Dieser Artikel wurde im Rahmen der Data Science Blogathon
war eine Plattform für Kunden, um Unternehmen basierend auf ihrer Zufriedenheit Feedback zu geben. Kundenbewertungen sind die weltweit vertrauenswürdigste Quelle für echte Inhalte für andere Benutzer. Das Kundenfeedback dient als Validierungsinstrument eines Drittanbieters, um Vertrauen in die Marke des Benutzers aufzubauen.. Um dieses Kundenfeedback zu einer Entität zu verstehen, Die Sentimentanalyse wird zu einem Ergänzungswerkzeug für jedes Unternehmen.
Die Stimmungsanalyse beinhaltet die Untersuchung von Online-Gesprächen wie Tweets, Blogposts oder Kommentare zu bestimmten Diensten oder Themen und trennen Nutzermeinungen (positiv, negativ und neutral), ermöglicht es Unternehmen, die Kundenstimmung gegenüber Produkten zu erkennen. Hilft Unternehmen mit einem tiefen Puls darüber, wie Kunden wirklich sind “Sie fühlen” über Ihre Marke und verarbeiten Sie große Datenmengen effizient und kostengünstig. Durch die automatische Analyse von Kundenfeedback, von Umfrageantworten bis hin zu Social-Media-Gesprächen, Marken können ihren Kunden aufmerksam zuhören und Produkte und Dienstleistungen an ihre Bedürfnisse anpassen.
Die Stimmungsanalyse kann als detailliert eingestuft werden, Emotionserkennung, aspektbasierte Sentimentanalyse und Intentionsanalyse. Detaillierte Sentimentanalyse befasst sich mit der Polarität der Interpretation im Rückblick, während die Emotionserkennung den emotionalen Ausdruck des Benutzers über ein Produkt beinhaltet.
Die aspektbasierte Sentimentanalyse ist eine Vielzahl von Sentimentanalysen, die bei der Verbesserung des Geschäfts helfen, indem sie die Eigenschaften Ihres Produkts kennen, die basierend auf Kundenfeedback verbessert werden müssen, um Ihr Produkt zu einem Bestseller zu machen.. ABSA identifiziert die Aspekte in der Bewertung zu einem Produkt und findet auch heraus, ob der in der Bewertung erwähnte Aspekt zu welcher Art von Stimmung gehört.
In diesem Artikel, Wir werden ABSA mit dem Laptop- und Restaurantdatensatz von SemEval durchführen 2014, sowie in mehrsprachigen Datensätzen wie dem Hindi-Datensatz auf Produkten wie Laptops, Telefone, Restaurants und Hotels.
Datenvorverarbeitung
Tokenización: Tokenisierung ist die Aufteilung des Textabsatzes in kleinere Abschnitte, als Sätze (Satztokenisierung) oder Worte (Wort-Tokenisierung). Der Hauptnachteil der Wort-Tokenisierung sind Wörter ohne Vokabular (OOV), um OOV zu vermeiden und auch Informationen aus der Textsatz-Tokenisierung zu extrahieren, die in dieser Analyse verwendet wird.
Leere Wörter entfernen: Nach der Tokenisierung, Stoppwörter werden erkannt und aus Tweets entfernt. Stoppwörter sind die häufigsten Wörter in einer Sprache, die dem Satz oder Dokument möglicherweise nicht viele Informationen hinzufügen. Diese Wörter werden gefiltert, um Rauschen zu minimieren und die Qualität der Textdaten für eine bessere Klassifizierung zu verbessern.. Die NLP-Bibliothek enthält eine Sammlung von Stoppwörtern für jede Sprache des Textes in NLTK. Die Wörter im Text werden mit dieser Stoppwortliste verglichen, Übereinstimmungswörter werden entfernt, um die Datenqualität zu verbessern und um leicht Stimmungswörter aus Tweets zu extrahieren.
Satzzeichen und Zeichen entfernen: Nach ausgedehnten Kontraktionen, Sonderzeichen und Satzzeichen werden durch die Regex-Funktion entfernt. Der Hauptgrund dafür ist, dass Satzzeichen oder Sonderzeichen bei der Analyse des Textes oft nicht sehr wichtig sind und sie verwenden, um Merkmale oder Informationen basierend auf NLP und ML zu extrahieren.
Ersetzen der Negation durch Antonyme: Das Ersetzen negativer Wörter durch Antonyme verringert die Dimensionalität der Wortanzahl der Dokumentmatrix, Daher ist es von Vorteil, das Vokabular zu komprimieren, ohne seine Bedeutung zu verlieren, um Speicher zu sparen.
von nltk.corpus import wordnet
Klasse AntonymReplacer(Objekt):
def ersetzen(selbst, Wort, pos=Keine):
Antonyme = set()
für syn in wordnet.syncets(Wort, pos = pos):
für Lemma in syn.lemmas():
für antonym in lemma.antonyms():
antonyms.add(antonym.name())
wenn len(Antonyme) == 1:
zurück antonyms.pop()
anders:
zurück
def replace_negations(selbst, gesendet):
ich, l = 0, len(gesendet)
Wörter = []
während ich < l:
Wort = gesendet[ich]
if word == 'nicht' und i+1 < l:
Ameise = self.replace(gesendet[ich+1])
wenn Ameise:
Wörter.anhängen(Ameise)
ich += 2
fortsetzen
Wörter.anhängen(Wort)
ich += 1
Wörter zurückgeben
Rechtschreibkorrektur: Wörter mit mehreren sich wiederholenden Zeichen und falscher Schreibweise, die aufgrund von menschlichen Tippfehlern auftreten, sollten entfernt werden, da sie generell egal sind. Zum Beispiel, Wörter wie endlichyy, Exakt, etc. sind falsche Eingaben, aber trotzdem, muss für die spätere Verwendung korrigiert werden.
Lematización: Stemming ist die gebräuchlichste Textvorverarbeitungstechnik für die Wortnormalisierung. Das Lemmatisieren eines Wortes wandelt das Wort in seine grundlegende bedeutungsvolle Form um, indem die morphologische Analyse jedes Wortes beobachtet wird. Stemming ist auch ähnlich wie Stemming, aber die erste berücksichtigt nicht den Kontext des Wortes im Satz und entfernt nur das Suffix in den Wörtern.
nltk.download('Wortnetz')
aus nltk.stem importieren WordNetLemmatizer
lemmatizer=WordNetLemmatizer()
antreplacer = AntonymReplacer()
def clean_text(Text):
#Lemmatisieren der Texte
# Entfernen von Aphostroph-Wörtern
text = text.lower() if pd.notnull(Text) sonst Text
text = re.sub(R"was ist", "was ist ",str(Text))
text = re.sub(R"'S", " ", str(Text))
text = re.sub(R"'und", " verfügen über ", str(Text))
text = re.sub(R"kippen", "kann nicht ", str(Text))
text = re.sub(ist es nicht, 'ist nicht', str(Text))
text = re.sub(Ich werde nicht, 'wird nicht', str(Text))
text = re.sub(R"nicht", " nicht ", str(Text))
text = re.sub(R"Ich bin", "ich bin ", str(Text))
text = re.sub(R"'betreffend", " sind ", str(Text))
text = re.sub(R"'D", " möchten ", str(Text))
text = re.sub(R"'NS", " Wille ", str(Text))
text = re.sub(R"'Entschuldigung", " Entschuldigung ", str(Text))
text = re.sub('W', ' ', str(Text))
text = re.sub('s+', ' ', str(Text))
# Satzzeichen und Zahlen entfernen
text = re.sub('[^ a-zA-Z]', ' ', str(Text))
# Entfernung einzelner Zeichen
text = re.sub(R"s+[a-zA-Z]s+", ' ', str(Text))
text=lemmatizer.lemmatize(Text)
# Verneinungswörter durch Antonyme ersetzen
text=antreplacer.replace(Text)
# Mehrere Leerzeichen entfernen
text = re.sub(r's+', ' ', str(Text))
text = text.strip(' ')
Rückgabetext
Klassifikatormodelle

Keying ist die Methode, die Wörter im Satz als Vektoren darzustellen. Die Einbettungstechnik, die wir verwenden werden, ist die GloVe-Einbettung, Konstruieren von Wort-Ko-Auftrittsmatrizen. Englische Sätze werden mit vortrainierten GloVe-Inlays trainiert und Inlays für Hindi-Sätze werden individuell mit 13 Millionen Hindi-Korpusdaten trainiert.
def get_word2vec_embedding_matrix(Modell):
Einbettungsmatrix = np.zeros((vocab_size,300))
für Wort, i in tokenizer.word_index.items():
Versuchen:
Einbettungsvektor = Modell[Wort]
außer KeyError:
embedding_vector = Keine
wenn embedding_vector nicht None ist:
Einbettungsmatrix[ich]=einbettender_vektor
embedding_matrix zurückgeben
Nach dem Satz werden Wörter mit GloVe Embedding in Vektoren umgewandelt, bidirektionale LSTM- und CNN-Modelle werden auf der Keying-Schicht angewendet, um Aspektterme und Sentimentterme zu trainieren und vorherzusagen, beziehungsweise. Das 1000 Die am häufigsten verwendeten Aspektbegriffe werden im Datensatz identifiziert und das Bi-LSTM-Modell wird trainiert und in diese Aspektklassen eingeordnet. Vorhergesagte Aspektbegriffe sind mit BIO . gekennzeichnet. Die Stimmung des gefundenen Aspektbegriffs wird mithilfe des CNN-Modells vorhergesagt, um die Bewertung als positiv zu klassifizieren, negativ und neutral.
einbetten_dim = 128 lstm_out = 196 Modell = Sequentiell() model.add(Einbettung(10000, embed_dim,input_length = 28)) model.add(Bidirektional(LSTM(lstm_out,return_sequences=Wahr))) model.add(LSTM(lstm_out, Ausfall=0,2, recurrent_dropout=0.2)) model.add(Beachtung()) model.add(Ebnen()) model.add(Aussteigen(0.3)) model.add(Dicht(1000, Aktivierung='Softmax')) model.compile(Verlust="kategoriale_Kreuzentropie", Optimierer="Adam", Metriken=['Richtigkeit']) Modell.Zusammenfassung()

history_object = model.fit(ZugX, trainY, Epochen=5,Batch_Größe=8)
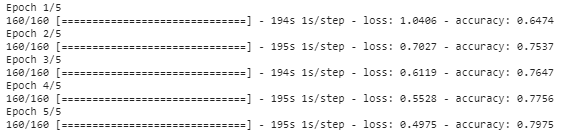
Zusammenfassung
In diesem Artikel, Wir haben verschiedene Vorverarbeitungstechniken auf Textrevisionen angewendet und Wörter werden mithilfe von GloVe-Einbettung in Vektordarstellungen umgewandelt. Die eingebettete Schicht wird mit der bidirektionalen LSTM-Schicht hinzugefügt, um die Aspektbegriffe im Satz zu finden, und Bahdanaus Aufmerksamkeit wird angewendet, um die Assoziation zwischen den Ziel- und den Kontextwörtern zu finden. Ermitteln Sie die Stimmungspolarität für jeden Aspektbegriff, der im obigen Modell gefunden und mit dem CNN-Modell vorhergesagt wurde, um den Aspektbegriff als positiv zu klassifizieren., negativ oder neutral. Aspektbegriffe, die aus dem Satz vorhergesagt werden, werden mit BIO-Tagging markiert, nämlich, Anfang, zwischen oder außerhalb des Aspektbegriffs.
Der vollständige Code für dieses Miniprojekt ist verfügbar hier.
Abschließende Anmerkungen
Ich hoffe, es hat Ihnen Spaß gemacht, diesen Artikel zu lesen.
Viel Spaß beim Lernen!!
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von DataPeaker und werden nach Ermessen des Autors verwendet.





