Dieser Artikel wurde im Rahmen der Data Science Blogathon.
Einführung
Big Data zeichnet sich oft durch: –
ein) Volumen: – Volumen bedeutet eine riesige und riesige Menge an Daten, die verarbeitet werden müssen.
B) Geschwindigkeit: – Die Geschwindigkeit, mit der Daten als Echtzeitverarbeitung ankommen.
C) Richtigkeit: – Wahrhaftigkeit bedeutet die Qualität der Daten (was eigentlich großartig sein muss, um Analyseberichte zu erstellen, etc.)
D) Vielfalt: – Es bedeutet die verschiedenen Arten von Daten wie
* Strukturierte Daten: – Daten im Tabellenformat.
* Unstrukturierte Daten: – Daten nicht im Tabellenformat
* Semistrukturierte Daten: – Mischung aus strukturierten und unstrukturierten Daten.
Um mit großen Datenbytes zu arbeiten, Zuerst müssen wir die Daten irgendwo speichern oder ablegen. Deswegen, die lösung dafür ist HDFS (Hadoop verteiltes Dateisystem).
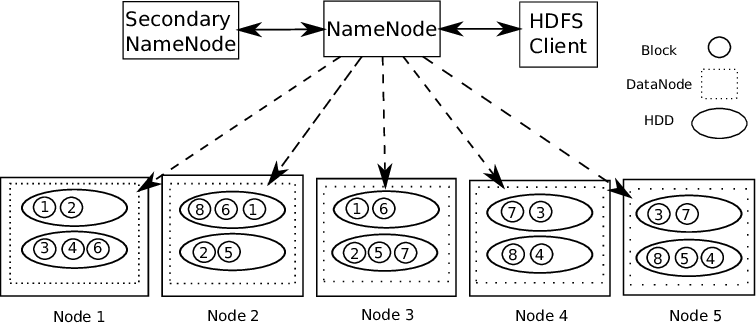
Hadoop unterstützt Master-Slave-Architektur. Es ist eine Art verteiltes System, in dem parallele Datenverarbeitung durchgeführt wird. Hadoop besteht aus 1 Master und mehrere Slaves.
Regelknoten benennen: – Für jeden gespeicherten Datenblock, Es gibt 2 Kopien vorhanden. Eine auf verschiedenen Datenknoten und eine zweite Kopie auf einem anderen Datenknoten. Daher, Fehlertoleranzproblem ist gelöst.
Der Namensknoten enthält die folgenden Informationen: –
1) Metadateninformationen für Dateien, die auf Datenknoten gespeichert sind. Metadaten bestehen aus 2 Aufzeichnungen: FsImage und EditLogs. FsImage besteht aus dem vollständigen Zustand des Dateisystems ab dem Start des Namensknotens. EditLogs enthält die letzten Änderungen, die am Dateisystem vorgenommen wurden.
2) Speicherort des im Datenknoten gespeicherten Dateiblocks.
3) Dateigröße.
Der Datenknoten enthält die eigentlichen Daten.
Deswegen, HDFS unterstützt Datenintegrität. Die gespeicherten Daten werden auf Korrektheit überprüft, indem die Daten mit ihrer Prüfsumme verglichen werden. Wenn Fehler erkannt werden, der Namensknoten wird gemeldet. Deswegen, erstellt zusätzliche Kopien derselben Daten und entfernt beschädigte Kopien.
HDFS besteht aus Sekundärer Namensknoten der gleichzeitig mit dem Haupt-Namensknoten als Helfer-Daemon arbeitet. Kein Backup-Namensknoten. Liest ständig alle Dateisysteme und Metadaten vom Name Node RAM auf die Festplatte. Es ist verantwortlich für die Kombination von EditLogs mit FSImage von Name Node.
Deswegen, HDFS ist wie ein Data Warehouse, in dem wir jede Art von Daten ablegen können. Die Verarbeitung dieser Daten erfordert Hadoop-Tools wie Hive (für den Umgang mit strukturierten Daten), HBase (für den Umgang mit unstrukturierten Daten), etc. Hadoop unterstützt das Konzept “Einmal schreiben, bereit für viele”.
Dann, Nehmen wir ein Beispiel und verstehen, wie wir mit Scala Language riesige Datenmengen verarbeiten und viele Transformationen durchführen können.
EIN) Eclipse-IDE-Konfiguration mit Scala-Konfiguration.
Link zum Herunterladen der Eclipse-IDE – https://www.eclipse.org/downloads/
Sie müssen die Eclipse-IDE herunterladen und dabei Ihre Computeranforderungen berücksichtigen. Beim Starten der Eclipse-IDE, Sie werden diese Art von Bildschirm sehen.

Gehe zu Hilfe -> Eclipse-Marktplatz -> Suche -> Scala-Idee -> Auf PC installieren
Danach in der Eclipse-IDE – auswählen Offene Perspektive -> Scala, Sie erhalten alle Scala-Komponenten in der ide zur Verwendung.
Erstellen Sie ein neues Projekt in Eclipse und aktualisieren Sie die pom-Datei mit den folgenden Schritten:https://medium.com/@manojkumardhakad/how-to-create-maven-project-for-spark-and-scala-in-scala-ide-1a97ac003883
Ändern Sie die scala-Bibliotheksversion, indem Sie mit der rechten Maustaste auf klicken Projekt -> Pfad erstellen -> Build-Pfad konfigurieren.
Aktualisieren Sie das Projekt, indem Sie mit der rechten Maustaste auf klicken Projekt -> Maven -> Maven-Projekt aktualisieren -> Snapshot-Aktualisierung erzwingen / Versionen. Deswegen, die pom-Datei wird gespeichert und alle erforderlichen Abhängigkeiten für das Projekt heruntergeladen.
Danach, Laden Sie die Spark-Version mit Hadoop-Winutils im Bin-Pfad herunter. Folgen Sie diesem Pfad, um die Einrichtung abzuschließen: https://stackoverflow.com/questions/25481325/how-to-set-up-spark-on-windows
B) Spark-Sitzungserstellung – 2 Typen.
Spark Session ist der Einstiegspunkt oder der Anfang zum Erstellen von RDDs, Datenrahmen, Datensätze. So erstellen Sie eine beliebige Spark-Anwendung, Zuerst brauchen wir eine Spark-Session.
Spark Session kann von 2 Typen: –
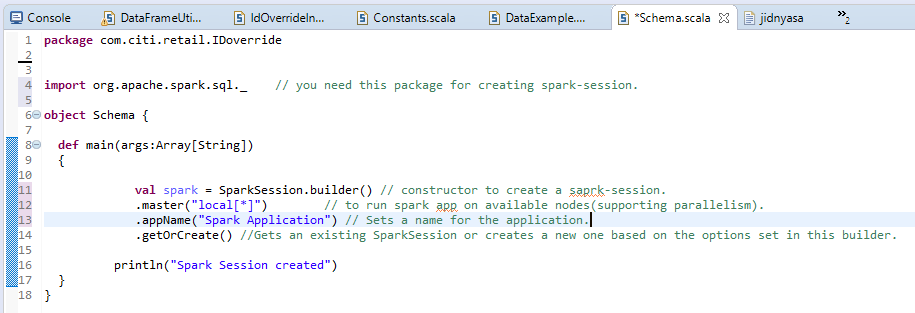
ein) Spark normale Sitzung: –
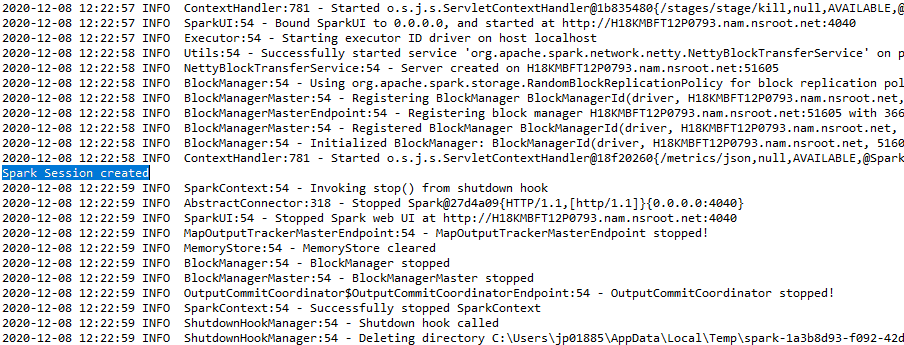
Die Ausgabe wird angezeigt als: –
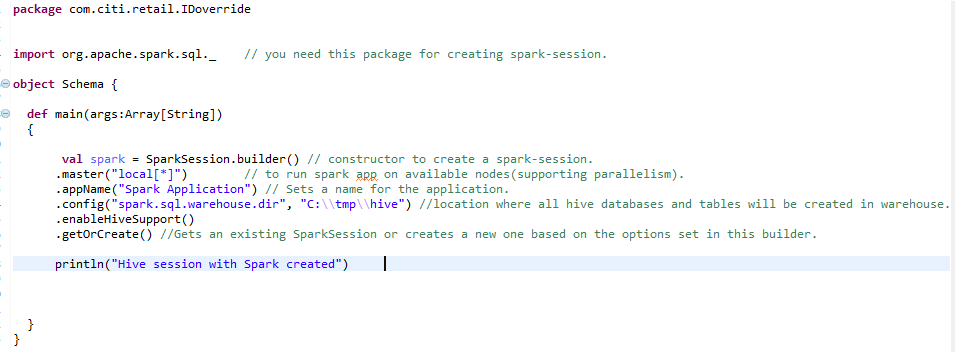
B) Spark-Sitzung für die Hive-Umgebung: –
So erstellen Sie eine skalierte Hive-Umgebung, wir brauchen die gleiche Spark-Session mit einer zusätzlichen Zeile. HiveSupport aktivieren () – Hive-Unterstützung aktivieren, einschließlich Konnektivität zum persistenten Hive-Metastore, Unterstützung für Hive-Serdes und benutzerdefinierte Hive-Funktionen.
C) RDD-Erstellung (Belastbarer verteilter Datensatz) und RDD in DataFrame umwandeln: –
Dann, nach dem ersten Schritt zum Erstellen von Spark-Session, es steht uns frei, RDD zu erstellen, Datensätze oder Datenrahmen. Dies sind die Datenstrukturen, in denen wir große Datenmengen speichern können.
Elastisch:- bedeutet Fehlertoleranz, damit sie fehlende oder beschädigte Partitionen aufgrund von Knotenausfällen neu berechnen können.
Verteilt:- bedeutet, dass die Daten auf mehrere Knoten verteilt sind (Macht der Parallelität).
Datensätze: – Daten, die extern geladen werden können und von beliebiger Form sein können, nämlich, JSON, CSV- oder Textdatei.
Zu den RDD-Funktionen gehören: –
ein) Berechnung im Speicher: – Nach der Durchführung von Transformationen an Daten, Ergebnisse werden im RAM statt auf der Festplatte gespeichert. Deswegen, RDD kann keine großen Datensätze verwenden. Die Lösung dafür ist, anstelle von RDD, Verwendung von DataFrame wird in Betracht gezogen / Datensatz.
B) Faule Bewertungen: – Das bedeutet, dass die Aktionen der durchgeführten Transformationen nur dann ausgewertet werden, wenn der Wert benötigt wird.
C) Fehlertoleranz: – Spark-RDDs sind fehlertolerant, da sie Datenherkunftsinformationen verfolgen, um verlorene Daten im Fehlerfall automatisch wiederherzustellen.
D) Unveränderlichkeit: – Unveränderliche Daten (nicht veränderbar) Sie können immer sicher über mehrere Prozesse hinweg geteilt werden. Wir können das RDD jederzeit neu erstellen.
mich) Aufteilung: – Es bedeutet, die Daten zu teilen, sodass jede Partition von verschiedenen Knoten ausgeführt werden kann, so wird die Datenverarbeitung schneller.
F) Beharrlichkeit:- Benutzer können auswählen, welche RDDs sie verwenden müssen und eine Speicherstrategie für sie auswählen.
Gramm) Grobkornoperationen: – Dies bedeutet, dass, wenn die Daten für verschiedene Operationen in verschiedene Cluster unterteilt sind, wir können Transformationen einmal für den gesamten Cluster anwenden und nicht für verschiedene Partitionen separat.
D) Verwenden des Datenrahmens und Ausführen von Transformationen: –
Beim Konvertieren von RDD in Datenrahmen, muss hinzufügen Spark.implicits._ importieren nach dem funken Sitzung.
Der Datenrahmen kann auf viele Arten erstellt werden. Sehen wir uns die verschiedenen Transformationen an, die auf den Datenrahmen angewendet werden können.
Paso 1:- Datenrahmen erstellen: –
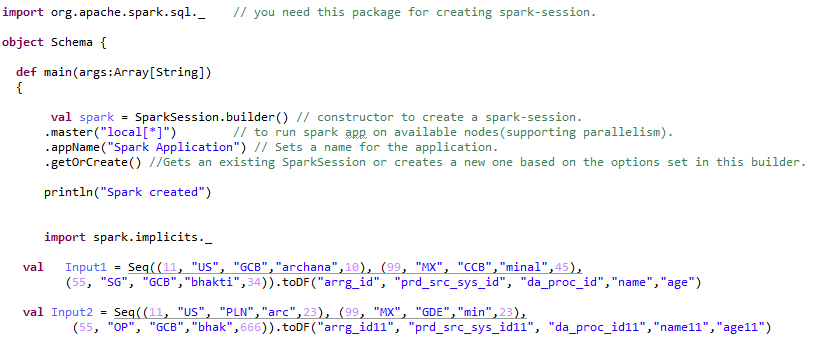
Paso 2:- Durchführen verschiedener Transformationstypen an einem Datenrahmen: –
ein) Bitte auswählen:- Wählen Sie die erforderlichen Spalten aus dem Datenrahmen, den der Benutzer benötigt.
Input1.select (“arrg_id”, “da_proc_id”). Zeigen ()

B) selectExpr: – Gewünschte Spalten auswählen und Spalten auch umbenennen.
Input2.selectExpr (“arrg_id11”, “prd_src_sys_id11 als prd_src_new”, “da_proc_id11”). Zeigen ()

C) mit Spalte: – withColumns hilft beim Hinzufügen einer neuen Spalte mit dem bestimmten Wert, den der Benutzer im ausgewählten Datenrahmen haben möchte.
Input1.withColumn (“New_col”, beleuchtet (Null))

D) mitSpalteUmbenannt: – Benennen Sie die Spalten des jeweiligen Datenrahmens um, den der Benutzer benötigt.
Input1.withColumnRenamed (“da_proc_id”, “da_proc_id_newname”)

mich) Tropfen:- Entfernen Sie die Spalten, die der Benutzer nicht möchte.
Input2.drop (“arrg_id11,” prd_src_sys_id11, “da_proc_id11”)
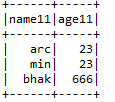
F) Einloggen:- EIN 2 Datenrahmen zusammen mit den Verbindungsschlüsseln beider Datenrahmen.
Eingabe1.beitreten (Eingang2, Input1.col (“arrg_id”) === Input2.col (“arrg_id11),” rechts “)
.mitSpalte (“prd_src_sys_id”, beleuchtet (Null))
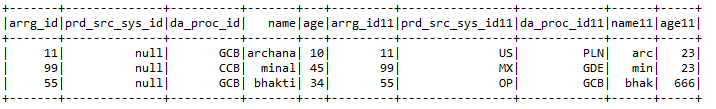
Gramm) Hinzugefügte Funktionen:- Einige der zusätzlichen Funktionen umfassen
* Erzählen:- Gibt die Anzahl einer bestimmten Spalte oder die Anzahl des gesamten Datenrahmens an.
println (Input1.count ())
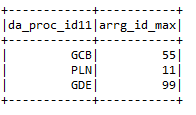
* Max .: – Gibt den maximalen Wert der Spalte gemäß einer bestimmten Bedingung an.
input2.groupBy (“da_proc_id”). max (“arrg_id”). mitSpalteUmbenannt (“max (arrg_id)”,
“Arrg_id_max”)
* Mindest: – Gibt einen Mindestwert der Datenrahmenspalte an.

h) Filter: – Filtern Sie die Spalten eines Datenrahmens, indem Sie eine bestimmte Bedingung ausführen.

ich) printSchema: – Geben Sie Details wie Spaltennamen an, Spaltendatentypen und ob Spalten nullablesbar sein können.
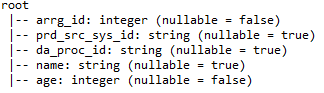
J) Union: – Kombinieren Sie die Werte von 2 Datenrahmen solange die Spaltennamen beider Datenrahmen gleich sind.
MICH) Bienenstock:-
Hive ist eine der am häufigsten verwendeten Datenbanken in Big Data. Es ist eine Art relationale Datenbank, in der die Daten in tabellarischer Form gespeichert werden. Die standardmäßige Hive-Datenbank ist die Derby. Bienenstockprozesse strukturiert und halbstrukturiert Daten. Bei unstrukturierten Daten, Erstellen Sie zuerst eine Tabelle im Hive und laden Sie die Daten in die Tabelle, gut strukturiert. Hive unterstützt alle primitiven SQL-Datentypen.
Bienenstock zugeben 2 Arten von Tabellen: –
ein) Verwaltete Tabellen: – Dies ist die Standardtabelle in Hive. Wenn der Benutzer eine Tabelle in Hive erstellt, ohne sie als extern anzugeben, standardmäßig, eine interne Tabelle wird an einer bestimmten Stelle in HDFS erstellt.
Standardmäßig, eine interne Tabelle wird in einem Ordnerpfad ähnlich wie erstellt / Nutzername / Bienenstock / Lager HDFS-Verzeichnis. Wir können den Standardstandort durch die Standorteigenschaft während der Tabellenerstellung überschreiben.
Wenn wir die Tabelle oder verwaltete Partition löschen, die Tabellendaten und die mit dieser Tabelle verknüpften Metadaten werden aus dem HDFS entfernt.
B) Externer Tisch: – Externe Tabellen werden außerhalb des Warehouse-Verzeichnisses gespeichert. Pueden acceder a los datos almacenados en fuentes como ubicaciones HDFS remotas o volúmenes de almacenamiento de Azure.
Siempre que dejamos caer la tabla externa, solo se eliminarán los metadatos asociados con la tabla, los datos de la tabla permanecen intactos por Hive.
Podemos crear la tabla externa especificando el EXTERNO palabra clave en la instrucción de tabla de creación de Hive.
Comando para crear una tabla externa.
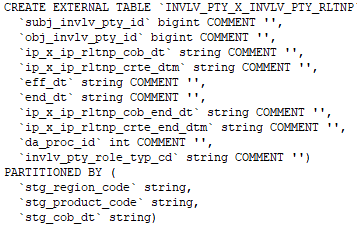
Comando para comprobar si la tabla creada es externa o no: –
desc con formato