Dieser Artikel wurde im Rahmen der Data Science Blogathon
Einführung
UNS, die Menschen, wir lesen fast jede Minute unseres Lebens Texte. Wäre es nicht toll, wenn unsere Maschinen oder Anlagen auch Texte lesen könnten wie wir? Aber die wichtigste Frage ist “Wie machen wir unsere Maschinen lesen”? Hier kommt die optische Zeichenerkennung ins Spiel. (OCR).
Optische Zeichenerkennung (OCR)
Optische Zeichenerkennung (OCR) ist eine Technik zum Lesen oder Erfassen von Text aus gedruckten oder gescannten Fotos, handgeschriebene Bilder und deren Umwandlung in ein bearbeitbares und durchsuchbares digitales Format.
Anwendungen
OCR hat viele Anwendungen in der heutigen Geschäftswelt. Einige davon sind unten aufgeführt:
- Passerkennung an Flughäfen
- Automatisierung der Dateneingabe
- Kennzeichenerkennung
- Extrahieren Sie Visitenkarteninformationen in eine Kontaktliste
- Konvertieren handschriftlicher Dokumente in elektronische Bilder
- Durchsuchbare PDF-Dateien erstellen
- Audiodateien erstellen (Text zu Audio)
Einige der Open-Source-OCR-Tools sind Tesserakt, OCRopus.
In diesem Artikel, wir konzentrieren uns auf Tesseract OCR. Und um die Bilder zu lesen brauchen wir OpenCV.
Installation von Tesseract OCR:
Laden Sie das neueste Installationsprogramm für Windows herunter 10 aus “https://github.com/UB-Mannheim/tesseract/wiki“. Führen Sie die .exe-Datei aus, sobald sie heruntergeladen wurde.
Notiz: Vergessen Sie nicht, den Installationspfad der Software aus der Datei zu kopieren. Wir werden es später brauchen, da wir den Pfad der ausführbaren Tesseract-Datei im Code hinzufügen müssen, wenn das Installationsverzeichnis vom Standard abweicht.
Der typische Installationspfad auf Windows-Systemen ist C: Programmdateien.
Dann, in meinem Fall, es ist “C: Programmdateien Tesseract-OCRtesseract.exe“.
Dann, Python-Container für Tesseract installieren, Eingabeaufforderung öffnen und Befehl ausführen “pip instalar pytesseract“.
OpenCV
OpenCV (Open-Source-Computer Vision) ist eine Open-Source-Bibliothek für Bildverarbeitungsanwendungen, Maschinelles Lernen und Computer Vision.
OpenCV-Python ist die Python-API für OpenCV.
Um es zu installieren, Eingabeaufforderung öffnen und Befehl ausführen “pip instalar opencv-python“.
OCR-Beispielskript erstellen
1. Lesen Sie ein Beispielbild
CV2 importieren
Lesen Sie das Bild mit der Methode cv2.imread () und speichere es in einer Variablen "img".
img = cv2.imread("bild.jpg")
Falls erforderlich, Bildgröße mit der Methode cv2.resize ändern ()
img = cv2.resize(img, (400, 400))
Zeigen Sie das Bild mit der cv2.imshow-Methode an ()
cv2.imshow("Bild", img)
Das Fenster unendlich anzeigen (um einen Absturz des Kernels zu verhindern)
cv2.waitKey(0)
Alle offenen Fenster schließen
cv2.destroyAllWindows()
2. Kettenbildkonvertierung
pytesseract importieren
Pfad des Tesseracts im Code festlegen
pytesseract.pytesseract.tesseract_cmd=r'C:ProgrammdateienTesseract-OCRtesseract.exe'
Der folgende Fehler tritt auf, wenn wir den Pfad nicht setzen.

So konvertieren Sie ein Bild in eine Zeichenfolge, Verwenden Sie pytesseract.image_to_string (img) und in einer Variablen speichern “Text”
text = pytesseract.image_to_string(img)
Ergebnis ausdrucken
drucken(Text)
Vollständiger Code:
CV2 importieren
pytesseract importieren
pytesseract.pytesseract.tesseract_cmd=r'C:ProgrammdateienTesseract-OCRtesseract.exe'
img = cv2.imread("bild.jpg")
img = cv2.resize(img, (400, 450))
cv2.imshow("Bild", img)
text = pytesseract.image_to_string(img)
drucken(Text)
cv2.waitKey(0)
cv2.destroyAllWindows()
Die Ausgabe des obigen Codes:
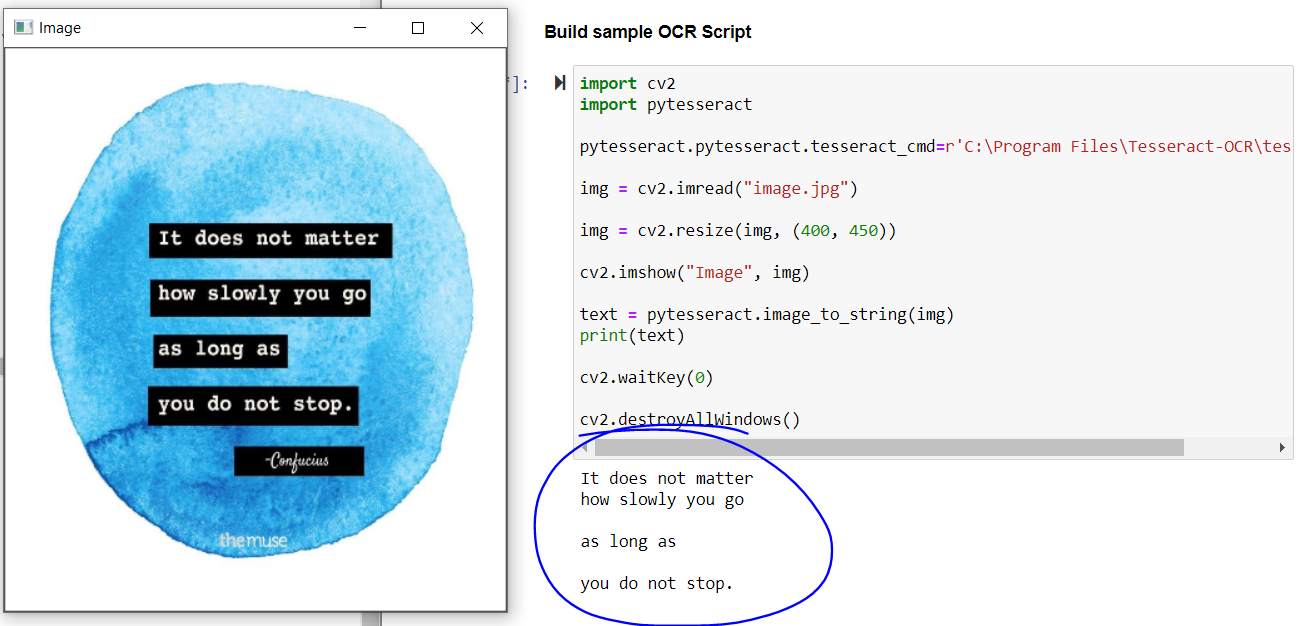
Die Ausgabe des obigen Codes
Wenn wir uns das Ergebnis ansehen, das Hauptzitat ist perfekt extrahiert, aber du bekommst nicht den Namen des Philosophen und den Text am unteren Rand des Bildes.
Um Text genau zu extrahieren und Präzisionsverlust zu vermeiden, wir müssen das Bild vorverarbeiten. Ich habe diesen Artikel gefunden (https://directiondatascience.com/pre-processing-in-ocr-fc231c6035a7) Ziemlich nützlich. Bitte beziehen Sie sich darauf, um die Vorverarbeitungstechniken besser zu verstehen.
Perfekt! Jetzt haben wir die erforderlichen Grundlagen, Schauen wir uns einige einfache OCR-Anwendungen an.
1. Erstellen von Wortwolken in Überprüfungsbildern
Die Wortwolke ist eine visuelle Darstellung der Häufigkeit von Wörtern. Je größer das Wort in einer Wortwolke erscheint, das Wort wird am häufigsten im Text verwendet.
Dafür, Ich habe einige Amazon-Rezensions-Schnappschüsse für das Apple iPad der 8. Generation gemacht.
Beispielbild
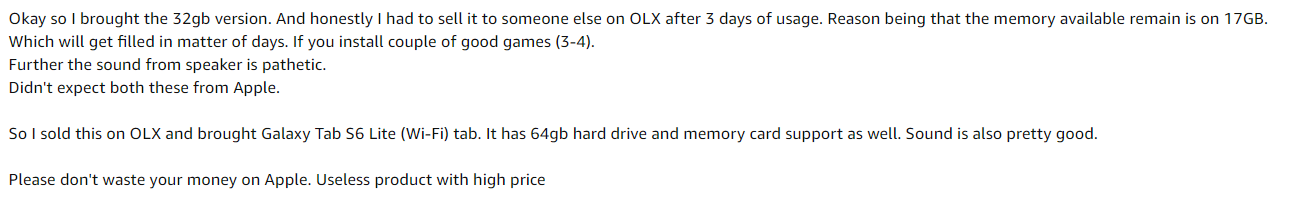
Schritte:
- Erstellen Sie eine Liste aller verfügbaren Bewertungsbilder
- Falls erforderlich, Bilder mit der Methode cv2.imshow anzeigen ()
- Lesen Sie Text aus Bildern mit pytesseract
- Erstellen Sie einen Datenrahmen
- Text vorverarbeiten: Sonderzeichen entfernen, Stoppwörter
- Bauen Sie positive und negative Wortwolken auf
Paso 1: erstellt eine Liste aller verfügbaren Review-Bilder
Importieren von OS OrdnerPfad = "Bewertungen" myRevList = os.listdir(Ordnerpfad)
Paso 2: Falls erforderlich, Bilder mit der Methode cv2.imshow anzeigen ()
für Bild in myRevList:
img = cv2.imread(F'{Ordnerpfad}/{Bild}')
cv2.imshow("Bild", img)
cv2.waitKey(0)
cv2.destroyAllWindows()
Paso 3: Text aus Bildern mit pytesseract lesen
CV2 importieren
pytesseract importieren
pytesseract.pytesseract.tesseract_cmd=r'C:ProgrammdateienTesseract-OCRtesseract.exe'
Korpus = []
für Bilder in myRevList:
img = cv2.imread(F'{Ordnerpfad}/{Bilder}')
wenn img None ist:
korpus.anhängen("Das Bild konnte nicht gelesen werden.")
anders:
rev = pytesseract.image_to_string(img)
korpus.anhängen(Rev)
aufführen(Korpus)
Korpus
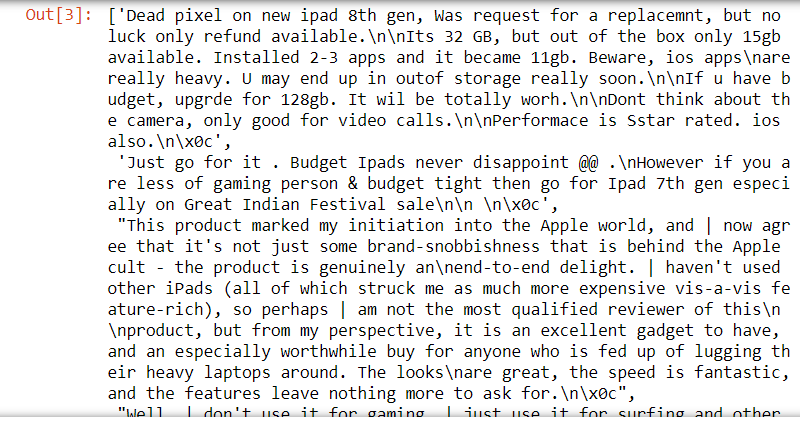
Paso 4: einen Datenrahmen erstellen
Pandas als pd importieren data = pd.DataFrame(aufführen(Korpus), Spalten=['Rezension']) Daten

Paso 5: den Text vorverarbeiten: Sonderzeichen entfernen, leere Worte
#Sonderzeichen entfernen
Importieren
auf jeden Fall sauber(Text):
zurück re.sub('[^ A-Za-z0-9" "]+', ' ', Text)
Daten['Gesäuberte Rezension'] = Daten['Rezension'].anwenden(sauber)
Daten

Entfernen von Stoppwörtern aus der 'Clean Review’ und Hinzufügen aller verbleibenden Wörter zu einer Listenvariablen “endgültige Liste”.
-
# Stoppwörter entfernen nltk importieren aus nltk.corpus importieren Stoppwörter nltk.download("punkt") aus nltk import word_tokenize stop_words = stopwords.words('Englisch') final_list = [] für Spalte in Daten[['Gesäuberte Rezension']]: SpalteSeriesObj = Daten[Säule] all_rev = columnSeriesObj.values für mich in Reichweite(len(all_rev)): Token = word_tokenize(all_rev[ich]) für Wort in Token: wenn word.lower() nicht in stop_words: final_list.append(Wort)
Paso 6: Bauen Sie positive und negative Wortwolken auf
Installieren Sie die Wortwolkenbibliothek mit dem Befehl “pip instalar wordcloud“.
In englischer Sprache, Wir haben einen vordefinierten Satz positiver und negativer Wörter namens Meinungslexika. Diese Dateien können heruntergeladen werden von Verknüpfung oder direkt bei mir GitHub-Repository.
Sobald die Dateien heruntergeladen sind, Lesen Sie diese Dateien im Code und erstellen Sie eine Liste mit positiven und negativen Wörtern.
mit offen(R"meinung-lexikon-deutschpositive-words.txt","R") als pos:
poswords = pos.lesen().Teilt("n")
mit offen(R"meinung-lexikon-Englishnegative-words.txt","R") als negativ:
Negativwörter = neg.lesen().Teilt("n")
Importieren von Bibliotheken zum Generieren und Anzeigen von Wortwolken.
import matplotlib.pyplot als plt aus Wordcloud importieren WordCloud
Positive Wortwolke
# Auswahl der einzigen Wörter, die in Poswörtern vorkommen
pos_in_pos = " ".beitreten([w für w in final_list, wenn w in Poswords])
wordcloud_pos = WordCloud(
background_color="Schwarz",
Breite=1800,
Höhe=1400
).generieren(pos_in_pos)
plt.imshow(wordcloud_pos)

Das Wort "gut" ist das am häufigsten verwendete Wort, das unsere Aufmerksamkeit erregt. Wenn wir uns die Bewertungen ansehen, Leute haben Rezensionen geschrieben, die besagen, dass das iPad einen guten Bildschirm hat, guter Klang, gute Soft- und Hardware.
Negative Wortwolke
# Auswahl der einzigen Wörter, die in Negativwörtern vorkommen
neg_in_neg = " ".beitreten([w für w in final_list, wenn w in negativen Wörtern])
wordcloud_neg = WordCloud(
background_color="Schwarz",
Breite=1800,
Höhe=1400
).generieren(neg_in_neg)
plt.imshow(wordcloud_neg)

Die Worte teuer, stecken, geschlagen, Enttäuschung stand in negativer Wortwolke. Wenn wir uns den Kontext des Wortes stecken ansehen, Würfel “Obwohl es nur 3 GB RAM, bleibt nie hängen”, was positiv an dem gerät ist.
Deswegen, es ist gut, Bigrama-Wortwolken zu erstellen / Trigramm, um den Kontext nicht zu verlieren.
2. Audiodateien erstellen (Text zu Audio)
gTTS ist eine Python-Bibliothek mit der Text-to-Speech-API von Google Translate.
Für die Installation, führe den Befehl aus “pip installieren gtts"An der Eingabeaufforderung.
Importieren Sie erforderliche Bibliotheken
CV2 importieren pytesseract importieren aus gtts importieren gTTS Importieren von OS
Legen Sie den Pfad von tesseract fest
pytesseract.pytesseract.tesseract_cmd=r'C:ProgrammdateienTesseract-OCRtesseract.exe'
Lesen Sie das Bild mit cv2.imread () und nimm den Text mit pytesseract aus dem Bild und speichere ihn in einer Variablen.
rev = cv2.imread("Bewertungen15.PNG")
# Zeigen Sie das Bild mit cv2.imshow an() Methode
# cv2.imshow("Bild", Rev)
# cv2.waitKey(0)
# cv2.destroyAllWindows()
# Holen Sie sich den Text aus dem Bild mit pytesseract
txt = pytesseract.image_to_string(Rev)
drucken(TXT)
Stellen Sie die Sprache ein und erstellen Sie eine Text-zu-Audio-Konvertierung mit gTTS, ohne den Text durchzugehen, Sprache
Sprache="In" outObj = gTTS(text=txt, lang=Sprache, langsam=Falsch)
Speichern Sie die Audiodatei unter “rev.mp3”
outObj.save("rev.mp3")
die Audiodatei abspielen
os.system('rev.mp3')
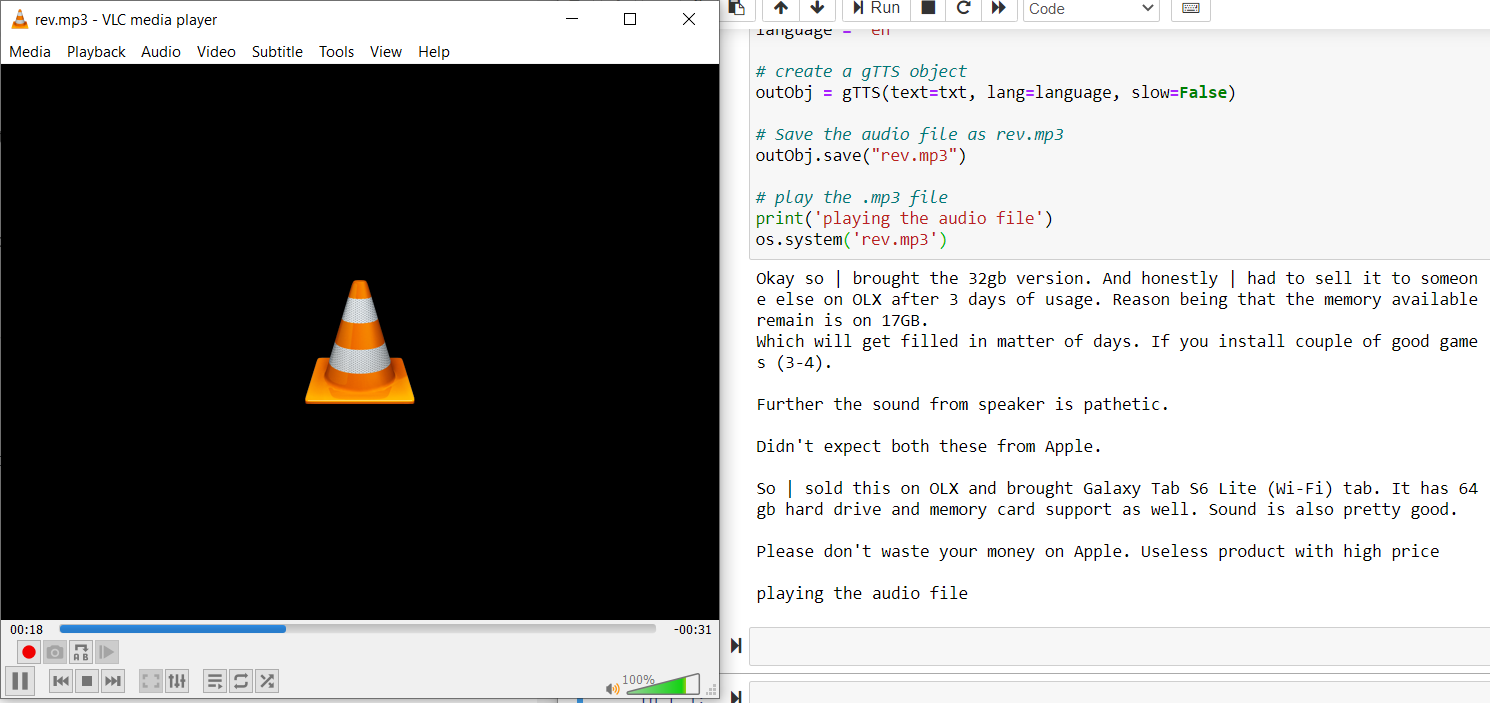
Vollständiger Code:
-
CV2 importieren pytesseract importieren aus gtts importieren gTTS Importieren von OS rev = cv2.imread("Bewertungen15.PNG") # cv2.imshow("Bild", Rev) # cv2.waitKey(0) # cv2.destroyAllWindows() txt = pytesseract.image_to_string(Rev) drucken(TXT) Sprache="In" outObj = gTTS(text=txt, lang=Sprache, langsam=Falsch) outObj.save("rev.mp3") drucken('Wiedergabe der Audiodatei') os.system('rev.mp3')
Abschließende Anmerkungen
Am Ende dieses Artikels, wir haben das Konzept der optischen Zeichenerkennung verstanden (OCR) und wir sind mit dem Lesen von Bildern mit OpenCV und dem Erfassen von Text aus Bildern mit pytesseract vertraut. Wir haben zwei grundlegende OCR-Anwendungen gesehen: Wortwolken bauen, Erstellen Sie hörbare Dateien, indem Sie Text mit gTTS in Sprache umwandeln.
Verweise:
Ich hoffe, dieser Artikel ist informativ und, bitte, Lassen Sie es mich wissen, wenn Sie Fragen oder Kommentare zu diesem Artikel im Kommentarbereich haben. Viel Spaß beim Lernen
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von DataPeaker und werden nach Ermessen des Autors verwendet.





