Dieser Artikel wurde im Rahmen der Data Science Blogathon
Überblick
In diesem Artikel wird kurz auf CNN . eingegangen, eine spezielle Variante neuronaler Netze, die speziell für bildbezogene Aufgaben entwickelt wurde. Der Artikel konzentriert sich hauptsächlich auf den Implementierungsteil von CNN. Es wurden alle Anstrengungen unternommen, um diesen Artikel interaktiv und unkompliziert zu gestalten.. Viel Spaß beim Lernen !!

Einführung
Convolutional Neural Networks wurden im Jahr von Yann LeCun und Yoshua Bengio eingeführt 1995 die später außergewöhnliche Ergebnisse im Bereich der Bilder zeigte. Dann, Was sie im Vergleich zu gewöhnlichen neuronalen Netzen bei der Anwendung im Bildbereich besonders machte? Einen der Gründe erkläre ich an einem einfachen Beispiel. Bitte beachten Sie, dass Sie mit der Klassifizierung von handgeschriebenen Ziffernbildern beauftragt wurden und dass einige Beispieltrainingssätze unten gezeigt werden.

Wenn du richtig beobachtest, Sie können feststellen, dass alle Ziffern in der Mitte der jeweiligen Bilder erscheinen. Das Training eines normalen neuronalen Netzmodells mit diesen Bildern kann zu guten Ergebnissen führen, wenn das Testbild von einem ähnlichen Typ ist. Aber, Was ist, wenn das Testbild wie unten aussieht??

Hier erscheint die Zahl Neun in der Ecke des Bildes. Wenn wir ein einfaches neuronales Netzmodell verwenden, um dieses Bild zu klassifizieren, unser Modell kann abrupt versagen. Aber wenn das gleiche Testbild einem CNN-Modell gegeben wird, es wird sehr wahrscheinlich richtig klassifiziert. Der Grund für die bessere Leistung ist, dass nach räumlichen Merkmalen im Bild gesucht wird. Für den obigen Fall selbst, auch wenn die Zahl Neun in der linken Ecke des Rahmens steht, das trainierte CNN-Modell erfasst die Merkmale im Bild und sagt wahrscheinlich voraus, dass die Zahl die Ziffer Neun ist. Ein normales neuronales Netzwerk kann diese Art von Magie nicht ausführen. Lassen Sie uns nun kurz die Hauptbausteine von CNN besprechen.
Hauptkomponenten der Architektur eines CNN-Modells
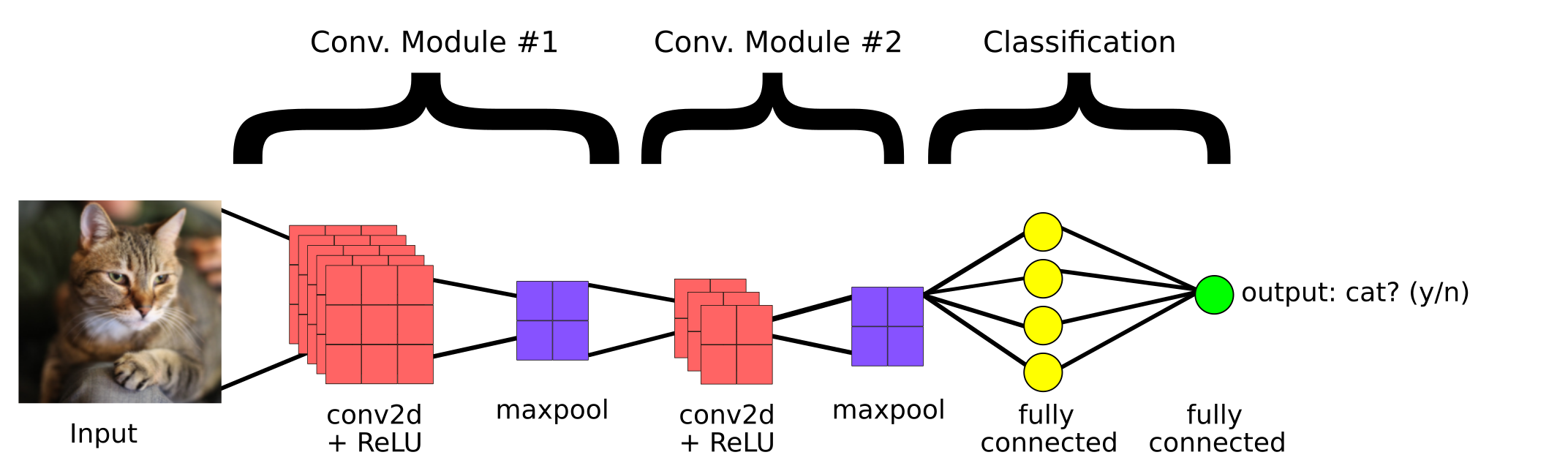
Dies ist ein einfaches CNN-Modell, das erstellt wurde, um zu klassifizieren, ob das Bild eine Katze enthält oder nicht. Dann, die Hauptkomponenten eines CNN sind:
1. Faltdeckel
2. Gruppierungsebene
3.Vollständig verbundene Schicht
Faltdeckel
Faltungsebenen helfen uns, die im Bild vorhandenen Merkmale zu extrahieren. Diese Extraktion wird mit Hilfe von Filtern erreicht. Beachten Sie den folgenden Vorgang.
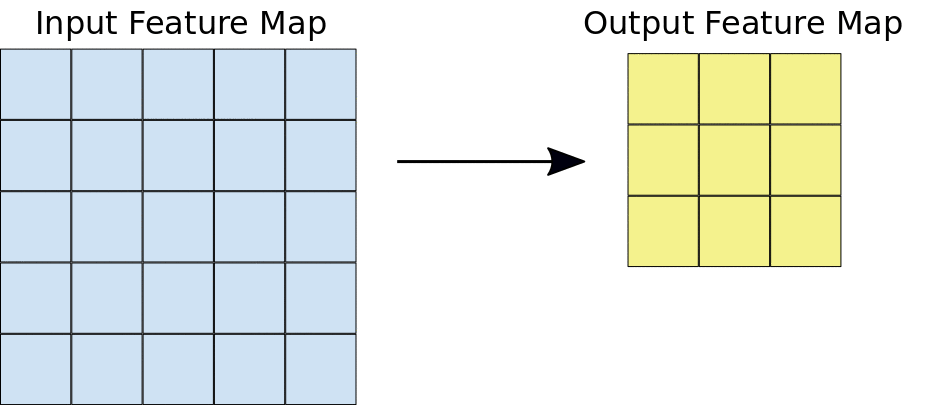
Hier sehen wir, dass ein Fenster über das gesamte Bild gleitet, wo das Bild als Raster gerendert wird (So sieht der Computer Bilder, bei denen die Raster mit Zahlen gefüllt sind!!). Sehen wir uns nun an, wie die Berechnungen in der Faltungsoperation durchgeführt werden.
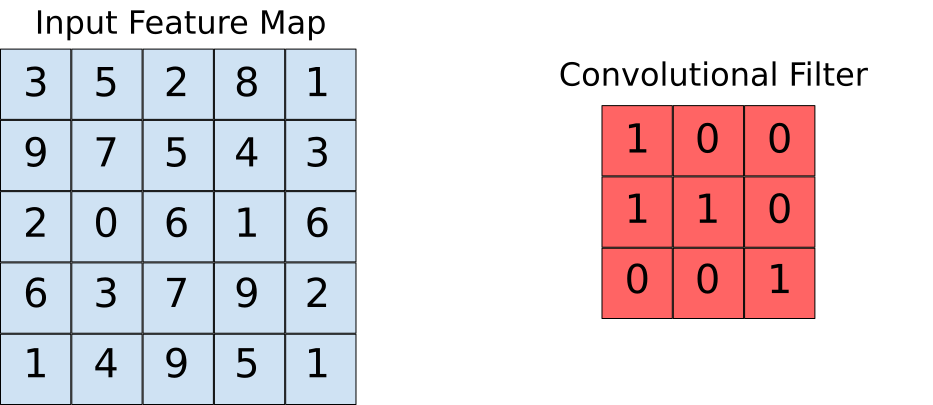
Angenommen, die Karte der Eingangseigenschaften ist unser Bild und der Faltungsfilter ist das Fenster, über das wir gleiten werden. Schauen wir uns nun eine der Instanzen der Faltungsoperation an.
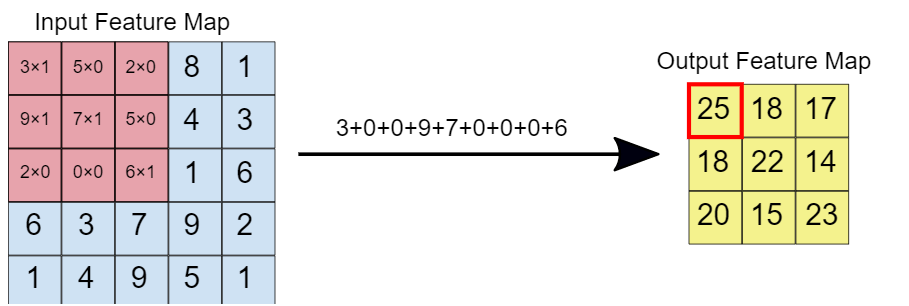
Wenn der Faltungsfilter dem Bild überlagert ist, die jeweiligen Elemente werden multipliziert. Später, die multiplizierten Werte werden addiert, um einen einzelnen Wert zu erhalten, der in der Ausgabe-Feature-Map ausgefüllt wird. Dieser Vorgang wird fortgesetzt, bis wir das Fenster über das Kennfeld der Eingabeeigenschaften schieben., damit das Ausgangskennfeld füllen.
Gruppierungsebene
Die Idee hinter der Verwendung eines Gruppierungs-Layers besteht darin, die Dimension der Feature-Map zu reduzieren. Für die unten angegebene Darstellung, Wir haben eine maximale Gruppierungsschicht von verwendet 2 * 2. Jedes Mal gleitet das Fenster über das Bild, wir nehmen den maximalen Wert innerhalb des Fensters.
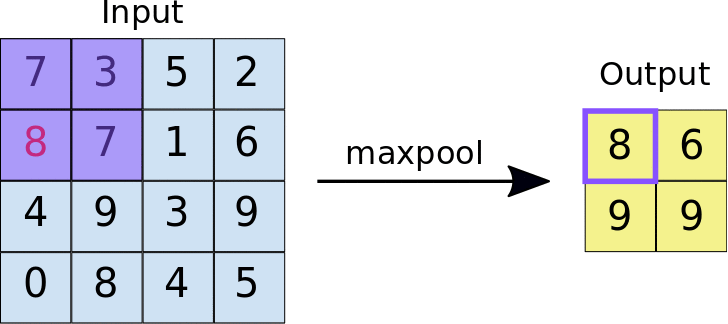
Schließlich, nach maximalem Gruppenbetrieb, Wir können hier sehen, dass die Dimension der Eingabe, nämlich, 4 * 4, wurde reduziert auf 2 * 2.
Vollständig verbundene Schicht
Diese Schicht ist im hinteren Abschnitt der CNN-Modellarchitektur vorhanden, wie zuvor zu sehen. Die Eingabe für die vollständig verbundene Schicht sind die reichhaltigen Merkmale, die durch Faltungsfilter extrahiert wurden. Diese breitet sich dann weiter zur Ausgabeschicht aus, wobei wir die Wahrscheinlichkeit erhalten, dass das Eingabebild zu verschiedenen Klassen gehört. Das vorhergesagte Ergebnis ist die Klasse mit der höchsten Wahrscheinlichkeit, die das Modell vorhergesagt hat.
Codeimplementierung
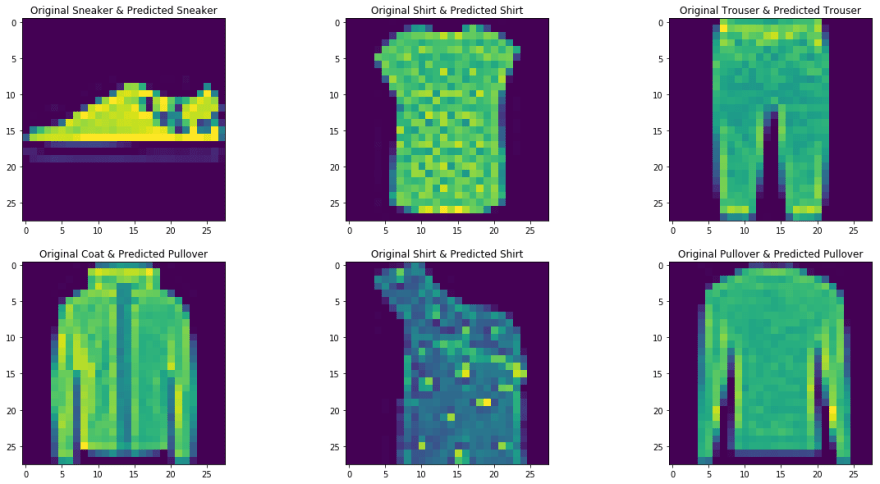
Hier nehmen wir den Fashion MNIST als unseren Problemdatensatz. Der Datensatz enthält T-Shirts, Hose, Pullover, Kleider, Mäntel, Flip Flops, Hemden, Schuhe, Taschen und Stiefeletten. Die Aufgabe besteht darin, nach dem Training des Modells ein bestimmtes Bild in die oben genannten Klassen einzuordnen.
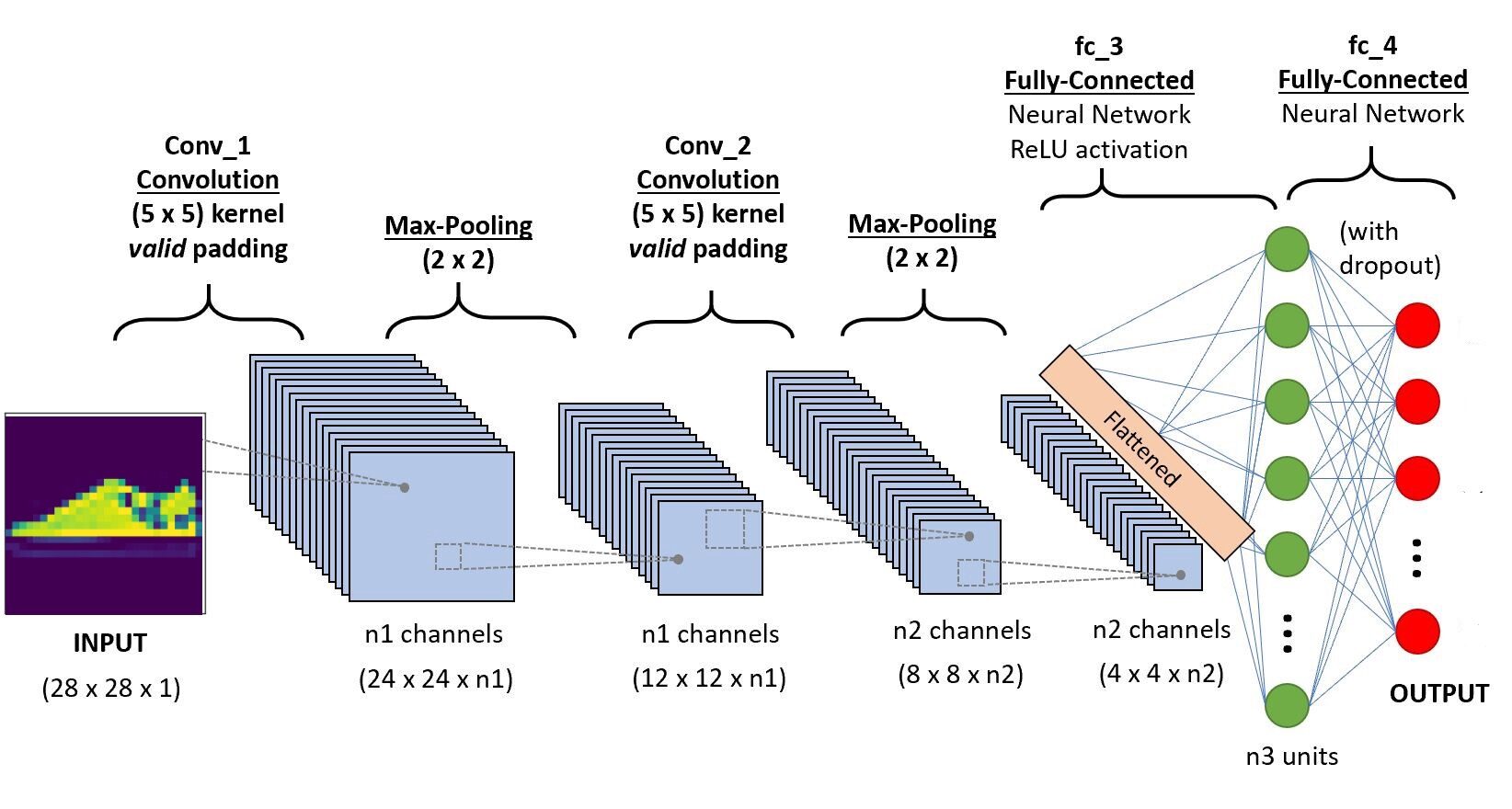
Wir implementieren den Code in Google Colab, da sie die Nutzung kostenloser GPU-Ressourcen für einen festgelegten Zeitraum zur Verfügung stellen. Wenn Sie neu in der Colab-Umgebung und den GPUs sind, Überprüfen Sie diesen Blog, um eine bessere Vorstellung zu bekommen. Unten ist die CNN-Architektur, die wir bauen werden.
Paso 1: Importieren Sie die erforderlichen Bibliotheken
Importieren von OS Taschenlampe importieren Torchvision importieren Tarfile importieren aus Torchvision Import transformiert aus Torch.utils.data import random_split aus Torch.utils.data.dataloader importieren DataLoader brenner.nn als nn importieren aus fackel.nn Importfunktion als F aus der itertools-Importkette
Paso -2: Herunterladen des Test- und Trainingsdatensatzes
train_set = Torchvision.datasets.FashionMNIST("/usr", herunterladen=Wahr, transform=
transformiert.Verfassen([transformiert.ToTensor()]))
test_set = Torchvision.datasets.FashionMNIST("./Daten", herunterladen=Wahr, train=Falsch, transform=
transformiert.Verfassen([transformiert.ToTensor()]))
Paso 3 Aufteilung des Trainingssets für Training und Validierung
train_size = 48000 val_size = 60000 - train_size train_ds,val_ds = random_split(train_set,[train_size,Wert_Größe])
Paso 4 Laden Sie den Datensatz mit dem Dataloader . in den Speicher
train_dl = DataLoader(train_ds,batch_size=20,shuffle=True) val_dl = DataLoader(val_ds,batch_size=20,shuffle=True) Klassen = train_set.classes
Lassen Sie uns nun die geladenen Daten visualisieren,
für Bilder,Etiketten in train_dl:
für img in imgs:
arr_ = np.squeeze(img)
plt.zeigen()
brechen
brechen
Paso -5 Definieren der Architektur
brenner.nn als nn importieren
brenner.nn.funktional als F importieren
#definiere die CNN-Architektur
Klasse Net(nn.Modul):
def __init__(selbst):
Super(Netz, selbst).__drin__()
#Faltungsschicht-1
self.conv1 = nn.Conv2d(1,6,5, padding=0)
#Faltungsschicht-2
self.conv2 = nn.Conv2d(6,10,5,padding=0)
# maximale Pooling-Schicht
self.pool = nn.MaxPool2d(2, 2)
# Vollständig verbundene Schicht 1
self.ff1 = nn.Linear(4*4*10,56)
# Vollständig verbundene Schicht 2
self.ff2 = nn.Linear(56,10)
def vorwärts(selbst, x):
# Hinzufügen einer Sequenz von Faltungs- und Max-Pooling-Schichten
#Eingangsdimmung-28*28*1
x = self.conv1(x)
# Nach der Faltungsoperation, Ausgangsdimmung - 24*24*6
x = self.pool(x)
# Nach Max. Poolbetrieb Ausgangsdimmung - 12*12*6
x = self.conv2(x)
# Nach der Faltungsoperation Ausgangsdimmung - 8*8*10
x = self.pool(x)
# Max. Pool-Ausgangsdimmung 4*4*10
x = x.Ansicht(-1,4*4*10) # Umformen der Werte in eine Form, die für die Eingabe des vollständig verbundenen Layers geeignet ist
x = F.relu(selbst.ff1(x)) # Anwenden von Relu auf die Ausgabe der ersten Ebene
x = F.sigmoid(selbst.ff2(x)) # Anwenden von Sigmoid auf die Ausgabe der zweiten Ebene
Rückgabe x
# Erstellen Sie ein vollständiges CNN model_scratch = Net() drucken(Modell)
# Tensoren auf GPU verschieben, wenn CUDA verfügbar ist
wenn use_cuda:
model_scratch.cuda()
Paso 6: Definition der Verlustfunktion
# Verlustfunktion
brenner.nn als nn importieren
brenner.optim als optim importieren
Kriterium_scratch = nn.CrossEntropyLoss()
def get_optimizer_scratch(Modell):
Optimierer = optim.SGD(modell.parameter(),lr = 0.04)
Renditeoptimierer
Paso 7: Implementierung des Trainings- und Validierungsalgorithmus
# Implementierung des Trainingsalgorithmus
def zug(n_epochen, Lader, Modell, Optimierer, Kriterium, use_cuda, save_path):
"""gibt trainiertes Modell zurück"""
# Tracker für minimalen Validierungsverlust initialisieren
valid_loss_min = np.Inf
für Epoche in Reichweite(1, n_epochen+1):
# Variablen initialisieren, um Trainings- und Validierungsverluste zu überwachen
train_loss = 0.0
valid_loss = 0.0
# Zugphase #
# das Modul in den Trainingsmodus versetzen
modell.zug()
für batch_idx, (Daten, Ziel) aufzählen(Lader['Bahn']):
# auf GPU wechseln
wenn use_cuda:
Daten, Ziel = data.cuda(), ziel.cuda()
optimizer.zero_grad()
Ausgabe = Modell(Daten)
Verlust = Kriterium(Ausgang, Ziel)
verlust.rückwärts()
Optimierer.Schritt()
train_loss = train_loss + ((1 / (batch_idx + 1)) * (verlust.daten.element() - train_loss))
# validiere das Modell #
# Setzen Sie das Modell in den Evaluierungsmodus
model.eval()
für batch_idx, (Daten, Ziel) aufzählen(Lader['gültig']):
# auf GPU wechseln
wenn use_cuda:
Daten, Ziel = data.cuda(), ziel.cuda()
Ausgabe = Modell(Daten)
Verlust = Kriterium(Ausgang, Ziel)
valid_loss = valid_loss + ((1 / (batch_idx + 1)) * (verlust.daten.element() - valid_loss))
# Trainings-/Validierungsstatistik drucken
drucken('Epoche: {} tTrainingsverlust: {:.6F} tValidierungsverlust: {:.6F}'.Format(
Epoche,
train_loss,
valid_loss
))
## Wenn sich der Validierungsverlust verringert hat, dann das Modell speichern
if valid_loss <= valid_loss_min:
drucken('Validierungsverlust verringert ({:.6F} --> {:.6F}). Modell speichern ...'.format(
valid_loss_min,
valid_loss))
fackel.save(model.state_dict(), save_path)
valid_loss_min = valid_loss
Rückgabemodell
Paso 8: Trainings- und Evaluierungsphase
num_epochen = 15
model_scratch = trainieren(Anzahl_Epochen, loaders_scratch, model_scratch, get_optimizer_scratch(model_scratch),
Kriterium_scratch, use_cuda, 'model_scratch.pt')
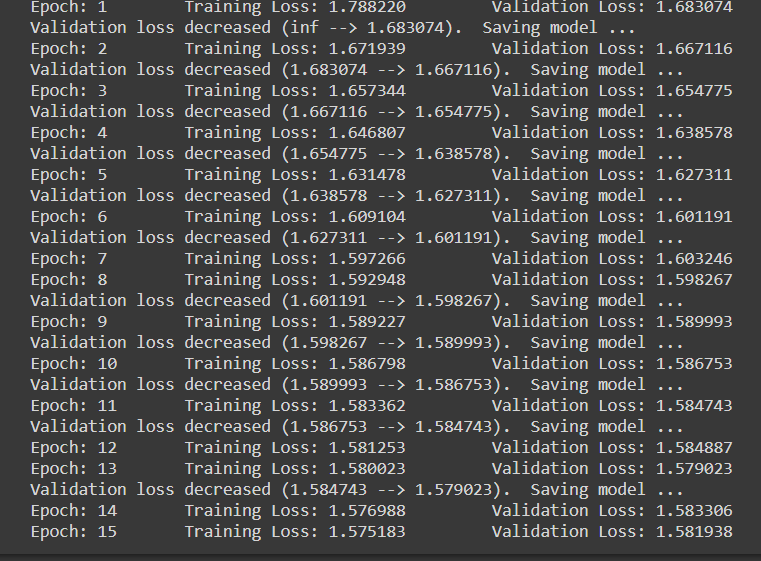
Beachten Sie, dass jedes Mal, wenn der Validierungsverlust abnimmt, wir speichern den zustand des modells.
Paso 9 Testphase
def test(Lader, Modell, Kriterium, use_cuda):
# Überwachen Sie den Testverlust und die Genauigkeit
test_loss = 0.
richtig = 0.
gesamt = 0.
# Setzen Sie das Modul in den Auswertemodus
model.eval()
für batch_idx, (Daten, Ziel) aufzählen(Lader['Prüfung']):
# auf GPU wechseln
wenn use_cuda:
Daten, Ziel = data.cuda(), ziel.cuda()
# Vorwärtspass: vorhergesagte Ausgaben berechnen, indem Eingaben an das Modell übergeben werden
Ausgabe = Modell(Daten)
# Berechnen Sie den Verlust
Verlust = Kriterium(Ausgang, Ziel)
# durchschnittlichen Testverlust aktualisieren
test_loss = test_loss + ((1 / (batch_idx + 1)) * (verlust.daten.element() - test_loss))
# Ausgabewahrscheinlichkeiten in vorhergesagte Klasse umwandeln
pred = output.data.max(1, keepdim=Wahr)[1]
# vergleiche Vorhersagen mit echtem Label
richtig += np.summe(np.squeeze(pred.eq(target.data.view_as(pred)),Achse=1).Zentralprozessor().numpy())
gesamt += data.size(0)
drucken('Testverlust: {:.6F}n'.format(test_loss))
drucken('nTest-Genauigkeit: %2D%% (%2d /% 2d)' % (
100. * Korrekt / gesamt, Korrekt, gesamt))
# Laden Sie das Modell mit der besten Validierungsgenauigkeit
model_scratch.load_state_dict(fackel.laden('model_scratch.pt'))
Prüfung(loaders_scratch, model_scratch, Kriterium_scratch, use_cuda)

Paso 10 Mit einer Probe testen
Die Funktion, die zum Testen des Modells mit einem einzelnen Bild definiert ist.
def predict_image(img, Modell):
# In einen Stapel von . umwandeln 1
xb = img.unsqueeze(0)
# Vorhersagen vom Modell abrufen
yb = Modell(xb)
# Wählen Sie den Index mit der höchsten Wahrscheinlichkeit
_, preds = brenner.max(yb, dim=1)
# das Bild drucken
plt.imshow(img.squeeze( ))
#das Klassenlabel für das Bild zurückgeben
zurück train_set.classes[Preds[0].Artikel()]
img,label = test_set[9] predict_image(img,model_scratch)
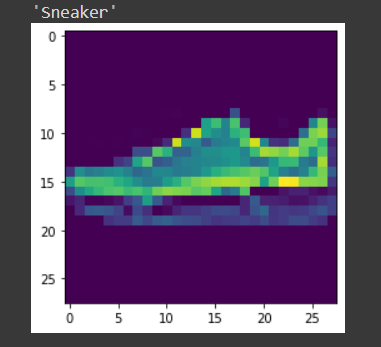
Fazit
Hier hatten wir kurz die Hauptoperationen in einem konvolutionellen neuronalen Netz und seine Architektur besprochen. Ein einfaches Faltungsneuralnetzwerkmodell wurde ebenfalls implementiert, um eine bessere Vorstellung vom praktischen Anwendungsfall zu erhalten. Sie finden den implementierten Code in my GitHub-Repository. Was ist mehr, Sie können die Leistung des bereitgestellten Modells verbessern, indem Sie den Datensatz vergrößern, Verwendung von Regularisierungstechniken wie Batch-Normalisierung und Aufgabe auf vollständig verbundenen Schichten der Architektur. Was ist mehr, Beachten Sie, dass auch vortrainierte CNN-Modelle verfügbar sind, die mit großen Datensätzen trainiert wurden. Durch die Verwendung dieser Modelle der neuesten Generation, Sie werden zweifellos die besten Messwerte für ein bestimmtes Problem erzielen.
Verweise
- https://www.youtube.com/watch?v = EHuACSjijbI – Jupiter
- https://www.youtube.com/watch?v = 2-Ol7ZB0MmU&t=1503s- Eine freundliche Einführung in konvolutionelle neuronale Netze und Bilderkennung
Über den Autor
Mein Name ist Adwait Dathan, Ich studiere derzeit meinen Master in Künstlicher Intelligenz und Data Science. Fühlen Sie sich frei, mit mir in Verbindung zu treten Linkedin.
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von DataPeaker und werden nach Ermessen des Autors verwendet.





