Dieser Artikel wurde im Rahmen der Data Science Blogathon.
Der Guide ist hauptsächlich für Anfänger, und ich werde versuchen, die Themen so gut wie möglich zu definieren und hervorzuheben. Da Deep Learning ein sehr großes Thema ist, Ich würde das ganze Tutorial in ein paar Teile aufteilen. Lesen Sie unbedingt die anderen Teile, wenn Sie dies hilfreich finden.
Inhalt
1. Einführung
- Was ist Deep Learning??
- Warum Deep Learning??
- Wie viele Daten sind groß?
- Einsatzgebiete von Deep Learning
- Unterschied zwischen Deep Learning und Machine Learning
2) Importieren Sie die erforderlichen Bibliotheken
3) Zusammenfassung
4) Logistische Regression
- Computergrafik
- Parameter initialisieren
- Vorwärtsausbreitung
- Optimierung mit Gradient Descent
5) Logistische Regression mit Sklearn
6) Abschließende Anmerkungen
Einführung
Was ist Deep Learning??
- Es ist ein Teilgebiet des maschinellen Lernens, inspiriert von den biologischen Neuronen des Gehirns und deren Übersetzung in künstliche neuronale Netze mit Repräsentationslernen.
Warum Deep Learning??
- Wenn das Datenvolumen steigt, Techniken des maschinellen Lernens, egal wie optimiert sie sind, beginnen, in Bezug auf Leistung und Genauigkeit ineffizient zu werden, während Deep Learning in solchen Fällen viel besser funktioniert.
Wie viele Daten sind groß?
- Gut, ein Schwellenwert kann nicht quantifiziert werden, damit die Daten als groß angesehen werden, aber, intuitiv, Sagen wir, eine Probe von einer Million könnte ausreichen, um zu sagen “Ist groß” (hier hätte Michael Scott seine berühmten Worte ausgesprochen “Das hat sie gesagt”).
Felder, in denen DL verwendet wird
- Bildklassifizierung, Spracherkennung, PNL (Verarbeitung natürlicher Sprache), Empfehlungssysteme, etc.
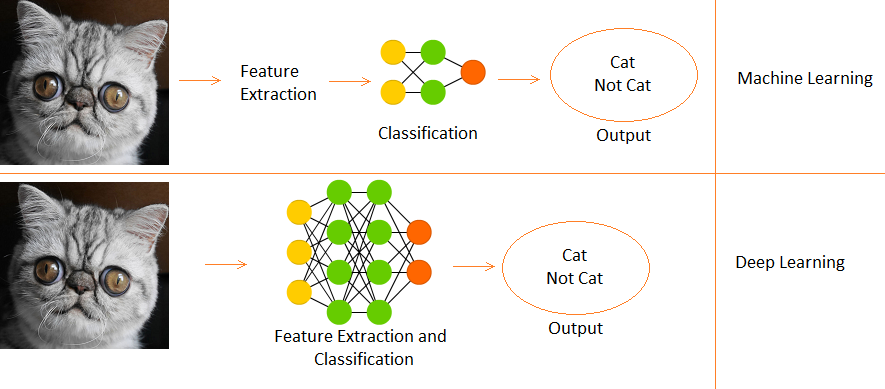
Unterschied zwischen Deep Learning und Machine Learning
- Deep Learning ist eine Teilmenge des maschinellen Lernens.
- De Maschinelles Lernen, Funktionen werden manuell bereitgestellt.
- Während Deep Learning Funktionen direkt aus Daten lernt.
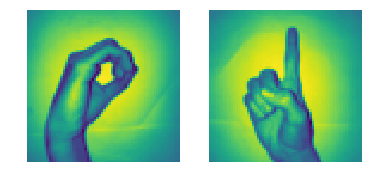
Wir werden die verwenden Datensatz von Ziffern in Gebärdensprache die auf Kaggle verfügbar ist hier. Jetzt fangen wir an.
Importieren Sie erforderliche Bibliotheken
numpy als np importieren # Lineare Algebra
Pandas als pd importieren # Datenverarbeitung, CSV-Datei I/O (z.B. pd.read_csv)
import matplotlib.pyplot als plt
# Eingabedatendateien sind im "../Eingang/" Verzeichnis.
# Importwarnungen
Importwarnungen
# Filterwarnungen
Warnungen.Filterwarnungen('ignorieren')
aus Unterprozessimport check_output
drucken(check_output(["ls", "../Eingang"]).dekodieren("utf8"))
# Alle Ergebnisse, die Sie in das aktuelle Verzeichnis schreiben, werden als Ausgabe gespeichert.

Zusammenfassung der Daten
- Es gibt 2062 Bilder von Gebärdensprachziffern in diesem Datensatz.
- Da gibt es 10 Ziffern von 0 al 9, Es gibt 10 einzigartige Signalbilder.
- Am Anfang, wir werden nur verwenden 0 Ja 1 (um es den Schülern einfach zu halten)
- In den Daten, das Handzeichen für 0 ist zwischen den Indizes 204 Ja 408. Es gibt 205 Proben für 0.
- Was ist mehr, das Handzeichen für 1 ist zwischen den Indizes 822 Ja 1027. Es gibt 206 Proben.
- Deswegen, wir werden verwenden 205 Proben jeder Klasse (Notiz: in Wirklichkeit, 205 Samples sind viel weniger für ein richtiges Deep-Learning-Modell, aber da es ein Tutorial ist, wir können es ignorieren),
Jetzt bereiten wir unsere X- und Y-Matrizen vor, wobei X unsere Bildmatrix ist (Merkmale) und Y ist unsere Etikettenmatrix (0 Ja 1).
# Datensatz laden
x_l = np.Last('../input/Gebärdensprache-Ziffern-Datensatz/X.npy')
Y_l = np.Last('../input/Gebärdensprache-Ziffern-Datensatz/Y.npy')
img_size = 64
plt.subplot(1, 2, 1)
plt.imshow(x_l[260].umformen(img_size, img_size))
plt.achse('aus')
plt.subplot(1, 2, 2)
plt.imshow(x_l[900].umformen(img_size, img_size))
plt.achse('aus')
# Verbinde eine Folge von Arrays entlang einer Zeilenachse.
# von 0 zu 204 ist Nullzeichen und von 205 zu 410 ist ein Zeichen
X = np.konkatenat((x_l[204:409], x_l[822:1027] ), Achse=0)
z = np.null(205)
o = np.ones(205)
Y = np.konkatenat((Mit, Ö), Achse=0).umformen(X.Form[0],1)
drucken("X-Form: " , X.Form)
drucken("Y-Form: " , Y.Form)

Um unsere Matrix X . zu erstellen, Wir teilen und verketten zuerst unsere Segmente von Handzeichenbildern von 0 Ja 1 vom Datensatz zur Matrix X. Dann, wir machen etwas ähnliches mit Y, aber wir verwenden stattdessen die Tags.
1) Wir sehen also, dass die Form unserer Matrix X ist (410, 64, 64)
- Das 410 es bedeutet 205 Bilder von 0, 205 Bilder von 1.
- das 64 bedeutet, dass die Größe unserer Bilder ist 64 x 64 Pixel.
2) Die Y-Form ist (410,1), Daher, 410 Einsen und Nullen.
3) Nun teilen wir X und Y in Züge und Testsätze auf.
- Zug = 75%, Zug = 15%
- random_state = Benutze einen bestimmten Seed beim Randomisieren, Daher, wenn die Zelle mehrmals läuft, die generierte Zufallszahl ändert sich nicht jedes Mal. Es wird jedes Mal das gleiche Test- und Zuglayout erstellt.
# Dann erstellen wir x_train, y_train, x_test, y_test-Arrays aus sklearn.model_selection import train_test_split X_Zug, X_test, Y_Zug, Y_test = train_test_split(x, Ja, test_size=0.15, random_state=42) number_of_train = X_train.shape[0] number_of_test = X_test.shape[0]
Wir haben eine dreidimensionale Eingabematrix, Also müssen wir es auf 2D reduzieren, um unser erstes Deep-Learning-Modell zu füttern. Wie und schon 2D, wir lassen es so wie es ist.
X_train_flatten = X_train.reshape(Anzahl_der_Zug,X_train.shape[1]*X_train.shape[2])
X_test_flatten = X_test .reshape(number_of_test,X_test.shape[1]*X_test.shape[2])
drucken("X-Zug abflachen",X_train_flatten.shape)
drucken("X-Test abflachen",X_test_flatten.shape)

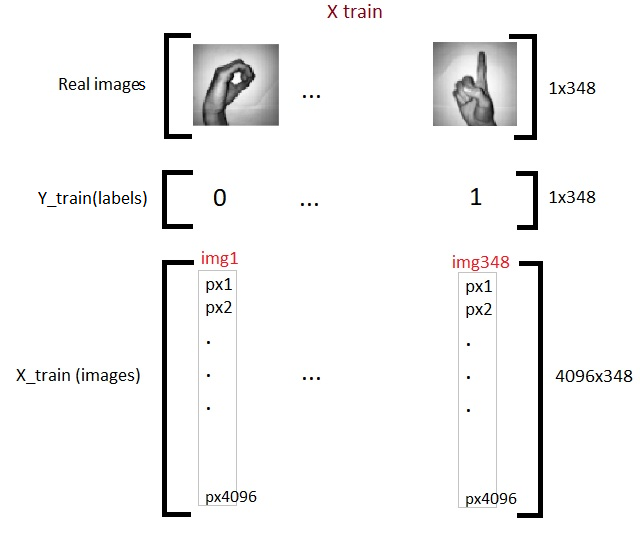
Wir haben jetzt insgesamt 348 Bilder, jeder mit 4096 Pixel in der Trainingsmatrix X. Ja 62 Bilder gleicher Pixeldichte 4096 in der Testmatrix. Nun transponieren wir die Matrizen. Dies ist nur eine persönliche Entscheidung und Sie werden in den nächsten Codes sehen, warum ich das sage.
x_train = X_train_flatten.T
x_test = X_test_flatten.T
y_train = Y_train.T
y_test = Y_test.T
drucken("x Zug: ",x_train.shape)
drucken("x-Test: ",x_test.shape)
drucken("dort Zug: ",y_train.shape)
drucken("du testest: ",y_test.shape)

Jetzt sind wir also mit der Vorbereitung unserer erforderlichen Daten fertig. So sieht es aus:
Jetzt lernen wir eines der Grundmodelle von Dl . kennen, sogenannte logistische Regression.
Logistische Regression
Wenn es um binäre Klassifikation geht, Das erste Modell, das mir in den Sinn kommt, ist die logistische Regression. Aber man könnte sich fragen, was die logistische Regression beim Deep Learning nützt.? Die Antwort ist einfach, da die logistische Regression ein einfaches neuronales Netz ist. Die Begriffe neuronales Netz und Deep Learning gehen Hand in Hand. Logistische Regression verstehen, Zuerst müssen wir etwas über Computergrafik lernen.
Berechnungstabelle
Computergrafik kann als bildhafte Darstellung mathematischer Ausdrücke angesehen werden. Lass uns das an einem Beispiel verstehen. Angenommen, wir haben einen einfachen mathematischen Ausdruck wie:
c = ( ein2 + B2 ) 1/2
Ihr Rechendiagramm wird:
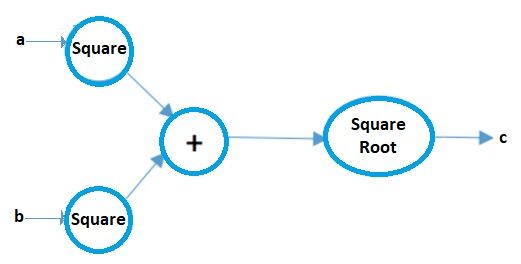
Bildquelle: Autor
Schauen wir uns nun einen logistischen Regressionsberechnungsgraphen an:
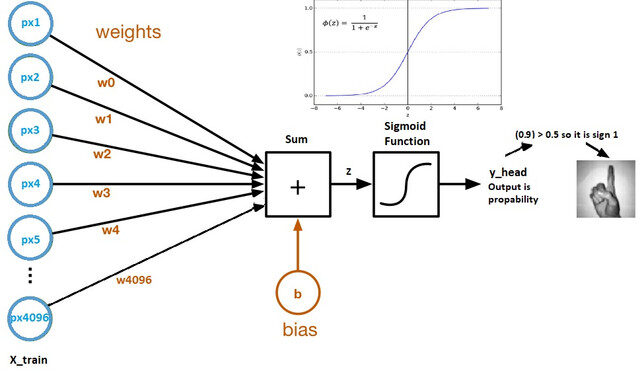
Bildquelle: Kaggle-Datensatz
- Die Gewichte und der Bias werden als Modellparameter bezeichnet.
- Die Gewichte repräsentieren die Koeffizienten jedes Pixels.
- Die Schiefe ist der Schnittpunkt der Kurve, die durch Auftragen von Parametern gegen Labels gebildet wird.
- Z = (px1 * wx1) + (px2 * wx2) +…. + (px4096 * wx4096)
- y_head = sigmoid_funktion (MIT)
- Die Sigmoidfunktion skaliert im Wesentlichen den Wert von Z zwischen 0 Ja 1, so wird es eine Wahrscheinlichkeit.
Warum die Sigmoid-Funktion verwenden??
- Es gibt uns ein probabilistisches Ergebnis.
- Da es ein Derivat ist, wir können es im Gradientenabstiegsalgorithmus verwenden.
Nun werden wir jede der Komponenten des obigen Berechnungsgraphen im Detail untersuchen.
Initialisierungsparameter
Bildquelle: Microsoft-Dokumente
Jedes Pixel hat sein eigenes Gewicht. Aber die Frage ist, was werden Ihre Anfangsgewichte sein?? Dafür gibt es mehrere Techniken, die ich in diesem Teil behandeln werde 2 dieses Artikels, Aber für den Moment, wir können sie mit einem beliebigen Zufallswert initialisieren, Sagen wir 0.01.
Die Form der Gewichtsmatrix ist (4096, 1), da es insgesamt 4096 Pixel pro Bild, und sei der anfängliche Bias 0.
# lasst uns Parameter initialisieren
# Was wir also brauchen, ist Dimension 4096 das ist die Anzahl der Pixel als Parameter für unsere Initialisierungsmethode(def)
def initialize_weights_and_bias(Abmessungen):
w = np.voll((Abmessungen,1),0.01)
b = 0.0
zurück w, B
w,b = initialize_weights_and_bias(4096)
Vorwärtsausbreitung
Alle Schritte von den Pixeln bis zur Kostenfunktion werden Vorwärtsausbreitung genannt.
Um Z zu berechnen, verwenden wir die Formel: Z = (wT) x + B. wobei x die Pixelmatrix ist, w gewichtet und b ist der Bias. Nach der Berechnung von Z, Wir führen es in die Sigmoid-Funktion ein, die y_head . zurückgibt (Wahrscheinlichkeit). Danach, wir berechnen die Verlustfunktion (Error).
Die Kostenfunktion ist die Summe aller Verluste und bestraft das Modell für falsche Vorhersagen. So lernt unser Modell die Parameter.
# Berechnung von z
#z = np.dot(w.T,x_train)+B
def sigmoid(Mit):
y_kopf = 1/(1+np.exp(-Mit))
zurück y_head
y_head = sigmoid(0) y_head > 0.5
Der mathematische Ausdruck der Verlustfunktion (Protokoll) es ist:
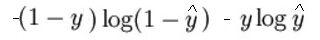
Wie ich bereits gesagt habe, Was die Verlustfunktion im Wesentlichen tut, ist, falsche Vorhersagen zu bestrafen. Hier ist der Code für die Vorwärtsausbreitung:
# Vorwärtsausbreitungsschritte:
# finde z = w.T*x+b
# y_head = sigmoid(Mit)
# Verlust(Error) = Verlust(Ja,y_head)
# Kosten = Summe(Verlust)
def forward_propagation(w,B,x_train,y_train):
z = z.B. zu(w.T,x_train) + B
y_head = sigmoid(Mit) # Wahrscheinlichkeitsrechnung 0-1
Verlust = -y_train*np.log(y_head)-(1-y_train)*np.log(1-y_head)
Kosten = (np.sum(Verlust))/x_train.shape[1] # x_train.shape[1] ist zum skalieren
Rücksendekosten
Optimierung mit Gradient Descent
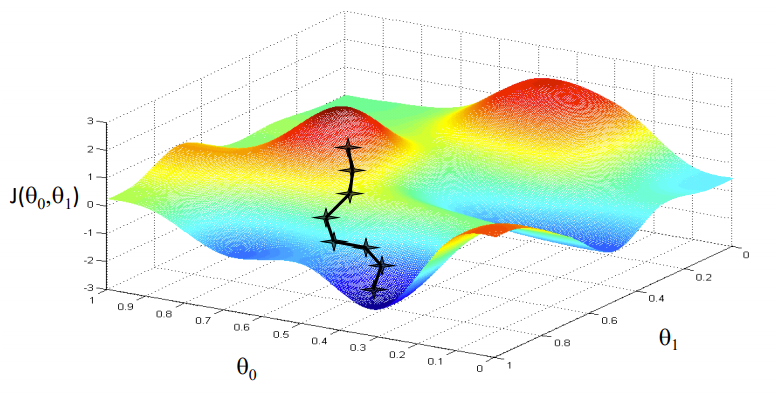
Bildquelle: Kursra
Unser Ziel ist es, die Werte unserer Parameter zu finden, für die, die Verlustfunktion ist das Minimum. Die Gleichung für den Gradientenabstieg lautet:
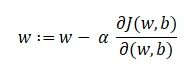
Wobei w das Gewicht oder der Parameter ist. Der griechische Buchstabe Alpha wird als Schrittweite bezeichnet. Was es bedeutet, ist die Größe der Iterationen, die wir nehmen werden, wenn wir den Hang hinuntergehen, um die lokalen Minima zu finden. Und der Rest ist die Ableitung der Verlustfunktion, auch bekannt als Gradient. Der Algorithmus für den Gradientenabstieg ist einfach:
- Zuerst, Wir nehmen einen zufälligen Datenpunkt in unserem Graphen und finden seine Steigung.
- Dann finden wir die Richtung, in der die Verlustfunktion abnimmt.
- Aktualisieren Sie die Gewichte mit der obigen Formel. (Diese Methode wird auch als Backpropagation bezeichnet.)
- Wählen Sie den nächsten Punkt mit einer Größe von α.
- Wiederholen.
# Bei der Rückwärtsausbreitung verwenden wir y_head, das in der Vorwärtsausbreitung gefunden wurde
# Anstatt also eine Rückwärtsausbreitungsmethode zu schreiben, Lassen Sie uns Vorwärtsausbreitung und Rückwärtsausbreitung kombinieren
def forward_backward_propagation(w,B,x_train,y_train):
# Vorwärtsausbreitung
z = np.dot(w.T,x_train) + B
y_head = sigmoid(Mit)
Verlust = -y_train*np.log(y_head)-(1-y_train)*np.log(1-y_head)
Kosten = (np.sum(Verlust))/x_train.shape[1] # x_train.shape[1] ist zum skalieren
# Rückwärtsausbreitung
Ableitungsgewicht = (np.dot(x_train,((y_head-y_train).T)))/x_train.shape[1] # x_train.shape[1] ist zum skalieren
derivative_bias = np.sum(y_head-y_train)/x_train.shape[1] # x_train.shape[1] ist zum skalieren
Steigungen = {"Ableitungsgewicht": Ableitungsgewicht,"derivative_bias": derivative_bias}
Rücksendekosten,Steigungen
Jetzt aktualisieren wir die Lernparameter:
# Aktualisierung(Lernen) Parameter
def aktualisieren(w, B, x_train, y_train, Lernrate,number_of_iterarion):
cost_list = []
cost_list2 = []
Index = []
# Aktualisierung(Lernen) Parameter ist number_of_iterarion mal
für mich in Reichweite(number_of_iterarion):
# Machen Sie Vorwärts- und Rückwärtsausbreitung und finden Sie Kosten und Gradienten
Kosten,Steigungen = forward_backward_propagation(w,B,x_train,y_train)
cost_list.append(Kosten)
# lass uns aktualisieren
w = w - Lernrate * Steigungen["Ableitungsgewicht"]
b = b - Lernrate * Steigungen["derivative_bias"]
wenn ich % 10 == 0:
cost_list2.append(Kosten)
index.anhängen(ich)
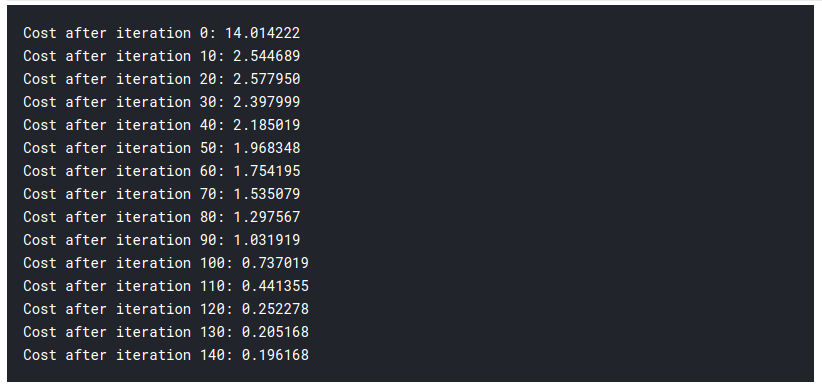
drucken ("Kosten nach Iteration %i: %F" %(ich, Kosten))
# wir aktualisieren(lernen) Parameter Gewichte und Bias
Parameter = {"Last": w,"Voreingenommenheit": B}
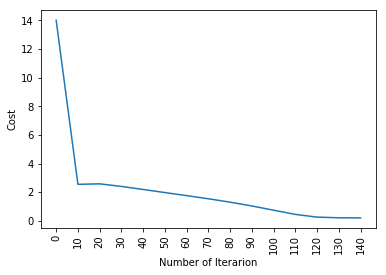
plt.plot(Index,cost_list2)
plt.xticks(Index,Rotation='vertikal')
plt.xlabel("Anzahl der Iterationen")
plt.ylabel("Kosten")
plt.zeigen()
Rückgabeparameter, Steigungen, Kostenliste
Parameter, Steigungen, cost_list = aktualisieren(w, B, x_train, y_train, Lernrate = 0,009, Anzahl_der_Iterarionen = 200)
Bisher, wir haben unsere Parameter gelernt. Das bedeutet, dass wir die Daten anpassen. Im Vorhersageschritt, Wir haben x_test als Eingabe und verwenden es, Wir machen Voraussagen.
# Vorhersage
auf jeden Fall vorhersagen(w,B,x_test):
# x_test ist eine Eingabe für die Vorwärtsausbreitung
z = sigmoid(np.dot(w.T,x_test)+B)
Y_Vorhersage = np.null((1,x_test.shape[1]))
# wenn z größer ist als 0.5, unsere Vorhersage ist Zeichen eins (y_head=1),
# wenn z kleiner als ist 0.5, unsere Vorhersage ist null (y_head=0),
für mich in Reichweite(z.Form[1]):
wenn z[0,ich]<= 0.5:
Y_Vorhersage[0,ich] = 0
anders:
Y_Vorhersage[0,ich] = 1
Y_Vorhersage zurückgeben
Vorhersagen(Parameter["Last"],Parameter["Voreingenommenheit"],x_test)
Jetzt machen wir unsere Vorhersagen. Lass uns alles zusammenfügen:
def logistische_regression(x_train, y_train, x_test, y_test, Lernrate , Anzahl_iterationen):
# initialisieren
Dimension = x_train.shape[0] # das ist 4096
w,b = initialize_weights_and_bias(Abmessungen)
# Lernrate nicht ändern
Parameter, Steigungen, cost_list = aktualisieren(w, B, x_train, y_train, Lernrate,Anzahl_iterationen)
y_prediction_test = vorhersagen(Parameter["Last"],Parameter["Voreingenommenheit"],x_test)
y_prediction_train = vorhersagen(Parameter["Last"],Parameter["Voreingenommenheit"],x_train)
# Zug-/Testfehler drucken
drucken("Zuggenauigkeit: {} %".Format(100 - np.mean(np.abs(y_prediction_train - y_train)) * 100))
drucken("Testgenauigkeit: {} %".Format(100 - np.mean(np.abs(y_prediction_test - y_test)) * 100))
logistische Regression(x_train, y_train, x_test, y_test,Lernrate = 0.01, Anzahl_iterationen = 150)

Dann, Wie du siehst, selbst das grundlegendste Modell des Deep Learning ist ziemlich schwierig. Es ist nicht leicht für dich zu lernen, und Anfänger fühlen sich manchmal überfordert, all dies auf einmal zu studieren. Aber die Sache ist die, wir haben Deep Learning noch nicht angerührt., das ist wie die oberfläche. Es gibt noch viel mehr, was ich in dem Teil hinzufügen werde 2 dieses Artikels.
Da wir die Logik hinter der logistischen Regression kennengelernt haben, Wir können eine Bibliothek namens SKlearn verwenden, die bereits viele der integrierten Modelle und Algorithmen enthält, damit du nicht alles bei null anfangen musst.
Logistische Regression mit Sklearn

Ich werde in diesem Abschnitt nicht viel erklären, da Sie fast die gesamte Logik und Intuition hinter der logistischen Regression kennen.. Wenn Sie mehr über die Sklearn-Bibliothek erfahren möchten, Sie können die offizielle Dokumentation lesen hier. Hier ist der Code, und ich bin sicher, Sie werden fassungslos sein, wie wenig Aufwand es braucht:
aus sklearn import linear_model
logreg = linear_model.LogisticRegression(random_state = 42,max_iter= 150)
drucken("Testgenauigkeit: {} ".Format(logreg.fit(x_train.T, y_train.T).Spielstand(x_test.T, y_test.T)))
drucken("Zuggenauigkeit: {} ".Format(logreg.fit(x_train.T, y_train.T).Spielstand(x_train.T, y_train.T)))

Jawohl! das ist alles was es brauchte, Solo 1 Codezeile!
Abschließende Anmerkungen
Wir haben heute viel gelernt. Aber das ist nur der Anfang. Schaut euch das Teil unbedingt an 2 dieses Artikels. Sie finden es unter folgendem Link. Wenn dir gefällt, was du liest, Sie können einige der anderen interessanten Artikel lesen, die ich geschrieben habe.
Sitten | Autor bei DataPeaker
Ich hoffe du hattest viel Spaß beim Lesen meines Artikels. Gesundheit!!
Die in diesem Artikel gezeigten Medien über die besten Bibliotheken für maschinelles Lernen in Julia sind nicht Eigentum von DataPeaker und werden nach Ermessen des Autors verwendet.





