Einführung
GraphLab war ein unerwarteter Durchbruch in meinem Lernplan. Schließlich, „Gute Dinge passieren, wenn weniger erwartet wird“. Angefangen hat alles mit Ende Black Friday-Daten-Hack. Von 1200 Teilnehmer, wir haben unsere Gewinner und ihre interessanten Lösungen bekommen.
Ich habe sie gelesen und analysiert. Mir wurde klar, dass ich ein erstaunliches Werkzeug für maschinelles Lernen vermisst hatte. Ein kurzer Scan hat mir gezeigt, dass dieses Tool ein enormes Potenzial hat, um unsere Modellierungsprobleme beim maschinellen Lernen zu reduzieren. Dann, Ich beschloss, es weiter zu erkunden. Ich habe jetzt ein paar Tage damit verbracht, seine Wissenschaft und seine logischen Anwendungsmethoden zu verstehen. Zu meiner Überraschung, es war nicht schwer zu verstehen.
Haben Sie versucht, Ihr Modell für maschinelles Lernen zu verbessern?? Aber ist es meistens gescheitert? Probieren Sie dieses fortschrittliche Tool für maschinelles Lernen aus. Eine einmonatige Testversion ist kostenlos und das Abonnement von 1 Jahr ist KOSTENLOS für den akademischen Gebrauch verfügbar. Später, Sie können ein Abonnement für die folgenden Jahre kaufen.
Um schnell loszulegen, Hier ist ein Anfängerleitfaden zu GraphLab in Python. Um das Verständnis zu erleichtern, Ich habe versucht, diese Konzepte so einfach wie möglich zu erklären.
Behandelten Themen
- Wie alles begann ?
- Was ist GraphLab??
- Vorteile und Einschränkungen von GraphLab
- So installieren Sie GraphLab?
- Erste Schritte mit GraphLab
Wie alles begann ?
GraphLab hat seit seinen Anfängen eine interessante Geschichte. Lass es mich kurz sagen.
GraphLab, bekannt als Dato wird gegründet von Carlos Gastrin. Carlos hat einen Doktortitel in Informatik von der Stanford University. Es geschah über 7 Jahre. Carlos war Professor an der Carnegie Mellon University. Zwei seiner Studenten arbeiteten an groß angelegten verteilten maschinellen Lernalgorithmen. Sie führten ihr Modell auf Hadoop aus und stellten fest, dass die Berechnung lange dauerte. Die Situation hat sich nach der Verwendung nicht einmal verbessert MPI (Hochleistungs-Computerbibliothek).
Dann, beschlossen, ein System zu bauen, um schnell mehr Artikel zu schreiben. Mit diesem, GraphLab war geboren.
PD – GraphLab Create ist eine kommerzielle Software von GraphLab. Auf GraphLab Create wird in Python über die Bibliothek zugegriffen “graphlab”. Deswegen, In diesem Artikel, „GraphLab“’ connota GraphLab erstellen. Sei nicht verwirrt.
Was ist GraphLab??
GraphLab ist ein neues paralleles Framework für maschinelles Lernen, geschrieben in C ++. Es ist ein Open-Source-Projekt und wurde mit Blick auf die Skalierung entwickelt, Vielfalt und Komplexität realer Daten. Enthält mehrere High-Level-Algorithmen wie den stochastischen Gradientenabstieg (SGD), Gradientenabstieg & Sperren für ein leistungsstarkes Erlebnis. Unterstützt Data Scientists und Entwickler bei der einfachen Erstellung und Installation umfangreicher Anwendungen.
Aber, Was macht es erstaunlich? Es ist das Vorhandensein geordneter Bibliotheken für die Transformation, Manipulation und Visualisierung von Datenmodellen. Was ist mehr, besteht aus skalierbaren Toolkits für maschinelles Lernen, die alles haben (fast schon) erforderlich, um Modelle für maschinelles Lernen zu verbessern. Toolkit beinhaltet Implementierung für Deep Learning, Faktor Maschinen, Themenmodellierung, Clusterbildung, nächste Nachbarn und mehr.
Hier ist die komplette Architektur von GraphLab Create.
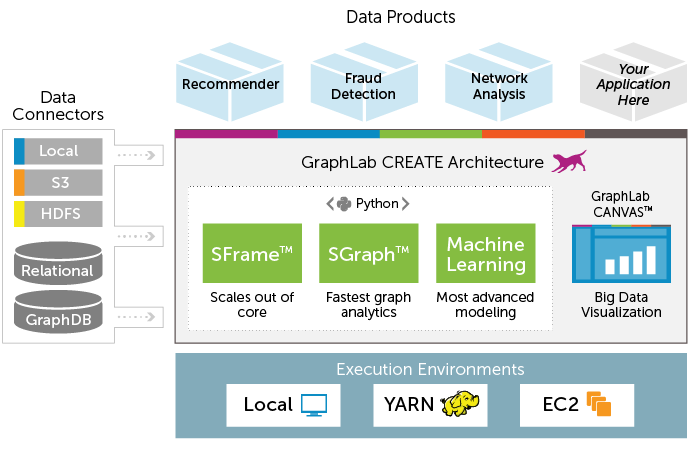
Was sind die Vorteile der Verwendung von GraphLab??
Es gibt mehrere Vorteile der Verwendung von GraphLab, wie unten beschrieben:
- Umgang mit Big Data: Die GraphLab-Datenstruktur kann große Datensätze verarbeiten, was zu skalierbarem maschinellem Lernen führt. Schauen wir uns die Datenstruktur von Graph Lab an:
-
- SRahmen: Es handelt sich um eine effiziente plattenbasierte tabellarische Datenstruktur, die nicht durch RAM begrenzt ist. Hilft bei der Skalierung der Datenverarbeitung und -analyse, um große Datensätze zu verarbeiten (Terabyte), sogar auf deinem Laptop. Es hat eine ähnliche Syntax wie Pandas oder R-Datenrahmen. Jede Spalte ist eins SArray, das ist eine Reihe von Elementen, die auf der Festplatte gespeichert sind. Dies macht SFrames datenträgerbasiert. Die Methoden zur Arbeit mit "SFrames" habe ich in den folgenden Abschnitten besprochen..
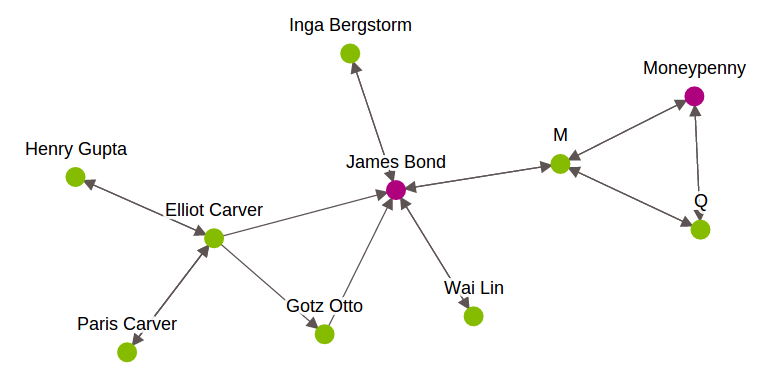
- SGraph: Graph hilft uns, Netzwerke zu verstehen, indem die Beziehungen zwischen Elementpaaren analysiert werden. Jedes Element wird durch a . dargestellt Scheitel in der Grafik. Die Beziehung zwischen Elementen wird dargestellt durch Kanten. In GraphLab, um graphenorientierte Datenanalysen durchzuführen, Verwendet SGraph Objekt. Es ist eine skalierbare Diagrammdatenstruktur, die Scheitelpunkte und Kanten in SFrames speichert. Um mehr darüber zu erfahren, Sieh dir das an Verknüpfung. Unten ist eine grafische Darstellung der James-Bond-Charaktere.

-
- Integration mit verschiedenen Datenquellen: GraphLab unterstützt verschiedene Datenquellen wie S3, ODBC, JSON, CSV, HDFS und vieles mehr.
- Untersuchen und Visualisieren von Daten mit GraphLab Canvas. GraphLab Canvas ist eine interaktive browserbasierte GUI, mit der Sie tabellarische Daten erkunden können, zusammenfassende Statistiken und bivariate Grafiken. Mit dieser Funktion, verbringen Sie weniger Zeit mit der Codierung der Datenexploration. Dies wird Ihnen helfen, sich mehr auf das Verständnis der Beziehung und Verteilung der Variablen zu konzentrieren.. Ich habe über diesen Teil in den folgenden Abschnitten gesprochen.
- Funktionsengineering: GraphLab verfügt über eine integrierte Option zum Erstellen nützlicher neuer Funktionen zur Verbesserung der Modellleistung. Es besteht aus mehreren Optionen wie Transformation, Gruppierung, Zurechnung, eine heiße Kodierung, tf-idf, etc.
- Modellieren: GraphLab verfügt über mehrere Werkzeugsätze, die eine schnelle und einfache Lösung von ML-Problemen bieten. Ermöglicht die Durchführung verschiedener Modellierungsübungen (Rückschritt, Einstufung, Gruppierung) in weniger Codezeilen. Sie können an Problemen wie dem Empfehlungssystem arbeiten, die Abbruchvorhersage, Stimmungsanalyse, Bildanalyse und vieles mehr.
- Produktionsautomatisierung: Mit Datenpipelines können Sie wiederverwendbare Codeaufgaben zu Jobs zusammenstellen. Später, automatisch in gängigen Laufzeitumgebungen ausführen (zum Beispiel, Amazon Webservices, Hadoop).
- GraphLab SDK erstellen: Fortgeschrittene Benutzer können die Funktionen von GraphLab Create mit dem GraphLab Creat SDK erweitern. Sie können neue Modelle definieren / Machine-Learning-Programme und integrieren Sie sie in den Rest des Pakets. Sehen Sie sich das GitHub-Repository an hier.
- Lizenz: Hat Nutzungsbeschränkung. Sie können sich für eine kostenlose Testphase von entscheiden 30 Tage oder eine Jahreslizenz für wissenschaftliches Publizieren. Um Ihr Abonnement zu verlängern, Sie werden belastet (siehe Abonnementstruktur hier).
So installieren Sie GraphLab?
Sie können GraphLab auch verwenden, nachdem Sie Ihre Lizenz verwendet haben. Aber trotzdem, Sie können auch mit der kostenlosen Testversion beginnen oder die wissenschaftliche Ausgabe im Abonnement von 1 Jahr. Deswegen, vor der Installation, Ihr Computer muss die Systemanforderungen erfüllen, um GraphLab auszuführen.
Systemvoraussetzungen für GraphLab:

Wenn Ihr System die oben genannten Anforderungen nicht erfüllt, Sie können verwenden GraphLab Create im kostenlosen AWS-Kontingent was ist mehr.
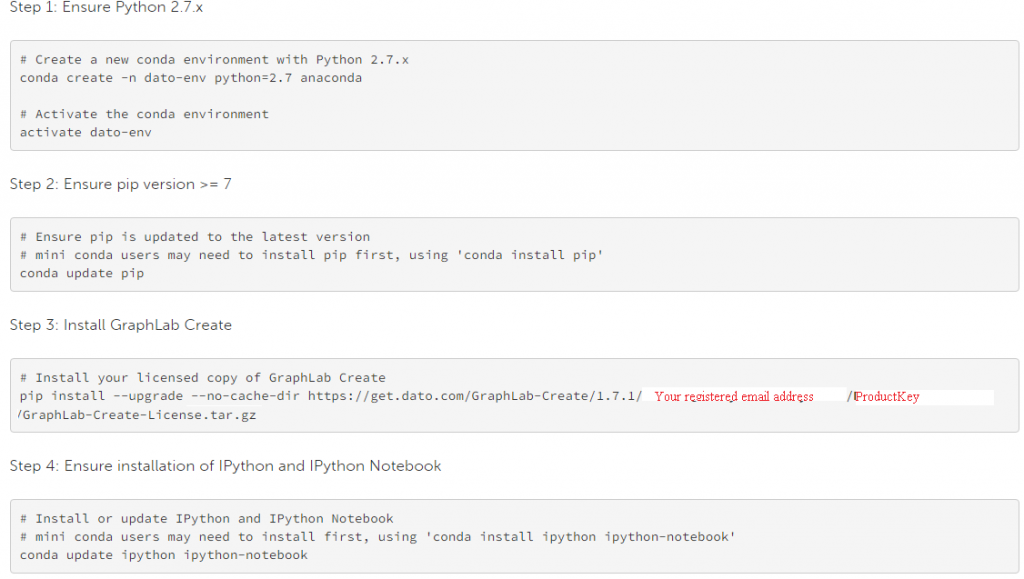
Schritte zur Installation:
- Melden Sie sich an für freie Strecke. Nach der Registrierung, Sie erhalten einen Product Key.
- Wählen Sie Ihr Betriebssystem (Automatische Auswahl ist aktiviert) und folgen Sie den Anweisungen
- Im Folgenden finden Sie die Installationsanweisungen für die Befehlszeile (zu “Anaconda Python-Umgebung”).
Erste Schritte mit Graphlab
Sobald Sie GraphLab erfolgreich installiert haben, Sie können darauf zugreifen, indem Sie “importieren ".
import graphlab
or
import graphlab as gl
Hier, Ich werde die Verwendung von GraphLab demonstrieren, indem ich eine Data Science-Herausforderung löse. Ich habe den Datensatz entnommen aus Black Friday-Daten-Hack.
-
-
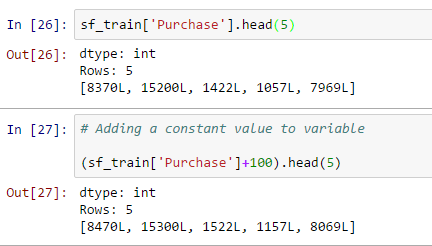
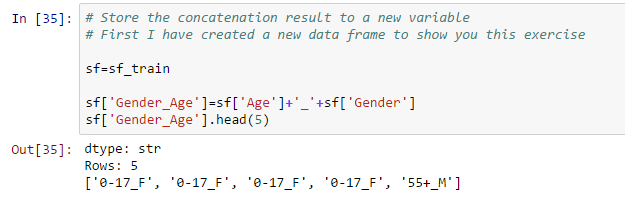
- Datenmanipulation: Sie können auch einen Datenbearbeitungsvorgang mit Sframe ausführen, Hinzufügen eines konstanten Werts zu allen Werten, Verketten von zwei oder mehr Variablen, Erstellen Sie eine neue Ausgabevariable basierend auf einer Variablen, wie unten gezeigt:
- Hinzufügen eines konstanten Werts zur Variablen:

- Verketten Sie zwei Zeichenfolgen und speichern Sie sie in einer neuen Variablen:

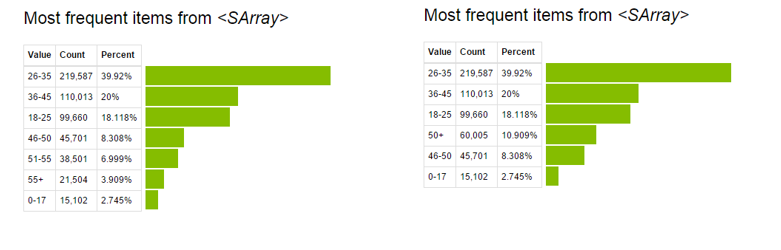
- Aktualisieren von Werten vorhandener Variablen: Dies kann über die Anwendungsfunktion erfolgen. In diesem Datensatz, Ich habe Altersgruppen kombiniert, die größer sind als 50 Verwenden des folgenden Codes:
# Vornehmen einer Änderung an der vorhandenen Variablen # Kombinieren Sie alle Behälter mit einem Alter von mehr als 50
def combine_age(Alter): wenn Alter =='51-55': return '50+' elif age=='55+': return '50+' else: Alter der Rückkehr
Sf['Alter']=sf['Alter'].anwenden(combine_age)
Jetzt, Beobachten Sie die Vor- und Nachanzeige der Variablen “Alter”.
 Weitere Informationen zum Bearbeiten von Daten mit GraphLab, Sieh dir das an Verknüpfung.
Weitere Informationen zum Bearbeiten von Daten mit GraphLab, Sieh dir das an Verknüpfung.
- Hinzufügen eines konstanten Werts zur Variablen:
- Funktionsengineering: Feature Engineering ist eine effektive Methode zur Verbesserung der Modellleistung. Mit dieser Technik, wir können neue Variablen nach der Transformation oder Manipulation bestehender Variablen erstellen. Eigentlich, GraphLab hat diesen Prozess automatisiert. Sie haben mehrere Transformationsmöglichkeiten für numerische Merkmale, kategorisch, Text und Bild. Was ist mehr, finden Sie direkte Möglichkeiten zur Gruppierung von Funktionen, Zurechnung, eine heiße Kodierung, Zählschwelle, TF-IDF, Hasher, Tokenzing und andere. Schauen wir uns die kategoriale Merkmalsimputation an “Produktkategorie_2” beyogen auf “Alter” Ja “Geschlecht„Aus dem“ Black Friday „Datensatz.
# Erstellen Sie die Daten # Variablen, auf deren Grundlage wir eine Imputation durchführen möchten, und eine zu imputierende Variable # Sie können sich die Algorithmen hinter der Imputation ansehen Hier. sf_impute = sf_train['Alter','Geschlecht','Produktkategorie_2']
Unterstellender = graphlab.feature_engineering. CategoricalImputer(Feature="Produktkategorie_2") # Fit and transform on the same data transformed_sf = imputer.fit_transform(sf_impute)#Retrieve the imputed values transformed_sf

Schließlich, Sie können diese Eingabevariable in das ursprüngliche Dataset importieren.
sf_train["Predicted_Product_Category_2"]=transformed_sf["predicted_feature_Product_Category_2"]
Ähnlich, Sie können basierend auf Ihren Anforderungen andere Feature-Engineering-Vorgänge auf das Dataset anwenden. Sie können sich darauf beziehen Verknüpfung für mehr Details.
- Modellieren: In dieser Phase, Wir machen Vorhersagen aus vergangenen Daten. GraphLab erstellt mühelos Modelle für häufige Aufgaben, Was:
EIN) Vorhersage numerischer Größen
B) Gebäudeempfehlungssysteme
C) Gruppendaten und Dokumente
D) Diagrammanalyse
- Datenmanipulation: Sie können auch einen Datenbearbeitungsvorgang mit Sframe ausführen, Hinzufügen eines konstanten Werts zu allen Werten, Verketten von zwei oder mehr Variablen, Erstellen Sie eine neue Ausgabevariable basierend auf einer Variablen, wie unten gezeigt:
-
 Weitere Informationen zum Bearbeiten von Daten mit GraphLab, Sieh dir das an
Weitere Informationen zum Bearbeiten von Daten mit GraphLab, Sieh dir das an 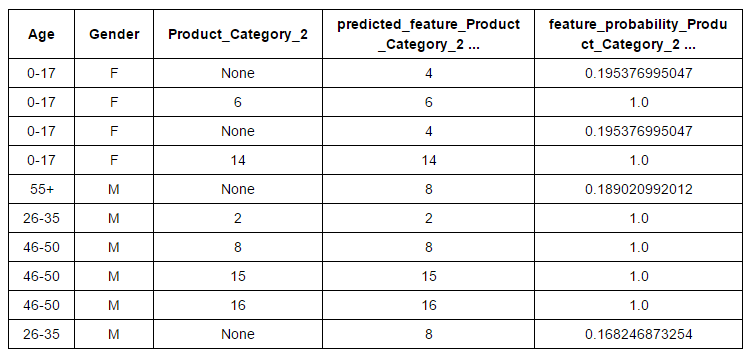
In der Black Friday Challenge, Wir sind verpflichtet, numerische Größen vorherzusagen “Kaufen”, nämlich, Wir brauchen ein Regressionsmodell, um die “Kaufen”.
In GraphLab, Tenemos tres tipos de modelos de regresión:
EIN) Lineare Regression
B) Zufällige Waldregression
C) Regresión impulsada por gradientes
Si tiene alguna confusión en la selección del algoritmo, GraphLab se encarga de eso. Mach dir keine Sorgen. Selecciona el modelo de regresión correcto automáticamente.
# Make a train-test split
train_data, validate_data = sf_train.random_split(0.8)
# Wählt automatisch das richtige Modell basierend auf Ihren Daten aus. Modell = graphlab.regression.create(train_data, Ziel="Erwerben", Merkmale = ['Geschlecht','Alter',"Beruf","City_Category","Stay_In_Current_City_Years", "Marital_Status","Product_Category_1"])
# Save predictions to an SArray
predictions = model.predict(validate_data)
# Evaluate the model and save the results into a dictionary
results = model.evaluate(validate_data)
Ergebnisse
Produktion:
{"max_error": 13377.561969523947, 'rmse': 3007.1225949345117}
#Do prediction on test data set
final_predictions = model.predict(sf_test)
Um mehr über andere Modellierungstechniken wie das Gruppieren zu erfahren, Einstufung, Empfehlungssystem, Textanalyse, Chartanalyse, Empfehlungssysteme, das kannst du überprüfen Verknüpfung. Alternative, hier ist das komplette Bedienungsanleitung von Daten.
Abschließende Anmerkungen
In diesem Artikel, wir haben davon erfahren “GraphLab erstellen”, was hilft, einen großen Datensatz zu verarbeiten, während Modelle für maschinelles Lernen erstellt werden. Wir analysieren auch die Graphlab-Datenstruktur, die es ermöglicht, große Datensätze wie "SFrame" und "SGraph" zu verarbeiten.. Ich empfehle, dass Sie GraphLab verwenden. Sie werden die automatisierten Funktionen wie die Datenexploration lieben (Segeltuch, interaktives Webdaten-Explorationstool), Funktionsengineering, Auswahl geeigneter Modelle und Umsetzung.
Zum besseren Verständnis, Ich demonstrierte auch eine Modellierungsübung mit GraphLab. In meinem nächsten Artikel über GraphLab, Ich werde mich auf Chartanalyse und Empfehlungssystem konzentrieren.
Findest du diesen Artikel hilfreich ? Teilen Sie mit uns Ihre Erfahrungen mit GraphLab.





