importieren LearningRateScheduler
Dann laden wir den Datensatz und führen einige Vorverarbeitungsschritte durch. Dies ist eine kritische Aufgabe, bevor das Deep-Learning-Modell trainiert wird.
Anzahl_Klassen = 10
def load_cifar10_data(img_rows, img_cols):
# cifar10 Trainings- und Validierungssets laden
(X_Zug, Y_Zug), (X_gültig, Y_gültig) = cifar10.lade Daten()
# Trainingsbilder skalieren
X_Zug = z.B.Array([cv2.Größe ändern(img, (img_rows,img_cols)) zum img In X_Zug[:,:,:,:]])
X_gültig = z.B.Array([cv2.Größe ändern(img, (img_rows,img_cols)) zum img In X_gültig[:,:,:,:]])
# Transformieren Sie Ziele in ein mit Keras kompatibles Format
Y_Zug = np_utils.to_kategorial(Y_Zug, Anzahl_Klassen)
Y_gültig = np_utils.to_kategorial(Y_gültig, Anzahl_Klassen)
X_Zug = X_Zug.astyp('float32')
X_gültig = X_gültig.astyp('float32')
# Daten vorverarbeiten
X_Zug = X_Zug / 255.0
X_gültig = X_gültig / 255.0
Rückkehr X_Zug, Y_Zug, X_gültig, Y_gültig
X_Zug, y_train, X_test, y_test = load_cifar10_data(224, 224)
Jetzt, wir werden unsere Deep-Learning-Architektur definieren. Dazu definieren wir schnell eine Funktion, das, wenn Sie die notwendigen Informationen erhalten, gibt die gesamte Startebene zurück.
def inception_module(x,
filter_1x1,
filter_3x3_reduzieren,
filter_3x3,
filter_5x5_reduzieren,
filter_5x5,
filter_pool_proj,
Name=Keiner):
conv_1x1 = Conv2D(filter_1x1, (1, 1), Polsterung='gleich', Aktivierung='relu', kernel_initializer=Kernel_init, bias_initializer=bias_init)(x)
conv_3x3 = Conv2D(filter_3x3_reduzieren, (1, 1), Polsterung='gleich', Aktivierung='relu', kernel_initializer=Kernel_init, bias_initializer=bias_init)(x)
conv_3x3 = Conv2D(filter_3x3, (3, 3), Polsterung='gleich', Aktivierung='relu', kernel_initializer=Kernel_init, bias_initializer=bias_init)(conv_3x3)
conv_5x5 = Conv2D(filter_5x5_reduzieren, (1, 1), Polsterung='gleich', Aktivierung='relu', kernel_initializer=Kernel_init, bias_initializer=bias_init)(x)
conv_5x5 = Conv2D(filter_5x5, (5, 5), Polsterung='gleich', Aktivierung='relu', kernel_initializer=Kernel_init, bias_initializer=bias_init)(conv_5x5)
pool_proj = MaxPool2D((3, 3), Schritte=(1, 1), Polsterung='gleich')(x)
pool_proj = Conv2D(filter_pool_proj, (1, 1), Polsterung='gleich', Aktivierung='relu', kernel_initializer=Kernel_init, bias_initializer=bias_init)(pool_proj)
Ausgang = verketten([conv_1x1, conv_3x3, conv_5x5, pool_proj], Achse=3, Name=Name)
Rückkehr Ausgang
Dann erstellen wir die GoogLeNet-Architektur, wie im Dokument erwähnt.
Kernel_init = schwer.Initialisierer.glorot_uniform()
bias_init = schwer.Initialisierer.Konstante(Wert=0.2)
input_layer = Eingang(Form=(224, 224, 3))
x = Conv2D(64, (7, 7), Polsterung='gleich', Schritte=(2, 2), Aktivierung='relu', Name='conv_1_7x7/2', kernel_initializer=Kernel_init, bias_initializer=bias_init)(input_layer)
x = MaxPool2D((3, 3), Polsterung='gleich', Schritte=(2, 2), Name='max_pool_1_3x3/2')(x)
x = Conv2D(64, (1, 1), Polsterung='gleich', Schritte=(1, 1), Aktivierung='relu', Name='conv_2a_3x3/1')(x)
x = Conv2D(192, (3, 3), Polsterung='gleich', Schritte=(1, 1), Aktivierung='relu', Name='conv_2b_3x3/1')(x)
x = MaxPool2D((3, 3), Polsterung='gleich', Schritte=(2, 2), Name='max_pool_2_3x3/2')(x)
x = inception_module(x,
filter_1x1=64,
filter_3x3_reduzieren=96,
filter_3x3=128,
filter_5x5_reduzieren=16,
filter_5x5=32,
filter_pool_proj=32,
Name='Anfang_3a')
x = inception_module(x,
filter_1x1=128,
filter_3x3_reduzieren=128,
filter_3x3=192,
filter_5x5_reduzieren=32,
filter_5x5=96,
filter_pool_proj=64,
Name='Anfang_3b')
x = MaxPool2D((3, 3), Polsterung='gleich', Schritte=(2, 2), Name='max_pool_3_3x3/2')(x)
x = inception_module(x,
filter_1x1=192,
filter_3x3_reduzieren=96,
filter_3x3=208,
filter_5x5_reduzieren=16,
filter_5x5=48,
filter_pool_proj=64,
Name='Anfang_4a')
x1 = DurchschnittPooling2D((5, 5), Schritte=3)(x)
x1 = Conv2D(128, (1, 1), Polsterung='gleich', Aktivierung='relu')(x1)
x1 = Ebnen()(x1)
x1 = Dicht(1024, Aktivierung='relu')(x1)
x1 = Aussteigen(0.7)(x1)
x1 = Dicht(10, Aktivierung='softmax', Name='auxilliary_output_1')(x1)
x = inception_module(x,
filter_1x1=160,
filter_3x3_reduzieren=112,
filter_3x3=224,
filter_5x5_reduzieren=24,
filter_5x5=64,
filter_pool_proj=64,
Name='Anfang_4b')
x = inception_module(x,
filter_1x1=128,
filter_3x3_reduzieren=128,
filter_3x3=256,
filter_5x5_reduzieren=24,
filter_5x5=64,
filter_pool_proj=64,
Name='Anfang_4c')
x = inception_module(x,
filter_1x1=112,
filter_3x3_reduzieren=144,
filter_3x3=288,
filter_5x5_reduzieren=32,
filter_5x5=64,
filter_pool_proj=64,
Name='inception_4d')
x2 = DurchschnittPooling2D((5, 5), Schritte=3)(x)
x2 = Conv2D(128, (1, 1), Polsterung='gleich', Aktivierung='relu')(x2)
x2 = Ebnen()(x2)
x2 = Dicht(1024, Aktivierung='relu')(x2)
x2 = Aussteigen(0.7)(x2)
x2 = Dicht(10, Aktivierung='softmax', Name='auxilliary_output_2')(x2)
x = inception_module(x,
filter_1x1=256,
filter_3x3_reduzieren=160,
filter_3x3=320,
filter_5x5_reduzieren=32,
filter_5x5=128,
filter_pool_proj=128,
Name='inception_4e')
x = MaxPool2D((3, 3), Polsterung='gleich', Schritte=(2, 2), Name='max_pool_4_3x3/2')(x)
x = inception_module(x,
filter_1x1=256,
filter_3x3_reduzieren=160,
filter_3x3=320,
filter_5x5_reduzieren=32,
filter_5x5=128,
filter_pool_proj=128,
Name='Anfang_5a')
x = inception_module(x,
filter_1x1=384,
filter_3x3_reduzieren=192,
filter_3x3=384,
filter_5x5_reduzieren=48,
filter_5x5=128,
filter_pool_proj=128,
Name='Anfang_5b')
x = GlobalAveragePooling2D(Name='avg_pool_5_3x3/1')(x)
x = Aussteigen(0.4)(x)
x = Dicht(10, Aktivierung='softmax', Name='Ausgang')(x)
Modell = Modell(input_layer, [x, x1, x2], Name='inception_v1')
Fassen wir unser Modell zusammen, um zu überprüfen, ob unsere bisherige Arbeit gut gelaufen ist.
Das Modell sieht gut aus, Wie können Sie aus der obigen Ausgabe messen?. Wir können noch den letzten Schliff hinzufügen, bevor wir unser Modell trainieren. Wir werden Folgendes definieren:
- Función de pérdida para cada Ausgabe-LayerDas "Ausgabe-Layer" ist ein Konzept, das im Bereich der Informationstechnologie und des Systemdesigns verwendet wird. Es bezieht sich auf die letzte Schicht eines Softwaremodells oder einer Architektur, die für die Präsentation der Ergebnisse für den Endbenutzer verantwortlich ist. Diese Schicht ist entscheidend für die Benutzererfahrung, Da es eine direkte Interaktion mit dem System und die Visualisierung der verarbeiteten Daten ermöglicht....
- Dieser Ausgabeschicht zugewiesene Gewichtung
- Optimierungsfunktion, die modifiziert wird, um nach jedem eine Gewichtsabnahme einzuschließen 8 Epochen.
- Bewertungsmetrik
Epochen = 25
initial_lrate = 0.01
def Verfall(Epoche, Schritte=100):
initial_lrate = 0.01
Tropfen = 0.96
epochs_drop = 8
lrate = initial_lrate * Mathematik.pow(Tropfen, Mathematik.Boden((1+Epoche)/epochs_drop))
Rückkehr lrate
sgd = SGD(lr=initial_lrate, Schwung=0.9, nesterov=Falsch)
lr_sc = LearningRateScheduler(Verfall, ausführlich=1)
Modell.kompilieren(Verlust=['kategoriale_Kreuzentropie', 'kategoriale_Kreuzentropie', 'kategoriale_Kreuzentropie'], verlust_gewichte=[1, 0.3, 0.3], Optimierer=sgd, Metriken=['Richtigkeit'])
Unser Modell ist nun fertig! Probieren Sie es aus, um zu sehen, wie es funktioniert.
Geschichte = Modell.fit(X_Zug, [y_train, y_train, y_train], Validierungsdaten=(X_test, [y_test, y_test, y_test]), Epochen=Epochen, batch_size=256, Rückrufe=[lr_sc])
Unten ist das Ergebnis, das ich beim Training des Modells erhalten habe:
Unser Modell lieferte eine beeindruckende Präzision der 80% + im Validierungsset, was zeigt, dass es sich wirklich lohnt, diese Modellarchitektur auszuprobieren.
Abschließende Anmerkungen
Dies war ein wirklich schöner Artikel zu schreiben und ich hoffe, Sie fanden ihn ebenso nützlich. Inception v1 stand im Mittelpunkt dieses Artikels, in dem ich das Wesentliche dieses Frameworks erklärte und demonstrierte, wie man es von Grund auf in Keras umsetzt.
In den nächsten Artikeln, Ich werde mich auf Fortschritte bei Inception-Architekturen konzentrieren. Diese Fortschritte wurden in späteren Artikeln detailliert beschrieben., nämlich, Einführung v2, Einführung v3, etc. Und wenn, sie sind so faszinierend wie der Name vermuten lässt, Also bleibt gespannt!
Wenn Sie Vorschläge haben / Kommentar zum Artikel, poste es im Kommentarbereich unten.





