Dieser Artikel wurde im Rahmen der Data Science Blogathon
Einführung
Maschine. Es ist inspiriert von der Funktionsweise eines menschlichen Gehirns und, Daher, ist ein Satz neuronaler Netzalgorithmen, der versucht, die Funktionsweise eines menschlichen Gehirns zu imitieren und aus Erfahrungen zu lernen.
In diesem Artikel, Wir werden lernen, wie ein grundlegendes neuronales Netzwerk funktioniert und wie es sich selbst verbessert, um die besten Vorhersagen zu treffen.
Inhaltsverzeichnis
- Neuronale Netze und ihre Komponenten
- Perzeptron und mehrschichtiges Perzeptron
- Schrittweise Arbeit des neuronalen Netzes
- Rückvermehrung und wie sie funktioniert
- Kurz zu den Aktivierungsfunktionen
Künstliche neuronale Netze und ihre Komponenten
Neuronale Netze ist ein computergestütztes Lernsystem, das ein Netzwerk von Funktionen verwendet, um eine Dateneingabe von einem Weg in eine gewünschte Ausgabe zu verstehen und zu übersetzen, normalerweise in anderer Form. Das Konzept des künstlichen neuronalen Netzes wurde von der Humanbiologie und der Art und Weise inspiriert, wie Neuronen des menschlichen Gehirns arbeiten zusammen, um die Eingaben der menschlichen Sinne zu verstehen.
In einfachen Worten, Neuronale Netze sind eine Reihe von Algorithmen, die versuchen, Muster zu erkennen, Datenbeziehungen und Informationen durch den Prozess, der inspiriert ist und wie das Gehirn funktioniert / Menschliche Biologie.
Komponenten (Bearbeiten) / Neuronale Netzwerkarchitektur
Ein einfaches neuronales Netz besteht aus drei Komponenten :
- Eingabeebene
- Versteckter Umhang
- Ausgabeschicht

Quelle: Wikipedia
Eingabeebene: Auch als Eingabeknoten bekannt, sind die eingänge / Informationen von der Außenwelt, die dem Modell zur Verfügung gestellt werden, um zu lernen und Schlussfolgerungen zu ziehen. Die Eingabeknoten geben die Informationen an die nächste Schicht weiter, nämlich, versteckte Schicht.
Versteckter Umhang: Die versteckte Schicht ist der Satz von Neuronen, in dem alle Berechnungen mit den Eingabedaten durchgeführt werden. In einem neuronalen Netz kann es beliebig viele versteckte Schichten geben. Das einfachste Netzwerk besteht aus einer einzelnen versteckten Schicht.
Ausgabeschicht: Die Ausgabeschicht ist die Ausgabe / Modellschlussfolgerungen aus allen durchgeführten Berechnungen. Es kann einen oder mehrere Knoten in der Ausgabeschicht geben. Wenn wir ein binäres Klassifizierungsproblem haben, der Ausgabeknoten ist 1, aber bei Mehrklassenklassifizierung, Ausgabeknoten können mehr sein als 1.
Perzeptron und mehrschichtiges Perzeptron
Perzeptron ist eine einfache Form eines neuronalen Netzes und besteht aus einer einzigen Schicht, in der alle mathematischen Berechnungen durchgeführt werden.
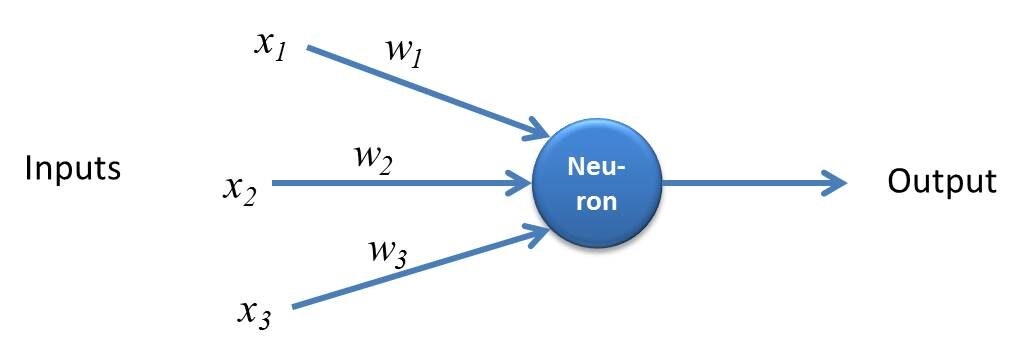
Quelle: kindsonthegenius.com
Während, Mehrschichtiges Perzeptron auch bekannt als Künstliche neurale Netzwerke Es besteht aus mehr als einer Wahrnehmung, die zu einem mehrschichtigen neuronalen Netz zusammengefasst sind.
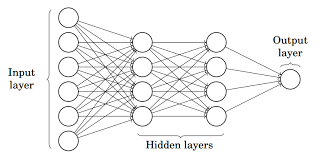
Quelle: Halb
Im Bild oben, Das künstliche neuronale Netz besteht aus vier miteinander verbundenen Schichten:
- Eine Eingabeschicht, mit 6 Eingabeknoten.
- Vorderseite 1 versteckt, mit 4 versteckte Knoten / 4 Perzeptronen
- Versteckter Umhang 2, mit 4 versteckte Knoten
- Ausgabeschicht mit 1 Ausgangsknoten
Schritt für Schritt Working de la rote neuronale künstliche
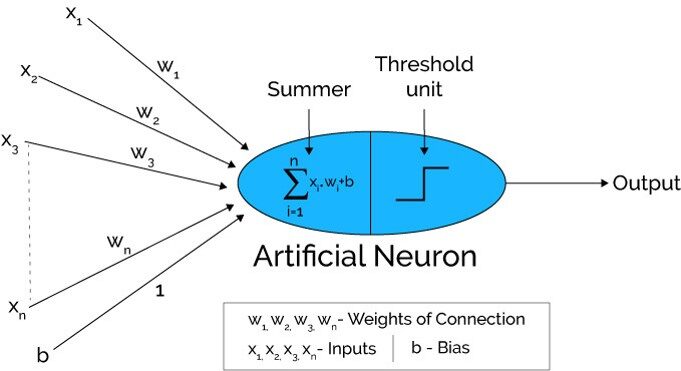
Quelle: Xenonstack.com
-
Im ersten Schritt Die Eingabeeinheiten werden übergeben, nämlich, die Daten werden mit einigen Gewichtungen an die versteckte Schicht übergeben.. Wir können eine beliebige Anzahl von versteckten Schichten haben. Im Bild oben, die Eingänge x1,x2,x3,….XNorden ist bestanden.
-
Jede verborgene Schicht besteht aus Neuronen. Alle Eingänge sind mit jedem Neuron verbunden.
-
Nach Übermittlung der Tickets, Alle Berechnungen werden in der versteckten Schicht durchgeführt (Blaues Oval im Bild)
Die Berechnung in verdeckten Schichten erfolgt in zwei Schritten, die wie folgt sind: :
-
Zuerst, alle Eingaben werden mit ihren Gewichten multipliziert. Gewicht ist der Gradient oder Koeffizient jeder Variablen. Zeigt die Stärke des jeweiligen Inputs an. Nach dem Zuweisen der Gewichte, eine Bias-Variable wird hinzugefügt. Voreingenommenheit ist eine Konstante, die dem Modell hilft, optimal zu passen.
MIT1 = W1*In1 + W2*In2 + W3*In3 + W4*In4 + W5*In5 + B
W1, W2, W3, W4, W5 sind die den In-Eingängen zugewiesenen Gewichte1, In2, In3, In4, In5, und b ist der Bias.
- Später, im zweiten schritt, das Die Aktivierungsfunktion wird auf die lineare Gleichung Z1 . angewendet. Die Aktivierungsfunktion ist eine nichtlineare Transformation, die auf die Eingabe angewendet wird, bevor sie an die nächste Neuronenschicht gesendet wird. Die Bedeutung der Aktivierungsfunktion besteht darin, dem Modell Nichtlinearität zu verleihen.
Es gibt verschiedene Aktivierungsfunktionen, die im nächsten Abschnitt aufgeführt werden.
-
Der gesamte in Punkt beschriebene Prozess 3 auf jeder versteckten Schicht durchgeführt. Nachdem du jede versteckte Schicht durchgegangen bist, wir gehen zur letzten schicht, nämlich, unsere Ausgabeschicht, die uns die endgültige Ausgabe liefert.
Der oben erläuterte Prozess wird als Vorwärtspropagation bezeichnet.
-
Nachdem Sie die Vorhersagen von der Ausgabeschicht erhalten haben, der Fehler wird berechnet, nämlich, die Differenz zwischen tatsächlicher und erwarteter Leistung.
Wenn der Fehler groß ist, dann werden Schritte unternommen, um den Fehler zu minimieren und zum gleichen Zweck, Rückwärtsausbreitung wird durchgeführt.
Was ist Rückwärtsausbreitung und wie funktioniert sie??
Reverse Propagation ist der Prozess des Aktualisierens und Findens der optimalen Werte von Gewichten oder Koeffizienten, die dem Modell helfen, den Fehler zu minimieren, nämlich, die Differenz zwischen den tatsächlichen und den vorhergesagten Werten.
Aber hier ist die Frage: Wie werden Gewichte aktualisiert und neue Gewichte berechnet??
Gewichte werden mit Hilfe von Optimierern aktualisiert.. Optimierer sind die Methoden / mathematische Formulierungen, um die Attribute neuronaler Netze zu ändern, nämlich, die Gewichte, um den Fehler zu minimieren.
Abwärts geneigte Rückwärtsausbreitung
Gradient Descent ist einer der Optimierer, der bei der Berechnung der neuen Gewichte hilft. Lassen Sie uns Schritt für Schritt verstehen, wie Gradient Descent die Kostenfunktion optimiert.
Im Bild unten, die Kurve ist unsere Kostenfunktionskurve und unser Ziel ist es, den Fehler so zu minimieren, dass JMindest nämlich, globale Minima sind erreicht.
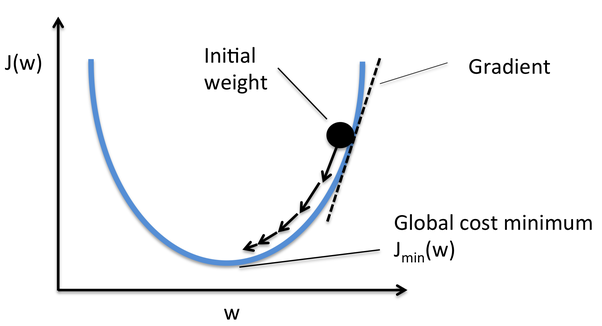
Quelle: Quora
Schritte zum Erreichen des globalen Minimums:
-
Zuerst, Gewichte werden zufällig initialisiert nämlich, der Zufallswert des Gewichts und der Schnittpunkte werden dem Modell zugewiesen, während die Vorwärtsausbreitung und Fehler werden berechnet nach all der rechnung. (Wie oben besprochen)
-
So dass er die Steigung wird berechnet, nämlich, abgeleitet aus Fehler mit aktuellen Gewichten
-
Später, die neuen Gewichte werden nach folgender Formel berechnet, wo a ist die Lernrate Dies ist der Parameter, der auch als Schrittweite bekannt ist, um die Geschwindigkeit oder die Schritte der Rückwärtsausbreitung zu steuern. Bietet zusätzliche Kontrolle darüber, wie schnell wir uns um die Kurve bewegen möchten, um globale Tiefststände zu erreichen.
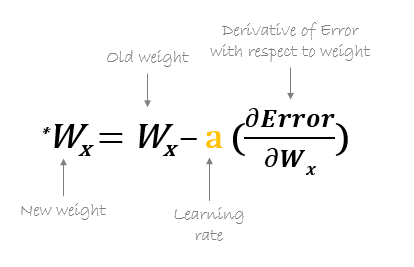
Quelle: hmkcode.com
4.Dieser Vorgang der Berechnung der neuen Gewichte, dann die Fehler der neuen Gewichte und dann die Aktualisierung der Gewichte. geht weiter, bis wir globale Tiefststände erreichen und der Verlust minimiert ist.
Zu beachten ist hierbei, dass die Lernrate, nämlich, a in unserem Gewichtsupdate Die Gleichung muss mit Bedacht gewählt werden. Die Lernrate ist der Betrag der Veränderung oder die Größe des Schrittes, der unternommen wird, um die globalen Minima zu erreichen. Es sollte nicht zu klein sein da es einige Zeit dauern wird, sich zu konvergieren, ebenso gut wie es sollte nicht sehr groß sein die die globalen Minima überhaupt nicht erreichen. Deswegen, die Lernrate ist der Hyperparameter, den wir basierend auf dem Modell wählen müssen.
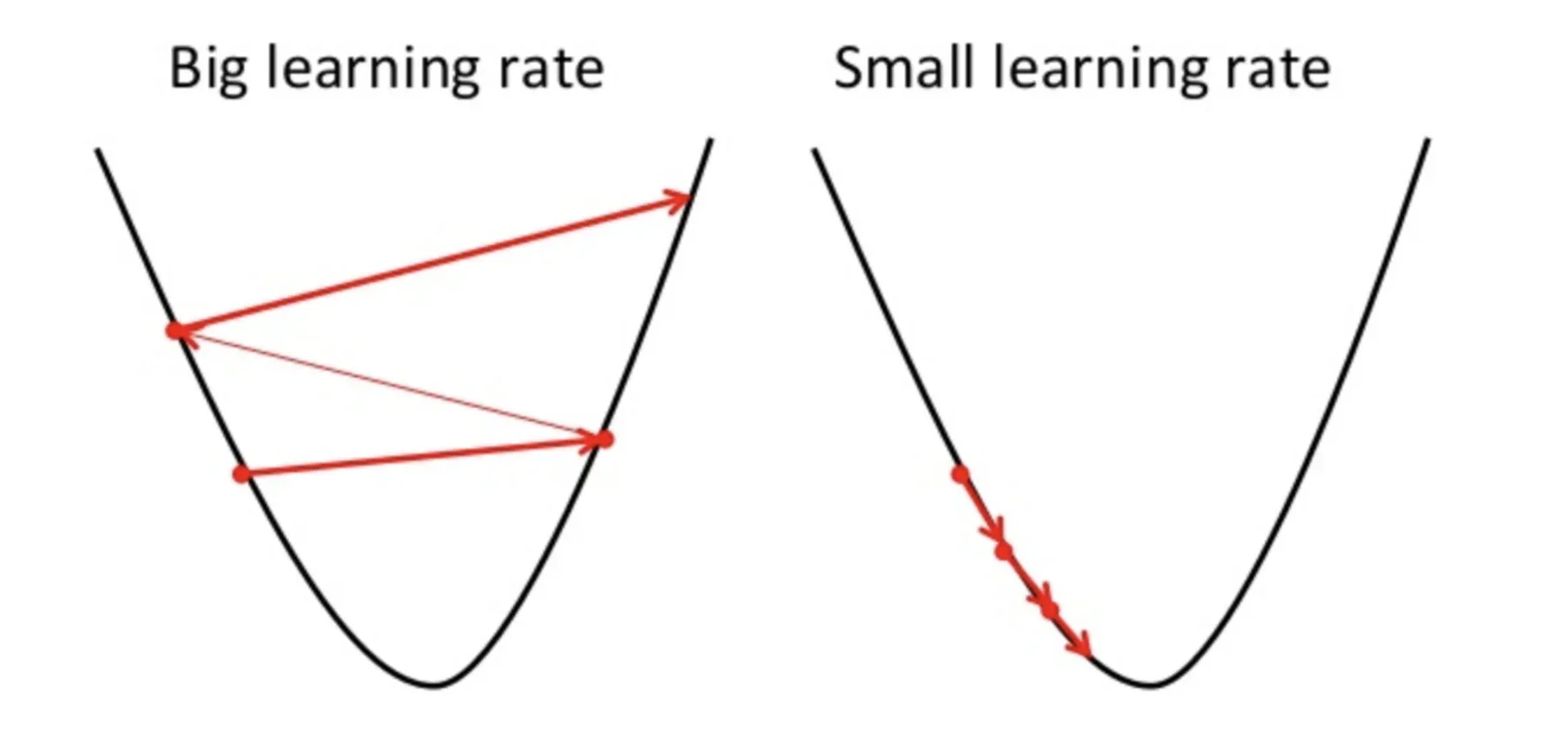
Quelle: Educative.io
Die detaillierte Mathematik und die Backpropagation-Kettenregel kennen, siehe Anhang Lernprogramm.
Kurz zu den Aktivierungsfunktionen
Triggerfunktionen sind an jedes Neuron angehängt und sind mathematische Gleichungen, die bestimmen, ob ein Neuron feuern soll oder nicht, basierend darauf, ob die Eingabe des Neurons für die Vorhersage des Modells relevant ist oder nicht. Der Zweck der Aktivierungsfunktion besteht darin, eine Nichtlinearität in die Daten einzuführen.
Verschiedene Arten von Triggerfunktionen sind:
- Sigmoid-Aktivierungsfunktion
- TanH-Aktivierungsfunktion / Hyperbolischer Tangens
- Funktion der gleichgerichteten Lineareinheit (Lebenslauf)
- Undichte ReLU
- Softmax
In diesem Blog finden Sie eine detaillierte Erklärung der Aktivierungsfunktionen.
Abschließende Anmerkungen
Hier beende ich meine Schritt-für-Schritt-Erklärung des ersten Deep Learning Neural Network, das ist ANA. Ich habe versucht, den Prozess von Propagation Forwarding und Backpropagation so einfach wie möglich zu erklären. Ich hoffe, dieser Artikel war es wert, gelesen zu werden 🙂
Bitte, melde dich gerne bei mir LinkedIn und teile deinen wertvollen Input. Bitte, schau dir meine anderen Artikel hier an.
Über den Autor
Soja Deepanshi Dhingra, Ich arbeite derzeit als Data Science Researcher und habe einen Hintergrund in Analytik, explorative Datenanalyse, Maschinelles Lernen und Deep Learning.
Die in diesem Artikel über das künstliche neuronale Netz gezeigten Medien sind nicht Eigentum von DataPeaker und werden nach Ermessen des Autors verwendet.





