Dieser Artikel wurde im Rahmen der Data Science Blogathon
Einführung
Die Funktionsauswahl ist der Prozess der Auswahl der Funktionen, die für ein Modell für maschinelles Lernen relevant sind. Das bedeutet, dass nur die Attribute ausgewählt werden, die einen signifikanten Einfluss auf die Modellausgabe haben.
Betrachten Sie den Fall, wenn Sie in ein Kaufhaus gehen, um Lebensmittel zu kaufen. Ein Produkt hat viele Informationen, nämlich, Produkt, Kategorie, Geburtstermin, MRP, Zutaten und Herstellungsdetails. Alle diese Informationen sind die Eigenschaften des Produkts. Normalerweise, Überprüfen Sie die Marke, MRP und Verfallsdatum vor dem Kauf eines Produkts. Aber trotzdem, die Zutaten- und Herstellungsabteilung geht dich nichts an. Deswegen, die Marke, el mrp, das Verfallsdatum sind relevante Merkmale und die Zutat, Herstellungsdetails sind irrelevant. So erfolgt die Funktionsauswahl.
In der echten Welt, Ein Dataset kann Tausende von Funktionen enthalten und es besteht die Möglichkeit, dass einige Funktionen redundant sind, einige können korreliert sein und andere können für das Modell irrelevant sein. In dieser Phase, wenn Sie alle Funktionen nutzen, Das Trainieren des Modells dauert lange und die Genauigkeit des Modells wird verringert. Deswegen, Merkmalsauswahl wird im Modellbau wichtig. Es gibt viele andere Möglichkeiten, Funktionen auszuwählen, als Eliminierung rekursiver Merkmale, genetische Algorythmen, Entscheidungsbäume. Aber trotzdem, Ich werde Ihnen die einfachste und manuellste Methode zum Filtern mit statistischen Tests erklären.
Jetzt haben Sie ein grundlegendes Verständnis der Funktionsauswahl, Wir werden sehen, wie verschiedene statistische Tests an den Daten durchgeführt werden, um wichtige Merkmale auszuwählen.
Ziel
Das Hauptziel dieses Blogs ist es, statistische Tests und ihre Implementierung in realen Daten in Python zu verstehen, was bei der Auswahl der Funktionen hilft.
Terminologien
Bevor Sie sich mit den Arten von statistischen Tests und deren Implementierung befassen, Es ist notwendig, die Bedeutung einiger Terminologien zu verstehen.
Hypothesentest
Hypothesentests in der Statistik sind eine Methode, um die Ergebnisse von Experimenten oder Umfragen zu testen, um zu sehen, ob sie aussagekräftige Ergebnisse liefern.. Nützlich, wenn Sie auf der Grundlage einer Stichprobe oder einer Korrelation zwischen zwei oder mehr Stichproben Rückschlüsse auf eine Grundgesamtheit ziehen möchten.
Nullhypothese
Diese Hypothese stellt fest, dass es keinen signifikanten Unterschied zwischen Stichprobe und Grundgesamtheit oder zwischen verschiedenen Grundgesamtheiten gibt.. Es wird mit H . bezeichnet0.
Nicht. Wir nehmen an, dass der Mittelwert von 2 proben sind die gleichen.
Alternative Hypothese
Die der Nullhypothese widersprechende Aussage ist in der Alternativhypothese enthalten. Es wird mit H . bezeichnet1.
Nicht. Wir nehmen an, dass der Mittelwert der 2 Proben ist ungleichmäßig.
kritischer Wert
Es ist ein Punkt auf der Skala der Teststatistik, ab dem die Nullhypothese abgelehnt wird.. Je höher der kritische Wert, desto geringer ist die Wahrscheinlichkeit, dass 2 Stichproben gehören zur gleichen Verteilung. Der kritische Wert für jede Testdose
p-Wert
p-Wert bedeutet 'Wahrscheinlichkeitswert'; gibt die Wahrscheinlichkeit an, dass ein Ergebnis zufällig aufgetreten ist. Grundsätzlich, Der p-Wert wird bei Hypothesentests verwendet, um Ihnen zu helfen, die Nullhypothese zu unterstützen oder abzulehnen. Je kleiner der p-Wert, desto stärker ist der Beweis, die Nullhypothese abzulehnen.
Freiheitsgrad
Der Freiheitsgrad ist die Anzahl der unabhängigen Variablen. Dieses Konzept wird verwendet, um die t-Statistik und die Chi-Quadrat-Statistik zu berechnen.
Sie können sich beziehen auf statistikwho.com Weitere Informationen zu diesen Terminologien.
Statistische Tests
Ein statistischer Test ist eine Möglichkeit zu bestimmen, ob die Zufallsvariable der Nullhypothese oder der Alternativhypothese folgt. Grundsätzlich, sagt, ob die Stichprobe und die Grundgesamtheit oder zwei oder mehr Stichproben signifikante Unterschiede aufweisen. Sie können verschiedene beschreibende Statistiken als Durchschnitt verwenden, Median, Weg, Bereich oder Standardabweichung für diesen Zweck. Aber trotzdem, wir verwenden im Allgemeinen den Mittelwert. Der statistische Test liefert eine Zahl, die dann mit dem p-Wert verglichen wird. Ist sein Wert größer als der p-Wert, akzeptiere die Nullhypothese, andererseits, Sie lehnt ab.
Das Verfahren zur Implementierung jedes statistischen Tests ist wie folgt::
- Den statistischen Wert berechnen wir mit der mathematischen Formel
- Dann berechnen wir den kritischen Wert mit statistischen Tabellen.
- Mit Hilfe des kritischen Wertes, wir berechnen den p-Wert
- Wenn der p-Wert> 0.05 wir akzeptieren die Nullhypothese, sonst lehnen wir es ab
Jetzt, da Sie die Funktionsauswahl und statistische Tests verstehen, wir können zur Implementierung verschiedener statistischer Tests mit ihrer Bedeutung übergehen. Davor, Ich zeige Ihnen den Datensatz und dieser Datensatz wird für alle Tests verwendet.
Datensatz
Der Datensatz, den ich verwenden werde, ist ein Datensatz zur Kreditvorhersage, der dem Vidhya-Analysewettbewerb entnommen wurde. Sie können auch am Wettbewerb teilnehmen und den Datensatz herunterladen. hier.
Zuerst habe ich alle notwendigen Python-Module und den Datensatz importiert.
numpy als np importieren
Pandas als pd importieren
Seegeboren als jdn importieren
von numpy import sqrt, Abs, runden
scipy.stats als Statistik importieren
von scipy.stats Importnorm
df=pd.read_csv('darlehen.csv')
df.kopf()

Es gibt viele Merkmale im Datensatz, als Geschlecht, Angehörige, Ausbildung, Einkommen des Antragstellers, Kreditbetrag, Kredit Geschichte. Wir werden diese Features nutzen und mit verschiedenen Tests prüfen, ob ein Feature-Effekt andere Features beeinflusst, nämlich, Z-Test, Korrelationstest, ANOVA-Test und Chi-Quadrat-Test.
Z-Test
Ein Z-Test wird verwendet, um den Mittelwert zweier gegebener Stichproben zu vergleichen und daraus abzuleiten, ob sie zur gleichen Verteilung gehören oder nicht.. Wir implementieren den Z-Test nicht, wenn die Stichprobengröße kleiner ist als 30.
Ein Z-Test kann ein Z-Test bei einer Stichprobe oder ein Z-Test bei zwei Stichproben sein.
Das einzigartige Muster teste t bestimmt, ob sich der Stichprobenmittelwert statistisch von einem bekannten oder hypothetischen Populationsmittelwert unterscheidet. Der Z-Test mit zwei Stichproben vergleicht 2 unabhängige Variablen.
Wir werden einen Z-Test mit zwei Stichproben implementieren.
Die Z-Statistik wird bezeichnet durch
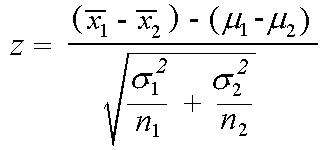
Implementierung
Bitte beachten Sie, dass wir implementieren 2 Beispiel-Z-Tests, bei denen eine Variable kategorial mit zwei Kategorien ist und die andere Variable kontinuierlich ist, um den Z-Test anzuwenden.
Hier verwenden wir die Geschlecht kategoriale Variable und Bewerbereinkommen Kontinuierliche Variable. Das Genre hat 2 Gruppen: männlich und weiblich. Daher lautet die Hypothese:
Nullhypothese: Es gibt keinen signifikanten Unterschied zwischen dem Durchschnittseinkommen von Männern und Frauen.
Alternative Hypothese: Es gibt einen signifikanten Unterschied zwischen dem Durchschnittseinkommen von Männern und Frauen.
Code
M_mean=df.loc[df['Geschlecht']=='Männlich','BewerberEinkommen'].bedeuten() F_mean=df.loc[df['Geschlecht']=='Weiblich','BewerberEinkommen'].bedeuten() M_std=df.loc[df['Geschlecht']=='Männlich','BewerberEinkommen'].std() F_std=df.loc[df['Geschlecht']=='Weiblich','BewerberEinkommen'].std() no_of_M=df.loc[df['Geschlecht']=='Männlich','BewerberEinkommen'].zählen() no_of_F=df.loc[df['Geschlecht']=='Weiblich','BewerberEinkommen'].zählen()
Der obige Code berechnet das durchschnittliche Einkommen männlicher Bewerber, das durchschnittliche Einkommen der weiblichen Bewerber, seine Standardabweichung und die Anzahl der Stichproben von Männern und Frauen.
twoSampZ Die Funktion berechnet die z-Statistik und den p-Wert, ohne die zuvor berechneten Eingabeparameter zu durchlaufen.
def twoSampZ(X1, X2, schlammig, sd1, sd2, n1, n2):
gepooltSE = sqrt(sd1**2/n1 + sd2**2/n2)
z = ((X1 - X2) - schlammig)/gepooltSE
pval = 2*(1 - norm.cdf(Abs(Mit)))
Rückrunde(Mit,3), pval
z,p= twoSampZ(M_mean,F_mean,0,M_std,F_std,no_of_M,nicht aus)
drucken('Z'= z,'p'= p)
Z = 1.828
p = 0.06759726635832197
wenn P<0.05:
drucken("wir lehnen die Nullhypothese ab")
anders:
drucken("wir akzeptieren die Nullhypothese")
wir akzeptieren die Nullhypothese
Da der p-Wert größer als ist 0.5 wir akzeptieren die Nullhypothese. Deswegen, Wir kommen zu dem Schluss, dass es keinen signifikanten Unterschied zwischen dem Einkommen von Männern und Frauen gibt.
Test T
Ein t-Test wird auch verwendet, um den Mittelwert zweier gegebener Stichproben zu vergleichen., wie Z-Test. Aber trotzdem, wird implementiert, wenn die Stichprobengröße kleiner als ist 30. Es wird eine Normalverteilung der Stichprobe angenommen. Es können auch ein oder zwei Proben sein. Der Freiheitsgrad wird durch n-1 berechnet, wobei n die Anzahl der Abtastwerte ist.
Es wird bezeichnet mit

Implementierung
Er wird wie der Z-Test durchgeführt. Die einzige Bedingung ist, dass die Stichprobengröße kleiner als sein muss 30. Ich habe dir die Umsetzung des Z-Tests gezeigt. Jetzt, Sie können den T-Test ausprobieren.
Korrelationstest
Ein Korrelationstest ist eine Metrik, um zu bewerten, inwieweit Variablen miteinander verbunden sind.
Beachten Sie, dass die Variablen stetig sein müssen, um den Korrelationstest anzuwenden.
Es gibt mehrere Methoden für Korrelationstests, nämlich, kovarianza, Korrelationskoeffizient nach Pearson, Rangkorrelationskoeffizient nach Spearman, etc.
Wir werden den Korrelationskoeffizienten von Personen verwenden, da er von den Werten der Variablen unabhängig ist.
Korrelationskoeffizient nach Pearson
Es wird verwendet, um die lineare Korrelation zwischen 2 Variablen. Es wird bezeichnet mit

Google Bild
Seine Werte liegen zwischen -1 Ja 1.
Ist der Wert von r 0, bedeutet, dass zwischen den Variablen X und Y kein Zusammenhang besteht.
Wenn der Wert von r zwischen liegt 0 Ja 1, bedeutet, dass zwischen X und Y ein positiver Zusammenhang besteht, und seine Kraft wächst von 0 ein 1. Positive Beziehung bedeutet, dass wenn der Wert von X steigt, der Wert von Y steigt auch.
Wenn der Wert von r zwischen liegt -1 Ja 0, bedeutet, dass es eine negative Beziehung zwischen X und Y gibt, und seine Stärke nimmt ab von -1 ein 0. Negative Beziehung bedeutet, dass wenn der Wert von X steigt, der Wert von Y sinkt.
Implementierung
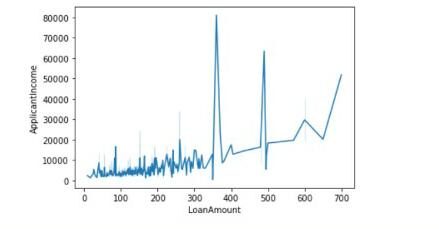
Hier verwenden wir zwei Variablen oder kontinuierliche Merkmale: Kreditbetrag Ja Bewerbereinkommen. Wir werden feststellen, ob zwischen dem Kreditbetrag und dem Einkommen des Antragstellers ein linearer Zusammenhang mit dem Wert des Korrelationskoeffizienten nach Pearson besteht, und wir werden auch den Graphen zwischen ihnen zeichnen.
Code
In der Spalte LoanAmount fehlen einige Werte, erste, wir füllen es mit dem Mittelwert. Dann berechnete er den Wert des Korrelationskoeffizienten.
df[„Darlehensbetrag“]= df[„Darlehensbetrag“].Fillna (df[„Darlehensbetrag“].meinen())
pcc = z.B. corrcoef (df.BewerberEinkommen, df.LoanAmount)
zu drucken (PCC)
[[1. 0.56562046] [0.56562046 1. ]]
Die Werte der Diagonalen geben die Korrelation der Merkmale mit sich selbst an. 0.56 stellen dar, dass es eine gewisse Korrelation zwischen den beiden Merkmalen gibt.
Wir können den Graphen auch wie folgt zeichnen:
sns.lineplot(Daten=df,x='Darlehensbetrag',y = 'Bewerbereinkommen')
ANOVA-Test
ANOVA bedeutet Varianzanalyse. Wie der Name schon sagt, verwendet Varianz als Parameter, um mehrere unabhängige Gruppen zu vergleichen. Die ANOVA kann eine unidirektionale ANOVA oder eine bidirektionale ANOVA sein. Eine einfache ANOVA wird angewendet, wenn drei oder mehr unabhängige Gruppen einer Variablen vorhanden sind. Wir werden das gleiche in Python implementieren.
Die F-Statistik kann berechnet werden durch

Implementierung
Hier verwenden wir die Angehörige kategoriale Variable und Bewerbereinkommen Kontinuierliche Variable. Die Angehörigen haben 4 Gruppen: 0,1,2,3+. Daher lautet die Hypothese:
Nullhypothese: Es gibt keinen signifikanten Unterschied zwischen den Durchschnittseinkommen zwischen den verschiedenen Gruppen von Unterhaltsberechtigten.
Alternative Hypothese: es gibt einen signifikanten Unterschied zwischen den Durchschnittseinkommen zwischen den verschiedenen Gruppen von Unterhaltsberechtigten.
Code
Zuerst, wir behandeln die fehlenden Werte in der Dependents-Funktion.
df['Abhängige'].ist Null().Summe()
df['Abhängige']=df['Abhängige'].Fillna('0')
Nachdem, erstellen wir einen Datenrahmen mit den Merkmalen Dependents und ApplicantIncome. Später, mit Hilfe der scipy.stats-Bibliothek, berechnen wir die F-Statistik und den p-Wert.
df_anova = df[['gesamte Rechnung','Tag']]
grps = pd.unique(df.Tageswerte)
d_daten = {grp:df_anova['gesamte Rechnung'][df_anova.day == grp] für grp in grps}
F, p = stats.f_oneway(d_daten['Sonne'], d_daten['Sa'], d_daten['Do'],d_daten['Fr'])
drucken('F ={},p={}'.Format(F,P))
F = 5.955112389949444,p=0.0005260114222572804
und P <0,05:
zu drucken (“Nullhypothese ablehnen”)
der Rest:
zu drucken (“akzeptiere die Nullhypothese”)
Nullhypothese ablehnen.
Da der p-Wert kleiner als ist 0.5 wir verwerfen die Nullhypothese. Deswegen, Wir kommen zu dem Schluss, dass es einen signifikanten Unterschied zwischen dem Einkommen verschiedener Gruppen von Abhängigen gibt.
Chi-Quadrat-Test
Dieser Test wird angewendet, wenn Sie zwei kategoriale Variablen aus einer Grundgesamtheit haben. Es wird verwendet, um zu bestimmen, ob es eine signifikante Assoziation oder Beziehung zwischen den beiden Variablen gibt.
Es gibt 2 Arten von Chi-Quadrat-Tests: Chi-Quadrat-Anpassungstest und Chi-Quadrat-Test auf Unabhängigkeit, Letzteres werden wir umsetzen.
Der Freiheitsgrad im Chi-Quadrat-Test berechnet sich aus (n-1) * (m-1) wobei n und m die Anzahl der Zeilen bzw. Spalten sind.
Es wird bezeichnet mit:

Implementierung
Wir werden kategoriale Merkmale verwenden Geschlecht Ja Kreditstatus und finde mit dem Chi-Quadrat-Test heraus, ob es einen Zusammenhang zwischen ihnen gibt.
Nullhypothese: Es besteht kein signifikanter Zusammenhang zwischen Geschlechtsmerkmalen und Kreditstatus.
Alternative Hypothese: Es besteht ein signifikanter Zusammenhang zwischen Geschlechtsmerkmalen und Kreditstatus.
Code
Zuerst, Wir rufen die Spalte Gender und LoanStatus ab und bilden ein Array.
dataset_table=pd.crossstab(Datensatz['Sex'],Datensatz['Raucher']) dataset_table
Loan_Status N Y
Gender
Female 37 75
Männlich 33 339
Später, wir berechnen die beobachteten und erwarteten Werte anhand der obigen Tabelle.
beobachtet=dataset_table.values val2=stats.chi2_contingency(dataset_table) erwartet=val2[3]
Dann berechnen wir die Chi-Quadrat-Statistik und den p-Wert mit dem folgenden Code:
von scipy.stats importieren chi2 chi_square=sum([(o-und)**2./e für o,e in zip(beobachtet,erwartet)]) chi_square_statistic=chi_square[0]+chi_square[1] p_value=1-chi2.cdf(x=chi_square_statistic,df = ddof)
drucken("Chi-Quadrat-Statistik:-",chi_square_statistic)
drucken('Signifikanzniveau: ',Alpha)
drucken('Freiheitsgrad: ',Ich werde kommen)
drucken('p-Wert:',p_Wert)
Chi-Quadrat-Statistik:- 0.23697508750826923 Signifikanzniveau: 0.05 Freiheitsgrad: 1 p-Wert: 0.6263994534115932
wenn p_Wert<=alpha:
drucken("Ablehnung der Nullhypothese")
anders:
drucken("Akzeptieren Sie die Nullhypothese")
Akzeptieren Sie die Nullhypothese
Da der p-Wert größer als ist 0.05, wir akzeptieren die Nullhypothese. Wir kommen zu dem Schluss, dass es keinen signifikanten Zusammenhang zwischen den beiden Merkmalen gibt.
Zusammenfassung
Zuerst, Wir haben die Funktionsauswahl besprochen. Dann gehen wir zu den statistischen Tests und verschiedenen damit verbundenen Terminologien über.. Schließlich, Wir haben die Anwendung statistischer Tests gesehen, nämlich, Z-Test, T-Test, Korrelationstest, ANOVA und Chi-Quadrat-Test zusammen mit ihrer Implementierung in Python.
Verweise
Hervorragendes Bild – Google Bild
Statistiken – statistikwho.com
Über mich
Hi! Soja Ashish Choudhary. Ich studiere B.Tech an der JC Bose University of Science and Technology. Data Science ist meine Leidenschaft und ich bin stolz darauf, interessante Blogs zu diesem Thema zu schreiben. Kontaktieren Sie mich gerne auf LinkedIn.
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von DataPeaker und werden nach Ermessen des Autors verwendet.





