Einführung
Heute, Organisationen verarbeiten eine große Menge und eine Vielzahl von Daten: Kundenanrufe, deine E-Mails, twittert, mobile App-Daten und mehr. Es braucht viel Mühe und Zeit, bis diese Daten nützlich sind. Eine der grundlegenden Fähigkeiten zum Extrahieren von Informationen aus Textdaten ist die Verarbeitung natürlicher Sprache (PNL).
Verarbeitung natürlicher Sprache (PNL) Es ist die Kunst und Wissenschaft, die uns hilft, Informationen aus dem Text zu extrahieren und in unseren Berechnungen und Algorithmen zu verwenden. Angesichts der Zunahme von Inhalten im Internet und in sozialen Netzwerken, ist eines der Must-haves für alle Data Scientists.
Ob Sie NLP kennen oder nicht, Dieser Leitfaden soll Ihnen als griffbereites Nachschlagewerk helfen. Durch diese Anleitung, Ich habe Ihnen Ressourcen und Codes zur Verfügung gestellt, um die gängigsten Aufgaben in NLP auszuführen.
Nachdem Sie diese Anleitung gelesen haben, Schaut gerne bei uns vorbei Videokurs zur Verarbeitung natürlicher Sprache (PNL).

Warum habe ich diese Anleitung erstellt?
Nachdem ich mich einige Zeit mit NLP-Problemen beschäftigt habe, Ich bin auf verschiedene Situationen gestoßen, in denen ich Hunderte verschiedener Quellen konsultieren musste, um die neuesten Entwicklungen in Form von Forschungsartikeln zu studieren, Blogs und Wettbewerbe für einige der gängigen NLP-Aufgaben. .
Dann, Ich beschloss, all diese Ressourcen an einem Ort zu sammeln und es zu einer One-Stop-Lösung für die neuesten und wichtigsten Ressourcen für diese gemeinsamen NLP-Aufgaben zu machen.. Unten finden Sie die Liste der Aufgaben, die in diesem Artikel behandelt werden, zusammen mit den entsprechenden Ressourcen.. Lasst uns beginnen.
Inhaltsverzeichnis
- Derivat
- Lematización
- Worteinlagen
- Wortart kennzeichnen
- Begriffsklärung für benannte Entität
- Erkennung benannter Entitäten
- Stimmungsanalyse
- Semantische Textähnlichkeit
- Spracherkennung
- Textzusammenfassung
1. Derivat
Was ist Stemming? ?: Ableitung ist der Prozess des Reduzierens von Wörtern (allgemein modifiziert oder abgeleitet) zu seiner Wurzel oder Wurzel des Wortes. Der Zweck der Wurzel besteht darin, die verwandten Wörter auf dieselbe Wurzel zu reduzieren, auch wenn die Wurzel kein Wörterbuchwort ist. Zum Beispiel, in der englischen sprache-
- hermosa Ja schön sind abgeleitet von Schönheit
- Beste Ja Beste sind abgeleitet von Beste Ja Beste beziehungsweise
Papier: das Originalartikel von Martin Porter in Porters Algorithmus zur Ableitung.
Algorithmus: Hier ist die Python-Implementierung des Porter2-Ableitungsalgorithmus.
Implementierung: So können Sie mit dem Porter2-Algorithmus ein Wort aus dem treibend Bücherei.
2. Lematización
Was ist Stemmen ?: Stemming ist der Prozess, eine Wortgruppe auf ihr Motto oder ihre Wörterbuchform zu reduzieren. Es berücksichtigt Dinge wie POS (Teile der Rede), die Bedeutung des Wortes im Satz, die Bedeutung des Wortes in engen Sätzen, etc. bevor du das Wort auf dein Motto reduzierst. Zum Beispiel, in der englischen sprache-
- hermosa Ja schön Sie sind Slogan zu hermosa Ja schön beziehungsweise.
- gut, Beste Ja Beste Sie sind Slogan zu gut, gut Ja gut beziehungsweise.
Dokumentieren 1: Dieses Papier bespricht die verschiedenen Methoden der Lemmatisierung ausführlich. Ein Muss, wenn Sie wissen möchten, wie traditionelle Stemmer funktionieren.
Dokumentieren 2: Das ist eine hervorragende Arbeit die das Problem des Stemming für variantenreiche Sprachen mittels Deep Learning anspricht.
Datensatz: Dies ist der Link zum Treebank-3-Datensatz die Sie verwenden können, wenn Sie Ihren eigenen Lemmatiser erstellen möchten.
Implementierung: Unten ist eine Implementierung eines englischen Lemmatizers mit spacy.
#!pip install spacy#python -m spacy download enimport spacynlp=spacy.load("en")doc="good better best"
for token in nlp(doc): print(token,token.lemma_)
3. Worteinlagen
Was sind Worteinbettungen ?: Word Embeddings ist der Name der Techniken, die verwendet werden, um natürliche Sprache in Vektorform von reellen Zahlen darzustellen. Sie sind nützlich, da Computer nicht in der Lage sind, natürliche Sprache zu verarbeiten. Dann, Diese Worteinlagen erfassen die Essenz und die Beziehung zwischen Wörtern in natürlicher Sprache mit reellen Zahlen. Und Worteinbettung, una palabra o frase se representa en un vector de Abmessungen"Dimension" Es handelt sich um einen Begriff, der in verschiedenen Disziplinen verwendet wird, wie z.B. Physik, Mathematik und Philosophie. Er bezieht sich auf das Ausmaß, in dem ein Objekt oder Phänomen analysiert oder beschrieben werden kann. In der Physik, zum Beispiel, Es ist die Rede von räumlichen und zeitlichen Dimensionen, während es sich in der Mathematik auf die Anzahl der Koordinaten beziehen kann, die notwendig sind, um einen Raum darzustellen. Es zu verstehen, ist grundlegend für das Studium und... fija de longitud, Sagen wir 100.
Zum Beispiel-
Ein Wort „Mann“ kann in einem Vektor von dargestellt werden 5 Maße wie
![]()
wobei jede dieser Zahlen die Größe des Wortes in einer bestimmten Richtung ist.
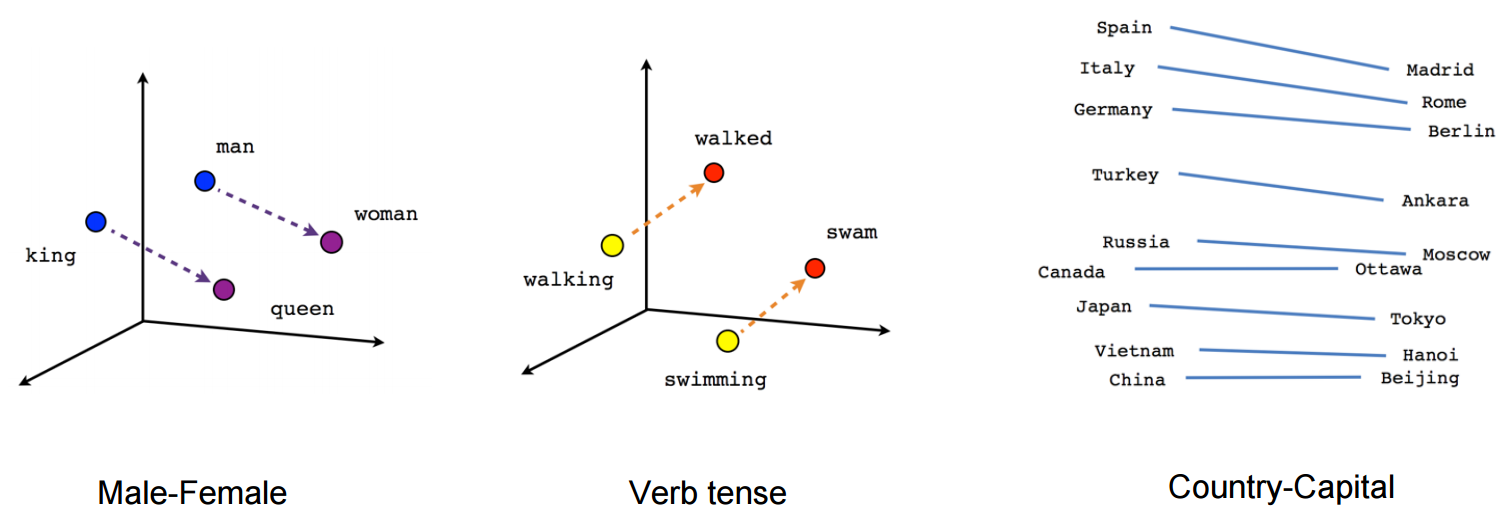
Blog: Hier ist ein Artikel, der Word-Einbettungen im Detail erklärt.
Papier: Eine sehr gute Rolle was Wortvektoren im Detail erklärt. Ein Muss für ein tiefes Verständnis von Wortvektoren.
Werkzeug: Ein browserbasiertes Werkzeug zum Visualisieren von Wortvektoren.
Vortrainierte Wortvektoren: Hier ist eine vollständige Liste von Vortrainierte Wortvektoren In 294 Sprachen von Facebook.
Implementierung: So erhalten Sie mit dem Gensim-Paket einen vortrainierten Ein-Wort-Wortvektor.
Laden Sie die . herunter Wortvektoren, die zuvor von hier aus in Google News trainiert wurden.
#!pip install gensimfrom gensim.models.keyedvectors import KeyedVectorsword_vectors=KeyedVectors.load_word2vec_format('GoogleNews-vectors-negative300.bin',binary=True)word_vectors['human']
Implementierung: So trainieren Sie Ihre eigenen Wortvektoren mit Gensim
sentence=[['first','sentence'],['second','sentence']]model = gensim.models.Word2Vec(sentence, min_count=1,size=300,workers=4)
4. Wortart kennzeichnen
Was ist Part Speech Tagging? ?: Vereinfacht gesagt, Part-of-Speech-Tagging ist das Markieren von Wörtern in einem Satz als Substantive, Verben, Adjektive, Adverbien, etc.. Zum Beispiel, in dem Satz-
„Ashok tötete die Schlange mit einem Stock“
Die Wortarten werden identifiziert als:
Ashok PROPN
empfindlich VERB
das DAS
Schlange SUBSTANTIV
mit ADP
ein DAS
palo SUBSTANTIV
. PUNKT
Prüfen 1: Dies passend betitelte Choi-Rolle Die ultimative Essenz auf dem neuesten Stand der Technik führt eine neuartige Methode namens Dynamic Feature Induction ein, die den Stand der Technik bei POS-Tagging-Aufgaben erreicht
Dokumentieren 2: Dieses Papier Führt unbeaufsichtigte POS-Etikettierung mit Anchor Hidden Markov-Modellen ein.
Implementierung: So können wir POS-Tagging mit spacy durchführen.
#!pip install spacy#!python -m spacy download en nlp=spacy.load('en')sentence="Ashok killed the snake with a stick"for token in nlp(sentence): print(token,token.pos_)
5. Begriffsklärung für benannte Entität
Was ist die Begriffsklärung für benannte Entitäten? ?: Die Begriffsklärung bei benannten Entitäten ist der Prozess zur Identifizierung von Entitätenerwähnungen in einem Satz. Zum Beispiel, in dem Satz-
„Apple erzielte einen Umsatz von 200 Milliarden Dollar in 2016“
Es ist die Aufgabe von Designation of Named Entities, daraus abzuleiten, dass Apple in dem Satz das Apple-Unternehmen und keine Frucht ist..
Benannte Entität, allgemein, erfordert eine Entitäts-Wissensdatenbank, die Sie verwenden können, um Entitäten im Satz mit der Wissensdatenbank zu verknüpfen.
Dokumentieren 1: Dieser Artikel von Huang nutzt Deep-Neural-Network-basierte Deep-Semantic-Relationship-Modelle in Verbindung mit der Wissensdatenbank, um hochmoderne Ergebnisse bei der Disambiguierung von benannten Entitäten zu erzielen.
Dokumentieren 2: Dieser Artikel von Ganea und Hofmann Nutzen Sie lokale neuronale Aufmerksamkeit zusammen mit Word-Einbettungen und ohne manuell erstellte Funktionen.
6. Erkennung benannter Entitäten
Was ist die Named Entity Recognition? ?: Die Named-Entity-Erkennung ist die Aufgabe, Entitäten in einem Satz zu identifizieren und sie in Kategorien wie eine Person einzuordnen, Organisation, Datum, Ort, Zeit, etc. Zum Beispiel, ein NER würde einen Satz nehmen wie:
„Ram von Apple Inc. reiste nach Sydney am 5 Oktober 2017“
und gibt etwas zurück wie
RAM
von
Apfel ORG
C ª. ORG
reiste
zu
Sydney GPE
Über
Fünfte DATUM
Oktober DATUM
2017 DATUM
Hier, ORG steht für Organisation und GPE steht für Location.
Das Problem bei aktuellen NERs besteht darin, dass selbst NERs der nächsten Generation dazu neigen, eine unterdurchschnittliche Leistung zu erbringen, wenn sie in einer Datendomäne verwendet werden, die sich von den Daten unterscheidet, mit denen das NER trainiert wurde..

Papier: Dieses ausgezeichnete Papier verwendet bidirektionale LSTMs und kombiniert überwachte und unüberwachte Lernmethoden, um ein State-of-the-Art-Ergebnis bei der Erkennung von Named Entities in . zu erreichen 4 Sprachen.
Implementierung: Dann, erklärt, wie Sie die Erkennung von benannten Entitäten mit spacy durchführen können.
import spacynlp=spacy.load('en')sentence="Ram of Apple Inc. travelled to Sydney on 5th October 2017"for token in nlp(sentence): print(token, token.ent_type_)
7. Stimmungsanalyse
Was ist Sentimentanalyse ?: Die Stimmungsanalyse ist ein breites Spektrum an subjektiver Analyse, die Techniken der Verarbeitung natürlicher Sprache verwendet, um Aufgaben wie die Identifizierung der Stimmung einer Kundenbewertung durchzuführen., positives oder negatives Gefühl in einem Satz, Beurteilen Sie die Stimmung mithilfe von Sprachanalyse oder schriftlicher Textanalyse, etc. Zum Beispiel:
"Ich mochte das Schokoladeneis nicht" – Es ist eine negative Eiscreme-Erfahrung.
„Ich habe Schokoladeneis nicht gehasst“: kann als neutrale Erfahrung angesehen werden
Es gibt eine Vielzahl von Methoden, die verwendet werden, um eine Sentiment-Analyse durchzuführen, vom Zählen negativer und positiver Wörter in einem Satz bis hin zur Verwendung von LSTM mit Worteinlagen.
Blog 1: Dieser Artikel konzentriert sich auf die Durchführung von Stimmungsanalysen zu Film-Tweets
Blog 2: Dieser Artikel konzentriert sich auf die Durchführung einer Sentimentanalyse von Tweets während der Chennai-Flut.
Dokumentieren 1: Dieses Papier adopta el enfoque del método de überwachtes LernenÜberwachtes Lernen ist ein Ansatz des maschinellen Lernens, bei dem ein Modell mit einem Satz von beschrifteten Daten trainiert wird. Jede Eingabe im Dataset ist mit einer bekannten Ausgabe verknüpft, So kann das Modell lernen, Ergebnisse für neue Eingaben vorherzusagen. Diese Methode wird häufig in Anwendungen wie der Bildklassifizierung eingesetzt., Spracherkennung und Trendvorhersage, und unterstreicht seine Bedeutung in... con el método Naive Bayes para clasificar las revisiones de IMDB.
Dokumentieren 2: Dieses Papier utiliza el método de Unüberwachtes LernenUnüberwachtes Lernen ist eine Technik des maschinellen Lernens, die es Modellen ermöglicht, Muster und Strukturen in Daten ohne vordefinierte Beschriftungen zu identifizieren. Durch Algorithmen wie k-means und Hauptkomponentenanalyse, Dieser Ansatz wird in einer Vielzahl von Anwendungen eingesetzt, wie z. B. Kundensegmentierung, Anomalieerkennung und Datenkomprimierung. Seine Fähigkeit, verborgene Informationen preiszugeben, macht es zu einem wertvollen Werkzeug in der... con LDA para identificar aspectos y sentimientos de las opiniones generadas por los usuarios. Dieses Dokument zeichnet sich dadurch aus, dass es das Problem des Mangels an kommentierten Rezensionen anspricht..
Repository: Dies ist ein großartiges Repository von Forschungsarbeiten und Durchführung von Sentiment-Analysen in verschiedenen Sprachen.
Datensatz 1: Stimmungsdatensatz aus mehreren Domänen, Ausführung 2.0
Datensatz 2: Datensatz zur Twitter-Stimmungsanalyse
Führen Sie die Twitter-Sentiment-Analyse selbst durch.
8. Semantische Textähnlichkeit
Was ist semantische Textähnlichkeit? ?: Semantische Ähnlichkeit von Texten ist der Prozess der Analyse der Ähnlichkeit zwischen zwei Textstücken in Bezug auf die Bedeutung und den Inhalt des Textes, anstatt die Syntax der beiden Textstücke zu analysieren. Was ist mehr, die Ähnlichkeit unterscheidet sich von der Beziehung.
Zum Beispiel –
Das Auto und der Bus sind ähnlich, aber das Auto und der Kraftstoff hängen zusammen.
Dokumentieren 1: Dieses Papier stellt die verschiedenen Ansätze zur Messung von Textähnlichkeit im Detail vor. Ein unverzichtbarer Artikel, um mehr über bestehende Ansätze an einem Ort zu erfahren.
Dokumentieren 2: Dieses Papier präsentiert das CNN, um ein Paar von zwei kurzen Texten zu klassifizieren
Dokumentieren 3: Dieses Papier verwendet Tree-LSTM, die ein hochmodernes Ergebnis in der semantischen Beziehung von Texten und semantischer Klassifikation erzielen.
9. Spracherkennung
Was ist Spracherkennung ?: Sprachidentifikation ist die Aufgabe, die Sprache zu identifizieren, in der der Inhalt gefunden wird. Es nutzt die statistischen und syntaktischen Eigenschaften der Sprache, um diese Aufgabe zu erfüllen. Es kann auch als Sonderfall der Textklassifikation betrachtet werden.
Blog: In diesem fastText Blogbeitrag, ein neues Tool einführen, das identifizieren kann 170 Sprachen mit 1 MB Speichernutzung.
Dokumentieren 1: Dieses Papier analysieren 7 Spracherkennungsmethoden von 285 Sprachen.
Dokumentieren 2: Dieses Papier beschreibt, wie tiefe neuronale Netze genutzt werden können, um Spitzenergebnisse bei der automatischen Spracherkennung zu erzielen.
10. Textzusammenfassung
Was ist eine Textzusammenfassung? ?: Textzusammenfassung ist der Prozess, einen Text zu kürzen, indem die wichtigen Punkte des Textes identifiziert und anhand dieser Punkte eine Zusammenfassung erstellt wird. Das Ziel der Textzusammenfassung besteht darin, das Maximum an Informationen bei gleichzeitiger maximaler Kürzung des Textes zu erhalten, ohne die Bedeutung des Textes zu verändern.
Dokumentieren 1: Dieses Papier beschreibt einen auf neuronalen Aufmerksamkeitsmodellen basierenden Ansatz zur abstrakten Satzzusammenfassung.
Dokumentieren 2: Dieses Papier beschreibt, wie Sequenz-für-Sequenz-RNNs verwendet werden können, um State-of-the-Art-Ergebnisse in der Textzusammenfassung zu erzielen.
Repository: Dieses Google Brain-Repository Das Team verfügt über die Codes, um ein benutzerdefiniertes Sequenz-für-Sequenz-Modell für die Textzusammenfassung zu verwenden. Das Modell wird auf einem Gigaword-Datensatz trainiert.
Anwendung: Der autotldr-Roboter auf Reddit Verwenden Sie die Textzusammenfassung, um Artikel in den Kommentaren eines Beitrags zusammenzufassen. Diese Funktion erwies sich unter Reddit-Benutzern als sehr bekannt..
Implementierung: So können Sie Ihren Text mit dem Gensim-Paket schnell zusammenfassen.
from gensim.summarization import summarizesentence="Automatic summarization is the process of shortening a text document with software, in order to create a summary with the major points of the original document. Technologies that can make a coherent summary take into account variables such as length, writing style and syntax.Automatic data summarization is part of machine learning and data mining. The main idea of summarization is to find a subset of data which contains the information of the entire set. Such techniques are widely used in industry today. Search engines are an example; others include summarization of documents, image collections and videos. Document summarization tries to create a representative summary or abstract of the entire document, by finding the most informative sentences, while in image summarization the system finds the most representative and important (i.e. salient) images. For surveillance videos, one might want to extract the important events from the uneventful context.There are two general approaches to automatic summarization: extraction and abstraction. Extractive methods work by selecting a subset of existing words, phrases, or sentences in the original text to form the summary. In contrast, abstractive methods build an internal semantic representation and then use natural language generation techniques to create a summary that is closer to what a human might express. Such a summary might include verbal innovations. Research to date has focused primarily on extractive methods, which are appropriate for image collection summarization and video summarization."summarize(sentence)
Abschließende Anmerkungen
Es ging also um die gängigsten NLP-Aufgaben nebst entsprechenden Ressourcen in Form von Blogs., Forschungsartikel, Repositorys und Anwendungen, etc. Wenn du es glaubst, Es gibt eine großartige Ressource zu jedem dieser Themen 10 Aufgaben, die ich verpasst habe oder Sie vorschlagen möchten, eine weitere Aufgabe hinzuzufügen, dann kommentieren Sie gerne Ihre Anregungen und Kommentare.
Wir haben auch einen tollen Kurs, NLP mit Python, für dich, wenn du NLP-Praktiker werden möchtest.
Viel Spaß beim Lernen!





